
I’m sure you’ve seen them many times — those wild squiggles that need to be deciphered and typed into a text box before you can buy concert tickets online or access a comment form.
CAPTCHAs are generally one or two words presented as graphics, overlaid with some kind of distortion, and they function as a test that relies on your human ability to recognize them. CAPTCHA stands for “Completely Automated Public Turing test to tell Computers and Humans Apart.” This is a misnomer, because a CAPTCHA isn’t a Turing test — but we’ll come back to that later!
The CAPTCHA innovation was pioneered by developers at Carnegie Mellon University. The idea behind it was to develop a means of distinguishing between people and web robots, so that web sites could offer their resources to individual humans without being exploited by robots.
Key Takeaways
- CAPTCHAs, originally designed to differentiate humans from bots, often fail to accommodate users with disabilities and can be cracked by sophisticated software, highlighting a significant accessibility and security issue.
- Alternatives to CAPTCHA, such as non-linguistic visual tests, audio tests, and logical puzzles, attempt to address these shortcomings but still present challenges in universal accessibility and security effectiveness.
- Non-interactive solutions like honeypots and session keys offer a layer of protection by analyzing data submission behavior to detect bots, potentially reducing the burden on users.
- Advanced spam filtering techniques and centralized sign-on systems like OpenID provide promising approaches to enhance security without compromising user accessibility, although they come with their own set of challenges.
- The ongoing evolution of bot detection and user authentication methods suggests a need for continuous innovation in security technologies to effectively protect online resources while ensuring a fair and accessible user experience.
The Need for CAPTCHA (or Something)
Site owners face a number of unique challenges in protecting their resources from automated harvesting. These include:
- Resources may be expensive to provide, and machines can consume far more data far more quickly than humans. Therefore, services that are machine-accessible may prove prohibitively expensive to maintain.
- Allowing bots to post comments and user-generated content opens a floodgate for spammers, which inevitably results in massive volumes of spam — often to the point where a service becomes unuseable.
- Data may be highly sensitive, such as personal medical or financial information, and needs to be sufficiently protected to prevent against attacks from data-mining robots.
- Interactions with a system may have fundamental implications for society as a whole; consider the issues that would arise in the case of electronic voting.
The Problem with CAPTCHA
CAPTCHA systems create a significant accessibility barrier, since they require the user to be able to see and understand shapes that may be very distorted and difficult to read. A CAPTCHA is therefore difficult or impossible for people who are blind or partially sighted, or have a cognitive disability such as dyslexia, to translate into the plain text box.
And of course there can be no plain-text equivalent for such an image, because that alternative would be readable by machines and therefore undermine the original purpose.
Since users with these disabilities are unable to perform critical tasks, such as creating accounts or making purchases, the CAPTCHA system can clearly be seen to fail this group.
Such a system is also eminently crackable. A CAPTCHA can be understood by suitably sophisticated scanning and character recognition software, such as that employed by postal systems the world over to recognize handwritten zip or postal codes. Or images can be aggregated and fed to a human, who can manually process thousands of such images in a day to create a database of known images — which can then be easily identified.
Recent high-profile cases of bots cracking the CAPTCHA system on Windows Live Hotmail and Gmail have highlighted the issue, as spammers created thousands of bogus accounts and flooded the systems with junk. Even more recently, security firm Websense Security Labs have reported that the Windows Live CAPTCHA can be cracked in as little as 60 seconds.
One CAPTCHA-cracking project, called PWNtcha (“Pretend We’re Not a Turing Computer but a Human Antagonist”), reports success rates between 49% and 100% at cracking some of the most popular systems, including 99% for the system used by LiveJournal, and 88% for that employed by PayPal.
Thus, the growth and proliferation of CAPTCHA systems should be taken less as evidence of their success than as evidence of the human propensity to be comforted by things that provide a false sense of security.
It’s ironic that CAPTCHA can be defeated by those who are sufficiently motivated, when they’re the very same people the test is designed to protect against. Just like DRM, CAPTCHA systems ultimately fail to protect against the original threat, while simultaneously inconveniencing ordinary users.
Heck, I find them difficult to read, and I have perfect 20/20 vision. When I signed up for my Facebook account I had to try five different images and two different browsers until I got my application through. Tedious in the extreme.
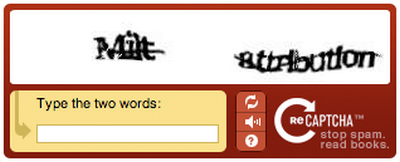
Just try this example.
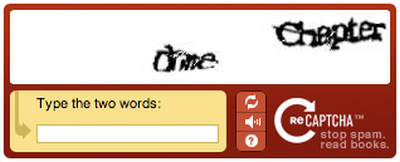
What does that first word say? “One”? “Dime”? I have no idea. To take it even further, have a look at this illustration from Matt May‘s presentation Escape from CAPTCHA, and see how well you’d be able to deal with it!

