Activities, Tasks and Intents, Oh My!

Whenever you read about Android development, you’ll see the word Activity pop up all the time. In this article, we’ll explain what Activities are, and how they relate to Tasks, Processes and the Back Stack running on the phone.
Key Takeaways
- An Android Activity is a visual component on a screen, with logic to manage life cycle and navigation. Activities are defined as subclasses of android.app.Activity and must be declared in a manifest file. They have a lifecycle and can be started or re-started at any time, with developers responsible for saving any state information.
- Android uses a Back Stack to manage navigation between Activities. This can contain activities from different applications, grouped into a Task. One app can launch an activity in another app using an Intent, allowing different applications to collaborate without knowing too much about each other. It’s possible to have more than one Task active at a time, with Android remembering the state of each Task.
- Intents manage navigation between Activities. They are messages that applications broadcast through the Android OS, with applications registering as listeners for these Intent events. Developers can use Explicit Intents to specify the specific Activity class they wish to start. When writing an application, developers should structure their intents so they can be used by other applications.
Activities
An activity is a visual component that you see on a screen, with some associated logic to manage life cycle and navigation. An application will generally consist of several activities. When you move from screen to screen, generally you are changing Activities, replacing what is on the screen with the new contents and controller.
Each activity is defined as a subclass of android.app.Activity, and must be declared in your manifest file, along with a declaration of how the activity can be started. The activity also has a lifecycle, responding to the following state machine:
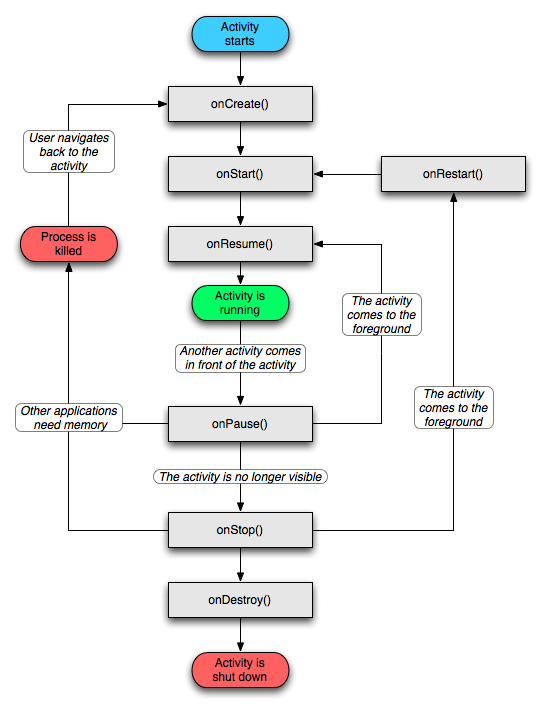
When an activity is on screen, it is running (green in the diagram). When Android changes activities, it will be paused. It is the developer’s responsibility to stop any CPU hungry tasks (e.g. Animation, Graphics) that are running when the onPause() method is called. Android may also request that an Activity be stopped because it wants to recover memory. When this happens, the activity may be stopped. As before, it is the developer’s responsibility to release any memory it can when it is sent the onStop() method. Finally, when the application is shut down, the onDestroy() method is called. There are also corresponding onCreate(), onStart() and onResume() methods that are used when the activity is progressively brought to its running state.
Activities may be started, or re-started at any time. It is important that the developer puts the right code in his activity to save any state information. As an example, by default, Android will re-create an Activity when the screen rotates, to allow the activity to use a different layout and components. It is possible to override this, but it serves as an example. Developers should put code in the onStart() and onStop() methods to save any state required.
Linking Activities Together with the Back Stack
Most applications will consist of ore than one screen, and Android has a very strong back mechanism through its use of a dedicated back button. It implements this using a Back Stack. When you click on an application in the home app, Android will start a back stack, and push on the home activity. If the application then navigates to another Activity, the appropriate lifecycle events are called and then it is pushed onto the stack, becoming the topmost (active) activity.
