
Key Takeaways
- Rake’s Versatility: Rake, a Ruby-based task management tool, extends beyond simple automation, handling everything from project setup to complex dependencies and environment management.
- Integration with Ruby on Rails: Rake and Rails work seamlessly together, making it an indispensable tool for Rails developers to automate repetitive tasks and manage databases.
- Task Management Simplified: Rake simplifies task management through namespaces and task dependencies, avoiding conflicts and ensuring organized and maintainable code.
- Parameter Passing and Task Customization: Rake supports parameterized tasks, allowing for dynamic task execution and greater flexibility in automation scripts.
- Automation Beyond Ruby: While deeply integrated with Ruby, Rake’s capabilities extend to automating a wide range of development tasks, proving its utility in diverse scenarios.
- Streamlined Workflow: By automating routine tasks, Rake enhances productivity, reduces errors, and allows developers to focus on core development tasks, thereby streamlining the workflow in Ruby and Rails projects.

A couple of years ago, I received an email from a friend stating he was learning Rails and he thought I should try it out. Although I had a good programming background, my web development skills were terrible. I knew a bit of HTML and CSS, but if you had asked me what POST and PUT had in common, I would have told you they both started with a P and ended with a T.
An author suggested that mastering Rails required mastering all aspects of web development, but the idea of learning everything from scratch did not excite me. A few days later, I stumbled upon some Ruby syntax on a Pastebin application online. I had no experience with Ruby whatsoever, but its syntax and style were so elegant and expressive that I could easily perceive what the author was attempting to do. I started toying around with Ruby books and instantly fell in love with the programming language. That’s the story of my affair with Ruby.
I know what you’re wondering-“What does this have to do with Rake and Rails? And why did I stylize the word scratch?”
Frankly speaking, I hate starting things from scratch. I don’t know whether it’s just me or if it’s a worldwide phenomenon. When you do something for the first time, it’s called an adventure. If you decide to do it again, everyone says it adds to your experience. But on the third run, it turns out to be boring.
When you step into the Ruby on Rails world as a developer, freelancer, or hobbyist, you will immediately feel the thrill and excitement of getting started and running
rails new webapp
But before you sink your teeth into engineering the stunning designs and concepts of your new web app, there are a series of necessary, although seemingly trivial, details to be addressed. Things like:
- Cleaning up the Gemfile
- Initializing a git repository
- Setting up gems for your toolkits like Bootstrap
- Configuring guard + spark, etc.
These steps will, of course, be beneficial for you as you develop your project, but they loom before you like a major obstacle to getting started. Dealing with these trifles drains all the excitement and energy from me and send me running for a cup of coffee.
Here’s where Rake comes in. As you may have guessed from its name, Rake is a Make-inspired application written in Ruby and developed by Jim Weirich. Rake is a task management utility that can do anything from automatically deleting your browser history to building artificial intelligence. I’m just kidding; Rake can’t quite do that, but it is powerful. Designed to build executable programs from source files, it can do so much more!
Initially, Jim wasn’t convinced that Rake would be useful, but the Ruby community were happy to prove him wrong by incorporating it with Ruby’s standard library.
Ok, let me state from the beginning that I never intended to write this code. I’m not convinced it is useful, and I’m not convinced anyone would even be interested in it. All I can say is that Why’s onion truck must by been passing through the Ohio valley. What am I talking about? … A Ruby version of Make.
–Jim Weirich
Getting Started with Rake
Rake is an Embedded Domain Specific Language (EDSL) because, beyond the walls of Ruby, it has no existence. The term EDSL suggests that Rake is a domain-specific language that is embedded inside another language (Ruby) which has greater scope. Rake extends Ruby, so you can use all the features and extensions that come with Ruby. You can take advantage of Rake by using it to automate some tasks that have been continually challenging you. Because of this, you will find the novelty of using it will not quickly wear off and you soon become much more productive.
Sounds interesting? Let’s get started, shall we?
The Basics
Here are a few rake tasks that you have likely seen before:
$ rake db:migrate
$ rake db:test:prepare
Running rake from the command-line involves calling rake followed by the name of the task. As the number of tasks increases, maintaining them and creating new ones becomes quite a tedious task in itself. Rake lets you organize your tasks using namespaces, making it possible to create multiple tasks having the same name assigned to different namespaces and avoid naming collision and ambiguity.
