
Key Takeaways
- Git is a powerful tool for managing personal projects, with capabilities for initializing projects, managing files and storing code in the cloud. It can be installed on Linux, Mac, or Windows and configured with user-specific information.
- The process of using Git involves creating a directory, initializing Git, configuring user details, creating files, checking repository status, adding and removing files, and committing changes. Commits serve as snapshots in time for the project, each identifiable by a unique hexadecimal number.
- Git allows for managing the project history, viewing details of particular commits and their associated changes. However, it does not cover how to revert to a particular commit or manage branches in this beginner’s guide.
- Git also allows for code to be stored in the cloud through platforms such as GitHub, GitLab, or BitBucket. This involves creating a remote repository, adding a remote origin, and pushing the code to the origin. This enables collaboration with others.
It is a general tendency of human beings to resist change. Unless Git was around when you started with version control systems, chances are that you are comfortable with Subversion. Often, people say that Git is too complex for beginners. Yet, I beg to differ!
In this tutorial, I will explain how to use Git for your personal projects. We will assume you are creating a project from scratch and want to manage it with Git. After going through the basic commands, we will have a look at how you could put your code in the cloud using GitHub.
We will talk about the basics of Git here — how to initialize your projects, how to manage new and existing files, and how to store your code in the cloud. We will avoid relatively complex parts of Git like branching, as this tutorial is intended for beginners.
Installing Git
The official website of Git has detailed information about installing on Linux, Mac, or Windows. In this case, we would be using Ubuntu 13.04 for demonstration purposes, where you install Git using apt-get.
sudo apt-get install git
Initial Configuration
Let’s create a directory inside which we will be working. Alternately, you could use Git to manage one of your existing projects, in which case you would not create the demo directory as below.
mkdir my_git_project
cd my_git_project
The first step is to initialize Git in a directory. This is done using the command init, which creates a .git directory that contains all the Git-related information for your project.

git init
Next, we need to configure our name and email. You can do it as follows, replacing the values with your own name and email.
git config --global user.name 'Shaumik'
git config --global user.email 'sd@gmail.com'
git config --global color.ui 'auto'
It is important to note that if you do not set your name and email, certain default values will be used. In our case, the username ‘donny’ and email ‘donny@ubuntu’ would be the default values.
Also, we set the UI color to auto so that the output of Git commands in the terminal are color coded. The reason we prefix --global to the command is to avoid typing these config commands the next time we start a Git project on our system.
Staging Files for Commit
The next step is to create some files in the directory. You could use a text editor like Vim. Note that if you are going to add Git to an already existing directory, you do not need to perform this step.
Check the Status of Your Repository
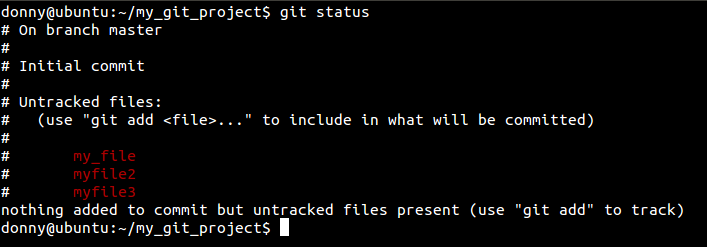
Now that we have some files in our repository, let us see how Git treats them. To check the current status of your repository, we use the git status command.
git status
Adding Files for Git to Track
At this point, we do not have any files for Git to track. We need to add files specifically to Git order to tell Git to track them. We add files using add.
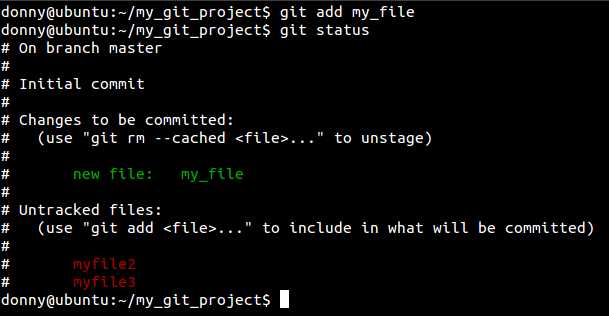
git add my_file
Checking the status of the repository again shows us that one file has been added.
