
Key Takeaways
- Trees, facets, and tags are all methods of organizing content, with trees being the oldest and most traditional, facets allowing for multiple categorizations, and tags offering flexible and user-driven organization.
- While trees provide a rigid structure that can be beneficial for clarity and inheritance modeling, they require careful planning and can be restrictive when content could fit into multiple categories.
- Tags are effective for focused topics and smaller data sets, allowing for categorization after content creation, but can be messy and confusing if not managed properly due to issues like synonyms, abbreviations, and homonyms.
- Facets work well with structured content and offer users the freedom to filter based on multiple dimensions in the order they prefer, but they require the content to be somewhat structured to be effective.
This article discusses the state of trees as a content organization structure in modern CMS as opposed to other approaches.
Update 18th Feb, 2015: This post got a reply from Contentful, which you can read here.
For several years I have been interested in content repositories as a key aspect of modern CMS. With “modern”, I mean CMS that are not just “page management systems” but CMS that actually manage content, thereby enabling authors to reuse their content on different devices and even different applications. This interest culminated in the creation of PHPCR and its reference implementation Jackalope. In this spirit, I was very intrigued by services like prismic.io and contentful.com that essentially provide a content repository as a service. I was especially impressed by Prismic’s UI. But when evaluating these systems, I noticed a surprising trend: they do not leverage trees, neither as a native storage concept nor as a visualization concept. Instead, they for the most part rely on flat structures with tagging. My gut feeling was telling me that this was a mistake, especially when managing larger content repositories. At the same time I wondered: “Am I just a dinosaur that is missing the ark?”.

I discussed the topic with Ekke at a conference last fall and after a short Twitter exchange we decided to write down our thoughts. I found additional inspiration in an article by David Weinberger who helped put my feelings in a historical context as well as explaining the advantages of different approaches to content organization, namely: trees, facets and tags. Additionally, I also want to mention the concept of references since they are supported by Contentful.
Introduction
Trees are the oldest of the methods mentioned above. The reason for this is likely that they work great in the physical world, ie. good old paper books, as they require no content duplication. That is, every piece of information is placed in exactly one place. The fact that trees have been around so long also gives them one distinct advantage: everyone knows how they work. Facets and tags, however, very much leverage the new possibilities of the digital age in that content can easily live in several places at once. But just because trees predate the digital age does not make them a dinosaur waiting for extinction. Let us first look at some of the advantages and disadvantages of facets and tags.
Tags
Lets start with the latter. Tags likely gained the most popularity with the advent of blogs. Fundamentally, blogs are otherwise a flat, chronologically sorted list of content pieces. Tags added an effective way to denote the main focus topics of a given article while also providing a useful filter criteria. By combining multiple tags in a filter it becomes possible in many cases to quickly drill down. Moreover, as each tag essentially stands on its own, adding a new tag is trivial. Simply begin using the new tag and it exists. This is simpler than a tree structure, where it is necessary to decide where in the tree a new topic best fits.

As such tags are also useful for allowing crowd sourced categorization. But here we also come to the main pain point of tagging: its inherently messy. Trying to stay on top of synonyms and abbreviations and typos that unintentionally place content in different “buckets” requires almost as much work as placing a topic into a tree structure and can lead to confusion when tags are later renamed/merged. Another approach can, of course, be to strictly control the creation of tags to prevent these issues from occurring but then one loses a lot of the reasons why tags are useful. Furthermore, homonyms cause major problems with tagging. For example the tag “apple” could relate to a fruit or to the computer company. A common solution is to then introduce tags like “apple fruit”, but with that tags lose a lot of their elegance. This brings us back to exactly why tags are so popular on blogs. Blogs were originally used for personal digital diaries, thereby reducing the risk of synonyms by different authors causing duplicate tags for the same topic. Also they usually focused on a specific topic which thereby reduced the chances of homonyms.
