Crawling and Searching Entire Domains with Diffbot

In this tutorial, I’ll show you how to build a custom SitePoint search engine that far outdoes anything WordPress could ever put out. We’ll be using Diffbot as a service to extract structured data from SitePoint automatically, and this matching API client to do both the searching and crawling.
![]()
I’ll also be using my trusty Homestead Improved environment for a clean project, so I can experiment in a VM that’s dedicated to this project and this project alone.
Key Takeaways
- Diffbot, a service that extracts structured data from websites, can be used to build a custom search engine that surpasses the capabilities of WordPress.
- A Diffbot Crawljob spiders a URL pattern for URLs and processes the pages found on the spidered URLs with the designated API engine. This can be used to index and process an entire domain, keeping itself up to date with newly published content.
- The Diffbot Crawljob can be customized to spider specific URLs, notify the user when the crawling is done, set maximum limits for crawling and processing, refresh at specific intervals, and process only new pages, among other settings.
- The Diffbot Search API can be used to search a dataset, even before it’s complete. It can return fine-tuned results based on common keywords, date ranges, targeted specific fields, or boolean combinations of various parameters.
- Diffbot is particularly useful for media conglomerates with multiple websites, as it can consolidate all content into a single directory by crawling all domains and using the Search API to traverse the returned data. However, it’s important to check a website’s terms of service before crawling, as it may not be permissible and could potentially infringe on the site’s ad revenue and other income streams.
What’s what?
To make a SitePoint search engine, we need to do the following:
- Build a Crawljob which will index and process the entire SitePoint.com domain and keep itself up to date with newly published content.
- Build a GUI for submitting search queries to the saved set produced by this crawljob. Searching is done via the Search API. We’ll do this in a followup post.
A Diffbot Crawljob does the following:
- It spiders a URL pattern for URLs. This does not mean processing – it means looking for links to process on all the pages it can find, starting from the domain you originally passed in as seed. For the difference between crawling and processing, see here.
- It processes the pages found on the spidered URLs with the designated API engine – for example, using Product API, it processes all products it found on Amazon.com and saves them into a structured database of items on offer.
Creating a Crawljob
Jobs can be created through Diffbot’s GUI, but I find creating them via the crawl API is a more customizable experience. In an empty folder, let’s first install the client library.
composer require swader/diffbot-php-clientI now need a job.php file into which I’ll just dump the job creation procedure, as per the README:
include 'vendor/autoload.php';
use Swader\Diffbot\Diffbot;
$diffbot = new Diffbot('my_token');The Diffbot instance is used to create access points to API types offered by Diffbot. In our case, a “Crawl” type is needed. Let’s name it “sp_search”.
$job = $diffbot->crawl('sp_search');This will create a new crawljob when the call() method is called. Next, we’ll need to configure the job. First, we need to give it the seed URL(s) on which to start the spidering process:
$job
->setSeeds(['https://www.sitepoint.com'])Then, we make it notify us when it’s done crawling, just so we know when a crawling round is complete, and we can expect up to date information to be in the dataset.
$job
->setSeeds(['https://www.sitepoint.com'])
->notify('bruno.skvorc@sitepoint.com')A site can have hundreds of thousands of links to spider, and hundreds of thousands of pages to process – the max limits are a cost-control mechanism, and in this case, I want the most detailed possible set available to me, so I’ll put in one million URLs into both values.
$job
->setSeeds(['https://www.sitepoint.com'])
->notify('bruno.skvorc@sitepoint.com')
->setMaxToCrawl(1000000)
->setMaxToProcess(1000000)We also want this job to refresh every 24 hours, because we know SitePoint publishes several new posts every single day. It’s important to note that repeating means “from the time the last round has finished” – so if it takes a job 24 hours to finish, the new crawling round will actually start 48 hours from the start of the previous round. We’ll set max rounds as 0, to indicate we want this to repeat indefinitely.
