

Pagination is a technique for breaking large record sets into smaller portions called pages. As a developer, you should be familiar with implementing pagination, but implementing pagination for real time data can become tricky even for experienced developers. In this tutorial, we are going to discuss the practical use cases and solutions for real time data pagination and cursor based pagination.
Key Takeaways
- Pagination is a method used to break large record sets into smaller portions, known as pages. Implementing pagination for real-time data can be challenging due to frequent updates and the potential for inaccurate results when adding or removing data.
- Various social networking sites, such as Twitter and Facebook, have successfully implemented real-time data pagination. They use cursor based pagination, which relies on unique identifiers (cursors) rather than record count for pagination.
- Cursor based pagination requires at least one column with unique sequential values, similar to Twitter’s max_id parameter or Facebook’s after parameter. It also needs a count parameter for filtering a limited number of results, and next and previous URLs to navigate through the data.
- Cursor based pagination is generally more efficient and reliable than offset-based pagination, especially for real-time data or large datasets. It reduces the load on the server and makes the pagination process faster and more efficient.
- Implementing cursor based pagination involves a few steps, including deciding on a unique identifier to use as the cursor, modifying the database query to fetch records based on this cursor, and updating the application’s UI to handle the paginated data and allow users to navigate through the pages.
Identifying Issues in Real Time Data Pagination
Wikipedia defines real time data as information delivered immediately after collection. There is no delay in the timeliness of the information provided. In such applications, it’s difficult to provide accurate paginated data due to the frequent updates. Let’s take a look at the issues with standard pagination when managing real time data.
-
Assumes the data is static and doesn’t change frequently – In default pagination, a retrieved record set is split into a number of pages. As data is not frequently changed, users feel like the pagination is working accurately, but results of the pagination become inaccurate when adding new data or removing existing data.
-
Pagination only considers record count, instead of each individual record – Records are broken into pages using the total record count and paginated normally. It doesn’t consider whether each record falls into the right page on pagination. This can lead to a redundant display of records.
Considering these points, it’s difficult to use to default pagination techniques to handle real time data. Let’s try to identify the issues using a practical scenario.
Assume that we have 20 records initially and we using 10 as the limit to break the records into pages. The following image shows how records are broken into pages.

Now assume that the result set is updated by five new records while we are on the first page. The following image shows the current scenario.
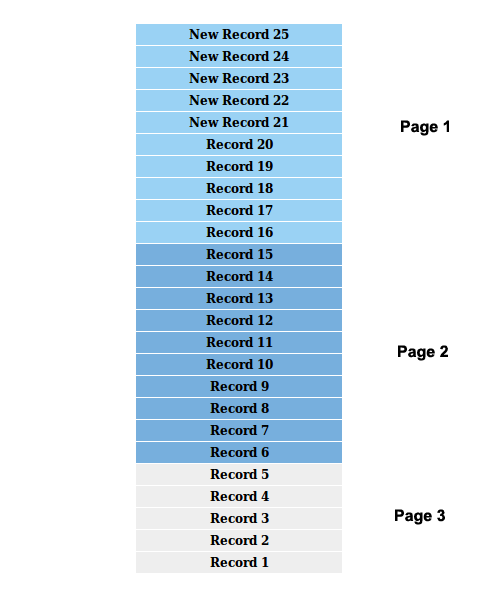
Now we navigate to the second page. Based on our first image, it should retrieve the records from 1-10. However, records with numbers 15-6 will be retrieved. You can clearly see that record numbers 15-11 are displayed in both the first page as well as the second page.
Practical Use Cases of Real Time Data Pagination
As we all know, reinventing the wheel is not something a developer should do. We should look at the existing pagination techniques of sites that solved these issues before thinking about building our own. Many social networking sites such as Twitter and Facebook provide real time data in their user profiles. In this section, we will be looking at the practical use cases of real time data pagination using some of the most popular sites.
Twitter API Cursor Based Pagination
Twitter user profiles are frequently populated with new tweets, so the Twitter time line data retrieval mechanism should be a good start to identifying pagination techniques in real time data feeds. Let’s see how it works using a Twitter API method.
The following contains a sample request to the Twitter API search tweets method.
https://api.twitter.com/1.1/search/tweets.json?q=php&since_id=24012619984051000&max_id=250126199840518145&result_type=recent&count=10
In the above URL, we request the most recent tweets containing the word ‘php’ and break the result set into blocks of 10 using the count parameter. This is the typical behavior of offset pagination where we reply on record count. But here we can see two additional parameters called since_id and max_id, which enables cursor based pagination. Let’s see how cursor based pagination works using our earlier example.