For instance, you could create two tasks with the name cleanup.
- main:cleanup – This task cleans up your webapp directory removing deadwood files and unnecessary code chunks.
- temp:cleanup – This wipes out all the files and folders listed under temp directory.
Here is a barebones structure of a rake task.
It consists of
- A namespace block
- A short description about the task
- The name of the task (note that I’ve used a symbol rather than a string)
- A
do..endblock - The code that the task is supposed to execute
Every piece of code in between the task :cleanup do..end block is executed when you call
rake main:cleanup
If you ever decide to add another task under the main namespace, it should be enclosed inside the outer do..end block. You can add any number of tasks under a namespace.
Dependency vs invoke
An essential component of any build tool is looking for dependencies (a.k.a prerequisites) and resolving them. A task can have multiple prerequisites which ought to get executed prior to the main task.
Rakefile
task :default => :third_task
task :first_task do
puts "First task"
end
task :second_task do
puts ">>Second task"
end
task :third_task => [:first_task, :second_task] do
puts ">>>>Hurray. This is the third task"
puts " This task depends on the first_task and second_task and won’t be executed unless both the dependencies are satisfied."
print "The syntax for declaring dependency is "
puts " :main_task => :dependency"
puts "and if there are more than 1 dependency, place all the dependencies inside the [] separated by commas "
puts ":main_task => [:dep1, :dep2]"
end
If you are wondering what :default is doing up there, it is a Ruby symbol that bears a special meaning to Rake. Running rake without any parameters from the terminal would execute third_task by default, because we’ve declared it with a :default symbol.
$ rake
Having prerequisites is useful, but wouldn’t it be awesome if we could do it the conventional, straightforward way, such as calling a task from another task? You can achieve this without having to leave Rake’s idioms.
namespace :main do
task :test do
if true
puts "Calling test2 task."
Rake::Task["main:test2"].invoke #invokes main:test2
else
abort()
end
end
task :test2 do
puts ">Test2 task invoked"
end
end
As exemplified above, you can even place the task invocation under a conditional statement, in which case it will be executed only if the condition falls true.
Parameterized Tasks
What if we wanted to, say, pass parameters to our Rake task? Sound impossible? Not really.
task :tests, [:arg1, :arg2] do |t, args|
puts "First argument: #{ args[:arg1] }"
puts "Second argument: #{args[:arg2]}"
end
And the output:
$ rake tests[1,some_random_string]
First argument: 1
Second argument: some_random_string
That’s wicked, isn’t it? The parameters go inside the [ ], separated by commas. It takes 2 block variables:
tis the object concerned with this taskargsis a hash that stores your arguments
Create a test directory for the sake of this example.
mkdir testapp && cd testapp
We’ll create an empty data file and a Rakefile inside testapp and see what sort of wizardry Rake is capable of.
$ ls
data.dat Rakefile
Here’s the Rakefile
namespace :setup do
desc "A test task to check whether a directory exists"
task :check do
puts "Enter the name of the destination directory: "
@dir = STDIN.gets.strip #Calling gets by itself would result in a call to "Kernel#gets" which is not what we want.
if File.directory?("../#{@dir}") #Checks whether the user requested directory exists and if not creates a new one.
puts "The directory exists"
setup_copy #Calls setup_copy method
else
puts "Creating the requested directory..."
mkdir "../#{@dir}"
setup_copy
end
end
desc "A test task to copy things around"
task :copy => :check do #A task dependency
puts "Copying files..."
cp_r '.', "../#{@dir}"
puts "Done.! :)"
end
end
def setup_copy
Rake::Task["setup:copy"].invoke #A task invocation
end
For instant gratification, try running
rake setup:copy
from the testapp directory. Rake performs as it is told.
- When
setup:copygets called, Rake attempts to satisfy its dependencysetup:check. - The
setup:checkcaptures the name of the destination directory through an instance variable. Using a local variable in that instance would mean that its scope would be restricted to that specific task. However, making it available to the subsequent child tasks would save us a lot of code and time. - The
if-elseblock checks whether the directory already exists, creates one if the condition fails and pokes thesetup_copyfunction. This goes to demonstrate Rake’s complaisance with Ruby. - The control returns to
setup:copy. Thecp_rmethod copies all the files residing in the current directory and places them in the user requested folder. (The ‘r’ incp_rtakes care of copying files recursively so that nothing is left out.)
