


In this guide, you’ll learn regex, or regular expression syntax. By the end, you’ll be able to apply regex solutions in most scenarios that call for it in your web development work.
Key Takeaways
-
Understanding and Using Regex: Regular expressions, or regex, are powerful tools for finding or matching patterns in strings. This guide introduces the basics of regex syntax, including metacharacters, character sets, and flags, enabling you to apply regex solutions effectively in web development scenarios. It demystifies the complexity of regex by breaking down the syntax into understandable parts, demonstrating how to match various patterns including digits, letters, and specific character combinations.
-
Practical Applications of Regex: Regex has a wide range of real-world applications in web development, from form input validation and web scraping to search-and-replace operations and filtering information in large text files. The guide emphasizes the versatility and utility of regex by providing examples and exercises that reflect common tasks developers encounter, showing how regex can simplify and automate these processes.
-
Building and Testing Regex Patterns: A crucial part of mastering regex involves building and testing patterns to ensure they match the desired criteria. Tools like Regex101 are highlighted as essential for experimenting with regex patterns in a supportive environment. This hands-on approach, combined with explanations of regex flags (such as global and case-insensitive flags), character sets, and special characters, equips you with the skills to construct efficient regex expressions and apply them to validate input, such as email addresses, in your projects.
What is Regex?
Regex, or regular expressions, are special sequences used to find or match patterns in strings. These sequences use metacharacters and other syntax to represent sets, ranges, or specific characters. For example, the expression [0-9] matches the range of numbers between 0 and 9, and humor|humour matches both the strings “humor” and “humour”.
Regular expressions have many real world uses cases, which include:
- form input validation
- web scraping
- search and replace
- filtering for information in massive text files such as logs
They may look complicated and intimidating for new users. Take a look at this example:
/^[a-zA-Z0-9.!#$%&’*+/=?^_`{|}~-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)*$/
It just look like garbled text. But don’t despair, there’s method behind this madness.
In this guide I’ll show you how to master regular expressions but first, let’s clarify the terminology used in this guide:
- pattern: regular expression pattern
- string: test string used to match the pattern
- digit: 0-9
- letter: a-z, A-Z
- symbol: !$%^&*()_+|~-=`{}[]:”;'<>?,./
- space: single white space, tab
- character: refers to a letter, digit or symbol

Credit: xkcd
Basics
To learn regex quickly with this guide, visit Regex101, where you can build regex patterns and test them against strings (text) that you supply.
When you open the site, you’ll need to select the JavaScript flavor, as that’s what we’ll be using for this guide. (Regex syntax is mostly the same for all languages, but there are some minor differences.)