We had 20 records broken into 2 pages and assume we are on the first page. 5 new records are added to the top of the list. The following image previews the current scenario.
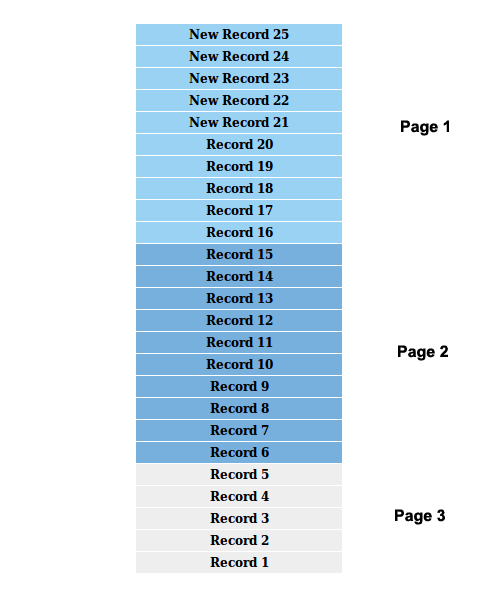
Now let’s take a look at a part of the response generated for the first page of the Twitter search request. You can view the complete response format here.
"search_metadata": {
"max_id": 250126199840518145,
"since_id": 24012619984051000,
"refresh_url": "?since_id=250126199840518145&q=php&result_type=recent&include_entities=1",
"next_results": "?max_id=249279667666817023&q=php&count=10&include_entities=1&result_type=recent",
"count": 10,
"completed_in": 0.035,
"since_id_str": "24012619984051000",
"query": "php",
"max_id_str": "250126199840518145"
}
As you can see, the search_metadata section provides details about the results. It will generate the next_results URL, in case there are more records to paginate. We are mainly using the max_id parameter for pagination. With each response we will retrieve the max_id parameter and we can use it to generate next result set. We use the max_id parameter to receive results older than the given ID.
In our example, we should retrieve the max_id parameter as Record 11 while displaying records 20-11. Then we pass the max_id to generate next result set. Thus, we will get the accurate results as shown in following image.
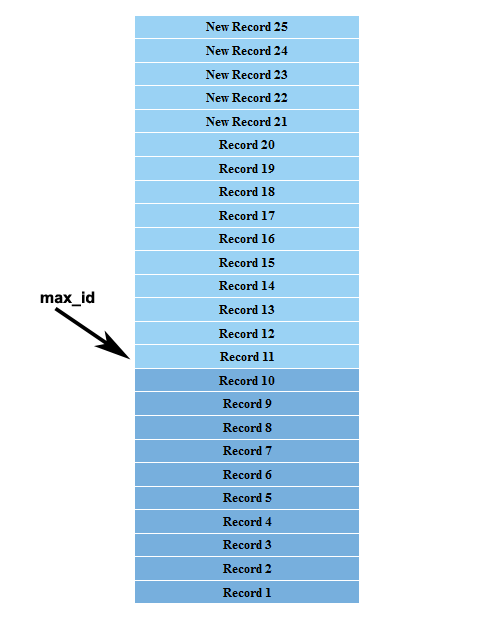
As you can see, we have the accurate results for the second page by eliminating 15 records at the top instead of 10 in offset based pagination. In cursor based pagination we can’t consider the concept of pages, as it changes rapidly, so the results will be considered as either previous or next. Generally, max_id is effective enough to generate accurate results, but there can be scenarios where since_id is also essential while paginating back and forth. You can look at more advanced examples of using both max_id and since_id on Twitter’s Developer section.
Facebook API Cursor Based Pagination
Facebook’s API implementation is slightly different compared to Twitter, even though both APIs use the same theory. Let’s take a look at the response for a sample Facebook API request.
{
"data": [
... Endpoint data is here
],
"paging": {
"cursors": {
"after": "MTAxNTExOTQ1MjAwNzI5NDE=",
"before": "NDMyNzQyODI3OTQw"
},
"previous": "https://graph.facebook.com/me/albums?limit=25&before=NDMyNzQyODI3OTQw"
"next": "https://graph.facebook.com/me/albums?limit=25&after=MTAxNTExOTQ1MjAwNzI5NDE="
}
}
As you can see, Facebook uses two string based cursors called before and after, for pagination, instead of since_id and max_id. In Facebook, the before cursor will point to the start of the page while the after cursor points to the end of the page.