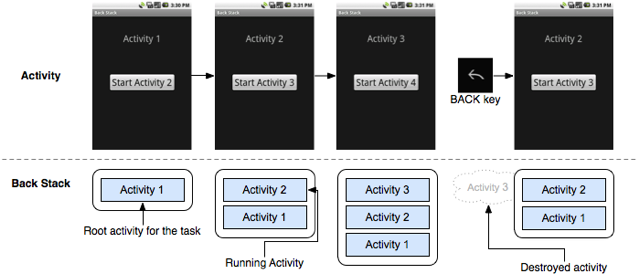
So far, this all sounds very straight forward, right? Every phone OS these days works in this fashion. Where Android is a little different is that a back stack can contain activities from different applications, grouped into something which is called a Task.
It is possible for one app to launch an activity in another application, using something called an Intent (which we will discuss later). This allows different applications to collaborate, but without having to know too much about each other. As an example, you might want to send an email from your application when the user clicks on a “Feedback” button. When this happens, Android pushes the composer activity from the Gmail application onto the back stack for the task, and the user types their message. When they finish (or press back), Android pops off the gmail activity and returns you to the next activity down, which will be your application. This makes it look like the applications have worked together as a coherent … well Task… when in fact they are completely independent.
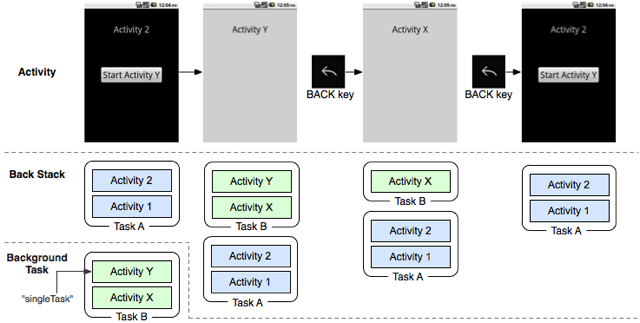
It is also possible to have more than one Task active at one time. Lets say you load up an application and drill down a few activities to what you want, then press the Home button, and start another application. Android remembers the state of where you were before in a Task. It then starts a new Task for your new application, which you could drill down some more. You are now free to go back out to switch between these two tasks, each time returning to exactly where you were before, thanks to the remembered Task and its back stack.
By default, Android will forget Tasks after a while if you don’t return to them. The rationale is that if you haven’t used a task for a period then you’ve lost interest in it and it can be shut down. This explains why if you exit say your web browser but go back to it soon after then you return to the last page you were on, but if you come back a few days later it might take you back to your home page instead. This is all managed for you automatically by Android.
Intents: Navigating between Activities (Amongst Other Things).
We mentioned earlier that navigation between activities is managed by Intents. An Intent is a type of message that applications broadcast through the Android OS to interested parties on the phone. Applications then register themselves as listeners for these Intent events using the Android manifest file, and take action accordingly. Used correctly they can be very powerful.
The simplest example of navigating between Activities within an application is to use an Explicit Intent. Using this method, a developer can specify the specific Activity class that they wish to start (for example using the startActivity() method in Activity). This is very straightforward though, and well documented in the Android developer docs. Lets look instead at how one could send an Email using an intent. Here’s a snippet from one of my applications, which makes it easy for users to send diagnostic logs to me:
Intent sendIntent = new Intent(Intent.ACTION_SEND);
// Add attributes to the intent
sendIntent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
sendIntent.putExtra(Intent.EXTRA_SUBJECT, "Log dump from NodeDroid");
sendIntent.putExtra(Intent.EXTRA_EMAIL, new String[] { "android-logs@8bitcloud.com" });
sendIntent.putExtra(Intent.EXTRA_TEXT, "");
sendIntent.setType("application/zip");
sendIntent.putExtra(Intent.EXTRA_STREAM, Uri.fromFile(dumpFile));
startActivity(Intent.createChooser(sendIntent, "Email:"));In this code sample, I’ve created an intent, and given it an action (Intent.ACTION_SEND) and set some extra fields to specify who the email should go to, the subject, and the file attachment. Finally, I call startActivity() to launch the intent. When run, the intent is broadcast to the Android OS, which checks to see which applications can respond to it. If more than one application can respond (which would be quite common in this case), the OS presents the user with a choice of application to handle the intent, and the option as choosing that as the default to use going forward. When a choice is made, the activity is started and the compose screen will be shown.
