
Key Takeaways
- Diffbot is a “visual learning robot” that utilizes machine learning to crawl URLs and visually extract data, providing a more reliable and human-like interpretation of web content than traditional web crawlers.
- The Diffbot API fully renders pages, including JavaScript content, and allows for the extraction of a wide range of data types from web pages, including text, images, videos, and metadata such as the author or publication date.
- The Custom API feature of Diffbot allows users to tweak existing Diffbot APIs or create completely new ones for custom content processing, enabling the extraction of specific data elements from the source code.
Have you ever wondered how social networks do URL previews so well when you share links? How do they know which images to grab, whom to cite as an author, or which tags to attach to the preview? Is it all crawling with complex regexes over source code? Actually, more often than not, it isn’t. Meta information defined in the source can be unreliable, and sites with less than stellar reputation often use them as keyword carriers, attempting to get search engines to rank them higher. Isn’t what we, the humans, see in front of us what matters anyway?
If you want to build a URL preview snippet or a news aggregator, there are many automatic crawlers available online, both proprietary and open source, but you seldom find something as niche as visual machine learning. This is exactly what Diffbot is – a “visual learning robot” which renders a URL you request in full and then visually extracts data, helping itself with some metadata from the page source as needed.
After covering some theory, in this post we’ll do a demo API call at one of SitePoint’s posts.
PHP Library
The PHP library for Diffbot is somewhat out of date, and as such we won’t be using it in this demo. We’ll be performing raw API calls, and in some future posts we’ll build our own library for API interaction.
If you’d like to take a look at the PHP library nonetheless, see here, and if you’re interested in libraries for other languages, Diffbot has a directory.
Update, July 2015: A PHP library has been developed since this article was published. See its entire development process here, or the source code here.
JavaScript Content
We said in the introductory section that Diffbot renders the request in full and then analyzes it. But, what about JavaScript content? Nowadays, websites often render some HTML above the fold, and then finish the CSS, JS, and dynamic content loading afterwards. Can the Diffbot API see that?
As a matter of fact, yes. Diffbot literally renders the page in full, and then inspects it visually, as explained in my StackOverflow Q&A here. There are some caveats, though, so make sure you read the answer carefully.
Pricing and API Health
Diffbot has several usage tiers. There’s a free trial tier which kills your API token after 7 days or 10000 calls, whichever comes first. The commercial tokens can be purchased at various prices, and never expire, but do have limitations. A special case by case approach is afforded to open source and/or educational projects which provides an older model of the free token – 10k calls per month, once per second max, but never expires. You need to contact them directly if you think you qualify.
Diffbot guarantees a high uptime, but failures sometimes do happen – especially in the most resource intensive API of the bunch: Crawlbot. Crawlbot is used to crawl entire domains, not just individual pages, and as such has a lower reliability rate than other APIs. Not by a lot, but enough to be noticeable in the API Health screen – the screen you can check to see if an API is up and running or currently unavailable if your calls run into issues or return error 500.
Demo
To prepare your environment, please boot up a Homestead Improved instance.
Create Project
Create a starter Laravel project by SSHing into the VM with vagrant ssh, going into the Code folder, and executing composer create-project laravel/laravel Laravel --prefer-dist. This will let you access the Laravel greeting page via http://homestead.app:8000 from the host’s browser.
Add a Route and Action
In app/routes.php add the following route:
Route::get('/diffbot', 'HomeController@diffbotDemo');
In app/controllers/HomeController add the following action:
public function diffbotDemo() {
die("hi");
}
If http://homestead.app:8000/diffbot now outputs “hi” on the screen, we’re ready to start playing with the API.
Get a Token
To interact with the Diffbot API, you need a token. Sign up for one on their pricing page. For the sake of this demo, let’s call our token $TOKEN, and we’ll refer to it as such in URLs. Replace $TOKEN with your own value where appropriate.
Install Guzzle
We’ll be using Guzzle as our HTTP client. It’s not required, but I do recommend you get familiar with it through a past article of ours.