Most API’s with real time data use this mechanism to accurately paginate through their results. As developers, we need to know the theory behind cursor based pagination in order to use existing APIs as well as create our own when necessary.
The Basics of Building Pagination for Real Time Data
Implementing real time data pagination is a complex task beyond the scope of this tutorial, so we are going to look at the basic needs and the process of creating a simple pagination mechanism to understand cursor based pagination.
Let’s identify the basic components of cursor based pagination, using the previously discussed examples.
-
Cursors – we need to have at least one column with unique sequential values to implement cursor based pagination. This can be similar to Twitter’s
max_idparameter or Facebook’safterparameter. -
Count – we need the
countparameter as with offset based pagination for filtering a limited number of results, before or after the cursor. -
Next URL – This is needed in case we are providing the pagination through an API. Users need to know whether the next page is available and how to get the next data set.
-
Previous URL – This is needed in case we are providing the pagination through an API. Users need to know whether the previous page is available and how to get the next data set.
These are the basic needs for cursor based pagination. Developers often work with offset based pagination and rarely get a chance to work with cursor based pagination, so it’s important to identify the differences and benefits of each technique for using them in appropriate scenarios.
-
In offset pagination, we can sort by any column and paginate the results while cursor based pagination depends on the sorting of the unique cursor column.
-
Offset pagination contains page numbers in addition to next and previous links. But due to the highly dynamic nature of the data, we can’t provide page numbers for cursor based pagination.
-
Generally, offset pagination allows us to navigate in both directions while cursor based pagination is mostly used for forward navigation.
So far, we looked at the basic needs and differences of cursor based pagination. Now we can move into a sample implementation to identify how it works.
Implementing Basic Cursor Based Pagination
<?php
class Real_Time_Pagination{
public $conn;
public function dbConnection(){
$this->conn = new PDO('mysql:host=localhost;dbname=database','username','password');
}
public function handlePaginationData(){
$direction = 'next';
$order = 'desc';
$where = '';
$params = array();
if(isset($_GET['max_id'])){
$direction = 'next';
$where = " where tweetID < :max_id ";
$order = 'desc';
$params = array(':max_id' => $_GET['max_id']);
}else if(isset($_GET['since_id'])){
$direction = 'prev';
$where = " where tweetID > :since_id ";
$order = 'asc';
$params = array(':since_id' => $_GET['since_id']);
}
$sth = $this->conn->prepare("select * from tweets $where order by tweetID $order ");
$sth->execute($params);
$results = $sth->fetchAll();
$count = count($results);
$sth = $this->conn->prepare("select * from tweets $where order by tweetID $order limit 3");
$sth->execute($params);
$results = $sth->fetchAll();
if($direction == 'prev'){
$results = array_reverse($results);
}
$html = "";
$max_id = '';
$since_id = '';
foreach($results as $row) {
if($since_id == '' )
$since_id = $row['tweetID'];
$view = $this->paginateDataView();
$html .= $this->assignTemplateVars(array('tweets'=>$row['tweet']) , $view);
$max_id = $row['tweetID'];
}
$html = $this->getResultsList($html);
$html .= $this->paginator($max_id,$since_id,$count,$direction);
return $html;
}
public function getResultsList($res){
$html = "<table>$res</table>";
return $html;
}
public function assignTemplateVars($params,$view){
foreach($params as $key=>$val){
$view = str_replace('{'.$key.'}',$val,$view);
}
return $view;
}
}
-
First, we create the database connection using PDO. Then we execute the
handlePaginationDatafunction for paginating the results. -
Then we check whether
max_idormin_idparameter is available in URL.max_idis is similar to Facebook’s after parameter and used to navigate forward.min_idis similar to Facebook’s before parameter and used to navigate backwards. Also, we set up the navigation direction, the where clause usingmax_idormin_idand the sorting order. -
Then we execute the query to get the complete result count followed by the same query with a limit statement to narrow the results.
-
In case we are traversing in the previous direction, we have to change the sorting to asc. Otherwise it will retrieve the most recent records instead of the previous page. We reverse the records in array to show them as descending.
