


GraphQL is a query language for APIs. Although it’s fundamentally different than REST, GraphQL can serve as an alternative to REST that offers performance, a great developer experience, and very powerful tools.
Throughout this article, we’re going to look at how you might tackle a few common use-cases with REST and GraphQL. This article comes complete with three projects. You will find the code for REST and GraphQL APIs that serve information about popular movies and actors as well as a simple frontend app built with HTML and jQuery.
We’re going to use these APIs to look into how these technologies are different so that we can identify their strengths and weaknesses. To start, however, let’s set the stage by taking a quick look at how these technologies came to be.
Key Takeaways
- GraphQL as an Evolution of REST: GraphQL is presented as a next-generation API technology that addresses many of the shortcomings of REST by allowing clients to request exactly what data they need, potentially reducing bandwidth and improving performance.
- Unified Querying Language: Unlike REST, which uses multiple endpoints, GraphQL uses a single endpoint with a powerful querying language, making it easier to work with complex data structures and reducing the overhead of managing multiple URLs.
- Enhanced Developer Experience: The article highlights GraphQL’s superior developer experience, facilitated by its strong type system, introspective capabilities, and comprehensive tooling, which includes the GraphiQL IDE for real-time API interaction and debugging.
- Performance Considerations: GraphQL can significantly reduce the number of network requests by allowing fetching of nested data in a single query, whereas REST might require multiple roundtrips between the client and server, as demonstrated in the provided coding examples.
