


Large organizations and enterprises often store data in spreadsheets and require an interface for entering this data into their web apps. The general idea is to upload the file, read its contents, and store it either in files or databases that the web application uses. Organizations may also need to export data from a web app. For example, they might need to export the grades of all students in a class. Again, spreadsheets are the preferred medium.
In this post, we’ll discuss different ways to handle these files and parse them to get the required information using Python.
Key Takeaways
- Python, with the help of libraries like Pandas and openpyxl, can be used to parse spreadsheet data, including reading and writing XLSX files, CSV files, and legacy spreadsheets. This allows for easy manipulation and analysis of data stored in these formats.
- The process of reading spreadsheets involves importing the pandas module, opening the spreadsheet file, selecting a specific sheet, and extracting the values of particular data cells. Pandas reads the spreadsheet as a table and stores it as a dataframe, which can then be queried to extract specific data.
- Creating spreadsheets follows a similar process, where a dataframe is first created and saved into a workbook, a sheet is created within the workbook, and data is added to the cells in the workbook. The ExcelWriter class in pandas provides additional options for saving data to spreadsheets, including appending dataframes to existing spreadsheets and setting date and time values.
A Quick Spreadsheet Primer
Before parsing spreadsheets, you must understand how they’re structured. A spreadsheet file is a collection of sheets, and each sheet is a collection of data cells placed in a grid, similar to a table. In a sheet, a data cell is identified by two values: its row and column numbers.
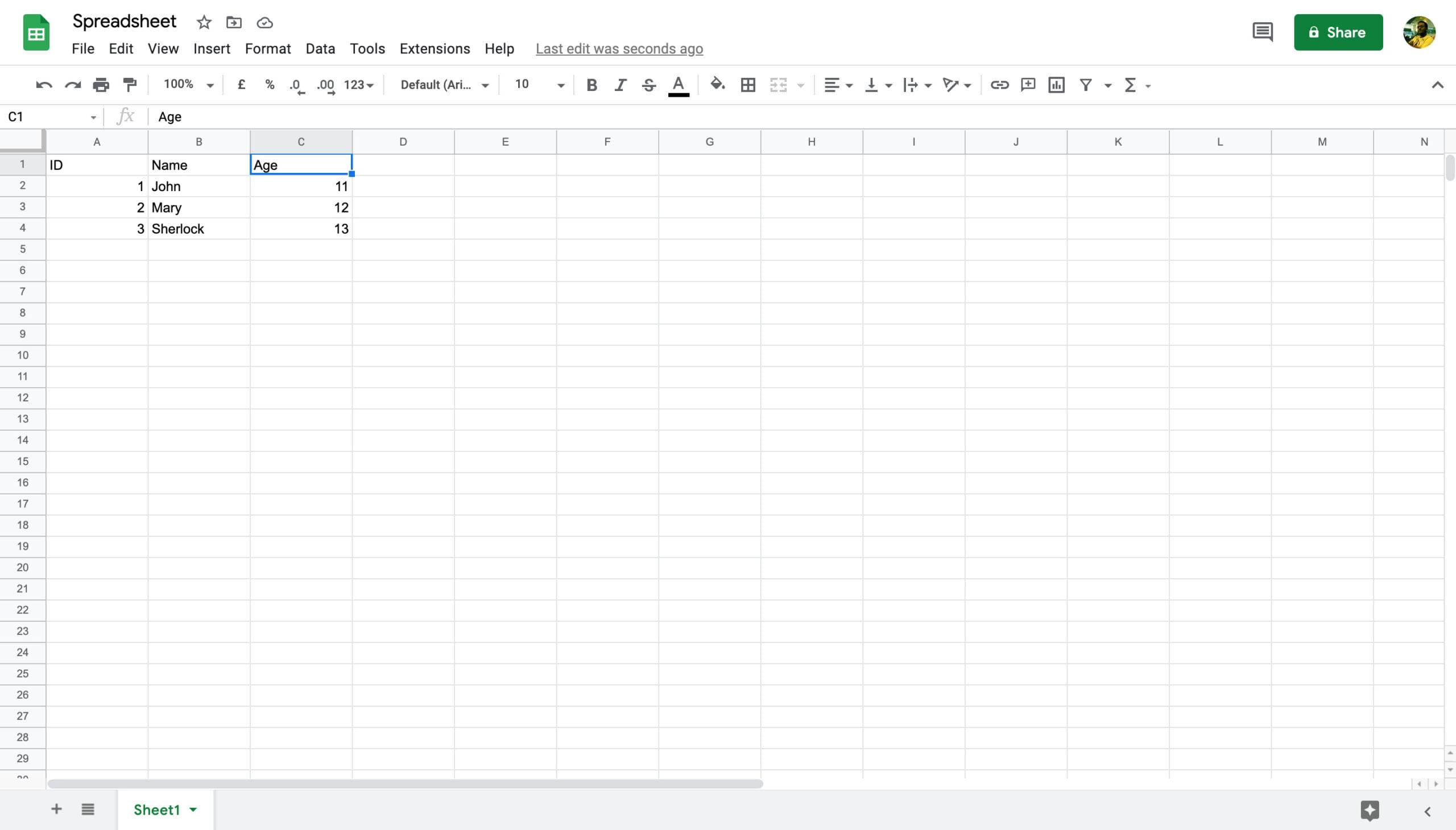
For instance, in the screenshot above, the spreadsheet contains only one sheet, “Sheet1”. The cell “2A” corresponds to the second row and first column. The value of cell 2A is 1.