Add the "guzzlehttp/guzzle": "4.1.*@dev" to your composer.json so the require block looks like this:
"require": {
"laravel/framework": "4.2.*",
"guzzlehttp/guzzle": "4.1.*@dev"
},
In the project root, run composer update.
Fetch Article Data
In the first example, we’ll crawl a SitePoint post with the default Article API from Diffbot. To do this, we refer to the docs which do an excellent job at explaining the workflow. Change the body of the diffbotDemo action to the following code:
public function diffbotDemo() {
$token = "$TOKEN";
$version = 'v3';
$client = new GuzzleHttp\Client(['base_url' => 'http://api.diffbot.com/']);
$response = $client->get($version.'/article', ['query' => [
'token' => $token,
'url' => 'https://www.sitepoint.com/7-mistakes-commonly-made-php-developers/'
]]);
die(var_dump($response->json()));
}
First, we set our token. Then, we define a variable that’ll hold the API version. Next, it’s up to us to create a new Guzzle client, and we also give it a base URL so we don’t have to type it in every time we make another request.
Next up, we create a response object by sending a GET request to the API’s URL, and we add in an array of query parameters in key => value format. In this case, we only pass in the token and the URL, the most basic of parameters.
Finally, since the Diffbot API returns JSON data, we use Guzzle’s json() method to automatically decode it into an array. We then pretty-print this data:
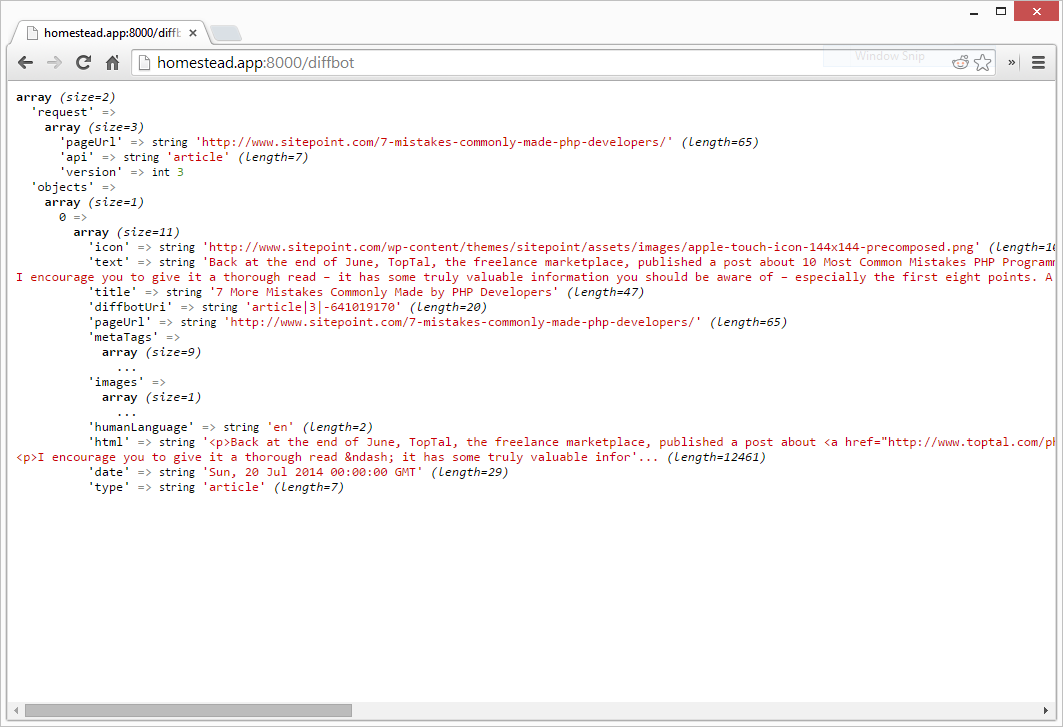
As you can see, we got some information back rather quickly. There’s the icon that was used, a preview of the text, the title, even the language, date and HTML have been returned. You’ll notice there’s no author, however. Let’s change this and request some more values.