Next, you need to disable the global and multi line flags in Regex101. We’ll cover them in the next section. For now, we’ll look at the simplest form of regular expression we can build. Input the following:
- regex input field: cat
- test string: rat bat cat sat fat cats eat tat cat mat CAT
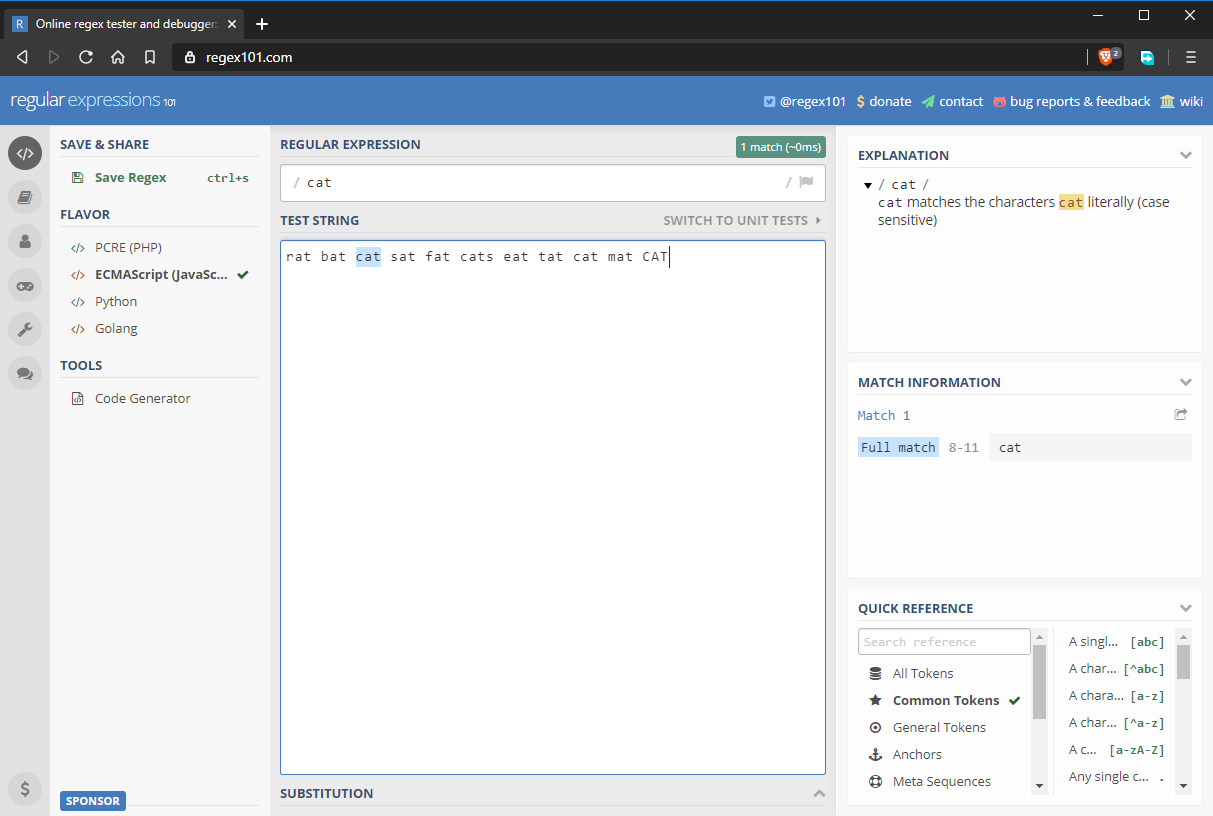
Take note that regular expressions in JavaScript start and end with /. If you were to write a regular expression in JavaScript code, it would look like this: /cat/ without any quotation marks. In the above state, the regular expression matches the string “cat”. However, as you can see in the image above, there are several “cat” strings that are not matched. In the next section, we’ll look at why.
Global and Case Insensitive Regex Flags
By default, a regex pattern will only return the first match it finds. If you’d like to return additional matches, you need to enable the global flag, denoted as g. Regex patterns are also case sensitive by default. You can override this behavior by enabling the insensitive flag, denoted by i. The updated regex pattern is now fully expressed as /cat/gi. As you can see below, all “cat” strings have been matched including the one with a different case.
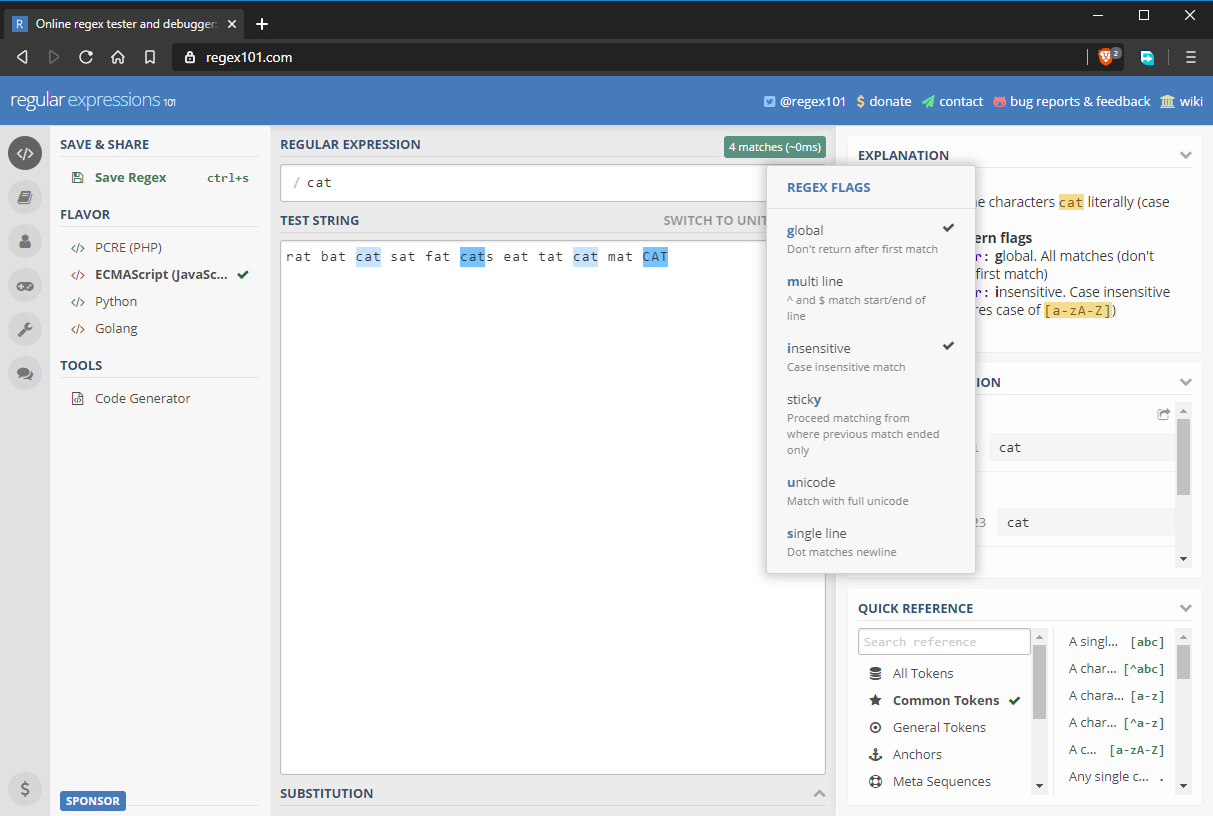
Character Sets
In the previous example, we learned how to perform exact case-sensitive matches. What if we wanted to match “bat”, “cat”, and “fat”. We can do this by using character sets, denoted with < brackets — code>[]. Basically, you put in multiple characters that you want to get matched. For example, [bcf]at will match multiple strings as follows:
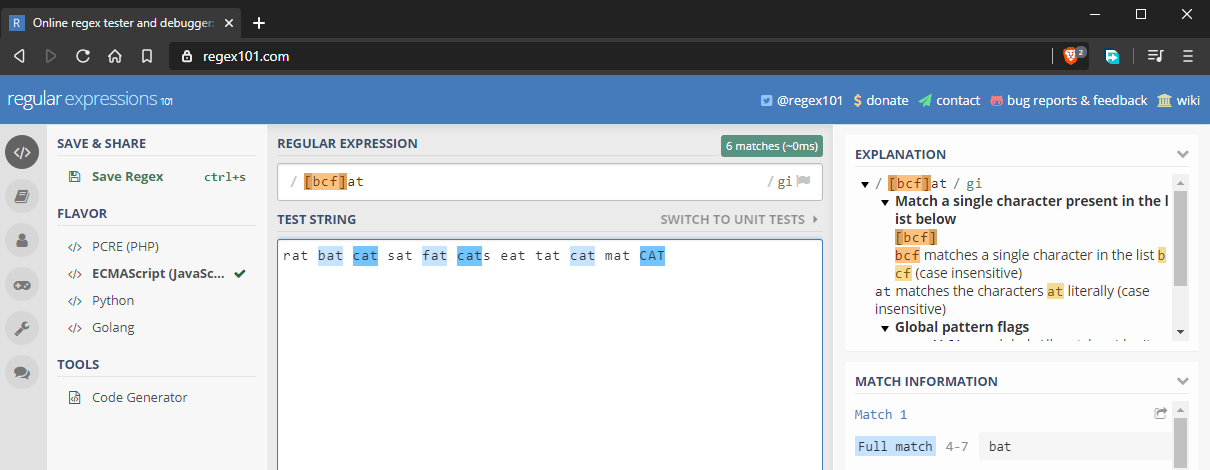
Character sets also work with digits.