Although programs with a GUI assign letters to the names of columns, when we parse the data, we will start row and column numbers from 0. That means, cell 2A will correspond to (1, 0), 4B to (1,3), 3C to (2, 2), and so on.
Setting up the Python Environment
We’ll use Python 3 to read and write spreadsheets. To read and write XLSX files, you need to install the Pandas module. You can do so through one of the Python installers: pip or easy_install. Pandas uses the openpyxl module to read new spreadsheet (.xlsx) files, and xlrd modules to read legacy spreadsheets (.xls files). Both these openpyxl and xlrd are installed as dependencies when you install Pandas:
pip3 install pandas
To read and write CSV files, you need the csv module, which comes pre-installed with Python. You can also read CSV files through Pandas.
Reading Spreadsheets
If you have a file and you want to parse the data in it, you need to perform the following in this order:
- import the
pandasmodule - open the spreadsheet file (or workbook)
- select a sheet
- extract the values of particular data cells
Open a spreadsheet file
Let’s first open a file in Python. To follow along you can use the following sample spreadsheet, courtesy of Learning Container:
import pandas as pd
workbook = pd.read_excel('sample-xlsx-file-for-testing.xlsx')
workbook.head()
| Segment | Country | Product | Discount Band | Units Sold | Manufacturing Price | Sale Price | Gross Sales | Discounts | Sales | COGS | Profit | Date | Month Number | Month Name | Year | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Government | Canada | Carretera | None | 1618.5 | 3 | 20 | 32370.0 | 0.0 | 32370.0 | 16185.0 | 16185.0 | 2014-01-01 | 1 | January | 2014 |
| 1 | Government | Germany | Carretera | None | 1321.0 | 3 | 20 | 26420.0 | 0.0 | 26420.0 | 13210.0 | 13210.0 | 2014-01-01 | 1 | January | 2014 |
| 2 | Midmarket | France | Carretera | None | 2178.0 | 3 | 15 | 32670.0 | 0.0 | 32670.0 | 21780.0 | 10890.0 | 2014-06-01 | 6 | June | 2014 |
| 3 | Midmarket | Germany | Carretera | None | 888.0 | 3 | 15 | 13320.0 | 0.0 | 13320.0 | 8880.0 | 4440.0 | 2014-06-01 | 6 | June | 2014 |
| 4 | Midmarket | Mexico | Carretera | None | 2470.0 | 3 | 15 | 37050.0 | 0.0 | 37050.0 | 24700.0 | 12350.0 | 2014-06-01 | 6 | June | 2014 |
Pandas reads the spreadsheet as a table and stores it as a Pandas dataframe.
If your file has non-ASCII characters, you should open it in the unicode format as follows:
import sys
workbook = pd.read_excel('sample-xlsx-file-for-testing.xlsx', encoding=sys.getfilesystemencoding())
If your spreadsheet is very large, you can add an argument use_cols, which loads only certain columns to the dataframe. For instance, the following argument would read only the first five columns:
workbook = pd.read_excel('~/Desktop/import-export-data.xlsx', usecols = 'A:E')
workbook.head()
| Segment | Country | Product | Discount Band | Units Sold | |
|---|---|---|---|---|---|
| 0 | Government | Canada | Carretera | None | 1618.5 |
| 1 | Government | Germany | Carretera | None | 1321.0 |
| 2 | Midmarket | France | Carretera | None | 2178.0 |
| 3 | Midmarket | Germany | Carretera | None | 888.0 |
| 4 | Midmarket | Mexico | Carretera | None | 2470.0 |
Additionally, you can use the nrows and skiprows arguments to read only a certain number of rows, or ignore a certain number of rows at the beginning, respectively.