If we add the “fields” parameter to the query params list and give it a value of “tags”, Diffbot will attempt to extract tags/categories from the URL provided. Add this line to the query array:
'fields' => 'tags'
and then change the die part to this:
$data = $response->json();
die(var_dump($data['objects'][0]['tags']));
Refreshing the screen now gives us this:
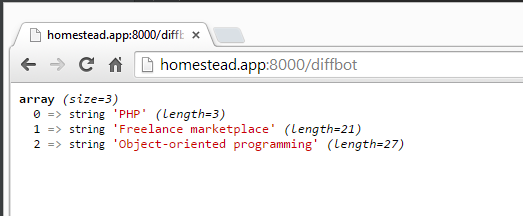
But, the source code of the article notes several other tags:
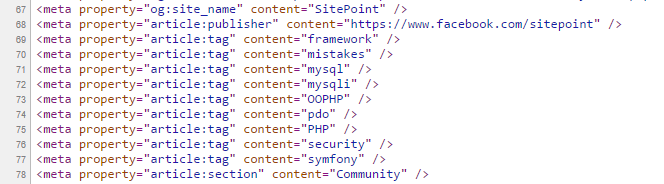
Why is the result so very different? It’s precisely due to the reason we mentioned at the end of the very first paragraph of this post: what we humans see takes precedence. Diffbot is a visual learning robot, and as such its AI deducts the tags from the actual rendered content – what it can see – rather than from looking at the source code which is far too easily spiced up for SEO purposes.
Is there a way to get the tags from the source code, though, if one really needs them? Furthermore, can we make Diffbot recognize the author on SitePoint articles? Yes. With the Custom API.
Meta Tags and Author with Custom API
The Custom API is a feature which allows you to not only tweak existing Diffbot API to your liking by adding new fields and rules for content extraction, but also allows you to create completely new APIs (accessed via a dedicated URL, too) for custom content processing.
Go to the dev dashboard and log in with your token. Then, go into “Custom API”. Activate the “Create a Rule” tab at the bottom, and input the URL of the article we’re crawling into the URL box, then click Test. Your screen should look something like this:
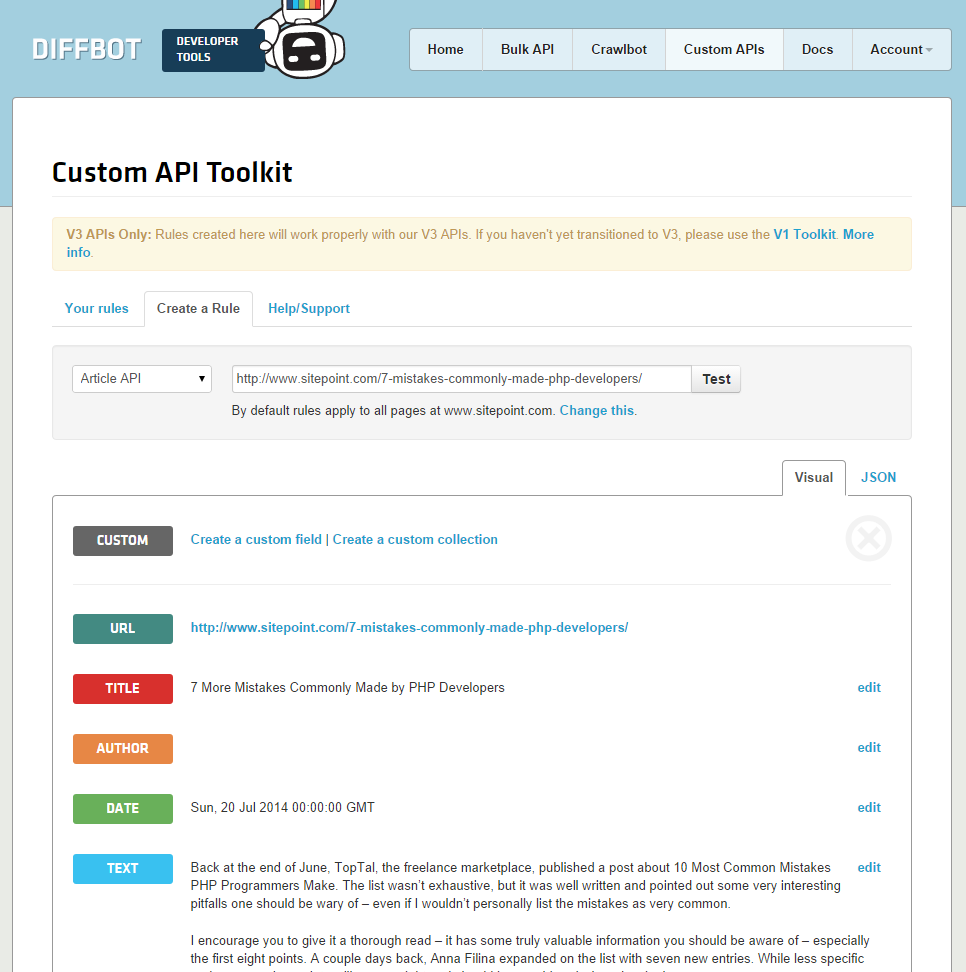
You’ll immediately notice the Author field is empty. You can tweak the author-searching rule by clicking Edit next to it, and finding the Author element in the live preview window that opens, then click on it to get the desired result. However, due to some, well, less than perfect CSS on SitePoint’s end, it’s very difficult to provide Diffbot’s API with a consistent path to the author name, especially by clicking on elements. Instead, add the following rule manually: .contributor--large .contributor_name a and click Save.
You’ll notice the Preview window now correctly populates the Author field:
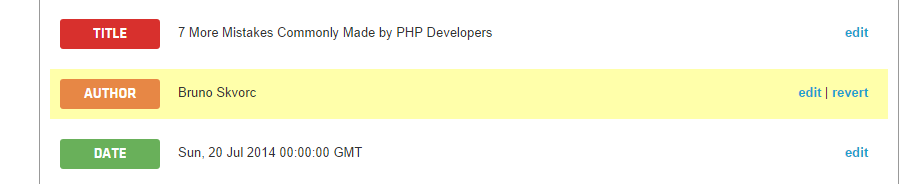
In fact, this new rule is automatically applied to all SitePoint links for your token. If you try to preview another SitePoint article, like this one, you’ll notice Peter Nijssen is successfully extracted:
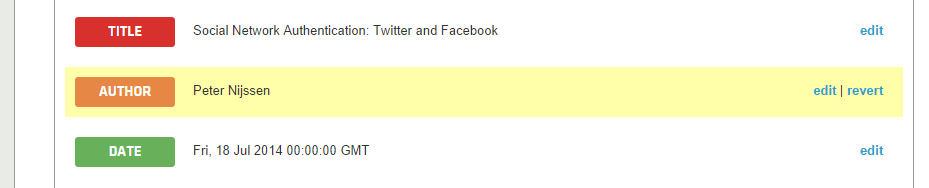
Ok, let’s modify the API further. We need the article:tag values that are visible in source code. Doing this requires a two-step process.
Step 1: Define a Collection
A collection is exactly what it sounds like – a collection of values grabbed via a specific ruleset. We’ll call our collection “MetaTags”, and give it the following selector: meta[property=article:tag]. This means “find all meta elements in the HTML that have the property attribute with the value article:tag“.