- Adaptability and Versioning: GraphQL offers more flexibility in API versioning through its introspective features and deprecation system, which can be more efficient and less disruptive compared to the traditional versioning in REST.
The Early Days of the Web
The early days of the web were simple. Web applications began as static HTML documents served over the early internet. Websites advanced to include dynamic content stored in databases (e.g. SQL) and used JavaScript to add interactivity. The vast majority of web content was viewed through web browsers on desktop computers and all was good with the world.
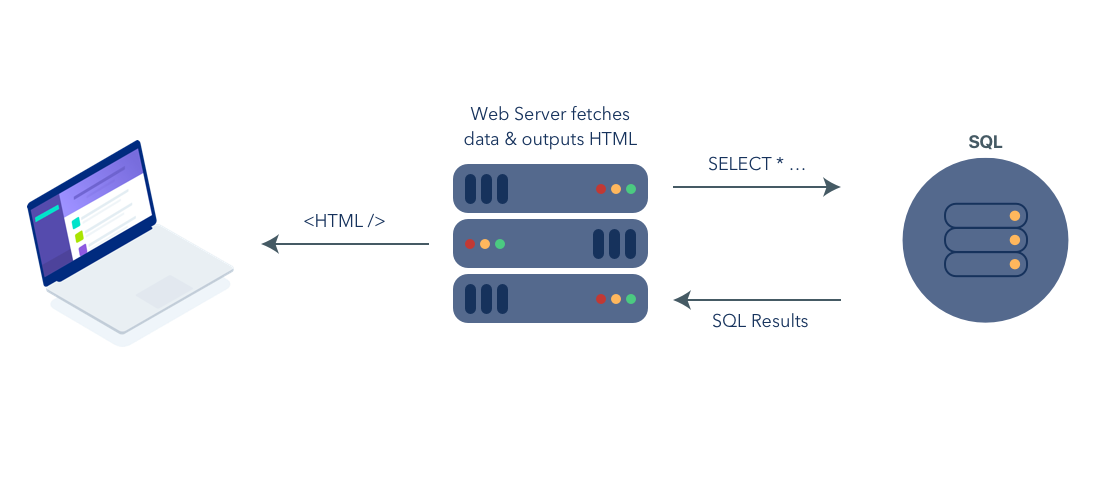
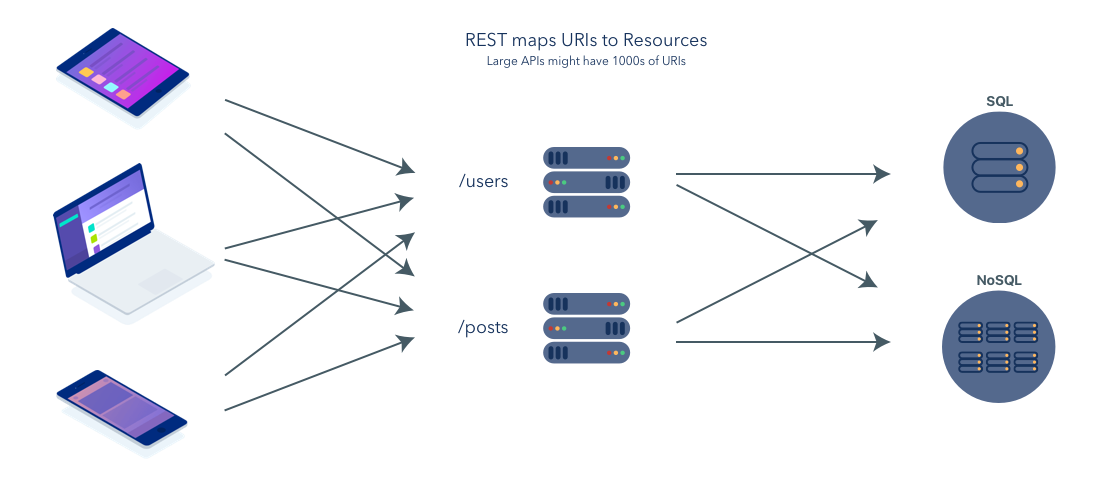
REST: The Rise of the API
Fast forward to 2007 when Steve Jobs introduced the iPhone. In addition to the far-reaching impacts that the smartphone would have on the world, culture, and communications, it also made developers’ lives a lot more complicated. The smartphone disrupted the development status quo. In a few short years, we suddenly had desktops, iPhones, Androids, and tablets.
In response, developers started using RESTful APIs to serve data to applications of all shapes and sizes. The new development model looked something like this:
GraphQL: The Evolution of the API
GraphQL is a query language for APIs that was designed and open-sourced by Facebook. You can think of GraphQL as an alternative to REST for building APIs. Whereas REST is a conceptual model that you can use to design and implement your API, GraphQL is a standardized language, type system, and specification that creates a strong contract between client and server. Having a standard language through which all of our devices communicate simplifies the process of creating large, cross-platform applications.
With GraphQL our diagram simplifies:
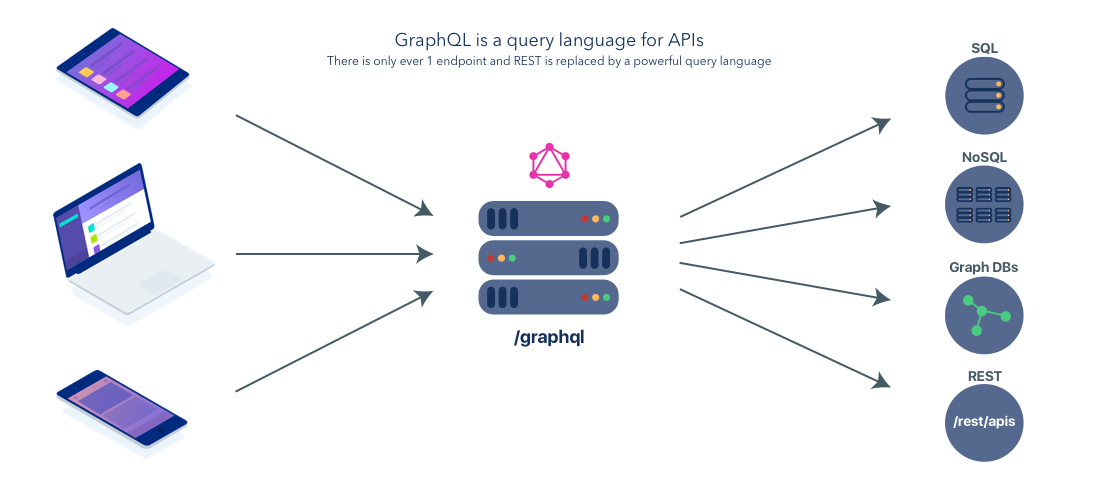
GraphQL vs REST
Throughout the rest of this tutorial (no pun intended), I encourage you to follow along with code! You can find the code for this article in the accompanying GitHub repo.