The problem could be seen more philosophically, as a question of “how does a machine recognize a human.” So in that sense, a CAPTCHA is more like a reverse Turing test, since a Turing test is about computers fooling humans, rather than humans fooling computers. But a true Turing test is about machine intelligence, whereas all a CAPTCHA tests is perceptual comprehension (which a real human can fail as easily as a machine can pass); really, a CAPTCHA isn’t a Turing test at all.
Alternatives to CAPTCHA
The purpose of CAPTCHA systems is to protect resources from bots while allowing access to humans, but they fail to do either of those things.
On the other hand, anyone who’s used such a system on a high-traffic site knows that they do make a difference. Abandoning them increases the volume of unwanted traffic, sometimes to an unmanageable extent.
Clearly there’s a need for something. So what are the alternatives to CAPTCHA?
Non-linguistic Visual Tests
Tests that use images other than words may be generally easier for users, since all they have to do is comprehend an undistorted picture, rather than decode distorted language. A prominent (and, I believe, pioneering) example of this is KittenAuth:

The system shows you a set of nine images, three of which are kittens. You have to identify the three kittens in order to pass authentication.
Although the failure rate for regular humans may be lower, and their comprehension by people with cognitive disabilities may be better, they still let down users who are blind or partially sighted. They also require a basic level of knowledge — you have to know what a kitten looks like. It’s easy to take that much for granted, but it remains a highly cultural assumption; you might know, but can you be absolutely sure that all of your users do?
This idea has also been taken to more frivolous places, such as a system based on the somewhat dubious “hot or not” tests, shown here.

Some may find that version funny, others may find it offensive. Either way, it’s no use as a genuine authentication system. The answers are arbitrary, and in any case, they can be mined programmatically from the Hot-or-Not web site!
Audio Tests
An alternative to a visual CAPTCHA test is an audio test, where a series of words or letters are spoken out loud and offered to users as an audio file; this audio is also overlaid with distortion of some kind, in the same attempt to prevent programmatic decoding.
However, such tests have exactly the same issues as visual CAPTCHAS. They solve the visual issue, sure, but they do so by introducing another, equally problematic barrier. People who are deaf and blind, who work in a noisy environment, lack the necessary hardware for sound output, or are unable to understand the sound due to a cognitive disability, or even a language barrier, are no better supported than with a conventional visual test.
Also, audio tests are as equally vulnerable to being cracked by suitably motivated bot programmers as visual ones.
Logical or Semantic Puzzles
Eric Meyer‘s Gatekeeper plugin for WordPress works by asking a simple question, framed in such a way as to make it extremely difficult for machines to understand while blatantly obvious to humans. Would you get this one?
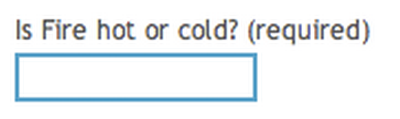
Other questions might be “What color is an orange?” or “How many sides has a triangle?”
The Achilles heel of this system is its scope. It has a limited number of questions and answers and is therefore vulnerable to brute-force attack. That problem can be reduced — but not solved completely — using flood-control (preventing a single user from making multiple attempts within a certain timeframe) and by ensuring that the selection of questions is large and frequently changed.
But the system is also underpinned by assumptions of knowledge. Ideally, the questions should be so simple that a child could answer them easily — as is certainly the case in this example. But for every question, we still have to assume that any human can answer it, which may not be true, especially when you factor cognitive disability or language barriers into the equation.
And as a system such as this proliferates, it may become increasingly difficult to think of good questions. We might end up resorting to jokes!

Unfortunately a system based on multiple choices like this would be very weak, because simple guesswork would produce a crack rate of 33%. Yet if we allowed freeform answers to a question like that, there’s far too much of an assumed-knowledge overhead — the user would have to recognize the joke, and then give an answer that the system can comprehend as correct.
Individual Authentication
For the highest level of security, individual authorization is always required. To log in to online banking, pay a credit-card bill, or vote, the system needs to know not just that you’re a human, but that you’re a specific human.
This kind of authentication could be harnessed to provide a lower level of certainty in more general applications, as authentication for a system where your specific identify is not required — only that you’re a person.
The simplest approach here is to require users to register before being able to comment, post, or add content to a site. This certainly reduces the amount of casual spam that a system might get, but it does nothing to put off a determined spammer who’s prepared to take the time to create an account.
It’s not difficult to find large numbers of people prepared to do this kind of work for next to nothing, given the wide range of living costs across the world economy. It would be trivially cheap for a spammer in a rich country to pay people in a poor country to do this kind of work all day.