Step 2: Define Collection Fields
Collection fields are individual entries in a collection – in our case, the various tags. Click on “Add a custom field to this collection”, and add the following values:
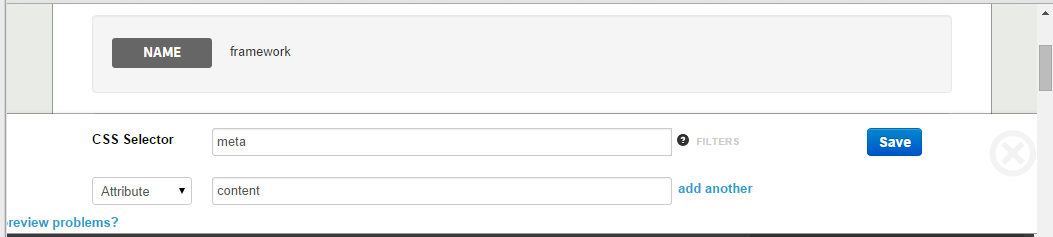
Click Save. You’ll immediately have access to the list of Tags in the result window:
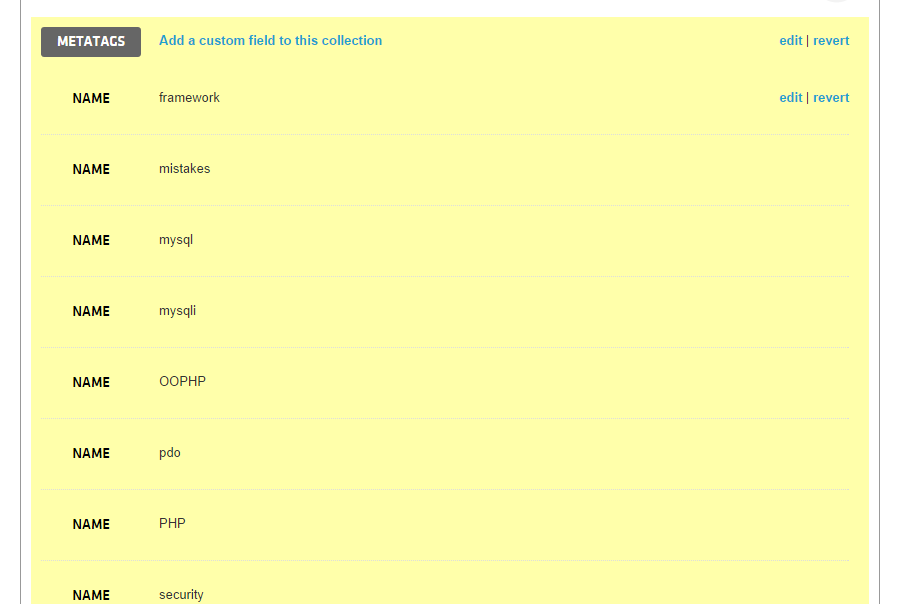
Change the final output of the diffbotDemo() action to this:
die(var_dump($data['objects'][0]['metaTags']));
If you now refresh the URL we tested with (http://homestead.app:8000/diffbot), you’ll notice the author and meta tags values are there. Here’s the output the above line of code produces:
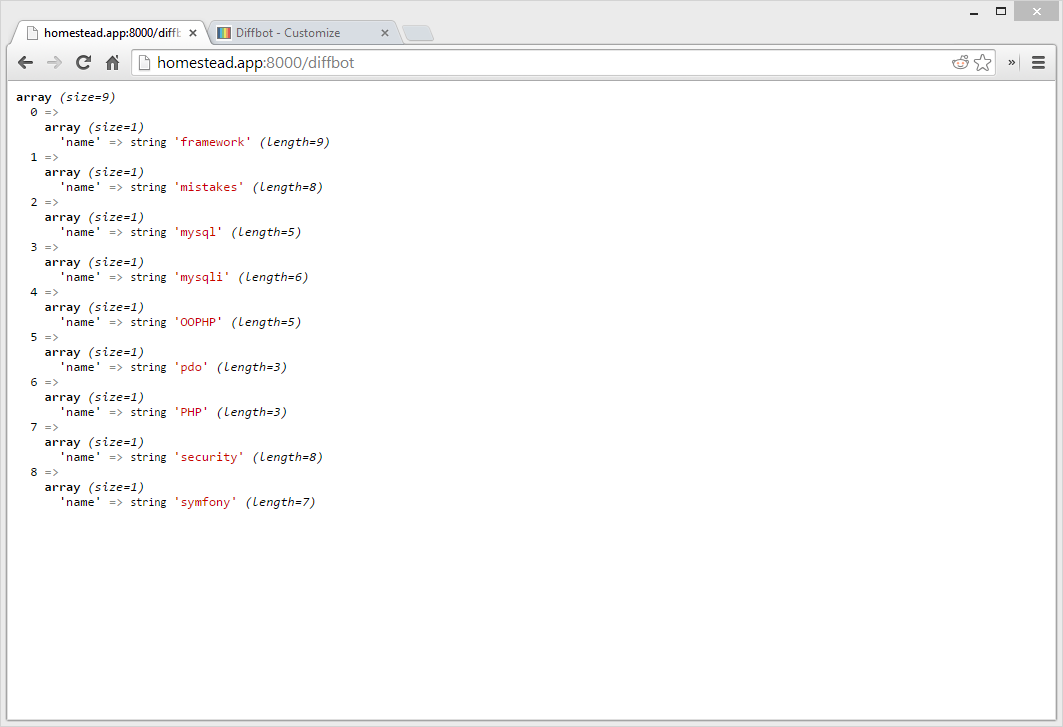
We have our tags!