Facets
Facets have become especially popular in e-commerce sites to allow users to filter based on multiple dimensions in the order they prefer. However, they basically require content to be somewhat structured to be effective. Whereas chapters in a book usually just provide a title following a lot of text, for facets, one should further work to split the text into more structured pieces of information. It is not necessary to have the same structure for all pieces of content, however. Furthermore, just like with tags, with facets it becomes possible to find the same piece of information in different places.
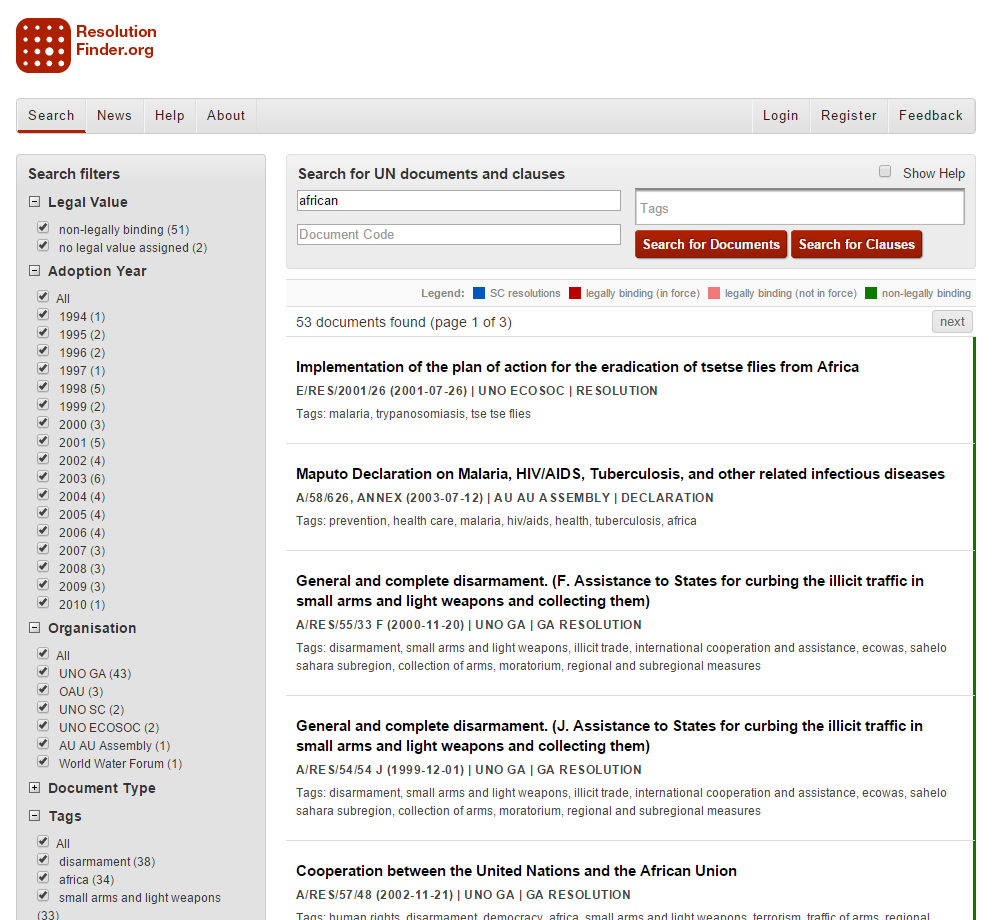
Facets are specifically useful when it is very hard to anticipate which strategy someone will use to find the given piece of content. Going back to the e-commerce example – one user might focus on the price first, then on the color and then on the fabric with the next user potentially wanting to drill down in a totally different order. Furthermore facets are great because they allow non domain expert users to discover the relevant dimensions simply by looking at the left over facets as they add filters. As a content provider, it also becomes quite easy to offer new facets by simply starting to fill in some new “facets”. That being said it is also possible to run into issues with homonyms when searching across different content types, but its much less likely than with tags. For example a status property might be a numeric value for some pieces of content and or a simple flag for others. In this case, with some additional work, it might even be possible to translate the flag to a numeric value on the fly.