$job
->setSeeds(['https://www.sitepoint.com'])
->notify('bruno.skvorc@sitepoint.com')
->setMaxToCrawl(1000000)
->setMaxToProcess(1000000)
->setRepeat(1)
->setMaxRounds(0)Finally, there’s the page processing pattern. When Diffbot processes pages during a crawl, only those that are processed – not crawled – are actually charged / counted towards your limit. It is, therefore, in our interest to be as specific as possible with our crawljob’s definition, as to avoid processing pages that aren’t articles – like author bios, ads, or even category listings. Looking for <section class="article_body"> should do – every post has this. And of course, we want it to only process the pages it hasn’t encountered before in each new round – no need to extract the same data over and over again, it would just stack up expenses.
$job
->setSeeds(['https://www.sitepoint.com'])
->notify('bruno.skvorc@sitepoint.com')
->setMaxToCrawl(1000000)
->setMaxToProcess(1000000)
->setRepeat(1)
->setMaxRounds(0)
->setPageProcessPatterns(['<section class="article_body">'])
->setOnlyProcessIfNew(1)Before finishing up with the crawljob configuration, there’s just one more important parameter we need to add – the crawl pattern. When passing in a seed URL to the Crawl API, the Crawljob will traverse all subdomains as well. So if we pass in https://www.sitepoint.com, Crawlbot will look through http://community.sitepoint.com, and the now outdated http://reference.sitepoint.com – this is something we want to avoid, as it would slow our crawling process dramatically, and harvest stuff we don’t need (we don’t want the forums indexed right now). To set this up, we use the setUrlCrawlPatterns method, indicating that crawled links must start with sitepoint.com.
$job
->setSeeds(['https://www.sitepoint.com'])
->notify('bruno.skvorc@sitepoint.com')
->setMaxToCrawl(1000000)
->setMaxToProcess(1000000)
->setRepeat(1)
->setMaxRounds(0)
->setPageProcessPatterns(['<section class="article_body">'])
->setOnlyProcessIfNew(1)
->setUrlCrawlPatterns(['^http://www.sitepoint.com', '^https://www.sitepoint.com'])Now we need to tell the job which API to use for processing. We could use the default – Analyze API – which would make Diffbot auto-determine the structure of the data we’re trying to obtain, but I prefer specificity and want it to know outright that it should only produce articles.
$api = $diffbot->createArticleAPI('crawl')->setMeta(true)->setDiscussion(false);
$job->setApi($api);Note that with the individual APIs (like Product, Article, Discussion, etc..) you can process individual resources even with the free demo token from Diffbot.com, which lets you test out your links and see what data they’ll return before diving into bulk processing via Crawlbot. For information on how to do this, see the README file.