The code includes three projects:
- A RESTful API
- a GraphQL API and
- a simple client web page built with jQuery and HTML.
The projects are purposefully simple and were designed to provide as simple a comparison between these technologies as possible.
If you would like to follow along open up three terminal windows and cd to the RESTful, GraphQL, and Client directories in the project repository. From each of these directories, run the development server via npm run dev. Once you have the servers ready, keep reading :)
Querying with REST
Our RESTful API contains a few endpoints:
| Endpoint | Description |
|---|---|
| /movies | returns an Array of objects containing links to our movies (e.g. [ { href: ‘http://localhost/movie/1’ } ] |
| /movie/:id | returns a single movie with id = :id |
| /movie/:id/actors | returns an array of objects containing links to actors in the movie with id = :id |
| /actors | returns an Array of objects containing links to actors |
| /actor/:id | returns a single actor with id = :id |
| /actor/:id/movies | returns an array of objects containing links to movies that the actor with id = :id has acted in |
Note: Our simple data model already has 6 endpoints that we need to maintain and document.
Let’s imagine that we are client developers that need to use our movies API to build a simple web page with HTML and jQuery. To build this page, we need information about our movies as well as the actors that appear in them. Our API has all the functionality we might need so let’s go ahead and fetch the data.
If you open a new terminal and run
curl localhost:3000/movies
You should get a response that looks like this:
[
{
"href": "http://localhost:3000/movie/1"
},
{
"href": "http://localhost:3000/movie/2"
},
{
"href": "http://localhost:3000/movie/3"
},
{
"href": "http://localhost:3000/movie/4"
},
{
"href": "http://localhost:3000/movie/5"
}
]
In RESTful fashion, the API returned an array of links to the actual movie objects. We can then go grab the first movie by running curl http://localhost:3000/movie/1 and the second with curl http://localhost:3000/movie/2 and so on and so forth.
If you look at app.js you can see our function for fetching all the data we need to populate our page:
const API_URL = 'http://localhost:3000/movies';
function fetchDataV1() {
// 1 call to get the movie links
$.get(API_URL, movieLinks => {
movieLinks.forEach(movieLink => {
// For each movie link, grab the movie object
$.get(movieLink.href, movie => {
$('#movies').append(buildMovieElement(movie))
// One call (for each movie) to get the links to actors in this movie
$.get(movie.actors, actorLinks => {
actorLinks.forEach(actorLink => {
// For each actor for each movie, grab the actor object
$.get(actorLink.href, actor => {
const selector = '#' + getMovieId(movie) + ' .actors';
const actorElement = buildActorElement(actor);
$(selector).append(actorElement);
})
})
})
})
})
})
}
As you might notice, this is less than ideal. When all is said and done we have made 1 + M + M + sum(Am) round trip calls to our API where M is the number of movies and sum(Am) is the sum of the number of acting credits in each of the M movies. For applications with small data requirements, this might be okay but it would never fly in a large, production system.