Ranges
Let’s assume we want to match all words that end with at. We could supply the full alphabet inside the character set, but that would be tedious. The solution is to use ranges like this [a-z]at:
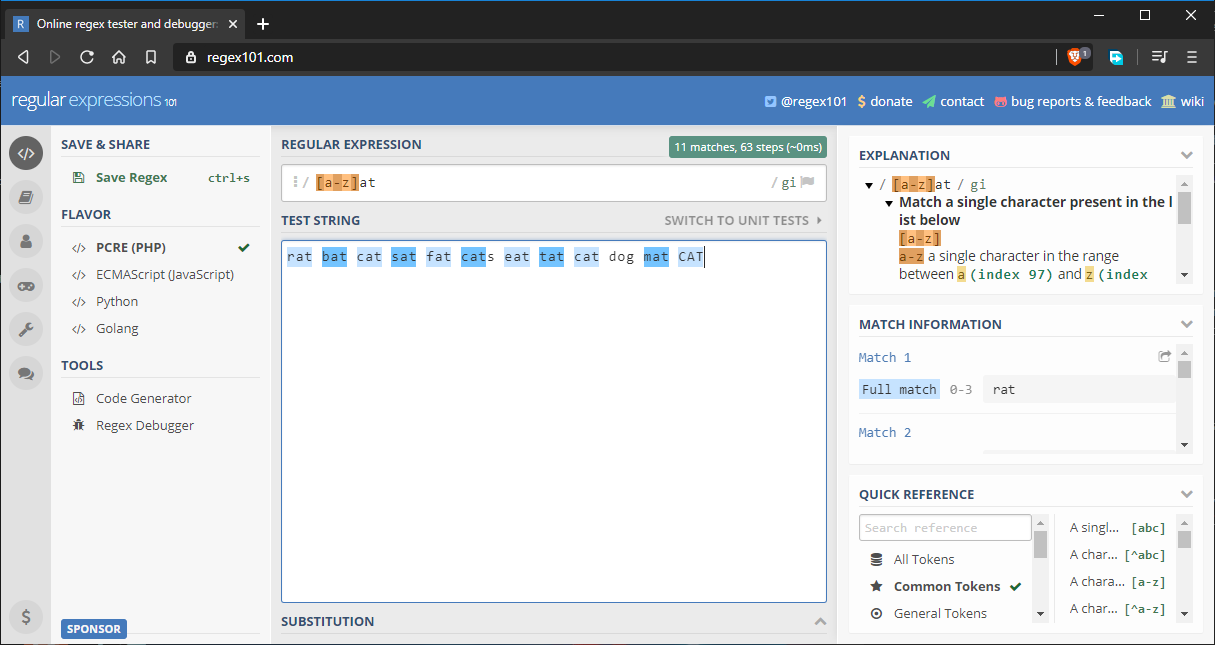
Here’s the full string that’s being tested: rat bat cat sat fat cats eat tat cat dog mat CAT.
As you can see, all words are matching as expected. I’ve added the word dog just to throw in an invalid match. Here are other ways you can use ranges:
- Partial range: selections such as
[a-f]or[g-p]. - Capitalized range:
[A-Z]. - Digit range:
[0-9]. - Symbol range: for example,
[#$%&@]. - Mixed range: for example,
[a-zA-Z0-9]includes all digits, lower and upper case letters. Do note that a range only specifies multiple alternatives for a single character in a pattern.To further understand how to define a range, it’s best to look at the full ASCII table in order to see how characters are ordered.

Repeating Characters
Let’s say you’d like to match all three-letter words. You’d probably do it like this:
[a-z][a-z][a-z]
This would match all three-letter words. But what if you want to match a five- or eight-character word. The above method is tedious. There’s a better way to express such a pattern using the {} curly braces notation. All you have to do is specify the number of repeating characters. Here are examples:
a{5}will match “aaaaa”.n{3}will match “nnn”.[a-z]{4}will match any four-letter word such as “door”, “room” or “book”.[a-z]{6,}will match any word with six or more letters.[a-z]{8,11}will match any word between eight and 11 letters. Basic password validation can be done this way.[0-9]{11}will match an 11-digit number. Basic international phone validation can be done this way.