The job is now configured, and we can call() Diffbot with instructions on how to create it:
$job->call();The full code for creating this job is:
$diffbot = new Diffbot('my_token');
$job = $diffbot->crawl('sp_search');
$job
->setSeeds(['https://www.sitepoint.com'])
->notify('bruno.skvorc@sitepoint.com')
->setMaxToCrawl(1000000)
->setMaxToProcess(1000000)
->setRepeat(1)
->setMaxRounds(0)
->setPageProcessPatterns(['<section class="article_body">'])
->setOnlyProcessIfNew(1)
->setApi($diffbot->createArticleAPI('crawl')->setMeta(true)->setDiscussion(false))
->setUrlCrawlPatterns(['^http://www.sitepoint.com', '^https://www.sitepoint.com']);
$job->call();Calling this script via command line (php job.php) or opening it in the browser has created the job – it can be seen in the Crawlbot dev screen:
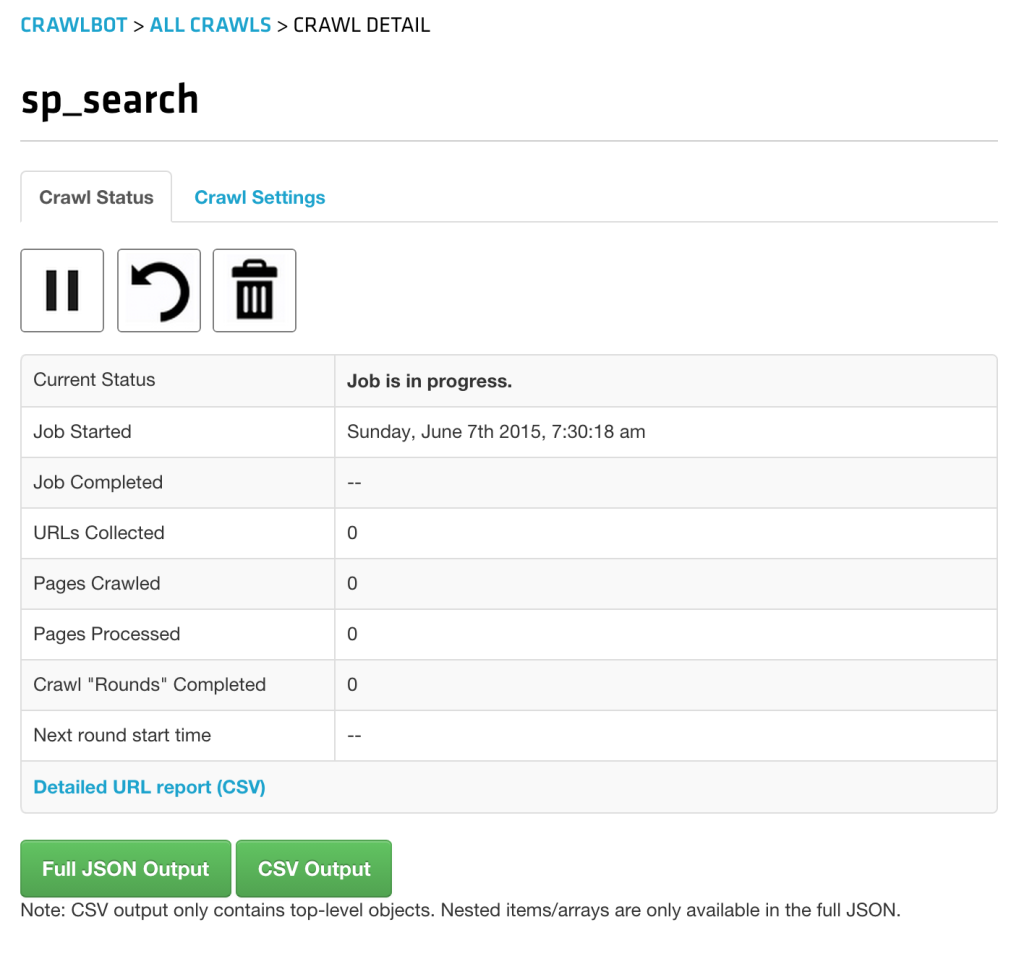
It’ll take a while to finish (days, actually – SitePoint is a huge place), but all subsequent rounds will be faster because we told the job to only process pages it hasn’t encountered before.
Searching
To search a dataset, we need to use the Search API. A dataset can be used even before it’s complete – the Search API will simply search through the data it has, ignoring the fact that it doesn’t have everything.
To use the search API, one needs to create a new search instance with a search query as a constructor parameter:
$search = $diffbot->search('author:"Bruno Skvorc"');
$search->setCol('sp_search');
$result = $search->call();The setCol method is optional, and if omitted will make the Search API go through all the collections under a single Diffbot token. As I have several collections from my previous experiments, I opted to specify the last one we created: sp_search (collections share names with the jobs that created them).
The returned data can be iterated over, and every element will be an instance of Article. Here’s a rudimentary table exposing links and titles:
<table>
<thead>
<tr>
<td>Title</td>
<td>Url</td>
</tr>
</thead>
<tbody>
<?php
foreach ($search as $article) {
echo '<tr>';
echo '<td>' . $article->getTitle() . '</td>';
echo '<td><a href="' . $article->getResolvedPageUrl() . '">Link</a></td>';
echo '</tr>';
}
?>
</tbody>
</table>
The Search API can return some amazingly fine tuned result sets. The query param will accept everything from common keywords, to date ranges, to targeted specific fields (like title:diffbot) to boolean combinations of various parameters, like type:article AND title:robot AND (overlord OR butler), producing all articles that have the word “robot” in the title and either the word “overlord” or “butler” in any of the fields (title, body, meta tags, etc). We’ll be taking advantage of all this advanced functionality in the next post as we build our search engine’s GUI.
