



The following is a short extract from our book, Jump Start Git, available for free to SitePoint Premium members. Print copies are sold in stores worldwide, or you can order them here. We hope you enjoy this extract and find it useful.
In Chapter 1, I talked about my one-time fear of trying out new things in a project. What if I tried something ambitious and it broke everything that was working earlier? This problem is solved by the use of branches in Git.
Key Takeaways
- Branching in Git allows for the creation of a new copy of a project, enabling experimentation without affecting the original project. If successful, the experimental elements can be easily incorporated into the master branch.
- Branches provide the ability to work on multiple tasks simultaneously without interference. This is useful when waiting for approval on one feature while needing to work on another. Branches also make code easier to understand by separating different ideas.
- Creating a branch in Git is done with the command ‘git branch [branch name]’. Switching to this branch is done with ‘git checkout [branch name]’. Deleting a branch is done with ‘git branch -D [branch name]’, but it is advised not to delete branches unless necessary.
- Merging branches in Git is a straightforward process. After ensuring the desired branch is active, the command ‘git merge [branch name]’ is used. However, this can create loops in project history, which can be difficult to navigate in larger teams. A method of merging without creating loops will be explored in the next chapter.
What Are Branches?
Creating a new branch in a project essentially means creating a new copy of that project. You can experiment with this copy without affecting the original. So if the experiment fails, you can just abandon it and return to the original—the master branch.
But if the experiment is successful, Git makes it easy to incorporate the experimental elements into the master. And if, at a later stage, you change your mind, you can easily revert back to the state of the project before this merger.
So a branch in Git is an independent path of development. You can create new commits in a branch while not affecting other branches. This ease of working with branches is one of the best features of Git. (Although other version control options like CVS had this branching option, the experience of merging branches on CVS was a very tedious one. If you’ve had experience with branches in other version control systems, be assured that working with branches in Git is quite different.)
In Git, you find yourself in the master branch by default. The name “master” doesn’t imply that it’s superior in any way. It’s just the convention to call it that.
Note: Branch Conventions
Although you’re free to use a different branch as your base branch in Git, people usually expect to find the latest, up-to-date code on a particular project in the master branch.
You might argue that, with the ability to go back to any commit, there’s no need for branches. However, imagine a situation where you need to show your work to your superior, while also working on a new, cool feature which is not a part of your completed work. As branching is used to separate different ideas, it makes the code in your repository easy to understand. Further, branching enables you to keep only the important commits in the master branch or the main branch.
Yet another use of branches is that they give you the ability to work on multiple things at the same time, without them interfering with each other. Let’s say you submit feature 1 for review, but your supervisor needs some time before reviewing it. Meanwhile, you need to work on feature 2. In this scenario, branches come into play. If you work on your new idea on a separate branch, you can always switch back to your earlier branch to return the repository to its previous state, which does not contain any code related to your idea.
Let’s now start working with branches in Git. To see the list of branches and the current branch you’re working on, run the following command:
git branch
If you have cloned your repository or set a remote, you can see the remote branches too. Just postfix -a to the command above:
git branch -a
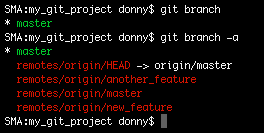
As shown above, the branches that colored red signify that they are on a remote. In our case, we can see the various branches that are present in the origin remote.