Conclusion
Diffbot is a powerful data extractor for the web – whether you need to consolidate many sites into a single search index without combining their back-ends, want to build a news aggregator, have an idea for a URL preview web component, or want to regularly harvest the contents of competitors’ public pricing lists, Diffbot can help. With dead simple API calls and highly structured responses, you’ll be up and running in next to no time. In a later article, we’ll build a brand new API for using Diffbot with PHP, and redo the calls above with it. We’ll also host the library on Packagist, so you can easily install it with Composer. Stay tuned!
Frequently Asked Questions (FAQs) about Diffbot
What is the primary function of Diffbot?
Diffbot is a web scraping tool that uses machine learning technology to extract and analyze data from web pages. It’s designed to understand web pages in the same way a human would, making it a powerful tool for data extraction. Diffbot can be used to gather data from social media sites, news articles, product pages, and more. It’s particularly useful for businesses that need to gather large amounts of data quickly and accurately.
How does Diffbot’s machine learning technology work?
Diffbot uses a form of artificial intelligence known as machine learning to understand and interpret web pages. It uses algorithms to analyze the structure and content of a web page, then extracts relevant data based on that analysis. This allows Diffbot to understand web pages in a way that’s similar to how a human would, making it a powerful tool for data extraction.
What types of data can Diffbot extract?
Diffbot can extract a wide range of data types from web pages. This includes text, images, videos, and more. It can also extract metadata, such as the author of a web page or the date it was published. This makes Diffbot a versatile tool for data extraction, capable of gathering a wide range of information from the web.
How accurate is Diffbot’s data extraction?
Diffbot’s data extraction is highly accurate, thanks to its use of machine learning technology. It’s designed to understand web pages in the same way a human would, which allows it to accurately identify and extract relevant data. However, like any tool, its accuracy can depend on the complexity of the web page and the type of data being extracted.
Can Diffbot extract data from social media sites?
Yes, Diffbot can extract data from social media sites. This includes sites like Facebook, Twitter, and LinkedIn. It can gather data such as posts, comments, likes, and shares, making it a useful tool for social media analysis and marketing research.
Is Diffbot easy to use?
Diffbot is designed to be user-friendly, with a straightforward interface and clear instructions. However, like any tool, there may be a learning curve for new users. Fortunately, Diffbot offers a range of resources to help users get started, including tutorials and customer support.
Can Diffbot handle large amounts of data?
Yes, Diffbot is designed to handle large amounts of data. It’s a powerful tool for businesses that need to gather and analyze large volumes of data quickly and accurately. Diffbot’s machine learning technology allows it to process data quickly, making it a valuable tool for big data projects.
What industries can benefit from using Diffbot?
A wide range of industries can benefit from using Diffbot. This includes marketing, research, journalism, e-commerce, and more. Any industry that relies on gathering and analyzing data from the web can potentially benefit from using Diffbot.
How does Diffbot compare to other data extraction tools?
Diffbot stands out from other data extraction tools thanks to its use of machine learning technology. This allows it to understand and interpret web pages in a way that’s similar to how a human would, making it a powerful and accurate tool for data extraction. However, like any tool, its effectiveness can depend on the specific needs of the user.
Is Diffbot a reliable tool for data extraction?
Yes, Diffbot is a reliable tool for data extraction. It’s used by a wide range of businesses and industries to gather and analyze data from the web. Its use of machine learning technology allows it to accurately extract relevant data, making it a trusted tool for data extraction.