Conclusion? Our simple RESTful approach is not adequate. To improve our API, we might go ask someone on the backend team to build us a special /moviesAndActors endpoint to power this page. Once that endpoint is ready, we can replace our 1 + M + M + sum(Am) network calls with a single request.
curl http://localhost:3000/moviesAndActors
This now returns a payload that should look something like this:
[
{
"id": 1,
"title": "The Shawshank Redemption",
"release_year": 1993,
"tags": [
"Crime",
"Drama"
],
"rating": 9.3,
"actors": [
{
"id": 1,
"name": "Tim Robbins",
"dob": "10/16/1958",
"num_credits": 73,
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BMTI1OTYxNzAxOF5BMl5BanBnXkFtZTYwNTE5ODI4._V1_.jpg",
"href": "http://localhost:3000/actor/1",
"movies": "http://localhost:3000/actor/1/movies"
},
{
"id": 2,
"name": "Morgan Freeman",
"dob": "06/01/1937",
"num_credits": 120,
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BMTc0MDMyMzI2OF5BMl5BanBnXkFtZTcwMzM2OTk1MQ@@._V1_UX214_CR0,0,214,317_AL_.jpg",
"href": "http://localhost:3000/actor/2",
"movies": "http://localhost:3000/actor/2/movies"
}
],
"image": "https://images-na.ssl-images-amazon.com/images/M/MV5BODU4MjU4NjIwNl5BMl5BanBnXkFtZTgwMDU2MjEyMDE@._V1_UX182_CR0,0,182,268_AL_.jpg",
"href": "http://localhost:3000/movie/1"
},
...
]
Great! In a single request, we were able to fetch all the data we needed to populate the page. Looking back at app.js in our Client directory we can see the improvement in action:
const MOVIES_AND_ACTORS_URL = 'http://localhost:3000/moviesAndActors';
function fetchDataV2() {
$.get(MOVIES_AND_ACTORS_URL, movies => renderRoot(movies));
}
function renderRoot(movies) {
movies.forEach(movie => {
$('#movies').append(buildMovieElement(movie));
movie.actors && movie.actors.forEach(actor => {
const selector = '#' + getMovieId(movie) + ' .actors';
const actorElement = buildActorElement(actor);
$(selector).append(actorElement);
})
});
}
Our new application will be much speedier than the last iteration, but it is still not perfect. If you open up http://localhost:4000 and look at our simple web page you should see something like this:
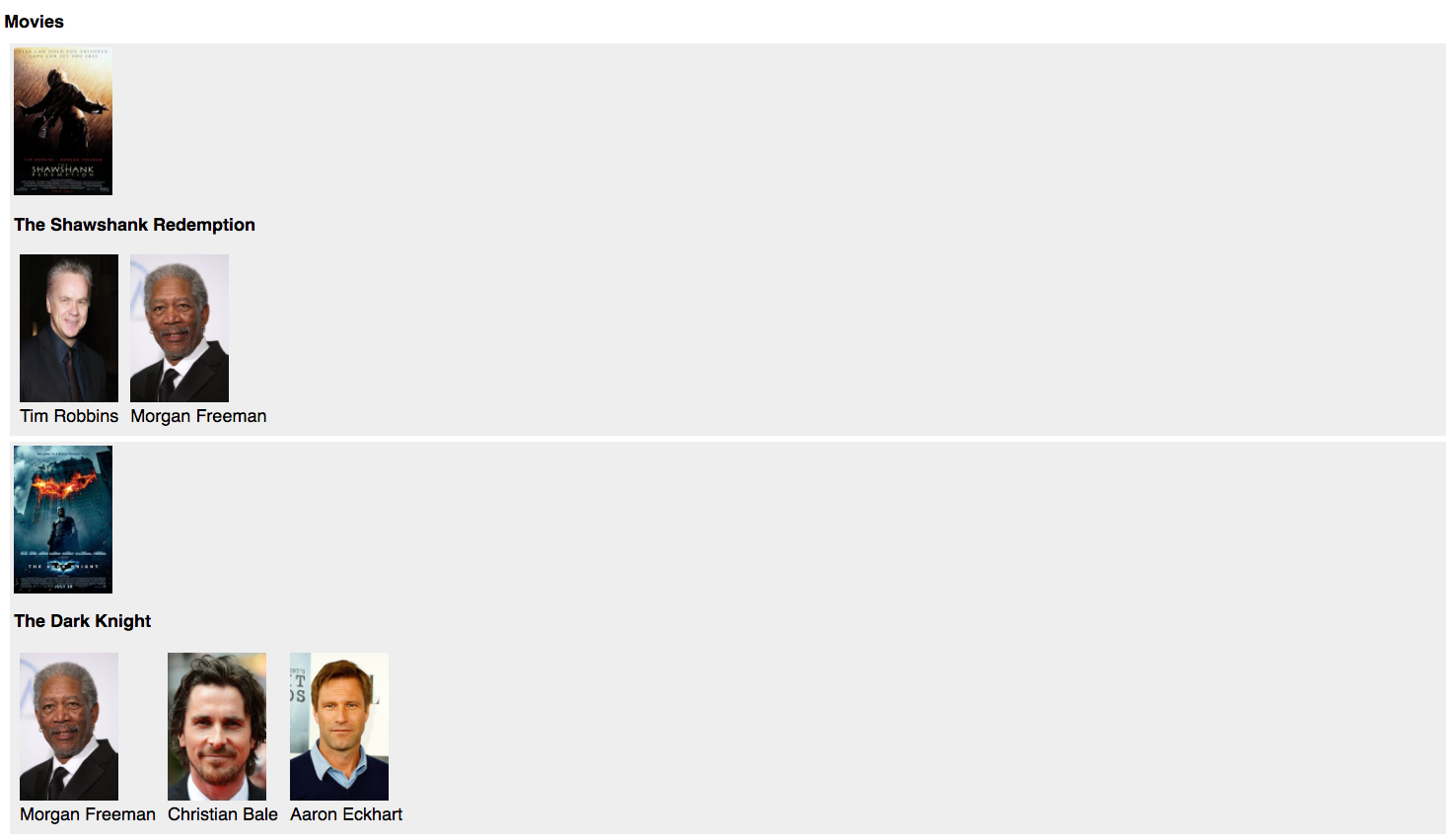