Note: I am not sure whether you noticed, but we did not require any standard library files or load any extensions to make cp_r and mkdir accessible in our Rakefile. That’s because, the “fileutils” library is loaded with the Rakefile by default. I would highly recommend going through the ruby docs on fileutils. You will definitely find it useful at some stage of the tutorial.
Wouldn’t a task invocation and a dependency result in a conflict of interest? I thought you might ask something along those lines.
No. They can survive together without beating each other up. We’ll stick with employing tasks as prerequisites, that way we can keep the code apparent and palpable. But, you can do it the other way around, too.
Imagine that you have the 4 tasks depicted in the snippet below:
namespace :setup do
task :init do
puts ">init: Task to initiate a process"
puts ">Imagine that all other tasks depend on this task"
end
task :cleanup => :init do #This task depends on :init
puts ">>cleanup:Tasks related to cleaning up Gemfile, deleting public/index.html etc."
end
task :git=> :init do #This one too depends on :init
puts ">>>git: Tasks concerned with setting up GIT repository"
end
task :all => [ :init, :cleanup, :git ] do #Depends on init, cleanup and git tasks.
puts ">>>>all: Done"
end
end
Try running
rake setup:all
and see how it works out.
The last-mentioned command executes all the tasks in succession because we’ve filled in that task with 3 prerequisites, namely :init, :cleanup and :git. That’s cool. But what if we wanted to set up our git repo without cleaning up our Gemfile?
That too is achievable. Go ahead and type this into your terminal.
rake setup:git
Since the setup:init is a prerequisite for the task concerned with creation of a git repo, it will get executed and woohoo.
Initializing..
Tasks concerned with setting up GIT repository.
Rake and Rails: The Perfect Duo
We are nearly done with hiking through the basics of Rake. There are just a few tiny bits remaining to be discussed about the design of the script we are about to construct.
Usually, developers tend to have a directory dedicated to Rails, inside of which they create new projects and maintain existing ones. Somewhat like the screenshot depicted below.
That’s good. We will create a folder named Rake under the ~/Rails directory which, in my opinion, is the desirable location to place our Rakefile and all of the associated files.
$ cd ~/Rails
$ mkdir Rake
Create a new Rails application, say, testapp under ~/Rails. (Using the rails new command)
$ ls
testapp Rake
Our Rake directory and Rails application directory are in the same level. So, let’s get started.
The Rakefile and all the associated files will dwell inside the Rake directory. At the other end we have the testapp directory, which is the destination directory that we plan to manipulate. The setup:init task will initiate the process. It will copy all the files residing in the Rake directory to the destination directory’s lib/tasks folder. Every Rails app, generated via the generate script, comes equipped with a lib/tasks folder. The Rails convention is to place all the Rake tasks in this directory and these tasks will be accessible from the root of the Rails application directory by default.
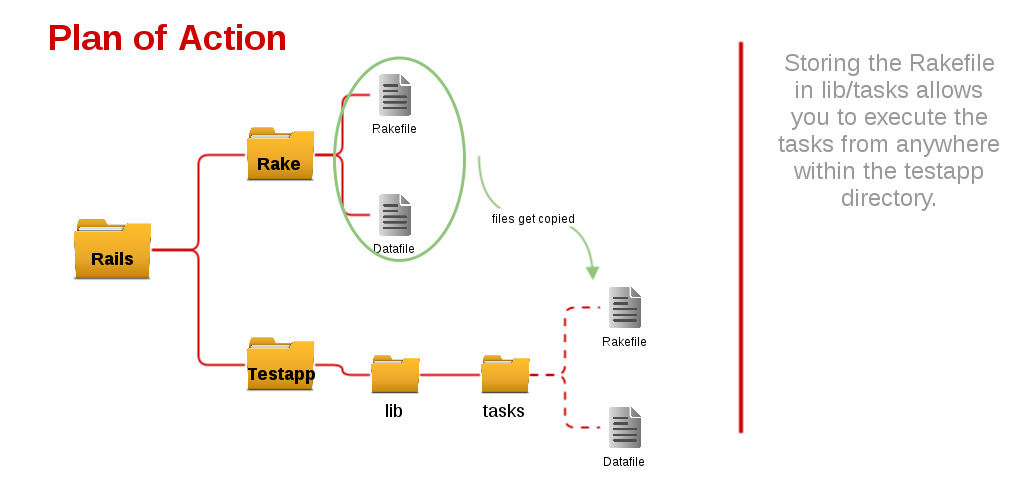
Here is a sketch of an improved :init task.