We can also get the “meta” information about a Search API request by passing true into the call() after making the original call:
$info = $search->call(true);
dump($info);The result we get back is a SearchInfo object with the values as shown below (all accessible via getters):
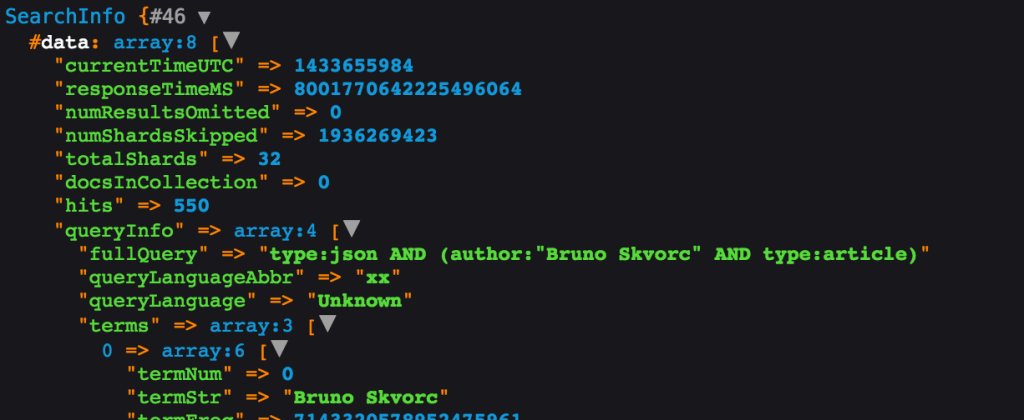
With SearchInfo, you get access to the speed of your request, the number of hits (not the returned results, but total number – useful for pagination), etc.
To get information about a specific crawljob, like finding out its current status, or how many pages were crawled, processed, etc, we can call the crawl API again and just pass in the same job name. This, then, works as a read only operation, returning all the meta info about our job:
dump($diffbot->crawl('sp_search')->call());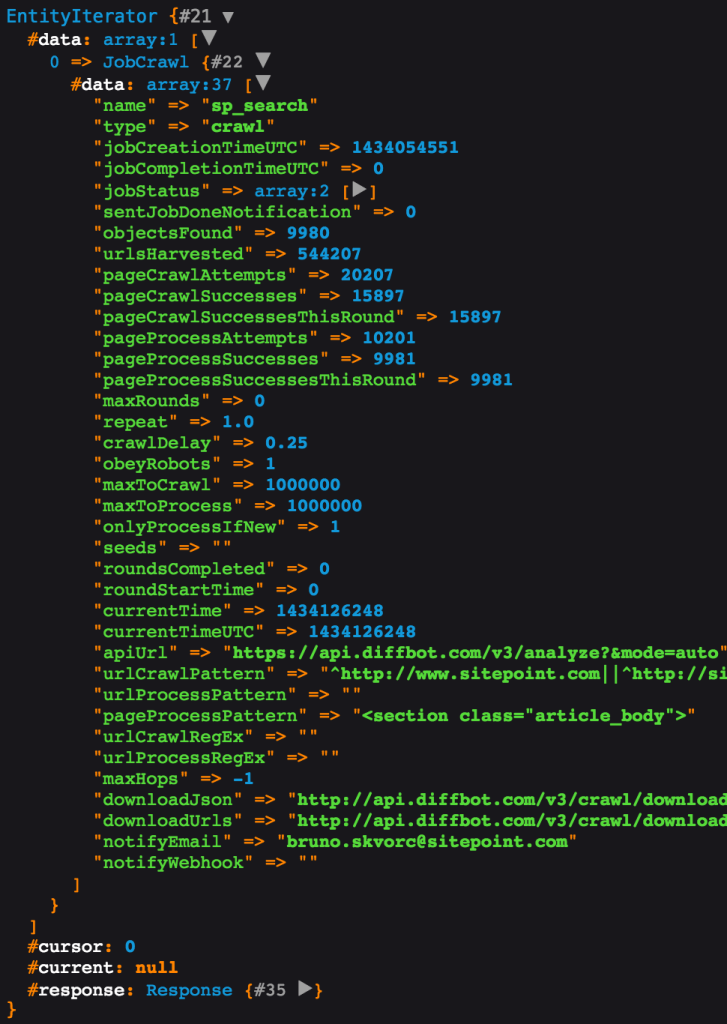
At this point, we’ve got our collection being populated with crawled data from SitePoint.com. Now all we have to do is build a GUI around the Search functionality of the Diffbot API client, and that’s exactly what we’re going to be doing in the next part.