Opening a specific sheet
You can select a certain sheet from your spreadsheet by using the sheet_name argument. By default, the read_excel() function parses the first sheet in the file. You can either provide the name of the sheet as a string, or the index of the sheet (starting from 0):
# Read the sheet with the name 'Sheet1'
worksheet = pd.read_excel('sample-xlsx-file-for-testing.xlsx', sheet_name = 'Sheet1')
# Read the 1st sheet in the file
worksheet = pd.read_excel('sample-xlsx-file-for-testing.xlsx', sheet_name = 0)
You can also select a number of sheets to be stored as a dict of Pandas dataframes by passing a list the sheet_name argument:
# Read the first two sheets and a sheet with the name 'Sheet 3'
worksheets = pd.read_excel('~/Desktop/import-export-data.xlsx', sheet_name = [0, 1, 'Sheet 3'])
Getting data from cells
Once you’ve selected the worksheet into a dataframe, you can extract the value of a particular data cell by querying into the Pandas dataframe:
import pandas as pd
workbook = pd.read_excel('sample-xlsx-file-for-testing.xlsx')
# Print the 1st value of the Product column
print(workbook['Product'].iloc[0])
=> Carretera
The .iloc() method helps you search for a value based on the index location. In the above code, .iloc() searches for the value at the 0th index location. Similarly, you can search for a value using a label through the .loc() method. For instance, if you pass the argument 0 to the .loc() method, it will search for the label 0 within the index:
print(workbook['Product'].loc[0])
=> Carretera
You can query your dataset once it’s loaded into a dataframe with the inbuilt functions in Pandas. Here’s an article on exploring the values of your Pandas dataframe.
Creating Spreadsheets
The workflow for creating worksheets is similar to that of the previous section.
- import the
pandasmodule - save data into a workbook
- create a sheet within the workbook
- add styling to the cells in the workbook
Create a new file
To create a new file, we first need a dataframe. Let’s recreate the demo sheet from the top of the article:
import pandas as pd
name = ['John', 'Mary', 'Sherlock']
age = [11, 12, 13]
df = pd.DataFrame({ 'Name': name, 'Age': age })
df.index.name = 'ID'
Then you can create a new spreadsheet file by calling the to_excel() function on the dataframe, specifying the name of the file it should save as:
df.to_excel('my_file.xlsx')
You can also open the same file using the function read_excel().
Adding sheets
You can save your dataframe as a certain sheet in the workbook using the sheet_name argument. The default value of this argument is Sheet1:
df.to_excel('my_file.xlsx', sheet_name = 'My Sheet')
More options while saving your spreadsheet
You can use the ExcelWriter class to get more options while saving to your spreadsheet. If you’d like to save multiple dataframes to the same file, you can use the following syntax:
import pandas as pd
workbook = pd.read_excel('my_file.xlsx')
# Creating a copy of workbook
workbook_2 = workbook.copy()
with pd.ExcelWriter('my_file_1.xlsx') as writer:
workbook.to_excel(writer, sheet_name='Sheet1')
workbook_2.to_excel(writer, sheet_name='Sheet2')
To append a dataframe to an existing spreadsheet, use the mode argument. Notice that append mode is only supported when you specify the engine as openpyxl:
with pd.ExcelWriter('my_file_1.xlsx', engine="openpyxl", mode='a') as writer:
workbook_2.to_excel(writer, sheet_name='Sheet3'
Additionally, use the date_format and datetime_format to set the values for date and time values:
with pd.ExcelWriter('my_file.xlsx',
date_format='YYYY-MM-DD',
datetime_format='YYYY-MM-DD HH:MM:SS') as writer:
workbook.to_excel(writer)
Reading Legacy (.xls) Spreadsheets
You can read legacy spreadsheets with the .xls extension using the same syntax in Pandas:
workbook = pd.read_excel('my_file_name.xls')
While you used the same read_excel() function, Pandas uses the xlrd engine to read it. You can read and write legacy spreadsheets using the same syntax that we discussed earlier in this tutorial.
A Quick Summary of CSV Files
CSV stands for “comma-separated values” (or sometimes character-separated if the delimiter used is some character other than a comma) and the name is pretty self explanatory. A typical CSV file looks like the following:
'ID', 'Name', 'Age'
'1', 'John', '11'
'2', 'Mary', '12'
'3', 'Sherlock', '13'
You may convert spreadsheets to CSV files to ease the parsing. CSV files can be parsed easily using the csv module in Python, in addition to Pandas:
workbook = pd.read_csv('my_file_name.csv')
Conclusion
As I mentioned earlier, creating and parsing spreadsheets is inevitable when you’re working with huge web applications. Thus, familiarity with parsing libraries can only help you when the need arises.
What scripting language do you use to handle spreadsheets? Does Python have any other library for this purpose that you prefer? Feel free to hit me up on Twitter.
FAQs on Using Python to Parse Spreadsheet Data
Can Python parse Excel?
Yes, Python can parse Excel files using libraries like pandas and openpyxl.
What is the Python library for parsing Excel files?
Two commonly used libraries are pandas and openpyxl. Pandas is a powerful data manipulation and analysis library that supports various file formats, including spreadsheets. Openpyxl is specifically designed for working with Excel files and offers features to read, modify, and create spreadsheets.
How to extract data from Excel using Python?
You can use the pandas.read_excel() function to read Excel files.
pandas can parse CSV files too. You can use the pandas.read_csv() function to read CSV files.
You can use pandas’ data manipulation functions like loc, iloc, and query to filter, select, and modify data based on various conditions.
You can install pandas and openpyxl using pip, the Python package manager. Run the commands pip install pandas and pip install openpyxl