


Key Takeaways
- Non-relational databases, such as DynamoDB and MongoDB, provide more flexibility in handling various data types and structures, making them an optimal choice for managing mixed workloads in applications like e-commerce inventory management. They can process data of various formats swiftly, saving significant time and effort during app development and iteration cycles.
- DynamoDB and MongoDB, while both non-relational, have different capabilities. DynamoDB requires additional products for complex queries, while MongoDB has an expressive query language that can serve various use cases, including in-place analytics without moving data to another system. This makes MongoDB a simpler and more efficient option for supporting mixed workloads.
- MongoDB’s fully managed service, Atlas, offers features like automated failover and replication to ensure high availability. It also allows adding extra replica nodes for workload isolation, ensuring that long-running analytical queries do not impact the performance of transactional workloads. Atlas also provides a self-service analytics tool, MongoDB Charts, that runs natively on MongoDB data, providing accurate, live data for business intelligence.
This article was created in partnership with MongoDB. Thank you for supporting the partners who make SitePoint possible.
Suppose that you’re building an e-commerce platform and as part of the exercise, you need to come up with a new data architecture for inventory management. You need to support fast, transactional workloads to actually keep track of inventory in near real-time.
The business would also like to be able to answer questions such as “based on historical data, when should we restock on widgets and gizmos?” and “who are the people that are buying widgets and generally, where are they located?” Your data architecture needs to support mixed workloads.
Where would you start?
For the transactional component, you would likely realize that you need an operational database — that is, one that allows you to conduct read, write, and update operations on your data. This should make sense as you would need to not only know how many widgets you have in your inventory but also be able to update that number when a customer purchases a widget. And you’d also need to make sure that your data layer is able to serve up a consistent view of the data to any connected applications. Otherwise, your soon-to-be unhappy customers would find themselves putting items in their carts that are not actually available.
To support your transactional workload, there is no shortage of operational databases to choose from as the underlying technologies go back 40 years. For applications that need to handle a variety of data types and data structures, such as our inventory application, many companies have opted for newer non-relational options in lieu of relational databases such as Oracle, MySQL, or SQL Server.
This is because non-relational databases, which do not store data in rows and columns as relational databases do, offer more flexibility in their ability to ingest and process data of various formats and shapes, saving significant amounts of time and effort during both app development and iteration cycles. Designed to scale vertically (“get a bigger machine”), traditional relational databases also have a difficult time supporting distributed requests with low latency and can run into performance limitations. This could be problematic if we have geographically distributed customers or unexpected peaks in application usage.
For the purposes of discussing data architectures to support mixed workloads, let’s compare implementation with two popular non-relational operational databases : DynamoDB, which is a non-relational database service developed at AWS; and MongoDB, one of the most popular non-relational databases.
Mixed Workloads with DynamoDB
DynamoDB is a fully managed cloud database service that stores data as a collection of key-value pairs in which a key serves as a unique identifier. Both keys and values can be anything, ranging from simple objects to complex compound objects. This makes the ingestion and persistence of a large variety of data far simpler compared to using a relational database.
However, for anything beyond simple queries such as the analytics we want our data architecture to support, AWS recommends that you use additional products such as Amazon EMR, Amazon Redshift, and others.
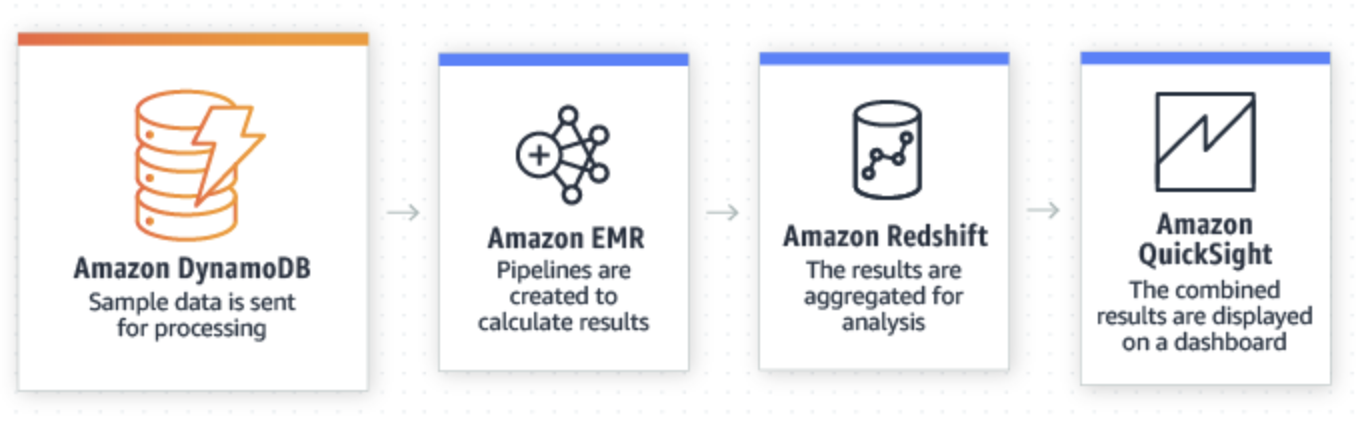
Source: https://aws.amazon.com/dynamodb/
This is because the expressive power of the DynamoDB query language, or in simpler terms, the breadth of ideas that can be represented and communicated using DynamoDB’s query language, is somewhat limited. This quality is quite common amongst non-relational databases — sometimes referred to as “NoSQL” databases — which optimized for data model flexibility and scalability, oftentimes at the expense of core database functionality.