Create a Branch
There are various ways of creating a branch in Git. To create a new branch and stay in your current branch, run the following:
git branch test_branch
Here, test_branch is the name of the created branch. However, on running git branch, it seems that the active branch is still the master branch. To change the active branch, we can run the checkout command (shown below):
git checkout test_branch
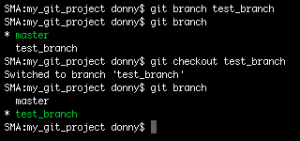
You can also combine the two commands above and thereby create and checkout to a new branch in a single command by postfixing -b to the checkout command:
git checkout -b new_test_branch
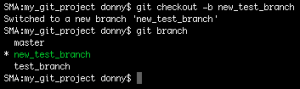
The branches we’ve just created are based on the latest commit of the current active branch—which in our case is master. If you want to create a branch (say old_commit_branch) based on a certain commit—such as cafb55d—you can run the following command:
git checkout -b old_commit_branch cafb55d
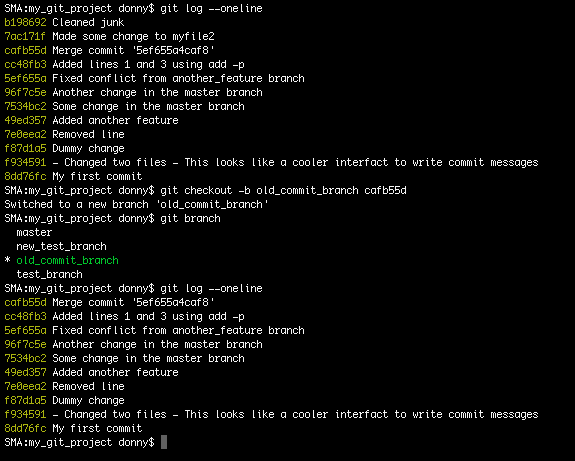
To rename the current branch to renamed_branch, run the following command:
git branch -m renamed_branch
Delete a Branch
To delete a branch, run the following command:
git branch -D new_test_branch
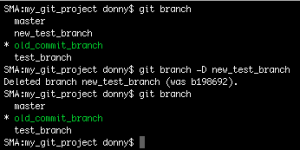
Note: Don’t Delete Branches Unless You Have To
As there’s not really any downside to keeping branches, as a precaution I’d suggest not deleting them unless the number of branches in the repository becomes too large to be manageable.
The -D option used above deletes a branch even if it hasn’t been synchronized with a remote branch. This means that if you have commits in your current branch that have not been pushed yet, -D will still delete your branch without providing any warning. To ensure you don’t lose data, you can postfix -d as an alternative to -D. -d only deletes a branch if it has been synchronized with a remote branch. Since our branches haven’t been synced yet, let’s see what happens if we postfix -d, shown below:

As you can see, Git gives you a warning and aborts the operation, as the data hasn’t been merged with a branch yet.
Branches and HEAD