-
Then we loop through the results. While looping, we assign the ID of the first record as
min_idand last record asmax_id. These cursor values are used for filtering accurate data by eliminating duplication. -
Finally, we can look at the
paginatorfunction for implementing pagination links.
public function paginator($max_id,$since_id,$count,$direction){
$pag['next_url'] = "?max_id=".$max_id;
$pag['prev_url'] = "?since_id=".$since_id;
$html = '';
$params = array('prev_url'=> $pag['prev_url'], 'next_url' => $pag['next_url']);
if($direction == 'next' ){
if($count <= 3)
$params['next_url'] ='#';
$view = $this->paginateLinksView();
$html .= $this->assignTemplateVars($params,$view);
}
if($direction == 'prev'){
if($count <= 3)
$params['prev_url'] ='#';
$view = $this->paginateLinksView();
$html .= $this->assignTemplateVars($params,$view);
}
return $html;
}
public function paginateLinksView(){
$html ="<a href='{prev_url}'>Prev</a>";
$html .="<a href='{next_url}'>Next</a>";
return $html;
}
public function paginateDataView(){
$html = "<tr><td>{tweet}</td></tr>";
return $html;
}
The following code contains the initialization code for the pagination generated in this section.
<?php
$rtp = new Real_Time_Pagination();
$rtp->dbConnection();
echo $rtp->handlePaginationData();
Now we have a simple data pagination sample to understand how real time data pagination works. Use this code and paginate through the results. While paginating, add some records at the end of table to make it real time. Then paginate forward and backwards to to check data duplications in pages. Do the same with offset based pagination to understand the difference.
Conclusion
In this tutorial, we learned the theory behind real time data pagination with cursor based pagination. Let us know your thoughts and experiences in the comments below!
Frequently Asked Questions (FAQs) on Cursor-Based Pagination
What is the main difference between offset and cursor-based pagination?
Offset-based pagination involves skipping a certain number of records from the start and then fetching a set number of records. However, this method can lead to issues like duplicate records if data is added or removed during pagination. On the other hand, cursor-based pagination uses a unique identifier (the cursor) from the last fetched record to retrieve the next set of records. This method is more efficient and avoids the issues associated with offset-based pagination, making it ideal for real-time data.
How does cursor-based pagination handle real-time data?
Cursor-based pagination is particularly effective for real-time data because it uses a unique identifier (the cursor) from the last fetched record to retrieve the next set of records. This means that even if new data is added or existing data is removed during the pagination process, the cursor will still point to the correct next record, ensuring that no records are missed or duplicated.
Can cursor-based pagination be used with any type of data?
Yes, cursor-based pagination can be used with any type of data. However, it is particularly effective with real-time data or large datasets where efficiency is crucial. The cursor can be any unique identifier, such as a timestamp or a unique ID, that can be used to fetch the next set of records.
How does cursor-based pagination improve performance?
Cursor-based pagination improves performance by reducing the amount of data that needs to be processed at once. Instead of fetching all records and then skipping a certain number, cursor-based pagination only fetches the next set of records based on the cursor. This reduces the load on the server and makes the pagination process faster and more efficient.
How can I implement cursor-based pagination in my application?
Implementing cursor-based pagination in your application involves a few steps. First, you need to decide on a unique identifier to use as the cursor. This could be a timestamp, a unique ID, or any other unique value. Next, you need to modify your database query to fetch records based on this cursor. Finally, you need to update your application’s UI to handle the paginated data and allow users to navigate through the pages.
What are the potential drawbacks of cursor-based pagination?
While cursor-based pagination is more efficient and reliable than offset-based pagination, it does have a few potential drawbacks. For example, it can be more complex to implement, especially if your data doesn’t have a clear unique identifier to use as the cursor. Additionally, it may not be suitable for all use cases, such as when you need to jump to a specific page number.
Can cursor-based pagination be used with GraphQL?
Yes, cursor-based pagination can be used with GraphQL. In fact, GraphQL has built-in support for cursor-based pagination through the Relay specification. This allows you to easily implement efficient, reliable pagination in your GraphQL applications.
How does cursor-based pagination work with MySQL?
Cursor-based pagination can be implemented in MySQL by using a unique identifier, such as a timestamp or a unique ID, as the cursor. You can then modify your SQL query to fetch records based on this cursor, using the ‘WHERE’ and ‘LIMIT’ clauses to specify the range of records to fetch.
How does Slack use cursor-based pagination in their API?
Slack uses cursor-based pagination in their API to efficiently fetch large amounts of data. They use a unique identifier as the cursor, and provide this cursor in the API response to allow clients to fetch the next set of records. This allows them to handle large datasets with high performance and reliability.
What is the JSON API specification for cursor-based pagination?
The JSON API specification for cursor-based pagination involves using a unique identifier as the cursor and including this cursor in the ‘links’ object of the API response. This allows clients to easily fetch the next set of records by following the provided link. This specification provides a standard, consistent way to implement cursor-based pagination in JSON APIs.