
The SEO community boasts a multitude of different opinions as to the volume of text indexed by the search engines on a single Web page. The question is, how large should the optimized page be? At what point is the balance between a page so short that SEs disregard it as “non-informative”, and one that’s so long that it leaves potentially important content beyond the spiders’ attention?
As far as I know, no one has yet tried to answer this question through their own experimentation. The participants of SEO forums typically confine themselves to quoting guidelines published by the engines themselves. Today, the belief that the leading search engines limit the volume of indexed text by the notorious “100 KB” limit is still is still widely held within the SEO community, leaving SEOs’ customers scratching their heads as they try to figure out what to do with the text that extends beyond this limit.
Running the Experiment
When I decided to set up an experiment to answer this question practically, my goals were:
- determine the volume of Web page text actually indexed and cached by the search engines
- find out if the volume of text indexed depends on the overall size of the HTML page
Here’s how this experiment was actually conducted. I took 25 pages of different sizes (from 45 KB to 4151 KB) and inserted unique, non-existent keywords into each page at 10 KB intervals (that is, a unique keyword was included after each 10 KB of text). These keywords were auto-generated exclusively for this experiment and served as “indexation depth marks”. The pages were then published, and I went to make myself some coffee because waiting for the robots to come promised to be a slow process! Finally I saw the bots of the Big Three (Google, Yahoo!, and MSN) in my server logs. The site access logs provided me with the information I needed to proceed with the experiment and finish it successfully.
It’s appropriate to note that I used special, experimental pages for this test. These pages reside on a domain that I have reserved for such experiments, and contain only text with keywords that I needed for the experiment. Such pages — with senseless text stuffed with abracadabra words every now and then — would certainly cause eyebrows to raise, if a human happened to see them. But human visitors were definitely not the expected audience here.
After I reviewed the log files and made sure the bots had dropped in, the only thing left was to check the rankings of each experimental page for each unique keyword I’d used. (I used Web CEO Ranking Checker for this). As you’ve probably guessed, if the search engines index only a certain part of the page, they will return this page in search results for the search terms that are above the scanning limit, but will fail to return the page in results provided for the keywords that appeared below the limit.
Test Results
This chart shows where the Big Three stopped returning my test pages.
![]()
Now that I had the data about the amount of page text downloaded by the SE bots, I could determine the length of page text indexed by the search engines. Believe me, the results are unexpected — to say the least! But this makes it even more pleasant to share them with everyone interested in the burning questions of search engine optimization.
As you can see from the table below, the bronze medal is awarded to Yahoo! with the result of 210 KB. Any page content above this limit won’t be indexed.
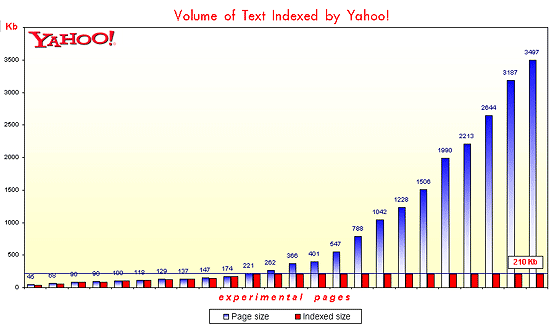
The second place belongs to the Great (by the quality of search) and Dreadful (by its attitude to SEO) Google. Their Googlebot is able to carry away to its innumerable servers more than 600 KB of information. At the same time, Google’s SERPs (search engine result pages) only list pages on which the searched keywords were located not further than 520 KB from the start of the page. This is the exact page size that, in Google’s opinion, is the most informative and provides maximum useful information to visitors without making them dive into overly lengthy text.
This chart shows how much text has been scraped by Google on the test pages.
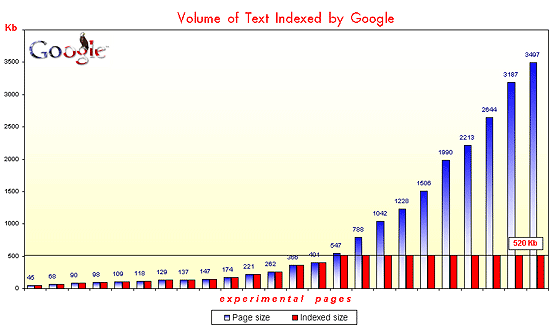
The absolute champion of indexing depth is MSN. Its MSNBot is capable of downloading up to 1.1MB of text from one page. Most importantly, it is able to index all this text and show it in the results pages. If the page size is greater than 1.1MB, the content that appears on the page after this limit is left unindexed.
Here’s how MSN copes with large volumes of text.
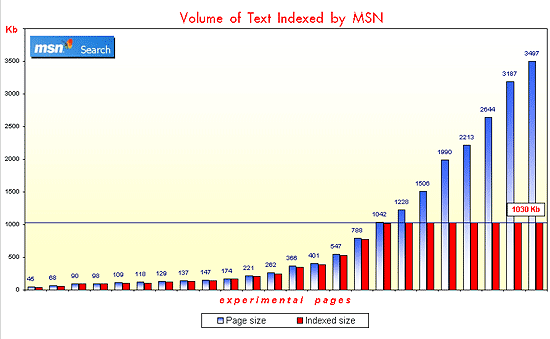
MSN showed a remarkable behavior during its first visit to the experimental pages. If a page was smaller than 170KB, it was well-represented in the SERPs. Any pages above this threshold were not presented in the SERPs for my queries, although the robot had downloaded the full 1.1MB of text. It seems that if a page was above 170KB, it barely had a chance to appear in MSN’s results. However, over a period of 4-5 weeks, the larger pages I’d created started to appear in MSN’s index, revealing the engine’s capacity to index large amounts of text over time. This research makes me think that MSN’s indexing speed depends on the page size. Hence, if you want part of your site’s information to be seen by MSN’s audience a.s.a.p., place it on a page that’s smaller than 170 KB.