Now that we’ve had a chance to experiment with the basics of branching, let’s spend a little time discussing how branches work in Git, and also introduce an important concept: HEAD.
As mentioned above, a branch is just a link between different commits, or a pathway through the commits. An important thing to note is that, while working with branches, the HEAD of a branch points to the latest commit in the branch. I’ll refer to HEAD a lot in upcoming chapters. In Git, the HEAD points to the latest commit in a branch. In other words, it refers to the tip of a branch.
A branch is essentially a pointer to a commit, which has a parent commit, a grandparent commit, and so on. This chain of commits forms the pathway I mentioned above. How, then, do you link a branch and HEAD? Well, HEAD and the tip of the current branch point to the same commit. Let’s look at a diagram to illustrate this idea:
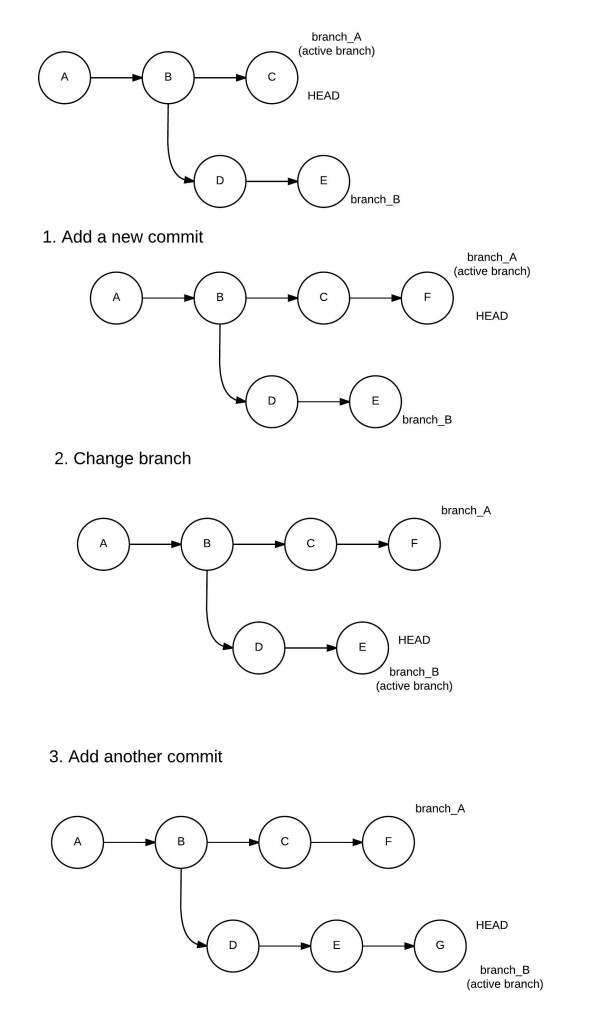
As shown above, branch_A initially is the active branch and HEAD points to commit C. Commit A is the base commit and doesn’t have any parent commit, so the commits in branch_A in reverse chronological order (which also forms the pathway I’ve talked about) are C → B → A. The commits in branch_B are E → D → B → A. The HEAD points to the latest commit of the active branch_A, which is commit C. When we add a commit, it’s added to the active branch. After the commit, branch_A points to F, and the branch follows F → C → B → A, whereas branch_B remains the same. HEAD now points to commit F. Similarly, the changes when we add yet another commit are demonstrated in the figure.
Advanced Branching: Merging Branches
As mentioned earlier, one of Git’s biggest advantages is that merging branches is especially easy. Let’s now look at how it’s done.
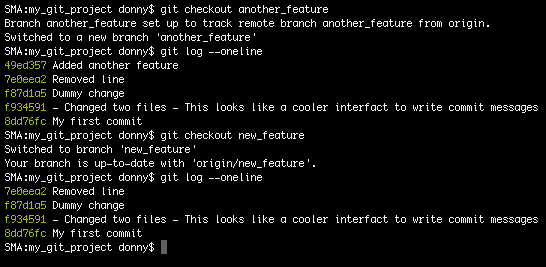
We’ll create two new branches—new_feature and another_feature—and add a few dummy commits. Checking the history in each branch shows us that the branch another_feature is ahead by one commit, as shown below:
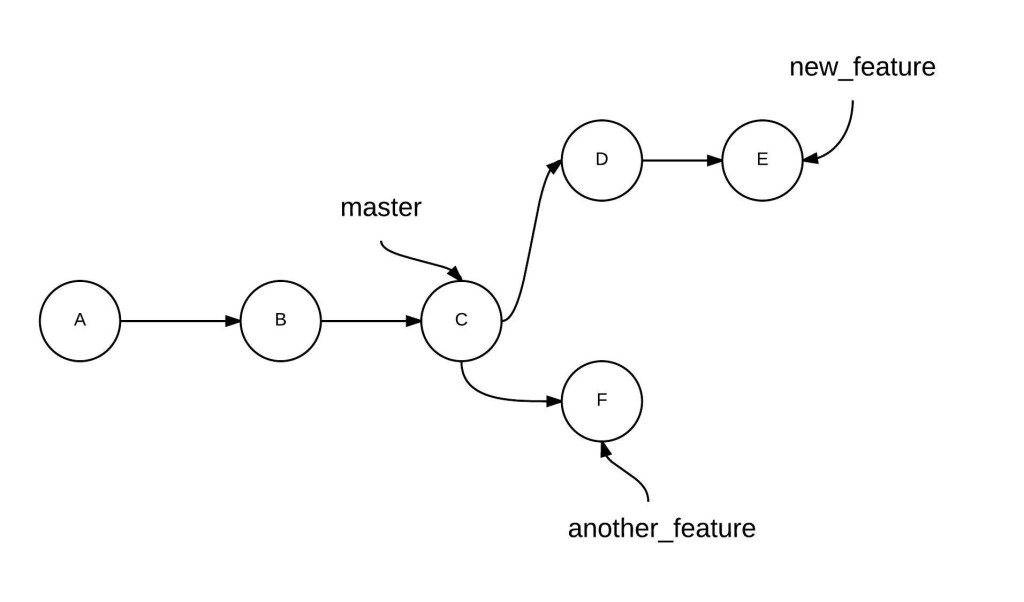
This situation can be visualized as shown below. Each circle represents a commit, and the branch name points to its HEAD (the tip of the branch).