To add multiple files, we use the following (note that we have added another file for demonstration purposes.)
git add myfile2 myfile3
You could use git add recursively, but be careful with that command. There are certain files (like compiled files) that are usually kept out of the Git repository. If you use add recursively, it would add all such files, if they are present in your repository.
Removing Files
Let’s say you have added files to Git that you do not want it to track. In such a situation, you tell Git to stop tracking them. Yet, running a simple git rm will not only remove it from Git, but will also remove it from your local file system as well! To tell Git to stop tracking a file, but still keep it on your local system, run the following command:
git rm --cached [file_name]
Committing Changes
Once you have staged your files, you can commit them into Git. Imagine a commit as a snapshot in time where you can return back to access your repository at that stage. You associate a commit message with every commit, which you can provide with the -m prefix.
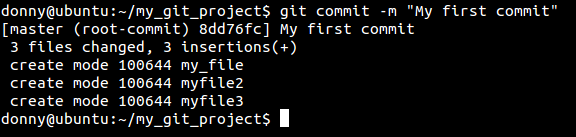
git commit -m "My first commit"
Provide a useful commit message because it helps you in identifying what you changed in that commit. Avoid overly general messages like “Fixed bugs”. If you have an issue tracker, you could provide messages like “Fixed bug #234”. It’s good practice to prefix your branch name or feature name to your commit message. For instance, “Asset management – Added feature to generate PDFs of assets” is a meaningful message.
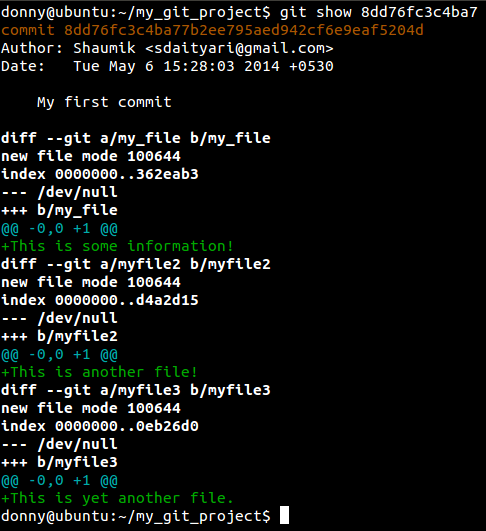
Git identifies commits by attaching a long hexadecimal number to every commit. Usually, you do not need to copy the whole string, and the first 5-6 characters are enough to identify your commit. In the screenshot, notice that 8dd76fc identifies our first commit.
Further Commits
Let’s now change a few files after our first commit. After changing them, we notice through git status that Git notices the change in the files that it is tracking.
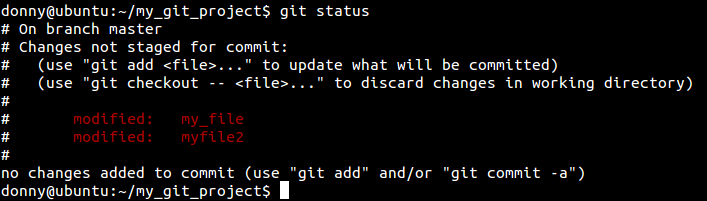
You can check the changes to the tracked files from the last commit by running git diff. If you want to have a look at the changes to a particular file, you can run git diff <file>.