When writing an application, developers should choose how they will structure their intents so that they can be used by other applications. For example, you might be writing a contact list application. By choosing the right action name and passing the contact ID as additional data in the intent, you make it possible for other applications to load up contact information for a user, rather than your app being a closed box, only accessible to itself.
The Wrap Up
In this article we have explained the way that Android puts together its navigation through using Activities and Tasks. This is all bound together by Android’s powerful Intent system, making it possible to create applications that collaborate on the phone, providing a consistent and intuitive interface for users to use. There are a number of concepts to pick up around Tasks and Activities when developing with Android, but once you’ve got the hang of them it becomes very easy to produce applications that work well with the rest of the system. Personally, I think this is one of the most compelling differentiators for the Android platform.
Frequently Asked Questions (FAQs) about Android Activities, Tasks, and Intents
What is the difference between an Activity and a Task in Android?
In Android, an Activity is a single, focused thing that the user can do. It is a component that provides a user interface for the user to interact with. On the other hand, a Task is a collection of activities that users interact with when performing a certain job. The activities are arranged in a stack—the back stack—in the order in which each activity is opened.
How does the Activity lifecycle work in Android?
The Activity lifecycle in Android is a set of states an Activity can be in during its entire lifetime. These states include Created, Started, Resumed, Paused, Stopped, and Destroyed. Android provides callbacks that will be called when the activity transitions between these states, allowing you to handle the transitions and maintain the state of your activity.
What is an Intent in Android and how does it work?
An Intent in Android is a messaging object that you can use to request an action from another app component. It provides a mechanism for performing late runtime binding between the code in different applications. Its most significant use is in the launching of activities, where it can be thought of as the glue between activities.
How do I start an Activity using an Intent?
To start an Activity, you create an Intent and then call startActivity(intent). The Intent describes the activity to start and carries any necessary data. If you want to receive a result from the activity, you call startActivityForResult(intent, requestCode).
How do I pass data between Activities using Intents?
You can pass data between activities by adding “extras” to the Intent. Extras are key-value pairs that you add to the Intent using the putExtra() method. The key is a string that identifies the data, and the value is the data itself.
What is the role of the manifest file in defining Activities?
The manifest file, AndroidManifest.xml, plays a crucial role in defining activities. It declares all the activities that exist in your application and specifies certain properties such as their parent activity and the categories they handle.
How do I handle the back button in Android Activities?
By default, when the user presses the back button, the current activity is popped from the back stack and destroyed, and the previous activity in the stack is resumed. If you want to handle the back button differently, you can override the onBackPressed() method in your activity.
What is a Context in Android?
A Context in Android is an interface to global information about an application environment. It provides access to resources, databases, preferences, start activities, and more. An Activity is a subclass of Context, so you can use it to perform actions that require a Context.
How do I save the state of an Activity?
You can save the state of an activity by implementing the onSaveInstanceState() callback method. This method gets called before the activity is destroyed, and it gives you a chance to save any state that you want to restore later.
What is a Task Affinity in Android?
Task Affinity in Android is a concept that defines which task an activity prefers to join. By default, all activities in an application have the same affinity and prefer to join the same task. However, you can override this by setting the taskAffinity attribute in the manifest file.
Bruce Cooper is an IT consultant who feels that in order to be able to serve his customers well he should have an understanding of the different technologies that are out there, and how they work. The best way to learn is through doing, so he often takes on small side projects to pick up a new technology.