As you can tell from the recommended pattern above, data is stored in DynamoDB, then moved to Amazon EMR, which provides a managed big data framework, for processing. The data is then piped to Amazon Redshift, a managed data warehouse for aggregation. Finally, Amazon Quicksight, a business intelligence tool, can use the aggregated data to create charts and dashboards that business users can leverage.
There are quite a few moving parts in this data architecture, not to mention the added complexity of learning to work with, building on, and operating multiple components (offset some by using managed services rather than building it all on your own) and costs. And since data is being moved from system to system, there is a very good possibility that the data represented in the charts and dashboards on one end is inconsistent with the actual state of things in the source database.
There’s nothing fundamentally wrong with this approach as long as you’re okay with the caveats above but let’s look at another one.
Mixed Workloads with MongoDB
MongoDB is similar to DynamoDB in a few ways:
- It’s a non-relational database
- It’s available as a fully managed cloud database through MongoDB Atlas
For the most part, that’s where the similarities end. Unlike DynamoDB, data is stored in JSON-like documents. Documents can contain as many key-value pairs or complex nested structures as an application requires. MongoDB also has an expressive query language which differentiates it from other non-relational databases. Not only is it easy to get data into the database, but it’s also easy to get data back out in ways that can serve a variety of use cases. For example, the database has an aggregation framework that allows you to perform analytics in-place without moving data to another system.
This means our data architecture for supporting mixed workloads can be a lot simpler. If we remove Amazon EMR and Amazon Redshift (or the equivalent services from your cloud provider), we’re left with the database and our business intelligence or dashboarding tool of choice.
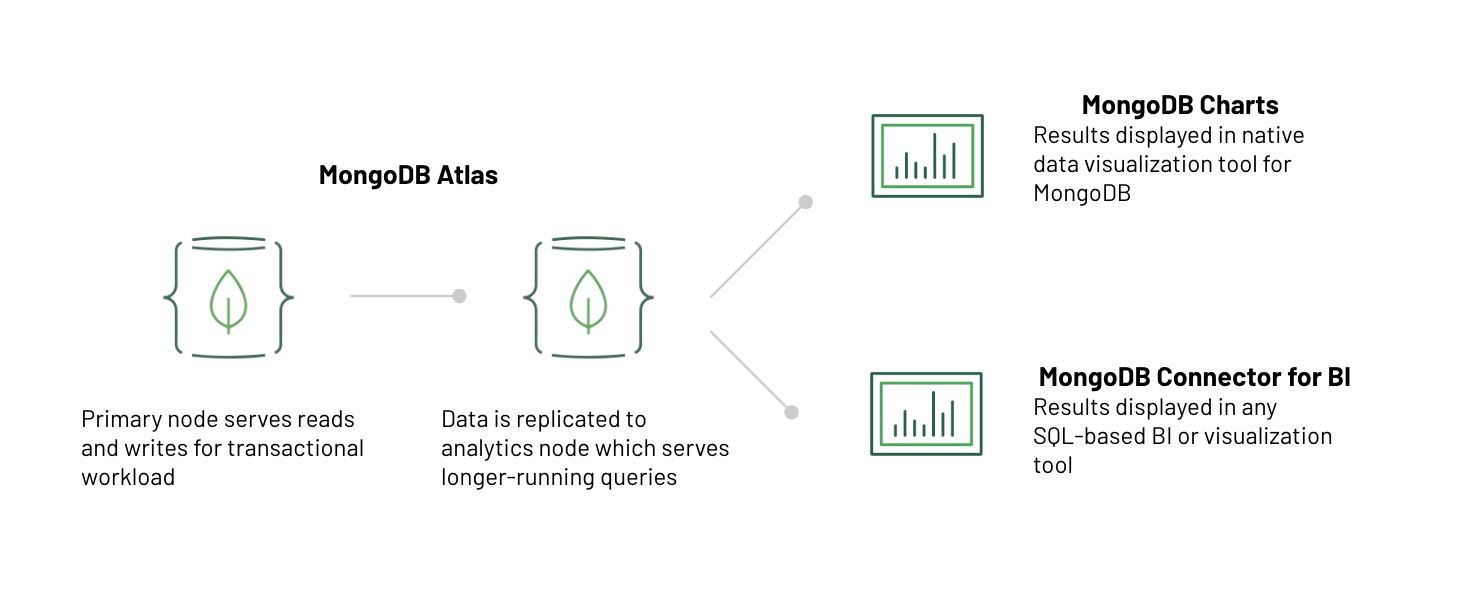
We do have another thing to consider, however — how do we ensure that analytical queries, which are typically longer-running than those supporting a transactional workload, do not impact the performance of the overall system? Luckily, MongoDB has an answer for that as well. The database natively supports replication and automated failover to ensure high availability but replica nodes can also be added and used to isolate specific workloads and queries.