References
References have also been around for a long time. With the digital age, it has become much easier to follow a reference. Since the pre-digital age, they’ve been a popular addition to physical books in the form of footnotes and indexes. On the web, a reference is just a click away and can even be inlined if needed (for example, browsers inline image references). Images, or rather media content in general, are a good example of references used in many CMS.

Often text content and media content is kept in separate storage containers that are just connected via references. This is likely because creation of media content requires different skills and resources while also requiring significantly more storage, which means the technical challenges are also not the same. As such, media content is often reused, hence the logical use of references. References are a very powerful tool from which one can effectively build not only tree but also graph structures. But this additional power also means it becomes very hard to visualize and therefore comprehend the actual data structure without actively traversing it. Querying a graph structure tends to require expert knowledge and providing a performant experience is also a non trivial challenge solved only by very specialized systems.
Trees
Which brings us back to trees. The main drawback of trees is, to some extent, also their biggest advantage: the rigid allocation of content to a single place in the tree. This requires careful planning and can lead to iffy situations where one piece of content could be placed in multiple categories. For example, an article about the economics in sports, could be placed under “economics” or “sports”. This can of course be solved via references, but as pointed out above, the overuse of references as a means to structure content can cause problems.
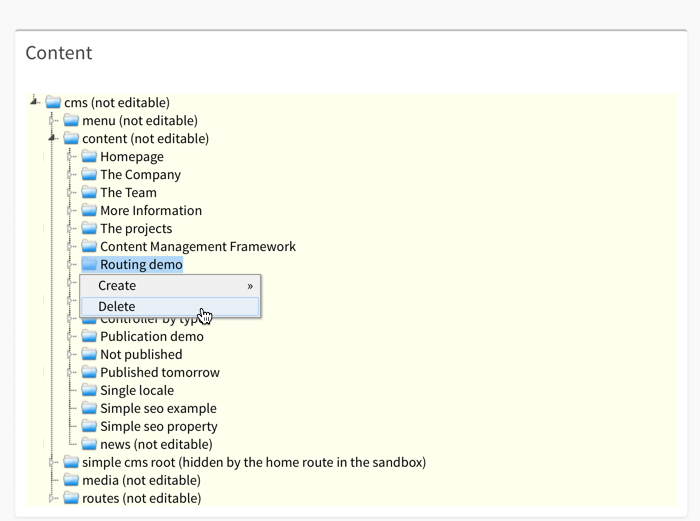
On the other hand, this rigidness also gives things a lot of clarity. Most importantly, trees can be used as a very simple way to model inheritance that is understandable even for non developers. In this way the location, the context of the content in the tree, provides an important piece of information. For example, placing an article under “sports” expresses that this article is about sports. But it can express multiple things on top of that. Going back to the above dilemma about the “economics in sports” article, placing the article in one or the other category can also be used to determine responsibility. That is, by placing it under “sports” it can also automatically assign rights to all the sports editors. Interestingly it can also help to bridge back to the physical world to, for example, determine where in the print version the article will appear.
The categorization inside a tree also enables weighting of facets so to say. If I use economics vs. sports in the first dimension and the publication date as the second, I steer people towards the ideal way to explore the content. Is the emphasis of the content on giving a snapshot of information for a specific date or is it rather on the specific topic? Obviously in practice, most tree structures also support references and as I said before, references can be used to build tree structures themselves. But the true power of a tree structure lies in the context and the natural visualization they provide. Forcing as much content to remain within the limitations of a tree ensures that this metaphor remains useful, where as overusing references will mean that it becomes ineffective requiring a much more complicated visualization of a graph.
tl;dr;
In summary, it becomes clear that all above mentioned systems have their advantages.