namespace :setup do
desc "Initiate setup. This task serves as a dependency for other tasks."
task :init do
print "Name of the destination directory: "
name = STDIN.gets.strip
if pwd().split('/').last == "Rake"
puts "Copying the files to #{name}/lib/tasks."
# Copying the rakefile over to lib/tasks of the destination directory.
# This is a Rails generated directory dedicated for rake tasks.
cp_r '.', "../#{name}/lib/tasks", verbose: false
print "Do you want to continue with the setup?(y/n): "
option = STDIN.gets.strip
case option
when /[^Yy]/
abort_message #A call to the abort_message method.
end
# change directory to the root of the Rails application directory
cd "../#{name}"
end
end
def abort_message
abort("Exiting. You can each task individually. See rake -T for more info") #A handy method to exit early from a rake task. You can read more about it here.
end
end
Apart from a few Ruby constructs, you shouldn’t have much trouble decoding it. Although preserving Rake files in lib/tasks isn’t mandatory, it might become advantageous at a later stage of the development phase.
But, there is a catch. If you plan to call up the custom Rake tasks from the testapp directory as demonstrated below, it wouldn’t work.
$ cd testapp
rake setup:init
rake aborted!
Don't know how to build task 'setup:init'
Although you can call up the tasks from the Rake directory without stumbling into any issues, executing custom Rake tasks from the web application’s root directory as shown will result in an error. Rake will ignore all the files currently placed in lib/tasks, including the Rakefile, because it will only load files having the “.rake” extension . To fix this, we might have to tweak our Rakefile. For the moment, we will let this pass and deal with it later.
Next, we have the cleanup task. You can engineer this task to perform all sorts of pesky cleanup jobs prior to getting started with the actual development of the app. As in the case of most developers, the first thing I do is edit my Gemfile, removing the commented lines of code and adding gems without which I find it hard to survive.
desc "Cleanup Gemfile and other stuff."
task :cleanup => :init do
print "Clean up the standard Gemfile for a new one?(y/n): "
option = STDIN.gets.strip
case option
when /[^Yy]/
abort_message
end
puts "Setting a new Gemfile."
cp 'lib/tasks/Gemfile', '.', verbose: false #Copying the gemfile from lib/tasks to the root of the project directory.
puts "Running bundle install. This may take a while...\n\n"
sh "bundle install" #sh bridges your task with the command-line, bestowing upon you the access to all the terminal commands.
end
Here is an edited version of the Gemfile.
source 'https://rubygems.org'
ruby '2.0.0'
gem 'rails', '4.0.0'
group :development, :test do
gem 'sqlite3', '1.3.7'
end
group :test do
#test
end
gem 'sass-rails', '4.0.0'
gem 'uglifier', '2.1.1'
gem 'coffee-rails', '4.0.0'
gem 'jquery-rails', '2.2.1'
gem 'turbolinks', '1.1.1'
gem 'jbuilder', '1.0.2'
group :doc do
gem 'sdoc', '0.3.20', require: false
end
group :production do
#production
end
We’ll place the good looking Gemfile in our ~/Rails/Rake directory and Rake will take care of the rest. The command rake setup:init will copy the Gemfile (along with the Rakefile) to lib/tasks and :cleanup will move it to the root directory replacing the original Gemfile.