If you look closely, you’ll notice that our page is using a movie’s title and image, and an actor’s name and image (i.e. we are only using 2 of 8 fields in a movie object and 2 of 7 fields in an actor object). That means we are wasting roughly three-quarters of the information that we are requesting over the network! This excess bandwidth usage can have very real impacts on performance as well as your infrastructure costs!
A savvy backend developer might scoff at this and quickly implement a special query parameter named fields that takes an array of field names that will dynamically determine which fields should be returned in a specific request.
For example, instead of curl http://localhost:3000/moviesAndActors we might have curl http://localhost:3000/moviesAndActors?fields=title,image. We might even have another special query parameter actor_fields that specifies which fields in the actor models should be included. E.G. curl http://localhost:3000/moviesAndActors?fields=title,image&actor_fields=name,image.
Now, this would be a near optimal implementation for our simple application but it introduces a bad habit where we create custom endpoints for specific pages in our client applications. The problem becomes more apparent when you start building an iOS app that shows different information than your web page and an Android app that shows different information than the iOS app.
Wouldn’t it be nice if we could build a generic API that explicitly represents the entities in our data model as well as the relationships between those entities but that does not suffer from the 1 + M + M + sum(Am) performance problem? Good news! We can!
Querying with GraphQL
With GraphQL, we can skip directly to the optimal query and fetch all the info we need and nothing more with a simple, intuitive query:
query MoviesAndActors {
movies {
title
image
actors {
image
name
}
}
}
Seriously! To try it yourself, open GraphiQL (the awesome browser based GraphQL IDE) at http://localhost:5000 and run the query above.
Now, let’s dive a little deeper.
Thinking in GraphQL
GraphQL takes a fundamentally different approach to APIs than REST. Instead of relying on HTTP constructs like verbs and URIs, it layers an intuitive query language and powerful type system on top of our data. The type system provides a strongly-typed contract between the client and server, and the query language provides a mechanism that the client developer can use to performantly fetch any data he or she might need for any given page.