To merge new_feature with master, run the following (after first making sure the master branch is active):
git checkout master
git merge new_feature
The result can be visualized as shown below:

To merge another_feature with new_feature, just run the following (making sure that the branch new_feature is active):
git checkout new_feature
git merge another_feature
The result can be visualized as shown below:
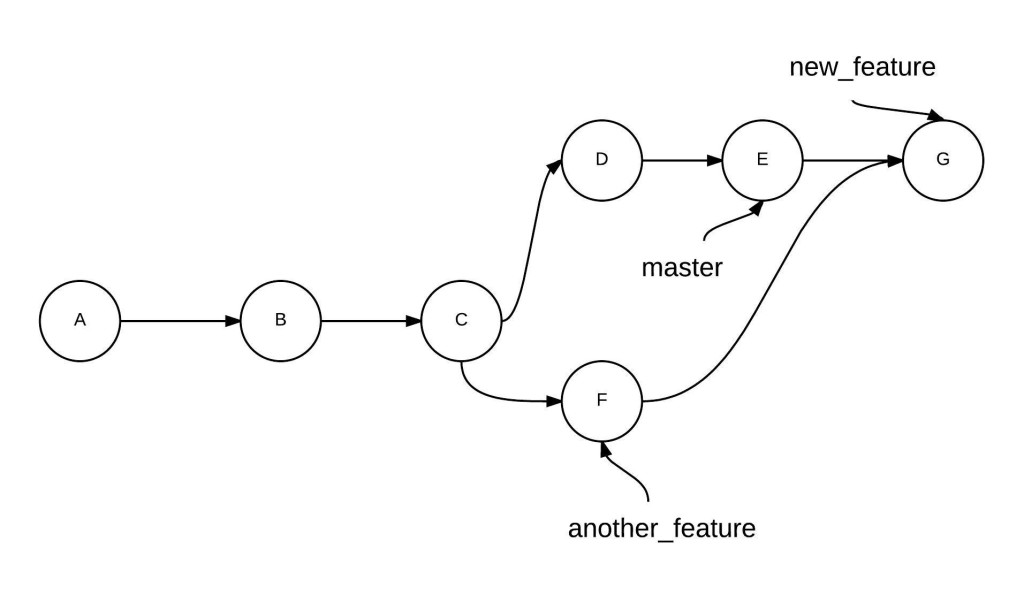
Important: Watch Out for Loops
The diagram above shows that this merge has created a loop in your project history across the two commits, where the workflows diverged and converged, respectively. While working individually or in small teams, such loops might not be an issue. However, in a larger team—where there might have been a lot of commits since the time you diverged from the main branch—such large loops make it difficult to navigate the history and understand the changes. We’ll explore a way of merging branches without creating loops using the rebase command in Chapter 6.
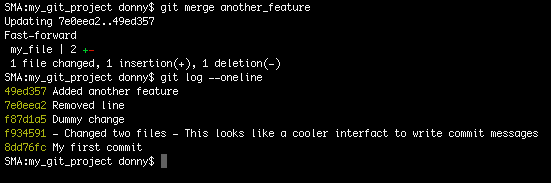
This merge happened without any “conflicts”. The simple reason for that is that no new commits had been added to branch new_feature as compared to the branch another_feature. Conflicts in Git happen when the same file has been modified in non-common commits in both branches. Git raises a conflict to make sure you don’t lose any data.