Here is my implementation of tasks concerned with the initialization of git, creation of the git repo, and pushing the app into the github repository:
desc "Git tasks"
task :git => :init do
print "Create a new GIT repository?(y/n): "
option = STDIN.gets.strip
case option
when /[^Yy]/
abort_message
end
sh 'git init'
puts "Adding a few items to .gitignore."
cp 'lib/tasks/.gitignore', '.', verbose: false
puts "Setting up git"
sh 'git add .'
sh 'git commit -m "Init" '
puts "Enter the link to your repository for this app."
repo = STDIN.gets.strip
sh "git remote add origin #{repo}"
sh 'git push -u origin master'
end
Since you have all the terminal commands at your disposal via the sh method, you can write a task to create a git branch with ease:
desc "Create a git branch"
task :git_branch => :git do
puts "Creating a git branch, just to be safe!"
sh 'git checkout -b Pre-development'
end
desc "Run all setup tasks"
task :all => [:init, :cleanup, :git, :git_branch] do
puts "DOne"
end
This is how our barebone tasks from earlier look if a bit of meat was added to them:
namespace :setup do
desc "Initiate setup. This task serves as a dependency for other tasks."
task :init do
print "Name of the destination directory: "
name = STDIN.gets.strip
#Calling gets by itself would result in a call to Kernel#gets which is not what we want. Switch to STDIN.gets instead.
if pwd().split('/').last == "Rake"
puts "Copying the files to #{name}/lib/tasks."
# Copying the rakefile over to lib/tasks of the destination directory. This is a Rails generated directory dedicated for rake tasks.
cp_r '.', "../#{name}/lib/tasks", verbose: false
print "Do you want to continue with the setup?(y/n): "
option = STDIN.gets.strip
case option
when /[^Yy]/
abort_message #A call to the abort_message method.
end
cd "../#{name}" #change directory to the root of the Rails app directory
end
end
def abort_message
abort("Exiting. You can each task individually. See rake -T for more info") #A handy method to exit early from a rake task. You can read more about it here.
end
desc "Cleanup Gemfile and other stuff."
task :cleanup => :init do
print "Clean up the standard Gemfile for a new one?(y/n): "
option = STDIN.gets.strip
case option
when /[^Yy]/
abort_message
end
puts "Setting a new Gemfile."
# Copying the gemfile from lib/tasks to the root of the project directory.
cp 'lib/tasks/Gemfile', '.', verbose: false
puts "Running bundle install. This may take a while...\n\n"
#sh bridges your task with the command-line bestowing upon you, the access to all the terminal commands.
sh "bundle install"
end
desc "Git tasks"
task :git => :init do
print "Create a new GIT repository?(y/n): "
option = STDIN.gets.strip
case option
when /[^Yy]/
abort_message
end
sh 'git init'
puts "Adding a few items to .gitignore."
cp 'lib/tasks/.gitignore', '.', verbose: false
puts "Setting up git"
sh 'git add .'
sh 'git commit -m "Init" '
puts "Enter the link to your repository for this app."
repo = STDIN.gets.strip
sh "git remote add origin #{repo}"
sh 'git push -u origin master'
end
desc "Task to create a new git branch"
task :git_branch => :git do
puts "Creating a git branch, just to be safe!"
sh 'git checkout -b Pre-development'
end
desc "Task to run all tasks under the setup namespace"
task :all => [:init, :cleanup, :git, :git_branch] do
puts "Done"
end
end
That’s a lot of code. However, it’s fairly easy to figure out what it does because, Ruby doesn’t complicate matters, but rather streamlines it to the point where a total stranger make sense of it.
Don’t Forget to DRY Up Your Code
The Rakefile looks a bit cluttered to me. Since it’s going to get pretty bad soon, we should refactor and clean it up a bit. The ideal solution is to keep the tasks neatly sorted into individual files and import them to the main Rakefile, like so:
Dir.glob('*.rake').each { |r| import r }
init.rake
namespace :setup do
desc "Initiate setup. This task serves as a dependency for other tasks."
task :init do
print "Name of the destination directory: "
name = STDIN.gets.strip
if pwd().split('/').last == "Rake"
puts "Copying the files to #{name}/lib/tasks."
cp_r '.', "../#{name}/lib/tasks", verbose: false
print "Do you want to continue with the setup?(y/n): "
option = STDIN.gets.strip
case_code(option)
cd "../#{name}"
else
puts "We are already on the destination directory"
end
end
def abort_message
abort("Exiting. You can each task individually. See rake -T for more info")
end
def case_code(option)
case option
when /[^Yy]/
abort_message
end
end
end
cleanup.rake
namespace :setup do
desc "Cleanup Gemfile and other stuff."
task :cleanup => :init do
print "Clean up the standard Gemfile for a new one?(y/n): "
option = STDIN.gets.strip
case_code(option)
puts "Setting a new Gemfile."