GraphQL encourages you to think about your data as a virtual graph of information. Entities that contain information are called types and these types can relate to one another via fields. Queries start at the root and traverse this virtual graph while grabbing the information they need along the way.
This “virtual graph” is more explicitly expressed as a schema. A schema is a collection of types, interfaces, enums, and unions that make up your API’s data model. GraphQL even includes a convenient schema language that we can use to define our API. For example, this is the schema for our movie API:
schema {
query: Query
}
type Query {
movies: [Movie]
actors: [Actor]
movie(id: Int!): Movie
actor(id: Int!): Actor
searchMovies(term: String): [Movie]
searchActors(term: String): [Actor]
}
type Movie {
id: Int
title: String
image: String
release_year: Int
tags: [String]
rating: Float
actors: [Actor]
}
type Actor {
id: Int
name: String
image: String
dob: String
num_credits: Int
movies: [Movie]
}
The type system opens the door for a lot of awesome stuff including better tools, better documentation, and more efficient applications. There is so much we could talk about, but for now, let’s skip ahead and highlight a few more scenarios that showcase the differences between REST and GraphQL.
GraphQL vs Rest: Versioning
A simple google search will result in many opinions on the best way to version (or evolve) a REST API. We’re not going to go down that rabbit hole, but I do want to stress that this is a non-trivial problem. One of the reasons that versioning is so difficult is that it is often very difficult to know what information is being used and by which applications or devices.
Adding information is generally easy with both REST and GraphQL. Add the field and it will flow down to your REST clients and will be safely ignored in GraphQL until you change your queries. However, removing and editing information is a different story.
In REST, it is hard to know at the field level what information is being used. We might know that an endpoint /movies is being used but we don’t know if the client is using the title, the image, or both. A possible solution is to add a query parameter fields that specifies which fields to return, but these parameters are almost always optional. For this reason, you will often see evolution occur at the endpoint level where we introduce a new endpoint /v2/movies. This works but also increases the surface area of our API as well as adds a burden on the developer to keep up to date and comprehensive documentation.
Versioning in GraphQL is very different. Every GraphQL query is required to state exactly what fields are being requested in any given query. The fact that this is mandatory means that we know exactly what information is being requested and allows us to ask the question of how often and by who. GraphQL also includes primitives that allow us to decorate a schema with deprecated fields and messages for why they are being deprecated.
This is what versioning looks like in GraphQL:

GraphQL vs REST: Caching
Caching in REST is straightforward and effective. In fact, caching is one of the six guiding constraints of REST and is baked into RESTful designs. If a response from an endpoint /movies/1 indicates that the response can be cached, any future requests to /movies/1 can simply be replaced by the item in the cache. Simple.
Caching in GraphQL is tackled slightly differently. Caching a GraphQL API will often require introducing some sort of unique identifier for each object in the API. When each object has a unique identifier, clients can build normalized caches that use this identifier to reliably cache, update, and expire objects. When the client issues downstream queries that reference that object, the cached version of the object can be used instead. If you are interested in learning more about how caching in GraphQL works here is a good article that covers the subject more in depth.
GraphQL vs REST: Developer Experience
Developer experience is an extremely important aspect of application development and is the reason we as engineers invest so much time into building good tooling. The comparison here is somewhat subjective but I think still important to mention.
REST is tried and true and has a rich ecosystem of tools to help developers document, test, and inspect RESTful APIs. With that being said there is a huge price developers pay as REST APIs scale. The number of endpoints quickly becomes overwhelming, inconsistencies become more apparent, and versioning remains difficult.
GraphQL really excels in the developer experience department. The type system has opened the door for awesome tools such as the GraphiQL IDE, and documentation is built into the schema itself. In GraphQL there is also only ever one endpoint, and, instead of relying on documentation to discover what data is available, you have a type safe language and auto-complete which you can use to quickly get up to speed with an API. GraphQL was also designed to work brilliantly with modern front-end frameworks and tools like React and Redux. If you are thinking of building an application with React, I highly recommend you check out either Relay or Apollo client.