We’ll discuss conflicts in detail in the next chapter. I mentioned earlier that branches can be visualized by just a simple pathway through commits. When we merge branches and there are no conflicts, such as above, only the branch pathway is changed and the HEAD of the branch is updated. This is called the fast forward type of merge.
The alternate way of merging branches is the no fast forward merge, by postfixing --no-ff to the merge command. In this way, a new commit is created on the base branch with the changes from the other branch. You are also asked to specify a commit message:
git merge --no-ff new_feature
In the example above, the former (merging new_feature with master) was a fast forward merge, whereas the latter was a no fast forward merge with a merge commit.
While the fast forward style of merges is default, it’s generally a good idea to go for the no fast forward method for merges into the master branch. In the long run, a new commit that identifies a new feature merge might be beneficial, as it logically separates the part of the code that is responsible for the new feature into a commit.
Conclusion
What Have You Learned?
In this chapter, we discussed what branches are and how to manage them in Git. We looked at creating, modifying, deleting and merging branches.
I’ve already spoken about how Git is beneficial to developers working in teams. The next chapter will look at this in more detail, as well as specific Git actions and commands that are frequently used while working in a distributed team.
Frequently Asked Questions about Git Branching
What is the main purpose of Git branching?
Git branching is a powerful feature that allows developers to create a separate line of development. This is particularly useful when working on a new feature or fix, as it allows you to isolate your work from the main project. Once the feature or fix is complete and tested, it can be merged back into the main project. This ensures that the main project remains stable and allows multiple developers to work on different features simultaneously without interfering with each other’s work.
How do I create a new branch in Git?
Creating a new branch in Git is simple. You can use the git branch command followed by the name of your new branch. For example, git branch new_feature would create a new branch called “new_feature”. To switch to this branch, you would use the git checkout command, like so: git checkout new_feature.
How can I merge branches in Git?
Merging branches in Git is done using the git merge command. Before you can merge, you need to be on the branch that you want to merge into. For example, if you want to merge a branch called “new_feature” into the “master” branch, you would first checkout to the master branch using git checkout master, then use the git merge new_feature command.
What is a Git branch pointer and how does it work?
A Git branch pointer is a file that contains the SHA1 hash of the commit it points to. When you create a new branch, Git creates a new pointer and moves it along with each new commit you make. This allows Git to keep track of your project’s history.
How can I delete a branch in Git?
Deleting a branch in Git is done using the git branch -d command followed by the name of the branch. For example, git branch -d old_feature would delete the branch named “old_feature”. However, Git will prevent you from deleting a branch if it has commits that haven’t been merged into another branch. To force deletion, you can use the -D option instead.
What is the difference between a fast-forward and a 3-way merge in Git?
A fast-forward merge in Git is possible when there is a linear path from the current branch tip to the target branch. Instead of creating a new commit, Git just moves the current branch pointer up to the target branch. On the other hand, a 3-way merge is used when there is no linear path. Git will create a new commit that has two parents, effectively joining the two branches.
How can I view all branches in my Git repository?
You can view all branches in your Git repository using the git branch command with no arguments. This will list all local branches. If you want to see remote branches as well, you can use the -a option, like so: git branch -a.
How can I rename a branch in Git?
Renaming a branch in Git is done using the git branch -m command followed by the old name and the new name. For example, git branch -m old_name new_name would rename the branch “old_name” to “new_name”.
What is a detached HEAD in Git and how can I avoid it?
A detached HEAD in Git occurs when you checkout a commit instead of a branch. This can be dangerous because any changes you make will be lost when you checkout to another branch. To avoid this, always make sure to checkout to a branch, not a commit.
How can I resolve conflicts when merging branches in Git?
When merging branches in Git, conflicts can occur if the same part of the same file was modified in both branches. Git will mark the file as “unmerged” and you will need to manually resolve the conflict. You can do this by opening the file in a text editor, finding the conflict markers (<<<<<<<, =======, >>>>>>>), and deciding which changes to keep. Once you’ve resolved all conflicts, you can add the file using git add and then commit it using git commit.