Centralized Sign-on
A system of centralized sign-on can mitigate the potential for abuse by putting all the impetus on a single system to authenticate users once, and then give them free rein thereafter.
Systems such as Microsoft Passport offer this kind of centralization; however, they also create significant privacy questions, as you have to be prepared to trust your personal data to a single, commercial entity (quite apart from the fact that Passport uses CAPTCHA authentication!).
However, a most promising alternative to this has recently begun to gain traction, in the form of OpenID. The OpenID system avoids privacy issues because it isn’t limited to a single authentication provider — you can pick and choose, and change at any time, who you trust to hold your authentication information. This information in turn is not revealed to the site you’re visiting; therefore, it offers a convenient means of centralized authentication without the attendant privacy issues.
The weak point of the system is how you obtain an OpenID in the first place, since some form of authentication is going to be required there. Simply having an OpenID is not enough to prove that you’re a legitimate user, so the onus would end up being on individual sites or OpenID providers to police the use of OpenID; for example, by banning OpenIDs that are known to be spammers. This in itself could end up being a minefield for disputes.
OpenID is a good idea, and is bound to catch on, but in itself does not address the issue at hand any better than individual authentication.
Non-interactive Solutions
We’ve looked at a number of interactive solutions now, and seen how none of them are entirely perfect, either for protection from robot attack, or for reliably identifying humans without introducing accessibility barriers.
Perhaps the solution lies with non-interactive solutions. These analyze data as it’s being submitted, rather than relying on users to authenticate themselves.
Honey Traps
The idea here is that you include a form field, which is hidden with CSS, and give it a name that encourages spam bots to fill it in, such as “email2.” The human user will never fill it in because they don’t know it’s there, but the bot won’t be able to tell the difference. Therefore, if that field contains any value when the form is submitted, the submission is rejected.
The problem is that assistive technologies may not be able to tell the difference either, and so their users may not know not to fill it in. That possibility could be reduced with descriptive text, such as “do not complete this field,” but doing that may be very confusing, as well as being recognizable by a bot.
Another variant of this is a simple trap that asks human users to confirm they’re not robots. This could take the form of a checkbox, like this one.
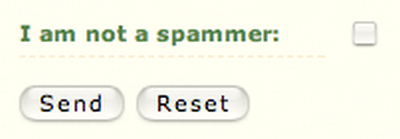
In both these examples, however, bots could learn to recognize the trap and thereby circumvent it. It’s one of those things that only works as long as not many people are using it — as soon as it became prevalent, on high-traffic sites like Digg or Facebook, the spammers would simply adapt.
Session Keys
A partial solution for form submission is to generate a session key on the fly when building the original form, and then check that session key when the form is submitted. This will prevent bots that bypass the form and post directly to its target, but it does nothing to stop bots that go through the regular web form.
Spam Filtering and Heuristics
Systems that accept user-generated content (such as blog comments) can filter content based on specific keywords (like “Viagra”), or using Bayesian filters to recognize patterns that might indicate spam. Such systems are already used by the vast majority of email systems, and are highly effective in reducing spam.
More sophisticated systems use a combination of filtering and heuristics that identify spam by additional factors, such as how quickly a comment was posted. One popular system is Spam Karma, which produces reports like this one.
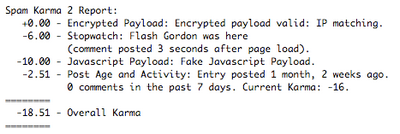
The report shows how a number of factors contribute to an overall “karma” score: posts with a low enough score are automatically rejected (and the admin is sent an email like the above).
It’s a misunderstanding of the nature of Karma to think that it can apply to individuals. Philosophical meanderings aside, this is a highly effective system that can make a huge difference to the spam overhead a site admin has to deal with.
There’s also a third-party service called Akismet, which works on the same principle of content filtering using keywords and heuristics. Since the system is managed centrally it has a much larger base of data to work from, which should make its assessments far more reliable — with a lower chance of spam getting through or of making a “false positive” (identifying as spam something which is legitimate).
Limited-use Accounts
One way for a system such as free email to limit abuse by robots is to deliberately throttle new accounts for a period of time; for example, by only allowing ten emails to be sent per day for the first month.
However, this approach may not ultimately help. It may reduce the incidence of abuse on a per-account basis, but it doesn’t prevent abuse entirely. There’s also nothing to stop a spammer from simply signing up for thousands of accounts and sending ten spam emails from each one. And of course, such a limitation may affect legitimate users as well, but legitimate users aren’t going to be inclined to sign up for multiple accounts.
Conclusion
The conclusion? Don’t make users take responsibility for our problems.
Bots, and the damage they cause, are not the fault or responsibility of individual users, and it’s totally unfair to expect them to take the responsibility. They’re not the fault of site owners either, but like it or not they are our responsibility — it’s we who suffer from them, we who benefit from their eradication, and therefore we who should shoulder the burden. And using interactive authentication systems such as CAPTCHA effectively passes the buck from us to our users.