Metacharacters
Metacharacters allow you to write regular expression patterns that are even more compact. Let’s go through them one by one:
\dmatches any digit that is the same as[0-9]\wmatches any letter, digit and underscore character\smatches a whitespace character — that is, a space or tab\tmatches a tab character only
From what we’ve learned so far, we can write regular expressions like this:
\w{5}matches any five-letter word or a five-digit number\d{11}matches an 11-digit number such as a phone number
Special Characters
Special characters take us a step further into writing more advanced pattern expressions:
+: One or more quantifiers (preceding character must exist and can be optionally duplicated). For example, the expressionc+atwill match “cat”, “ccat” and “ccccccccat”. You can repeat the preceding character as many times as you like and you’ll still get a match.?: Zero or one quantifier (preceding character is optional). For example, the expressionc?atwill only match “cat” or “at”.*: Zero or more quantifier (preceding character is optional and can be optionally duplicated). For example, the expressionc*atwill match “at”, “cat” and “ccccccat”. It’s like the combination of+and?.\: this “escape character” is used when we want to use a special character literally. For example,c\*will exactly match “c*” and not “ccccccc”.[^]: this “negate” notation is used to indicate a character that should not be matched within a range. For example, the expressionb[^a-c]ldwill not match “bald” or “bbld” because the second letters a to c are negative. However, the pattern will match “beld”, “bild”, “bold” and so forth..: this “do” notation will match any digit, letter or symbol except newline. For example,.{8}will match a an eight-character password consisting of letters, numbers and symbols. for example, “password” and “P@ssw0rd” will both match.
From what we’ve learned so far, we can create an interesting variety of compact but powerful regular expressions. For example:
.+matches one or an unlimited number of characters. For example, “c” , “cc” and “bcd#.670” will all match.[a-z]+will match all lowercase letter words irrespective of length, as long as they contain at least one letter. For example, “book” and “boardroom” will both match.
Groups
All the special characters we just mentioned only affect a single character or a range set. What if we wanted the effect to apply to a section of the expression? We can do this by creating groups using round brackets — (). For example, the pattern book(.com)? will match both “book” and “book.com”, since we’ve made the “.com” part optional.
Here’s a more complex example that would be used in a realistic scenario such as email validation:
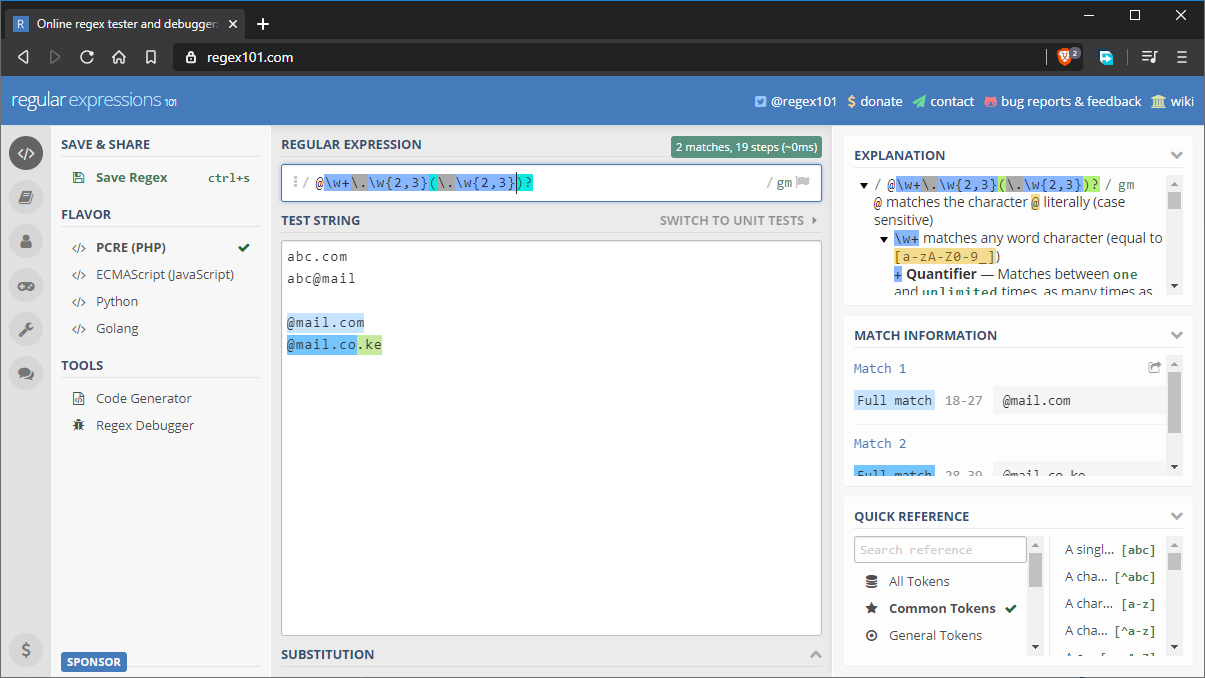
- pattern:
@\w+\.\w{2,3}(\.\w{2,3})? - test string:
abc.com abc@mail @mail.com @mail.co.ke
Alternate Characters
In regex, we can specify alternate characters using the “pipe” symbol — |. This is different from the special characters we showed earlier as it affects all the characters on each side of the pipe symbol. For example, the pattern sat|sit will match both “sat” and “sit” strings. We can rewrite the pattern as s(a|i)t to match the same strings.