cp 'lib/tasks/Gemfile', '.', verbose: false
puts "Running bundle install. This may take a while...\n\n"
sh "bundle install"
end
end
git.rake
namespace :setup do
desc "Git tasks"
task :git => :init do
print "Create a new GIT repository?(y/n): "
option = STDIN.gets.strip
case_code(option)
sh 'git init'
puts "Adding a few items to .gitignore."
cp 'lib/tasks/.gitignore', '.', verbose: false
puts "Setting up git"
sh 'git add .'
sh 'git commit -m "Init" '
puts "Enter the link to your repository for this app."
repo = STDIN.gets.strip
sh "git remote add origin #{repo}"
sh 'git push -u origin master'
end
task :git_branch => :git do
puts "Creating a git branch, just to be safe!"
sh 'git checkout -b Pre-development'
end
end
all.rake
namespace :setup do
task :all => [:init, :cleanup, :git, :git_branch] do
puts "Done"
end
end
This benefits us in 2 ways,
- Our Rake tasks are now organized and easily accessible.
- You can call up these tasks at any stage of web development from the project’s root directory. If you will recall, I had mentioned that the files residing in lib/tasks will only be loaded if they have a
.rakeextension. Rake ignored our custom tasks earlier because we had stored them inside the Rakefile.
Rake can automate tons of tasks, which you thought were too trivial or too complex. This tutorial was written with the intention to get you started with Rake to make your life easier by doing things with less human intervention. Now that you’ve seen Rake in action, you shouldn’t have trouble widening your horizons and making the best use of it.
Frequently Asked Questions (FAQs) about Rake Automation
What is the basic structure of a Rakefile?
A Rakefile is a script file written in Ruby that contains tasks to be executed by the Rake tool. The basic structure of a Rakefile includes the task name, dependencies (if any), and the actions to be performed. Each task is defined using the keyword ‘task’, followed by the task name and an optional list of dependencies. The actions are enclosed within a do-end block. Here’s a simple example:task :default => [:test]task :test do
ruby "test/unittest.rb"end
In this example, the ‘default’ task depends on the ‘test’ task, which runs a unit test script.
How can I pass arguments to a Rake task?
Rake allows you to pass arguments to tasks using square brackets after the task name. The arguments are then accessed within the task using the args keyword. Here’s an example:task :greet, [:name] do |t, args|
puts "Hello, #{args.name}!"end
In this example, the ‘greet’ task accepts a ‘name’ argument, which is then used in the greeting message.
How can I list all available Rake tasks?
You can list all available Rake tasks using the ‘rake -T’ command in the terminal. This will display a list of all tasks defined in the Rakefile, along with their descriptions. If a task does not have a description, it will not be listed.
How can I set a default task in Rake?
You can set a default task in Rake by defining a task named ‘default’. This task will be executed when you run the ‘rake’ command without specifying a task name. The ‘default’ task usually depends on other tasks, which are executed in the order they are listed.
Can I use Rake with Rails?
Yes, Rake is often used with Rails to automate various tasks such as database migrations, testing, and generating code. Rails comes with a number of predefined Rake tasks, which can be listed using the ‘rake -T’ command. You can also define your own tasks in the lib/tasks directory.
How can I run a specific Rake task?
You can run a specific Rake task using the ‘rake’ command followed by the task name. For example, ‘rake test’ will run the ‘test’ task. If the task accepts arguments, they can be passed in square brackets after the task name, like ‘rake greet[name]’.
Can I define dependencies between Rake tasks?
Yes, you can define dependencies between Rake tasks by listing the dependent tasks in an array after the task name. When the task is run, the dependent tasks will be executed first, in the order they are listed.
How can I write a description for a Rake task?
You can write a description for a Rake task using the ‘desc’ keyword followed by the description text. The description will be displayed when you list the tasks using the ‘rake -T’ command.
Can I use Rake to automate non-Ruby tasks?
Yes, Rake is not limited to automating Ruby tasks. You can use it to automate any task that can be scripted, such as shell commands, file operations, and network requests.
How can I debug a Rake task?
You can debug a Rake task by inserting ‘debugger’ statements at the points where you want to pause execution and inspect the program state. When the task is run, execution will stop at the ‘debugger’ statement, and you can use the debugger commands to step through the code, inspect variables, and so on.