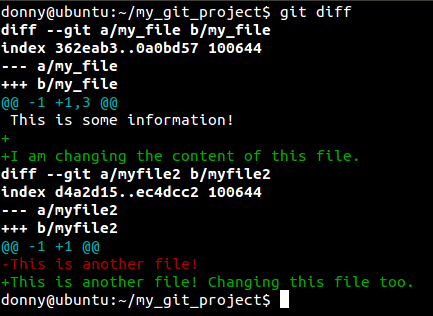
You need to add these files again to stage the changes in tracked files for the next commit. You can add all the tracked files by running:
git add -u
You could avoid this command by prefixing -a to git commit, which adds all changes to tracked files for a commit. This process, however, is very dangerous as it can be damaging. For instance, let’s say you opened a file and changed it by mistake. If you selectively stage them, you would notice changes in each file. But if you add -a to your commit, all files would be committed and you would fail to notice possible errors.
Once you have staged your files, you can proceed to a commit. Im mentioned that a message can be associated with every commit, which we entered by using -m. However, it is possible for you to provide multi-line messages by using the command git commit, which opens up an interactive format for you to write!
git commit
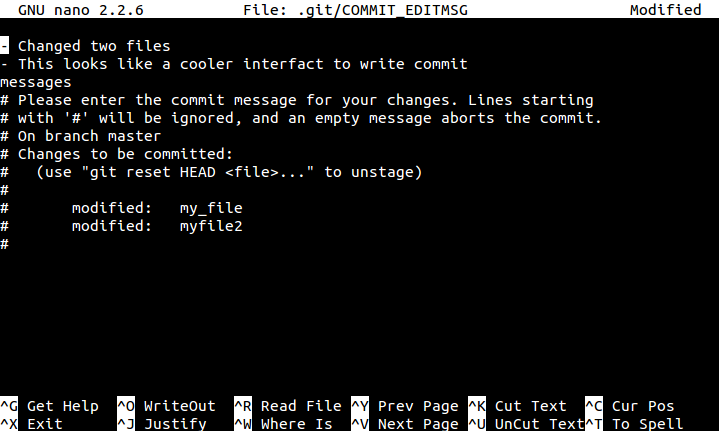
Managing of Your Project
To check the history of your project, you can run the following command.
git log
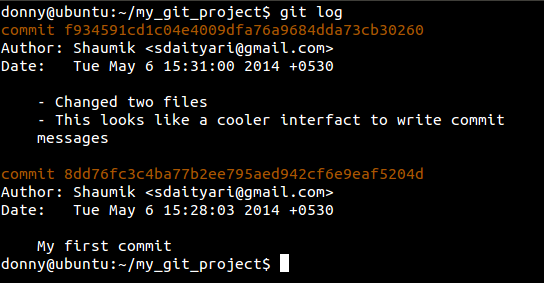
This shows you the entire history of the project — which is a list of all the commits and their information. The information about a commit contains the commit hash, author, time and commit message. There are many variations of git log, which you could explore once you understand the concept of a branch in Git. To view the details of a particular commit and the files that were changed, run the following command:
git show <hash>
Where <hash> is the hex number associated with the commit. As this tutorial is for beginners, we will not cover how to get back to the state of a particular commit in time or how to manage branches.
Putting Your Code in the Cloud
Once you have learned how to manage your code on your system, the next step is to put it in the cloud. Since Git doesn’t have a central server like Subversion, you need to add each source to collaborate with others. That is where the concept of remotes comes in. A remote refers to a remote version of your repository.
If you wish to put your code in the cloud, you could create a project on GitHub, GitLab, or BitBucket and push your existing code to the repository. In this case, the remote repository in the cloud would act as a remote to your repository. Conveniently, a remote to which you have write access is called the origin.
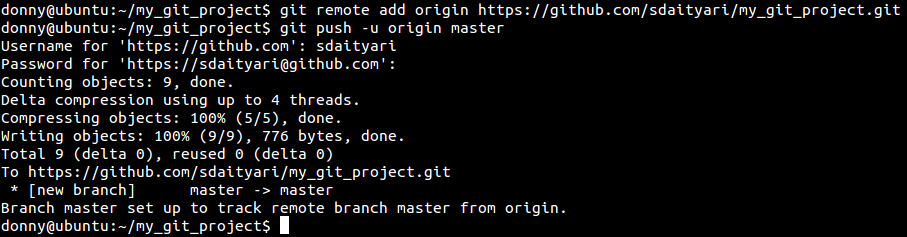
After you create a remote repository, you have the ability to add a remote origin and then push the code to the origin.
git remote add origin https://github.com/sdaityari/my_git_project.git
git push -u origin master
Conclusion
Git is full of features and we have covered just the basics here. I hope that this post helped you get started with Git. If you have any issues or questions about getting started, let us know in the comments below.