The above pattern can be expressed as s(a|i)t by using () parentheses.
Starting and Ending Patterns
You may have noticed that some positive matches are a result of partial matching. For example, if I wrote a pattern to match the string “boo”, the string “book” will get a positive match as well, despite not being an exact match. To remedy this, we’ll use the following notations:
^: placed at the start, this character matches a pattern at the start of a string.$: placed at the end, this character matches a pattern at the end of the string.
To fix the above situation, we can write our pattern as boo$. This will ensure that the last three characters match the pattern. However, there’s one problem we haven’t considered yet, as the following image shows:
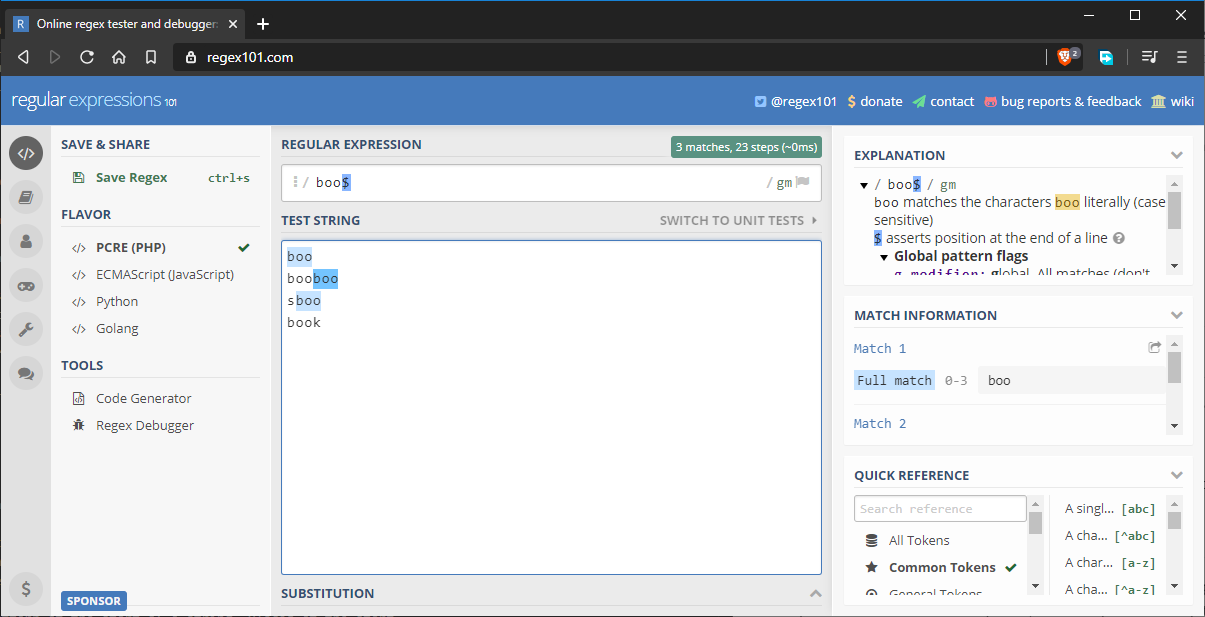
The string “sboo” gets a match because it still fulfills the current pattern matching requirements. To fix this, we can update the pattern as follows: ^boo$. This will strictly match the word “boo”. If you use both of them, both rules are enforced. For example, ^[a-z]{5}$ strictly matches a five-letter word. If the string has more than five letters, the pattern doesn’t match.