Moreover, the common theme with all interactive alternatives is that they fail users who have a cognitive disability, or don’t understand the same cultural cues as the author, or use assistive technologies. The more stringent the system, the higher the bar is raised and therefore the greater the chance of failing to recognize or admit a real human.
In my view, the right way to address this problem is with non-interactive solutions that ordinary users don’t even need to be aware of. Systems such as Spam Karma and Akismet are highly effective at reducing the amount of spam that site administrators have to deal with. In fact, we use Spam Karma here at SitePoint, and it does make a significant difference.
The Future
It’s clear that both interactive and non-interactive tests will continue to be used by site owners for the foreseeable future. Developers will try to come up with new and better tests, and spammers will continue to find ways of cracking them; it’s very much a vicious circle.
Perhaps, at some point in the future, somebody will come up with a test that is truly reliable and uncrackable — something that identifies humans in a way that cannot be faked. Maybe biometric data such as fingerprints or retina scans could factor into that somewhere; perhaps we’ll have direct neural interfaces that identify the presence of brain activity.
Personally, I’m still hoping for telepathic XML!
Frequently Asked Questions (FAQs) about CAPTCHA Problems and Alternatives
What are the common problems associated with CAPTCHA?
CAPTCHA, which stands for Completely Automated Public Turing test to tell Computers and Humans Apart, is a popular tool used to prevent bots from accessing websites. However, it’s not without its issues. The most common problems associated with CAPTCHA include difficulty in deciphering the distorted text, accessibility issues for visually impaired users, and the inconvenience it poses to users, which can lead to a poor user experience. Additionally, sophisticated bots can now bypass CAPTCHA, rendering it less effective.
What are some alternatives to CAPTCHA?
Given the problems associated with CAPTCHA, several alternatives have been developed. These include biometric authentication, which uses unique human characteristics like fingerprints or facial recognition; two-factor authentication, which requires users to provide two different types of identification; and behavioral analysis, which monitors user behavior to distinguish between humans and bots. Other alternatives include honeypots, time analysis, and user interaction-based methods.
How does biometric authentication work as an alternative to CAPTCHA?
Biometric authentication is a security process that relies on the unique biological characteristics of an individual to verify their identity. This could be anything from a fingerprint scan, facial recognition, or even voice recognition. The main advantage of this method is that it’s extremely difficult for bots to mimic these unique human characteristics, making it a highly secure alternative to CAPTCHA.
What is two-factor authentication and how does it work?
Two-factor authentication (2FA) is a security measure that requires users to provide two different types of identification to access a website or service. Typically, this involves something the user knows (like a password) and something they have (like a mobile device to receive a verification code). This method is more secure than traditional password-only approaches and is a viable alternative to CAPTCHA.
How does behavioral analysis work in distinguishing between humans and bots?
Behavioral analysis is a method that monitors user behavior to distinguish between humans and bots. It involves tracking and analyzing various user interactions, such as mouse movements, keystrokes, and browsing patterns. Since bots and humans interact with websites differently, this method can effectively identify and block bot traffic.
What is a honeypot and how does it work as a CAPTCHA alternative?
A honeypot is a security mechanism designed to lure and trap bots. It involves creating invisible form fields on a website that are only visible to bots. Since humans can’t see these fields, they won’t interact with them. However, bots, which automatically fill out all form fields, will interact with the honeypot, revealing themselves and allowing the website to block them.
How does time analysis work as a CAPTCHA alternative?
Time analysis is a method that measures the time it takes for a user to complete certain actions on a website. Since bots typically complete actions much faster than humans, this method can be used to identify and block bot traffic. However, it’s not foolproof, as some sophisticated bots can mimic human-like interaction speeds.
What are user interaction-based methods?
User interaction-based methods involve analyzing how users interact with a website to distinguish between humans and bots. This could involve tracking mouse movements, keystrokes, and even how users scroll through a page. Since bots and humans interact with websites differently, these methods can effectively identify and block bot traffic.
Are CAPTCHA alternatives more effective than CAPTCHA itself?
While CAPTCHA has been a popular tool for preventing bot access, its effectiveness has been questioned due to the emergence of sophisticated bots that can bypass it. CAPTCHA alternatives like biometric authentication, two-factor authentication, and behavioral analysis offer more secure ways to distinguish between humans and bots. However, the effectiveness of these alternatives can vary and depends on the specific method used and the sophistication of the bots.
What factors should I consider when choosing a CAPTCHA alternative?
When choosing a CAPTCHA alternative, consider factors like the level of security it offers, its impact on user experience, its accessibility, and its ease of implementation. It’s also important to consider the type of website or service it will be used for, as different methods may be more suitable for different types of sites.