
Keep up to date on current trends and technologies
HTML & CSS

Customizing Bootstrap jQuery Plugins
Maria Antonietta Perna

3 Tips for Speeding Up Your Bootstrap Website
Maria Antonietta Perna

Retrofit Your Website as a Progressive Web App
Craig Buckler

Game AI: The Bots Strike Back!
Earle Castledine

A Full-screen Bootstrap Carousel with Random Initial Image
George Martsoukos

Getting Bootstrap Tabs to Play Nice with Masonry
Maria Antonietta Perna

Bootstrap: Super Smart Features to Win You Over
Maria Antonietta Perna

Front-end Frameworks: Custom vs Ready-to-use Solutions
Ivaylo Gerchev

Understanding Bootstrap Modals
Syed Fazle Rahman
How to Optimize CSS and JS for Faster Sites
Gary Stevens

Build George Costanza’s Bathroom Finder using WRLD
Christopher Pitt

Build a Dynamic 3D Map with WRLD 3D
Christopher Pitt

Optimizing CSS: Tweaking Animation Performance with DevTools
Maria Antonietta Perna

Upgrade Your Project with CSS Selector and Custom Attributes
Tim Harrison

How to Create Custom Components Using Component IO
Craig Buckler

Learn a CSS Framework in 6 Minutes with Bulma
Gregg Pollack

How to Write Beautiful Sass
Miriam Suzanne
How to Use Warnings and Errors in Sass Effectively
Kitty Giraudel
CSS font-display: The Future of Font Rendering on the Web
Giulio Mainardi
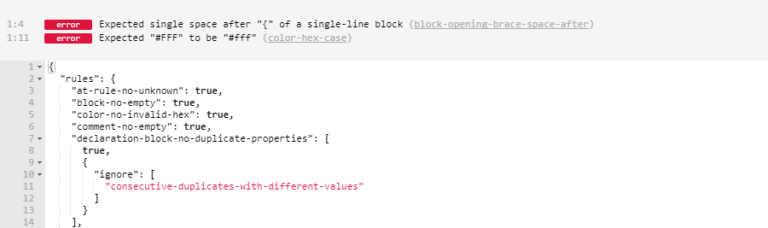
Taking CSS Linting to the Next Level with Stylelint
Ashley Nolan

Putting the “App” in Progressive Web Apps
Nicole Saidy
Building a Trello Layout with CSS Grid and Flexbox
Giulio Mainardi

How to Create CSS Conic Gradients for Pie Charts and More
Gajendar Singh

Fancy Web Animations Made Easy with GreenSock Plugins
Maria Antonietta Perna

Improve Web Typography with CSS Font Size Adjust
Gajendar Singh

Converting Your Typographic Units with Sass
Byron Houwens

CSS Architecture and the Three Pillars of Maintainable CSS
Zsolt Nagy

Sass Functions to Kick-Start Your Style Sheets
Byron Houwens

How to Create Beautiful HTML & CSS Presentations with WebSlides
Ivaylo Gerchev

Frame by Frame Animation Tutorial with CSS and JavaScript
Michael Romanov

What’s the Difference Between Sass and SCSS?
Kitty Giraudel

CSS Inheritance: An Introduction
Asha Laxmi
Showing 160 of 443