Regex in JavaScript
// Example 1
const regex1=/a-z/ig
//Example 2
const regex2= new RegExp(/[a-z]/, 'ig')
If you have Node.js installed on your machine, open a terminal and execute the command node to launch the Node.js shell interpreter. Next, execute as follows:
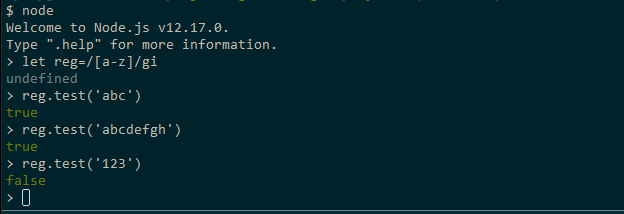
Feel free to play with more regex patterns. When done, use the command .exit to quit the shell.
Real World Example: Email Validation with regex
As we conclude this guide, let’s look at a popular usage of regex, email validation. For example, we might want to check that an email address a user has entered into a form is a valid email address.
This subject is more complicated than you might think. The email address syntax is quite simple: {name}@{domain}. In theory, an email address can contain a limited number of symbols such as #-@&%. etc. However, the placement of these symbols matters. Mail servers also have different rules on the use of symbols. For example, some servers treat the + symbol as invalid. In other mail servers, the symbol is used for email subaddressing.
As a challenge to test your knowledge, try to build a regular expression pattern that matches only the valid email addresses marked below:
# invalid email
abc
abc.com
# valid email address
abc@mail.com
abc@mail.nz
abc@mail.co.nz
abc123@mail.com
abc.def@music.com
# invalid email prefix
abc-@mail.com
abc..def@mail.com
.abc@mail.com
abc#def@mail.com
# valid email prefix
abc-d@mail.com
abc.def@mail.com
abc@mail.com
abc_def@mail.com
# invalid domain suffix
abc.def@mail.c
abc.def@mail#archive.com
abc.def@mail
abc.def@mail..com
# valid domain suffix
abc.def@mail.cc
abc.def@mail-archive.com
abc.def@mail.org
abc.def@mail.com
fully-qualified-domain@example.com
Do note some email addresses marked as valid may be invalid for certain organizations, while some that are marked as invalid may actually be allowed in other organizations. Either way, learning to build custom regular expressions for the organizations you work for is paramount in order to cater for their needs. In case you get stuck, you can look at the following possible solutions. Do note that none of them will give you a 100% match on the above valid email test strings.
- Possible Solution 1:
^\w*(\-\w)?(\.\w*)?@\w*(-\w*)?\.\w{2,3}(\.\w{2,3})?$
- Possible Solution 2:
^(([^<>()\[\]\\.,;:\s@"]+(\.[^<>()\[\]\\.,;:\s@"]+)*)|(".+"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$
Summary
I hope you’ve now learned the basics of regular expressions. We haven’t covered all regex features in this quick beginner guide, but you should have enough information to tackle most problems that call for a regex solution. To learn more, read our guide on best practices for the practical application of regex in real-world scenarios.
FAQs About Regular Expressions (RegEx)
What is a regular expression (regex)?
A regular expression, often abbreviated as regex or regexp, is a pattern that describes a set of strings. It’s used for text processing and searching in strings based on specific patterns.
Why are regular expressions useful?
Regular expressions are useful for tasks like pattern matching, searching, data validation, and text manipulation in various programming and text processing tasks.
How do I create a basic regex pattern?
You can create a basic regex pattern using characters and special symbols to represent specific characters or character classes. For example, abc matches the string “abc.”
What are metacharacters in regex?
Metacharacters are special characters in regex that have a predefined meaning. Examples include . (matches any character), * (matches zero or more of the preceding element), and + (matches one or more of the preceding element).
What is a character class in regex?
character class, denoted by square brackets [...], allows you to specify a set of characters that can match a single character at that position. For example, [aeiou] matches any vowel.
What is the difference between greedy and non-greedy quantifiers in regex?
Greedy quantifiers (e.g., *, +) match as much as possible, while non-greedy quantifiers (e.g., *?, +?) match as little as possible. Greedy quantifiers are the default in most regex engines.
How can I perform case-insensitive matching in regex?
To perform case-insensitive matching, you can use the i flag or modifier in most regex engines, or you can use character classes like [Aa] to match both uppercase and lowercase letters.
Can regex match complex patterns like email addresses and URLs?
Yes, regex can match complex patterns like email addresses and URLs, but the patterns can be quite intricate due to the variety of valid formats for such data.
What are some common pitfalls when using regex?
Common pitfalls include incorrect escaping of special characters, excessive greediness in quantifiers, not considering edge cases, and inefficient regex patterns for large input.