Tags are great for managing content structure that exhibits one or all of the below criteria:
- focused on a specific topic
- small data set
- categorization can be done after content creation
Faceting is mostly useful for content with the following attributes:
- content is “structured” in the sense that different facets of the content can be sensible separated and be given attribute names
- there is no singular way that users are expected to explore the content
References or rather graphs are ideal when:
- the content creation is very distinct
- the content itself is highly interrelated
Finally, trees are ideal:
- when most content fits into a rigid structure
- when there are experts with sufficient amount of time to properly place content into the structure
In practice, we of course see a lot of hybrid systems. That is, many blogs support tagging along with categories (essentially a tree with a depth of one). Many tree storage systems also support references which effectively also enable graphs.
Conclusion
My personal takeaway is that any CMS managing any sizeable amount of data needs to support trees. Anything else will lead to an unmanageable mess. However, systems with smaller sets of content, especially with a smaller group of authors, can get away with tagging as well. Facetting only really works well with a system that stores content that is highly structured at least on a per node type basis. In this spirit, I maintain that repository as a service providers will need to provide full support for trees, both to structure as well as visualized content, in order to become able to handle larger volumes of data. Faceting will also need to be provided if they intend to make inroads from doing more than just serving large chunks of text and media content.
I would like to thank Ekke and David for reviewing this article and proposing various improvements
Frequently Asked Questions (FAQs) about Content Organization Structures: Trees, Facets, and Tags
What are the key differences between trees, facets, and tags in content organization?
Trees, facets, and tags are all methods of organizing content, but they differ in their approach. A tree structure is hierarchical, with content organized in a top-down manner, like a family tree. Facets, on the other hand, allow for multiple categorizations, enabling users to filter and sort content based on various attributes. Tags are keywords or phrases assigned to content, allowing for flexible and user-driven organization.
How do I choose the right content organization structure for my website?
The choice of content organization structure depends on the nature of your content and the needs of your users. If your content naturally falls into a hierarchical structure, a tree might be the best choice. If your content can be categorized in multiple ways, facets could be more suitable. If you want to give users the freedom to categorize content as they see fit, tags might be the best option.
Can I use more than one content organization structure on my website?
Yes, it’s possible to use a combination of trees, facets, and tags to organize your content. This can provide a more flexible and user-friendly experience, allowing users to navigate and find content in a way that suits them best.
What are the advantages and disadvantages of using tags for content organization?
Tags offer a lot of flexibility and can be user-driven, allowing users to categorize content in a way that makes sense to them. However, they can also lead to inconsistency and confusion if not managed properly, as different users might use different tags for the same content.
How can I effectively manage tags on my website?
Effective tag management involves setting clear guidelines for tag usage, regularly reviewing and updating tags, and using a tag management system if necessary. It’s also important to educate users about the purpose and benefits of tags, and how to use them effectively.
What are some examples of websites that use facets for content organization?
Many e-commerce websites use facets for content organization. For example, online clothing stores often allow users to filter products by size, color, brand, price, and other attributes. This makes it easier for users to find exactly what they’re looking for.
How can I implement a tree structure on my website?
Implementing a tree structure involves organizing your content into categories and subcategories in a hierarchical manner. This can be done manually, or with the help of a content management system that supports tree structures.
What are some best practices for using facets for content organization?
Best practices for using facets include keeping the number of facets manageable, using clear and descriptive facet names, and regularly reviewing and updating facets to ensure they remain relevant and useful.
Can tags improve the SEO of my website?
Yes, tags can improve the SEO of your website by providing additional context and keywords for search engines. However, it’s important to use tags judiciously and avoid keyword stuffing, as this can harm your SEO.
How can I measure the effectiveness of my content organization structure?
You can measure the effectiveness of your content organization structure by tracking metrics like page views, time spent on page, bounce rate, and user feedback. If users are able to find and engage with your content easily, this is a good indication that your content organization structure is effective.