Conclusion
GraphQL offers a somewhat more opinionated yet extremely powerful set of tools for building efficient data-driven applications. REST is not going to disappear anytime soon but there is a lot to be desired especially when it comes to building client applications.
If you are interested in learning more, check out Scaphold.io’s GraphQL Backend as a Service. In a few minutes you will have a production ready GraphQL API deployed on AWS and ready to be customized and extended with your own business logic.
I hope you enjoyed this post and if you have any thoughts or comments, I would love to hear from you. Thanks for reading!
Frequently Asked Questions (FAQs) about REST 2.0 and GraphQL
What are the main differences between REST 2.0 and GraphQL?
REST 2.0 and GraphQL are both APIs but they differ in their approach to data delivery. REST 2.0 uses a standard HTTP protocol and it is stateless, meaning each request from the client to the server must contain all the information needed to understand and process the request. On the other hand, GraphQL is a query language for APIs and a runtime for executing those queries with your existing data. It provides a more efficient data integration by allowing clients to specify exactly what data they need, which can reduce the amount of data that needs to be transferred over the network and improve app performance.
Why should I consider using GraphQL over REST 2.0?
GraphQL offers several advantages over REST 2.0. It allows clients to request exactly what they need, which can lead to more efficient data loading. It also provides a type system that allows you to define what data can be queried, which can lead to more robust APIs. Additionally, GraphQL supports real-time updates with subscriptions, making it a good choice for applications that require real-time data.
Can REST 2.0 and GraphQL coexist in the same project?
Yes, REST 2.0 and GraphQL can coexist in the same project. In fact, many companies use both in their projects. They might use REST 2.0 for certain parts of their application where it makes sense and use GraphQL for other parts where they need more flexibility and efficiency in data loading.
What are the challenges of migrating from REST 2.0 to GraphQL?
Migrating from REST 2.0 to GraphQL can be challenging because they have different paradigms for handling data. You’ll need to rethink how you structure your data and how you handle data requests. Additionally, you might need to learn new tools and technologies, as GraphQL has its own ecosystem of tools and libraries.
How does GraphQL handle errors compared to REST 2.0?
In REST 2.0, errors are typically handled with HTTP status codes. In GraphQL, however, there’s no concept of HTTP status codes. Instead, GraphQL always returns a 200 OK status code and includes an “errors” field in the response body if there were any errors in processing the request.
Is GraphQL faster than REST 2.0?
It depends on the use case. GraphQL can be faster than REST 2.0 because it allows clients to request exactly what they need, which can reduce the amount of data that needs to be transferred over the network. However, if not implemented properly, GraphQL can also be slower than REST 2.0 due to over-fetching or under-fetching of data.
What is the learning curve like for GraphQL compared to REST 2.0?
GraphQL has a steeper learning curve than REST 2.0 because it introduces new concepts like types, queries, mutations, and subscriptions. However, once you get the hang of it, many developers find that GraphQL is more powerful and flexible than REST 2.0.
Can I use GraphQL with my existing REST 2.0 APIs?
Yes, you can use GraphQL with your existing REST 2.0 APIs. GraphQL can be used as a layer in front of your existing REST APIs to provide a more flexible and efficient data loading experience for your clients.
What are some good resources for learning more about GraphQL?
There are many great resources for learning more about GraphQL. The official GraphQL website is a good place to start. There are also many online tutorials, courses, and books available that can help you get started with GraphQL.
Is GraphQL suitable for all types of projects?
GraphQL is a powerful tool, but it’s not always the best choice for every project. If your project involves simple CRUD operations and doesn’t require real-time updates or complex nested data structures, REST 2.0 might be a better choice. However, if your project requires more flexibility and efficiency in data loading, GraphQL might be a better fit.