Atlas, the fully managed service for MongoDB, allows you to create a database cluster and add extra replica nodes for workload isolation (called specialized ‘analytics’ nodes) with the click of a button or simple API call. Any long-running analytical queries would hit these analytics nodes, ensuring that the performance of transactional workloads is entirely unaffected.
Atlas also provides a self-service analytics tool in the cloud called MongoDB Charts, which runs natively on MongoDB data with no data movement or transformations. This gives you more accurate information about the true state of things because the BI tool leverages live data.
Note that because you’d be running analytical queries against a replica, there’s also the possibility of eventual consistency. The “lag” in this scenario is likely to be shorter as it’s tied to the delay between operation on the “primary” replica and the application of that operation to the analytics replica, and not physically moving data across multiple disparate systems as shown in the previous architecture.
There you have it — two different data architectures for supporting mixed workloads using non-relational databases. Each has its trade-offs. If you require complex analytics on your transactional data, it may be worth the added complexity, latency, and cost to transform your data and move it through Amazon EMR and Amazon Redshift.
However, the analytics questions raised at the beginning of this article don’t call for this level of complexity. By selecting a database that allows you to run analytics in-place AND a way to isolate those workloads to ensure minimal performance impact to real-time operations, your architecture can be much simpler and easier to work with.
Frequently Asked Questions on Non-Relational Databases and Supporting Mixed Workloads
What are the key differences between relational and non-relational databases?
Relational databases are based on a relational model where data is stored in tables and relationships are formed using primary and foreign keys. They follow ACID (Atomicity, Consistency, Isolation, Durability) properties ensuring data integrity. Non-relational databases, on the other hand, do not use tables for data storage. They can store data in various formats like key-value pairs, wide-column, graph, or document-oriented. They follow the CAP theorem (Consistency, Availability, Partition tolerance) and are more flexible and scalable than relational databases.
How does a non-relational database support mixed workloads?
Non-relational databases are designed to handle mixed workloads efficiently. They can manage different types of data and perform various operations simultaneously. They can handle high-velocity, high-volume data from different sources and are capable of performing real-time analytics. This makes them ideal for big data and real-time web applications.
What are the advantages of using non-relational databases?
Non-relational databases offer several advantages. They provide high scalability and flexibility to handle diverse data types and large volumes of data. They are capable of distributed computing, which allows for easy and efficient data processing. They also offer high performance and are capable of handling high-velocity data.
Are non-relational databases better than relational databases?
The choice between relational and non-relational databases depends on the specific requirements of your project. Non-relational databases are ideal for handling big data and real-time applications, while relational databases are suitable for transactions requiring high data integrity.
What are some examples of non-relational databases?
Some popular non-relational databases include MongoDB, Cassandra, Redis, and Couchbase. Each of these databases has its own unique features and is used for specific purposes.
What is a mixed workload and how does it impact database performance?
A mixed workload refers to a variety of operations performed on a database simultaneously. It can include read and write operations, batch processing, real-time analytics, and more. Handling mixed workloads efficiently is crucial for maintaining high database performance.
How can I optimize a non-relational database for mixed workloads?
Optimizing a non-relational database for mixed workloads involves several strategies. These include proper indexing, efficient data modeling, using appropriate data types, and implementing effective sharding strategies.
What is the role of non-relational databases in big data?
Non-relational databases play a crucial role in big data. They can handle large volumes of structured and unstructured data efficiently. They also support distributed computing, which is essential for processing big data.
Can non-relational databases handle transactions?
Yes, non-relational databases can handle transactions. However, they follow the BASE (Basically Available, Soft state, Eventually consistent) model instead of the ACID model followed by relational databases.
What are the challenges of using non-relational databases?
While non-relational databases offer several advantages, they also come with challenges. These include complexity in data modeling, potential issues with data consistency, and the need for specialized skills to manage and optimize these databases.