Frequently Asked Questions (FAQs) about Git for Beginners
What is the difference between ‘git fetch’ and ‘git pull’?
Git fetch’ and ‘git pull’ are two commands that help you update your local repository with changes from the remote repository. ‘Git fetch’ only downloads new data from the remote repository, but it doesn’t integrate any of this new data into your working files. It’s a safe command to use if you just want to see what’s new, but not make any changes to your own work. On the other hand, ‘git pull’ does a ‘git fetch’ followed by a ‘git merge’. This means it downloads the new data and integrates it with your current files, making it a quick way to catch up with the remote repository.
How can I undo the last commit in Git?
If you want to undo the last commit in Git, you can use the command ‘git reset –soft HEAD~1’. This command will move your HEAD pointer back by one commit, effectively “undoing” the last commit. However, it’s important to note that this doesn’t delete any changes; it just removes the commit. The changes from the undone commit will still be in your working directory.
What is the purpose of ‘git stash’ command?
The ‘git stash’ command is used when you want to record the current state of the working directory and the index, but want to go back to a clean working directory. The command saves your local modifications away and reverts the working directory to match the HEAD commit. The modifications stashed away by this command can be listed with ‘git stash list’, inspected with ‘git stash show’, and restored (potentially on top of a different commit) with ‘git stash apply’.
How can I view the history of my commits?
You can view the history of your commits using the ‘git log’ command. This command shows you a list of all the commits in the repository in reverse chronological order. Each commit is displayed with its SHA-1 checksum, the author’s name and email, the date it was made, and the commit message.
What is a ‘git branch’ and how do I use it?
A ‘git branch’ is essentially a unique set of code changes with a unique name. Each repository can have one or more branches. The ‘git branch’ command lets you create, list, rename, and delete branches. It doesn’t let you switch between branches or put a forked history back together again. For this reason, ‘git branch’ is tightly integrated with the ‘git checkout’ and ‘git merge’ commands.
How can I merge changes from one branch to another?
You can merge changes from one branch to another using the ‘git merge’ command. This command takes the contents of a source branch and integrates it with the target branch. When ‘git merge’ is executed, a new commit is created that points to the merged content of the source and target branches.
What is a ‘git remote’?
A ‘git remote’ is a common repository that all team members use to exchange their changes. In most cases, such a remote repository is stored on a code hosting service like GitHub or on an internal server. The ‘git remote’ command lets you create, view, and delete connections to other repositories.
How can I resolve merge conflicts in Git?
Merge conflicts occur when competing changes are made to the same line of a file, or when one person edits a file and another person deletes the same file. The ‘git merge’ command will automatically merge changes unless there are conflicts. If there are conflicts, it will output a warning and a list of files that need manual resolution. After you’ve resolved the conflicts, you can use the ‘git add’ command to add the resolved files, and then ‘git commit’ to commit the resolved changes.
What is the use of ‘git push’ command?
The ‘git push’ command is used to upload local repository content to a remote repository. After a local repository has been modified, a push is executed to share the modifications with remote team members.
What is the difference between ‘git checkout’ and ‘git switch’?
Both ‘git checkout’ and ‘git switch’ are used to switch between different branches in a Git repository. However, ‘git switch’ is a newer command introduced in Git 2.23, designed to be more intuitive and easier to use for those new to Git. The ‘git switch’ command only does one thing – switch to another branch, whereas ‘git checkout’ can be used for both switching branches and checking out files, which can be confusing for beginners.