This summary chart shows how much information the search engines download, and how much is then stored in their indexes.
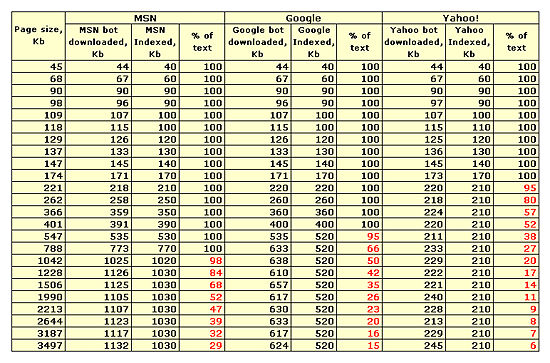
Thus, this experiment established the fact that the leading search engines differ considerably in terms of the the amount of page text they’re able to crawl. For Yahoo!, the limit is 210KB; for Google, 520KB; and for MSN, it’s 1030KB. Pages smaller than these sizes are indexed fully, while any text that extends beyond those limits will not be indexed.
Exceeding the Limits
Is it bad to have text that exceeds the indexing limit?
Definitely not! Having more text than the search engine is able to index will not harm your rankings. What you should be aware of is that such text doesn’t necessarily help your search engine rankings. If the content is needed by your visitors, and provides them with essential information, don’t hesitate to leave it on the page. However, there’s a widespread opinion that the search engines pay more attention to the words situated at the beginning and end of a Web page. In other words, if you have the phrase “tennis ball” in the first and last paragraphs of your copy, it makes your page rank higher for “tennis ball” than if you typed it twice in the middle of the page text.
If you intend to take advantage of this recommendation, but your page is above the indexation limits, the important point to remember is that the “last paragraph” is not where you stopped typing, but where the SE bot stopped reading.
Frequently Asked Questions about Search Engine Indexing
What is the importance of search engine indexing for my website?
Search engine indexing is a crucial process that allows your website to appear in search engine results. When a search engine indexes your site, it’s essentially adding it to its database, making it searchable for users. Without indexing, your website would be invisible to search engines, and consequently, to potential visitors. It’s the first step in achieving visibility and ranking in search engine results, which can drive significant traffic to your site.
How can I check if my website is indexed by search engines?
There are several ways to check if your website is indexed. One of the simplest methods is to use the “site:” operator followed by your website URL in a Google search. If your website pages appear in the search results, it means they are indexed. Alternatively, you can use Google Search Console’s “Coverage” report to see which of your pages have been indexed.
How long does it take for a website to be indexed?
The time it takes for a website to be indexed can vary greatly. It can happen within a few days or take several weeks. Factors that influence this include the quality of your content, your site’s SEO, and how often search engine bots crawl your site. Regularly updating your site with fresh, high-quality content can help speed up the process.
Why are some of my website pages not being indexed?
There could be several reasons why some of your pages are not being indexed. These could include technical issues like broken links or incorrect robots.txt files, poor quality or duplicate content, or a lack of internal links leading to the page. It’s important to regularly audit your website to identify and fix any issues that could be preventing your pages from being indexed.
How can I improve my website’s indexability?
Improving your website’s indexability involves making it easier for search engine bots to crawl and index your site. This can be achieved by ensuring your site has a clear, logical structure, using SEO-friendly URLs, creating a sitemap, and using internal links wisely. Regularly updating your site with fresh, unique content can also encourage search engines to crawl your site more frequently.
What is a robots.txt file and how does it affect indexing?
A robots.txt file is a text file that webmasters use to instruct search engine bots on how to crawl and index pages on their website. It can be used to prevent certain pages from being indexed, such as duplicate pages or pages with sensitive information. However, misuse of the robots.txt file can lead to important pages being left out of the index, so it’s important to use it correctly.
How does mobile-first indexing affect my website?
Mobile-first indexing means that Google predominantly uses the mobile version of your website for indexing and ranking. If your site isn’t mobile-friendly, it could negatively impact your site’s ranking in search engine results. Therefore, it’s important to ensure your site is optimized for mobile devices.
Can I control which pages on my website are indexed?
Yes, you can control which pages on your website are indexed by using a robots.txt file or meta tags. These tools allow you to instruct search engine bots not to index certain pages. However, it’s important to use these tools wisely, as preventing important pages from being indexed can harm your site’s visibility in search engine results.
What is the difference between crawling and indexing?
Crawling and indexing are two distinct steps in the process of making a webpage appear in search engine results. Crawling is when search engine bots scan a webpage to understand what it’s about. Indexing is the next step, where the crawled page is added to a search engine’s database, making it searchable for users.
How does SEO relate to search engine indexing?
SEO (Search Engine Optimization) is a set of strategies aimed at improving a website’s visibility in search engine results. A key part of SEO involves making a website easy to crawl and index by search engines. This includes using relevant keywords, creating high-quality content, and ensuring a website has a clear, logical structure.