Conclusion
In this tutorial, we looked at Diffbot’s ability to generate collections of structured data from websites of arbitrary format, and its Search API which can be used as the search engine behind a crawled site. While the price might be somewhat over the top for the average solo developer, for teams and companies this tool is a godsend.
Imagine being a media conglomerate with dozens or hundreds of different websites under your belt, and wanting a directory of all your content. Consolidating the efforts of all those backend teams to not only come up with a way to merge the databases but also find the time to do it in their daily efforts (which include keeping their outdated websites alive) would be an impossible and ultra expensive task, but with Diffbot, you unleash Crawlbot on all your domains and just use the Search API to traverse what was returned. What’s more, the data you crawl is downloadable in full as a JSON payload, so even if it gets too expensive, you can always import the data into your own solution later on.
It’s important to note that not many websites agree with being crawled, so you should probably look at their terms of service before attempting it on a site you don’t own – crawls can rack up people’s server costs rather quickly, and by stealing their content for your personal use without approval, you also rob them of potential ad revenue and other streams of income connected with the site.
In part 2, we’ll look at how we can turn everything we’ve got so far into a GUI so that the average Joe can easily use it as an in-depth SitePoint search engine.
If you have any questions or comments, please leave them below!
Frequently Asked Questions about Crawling and Searching Entire Domains
What is the difference between crawling and indexing?
Crawling and indexing are two distinct processes used by search engines to gather and organize information on the internet. Crawling refers to the process of a search engine scanning a website or webpage to collect data. This is done by bots, also known as spiders or crawlers, which follow links on pages to gather information. On the other hand, indexing is the process of organizing the data collected during crawling. This data is stored in a database, known as an index, which is used by search engines to provide quick and accurate search results.
How does Diffbot work?
Diffbot is an AI-powered tool that uses machine learning algorithms to crawl and extract data from web pages. It uses natural language processing and computer vision to understand the content of a webpage, much like a human would. This allows it to extract data from a wide variety of page types, including articles, products, and discussions, among others. The extracted data can then be used for a variety of purposes, such as data analysis, content aggregation, and more.
How can I use Diffbot to crawl an entire domain?
To crawl an entire domain using Diffbot, you need to use the Crawlbot API. This API allows you to specify the domain you want to crawl, as well as any additional parameters, such as the types of pages you want to crawl, the depth of the crawl, and more. Once the crawl is complete, you can use the Diffbot APIs to extract the data from the crawled pages.
What are the benefits of using Diffbot for domain crawling?
Diffbot offers several advantages for domain crawling. Firstly, it uses advanced AI technology to understand and extract data from web pages, allowing it to handle a wide variety of page types. Secondly, it provides a simple and easy-to-use API for crawling and data extraction, making it accessible to developers of all skill levels. Finally, it offers robust scalability, allowing you to crawl large domains without worrying about performance issues.
How does search engine crawling work?
Search engine crawling is the process of scanning websites to collect data for indexing. This is done by bots, which follow links on web pages to discover new content. The bots scan the content of the pages, including the text, images, and metadata, and send this data back to the search engine. The search engine then uses this data to build an index, which is used to provide search results.
How can I optimize my website for search engine crawling?
There are several ways to optimize your website for search engine crawling. Firstly, ensure that your website has a clear and logical structure, with all pages accessible through links. Secondly, use SEO-friendly URLs that clearly describe the content of each page. Thirdly, use meta tags to provide additional information about your pages to the search engines. Finally, regularly update your content to encourage search engines to crawl your site more frequently.
What is the role of a sitemap in website crawling?
A sitemap is a file that provides information about the pages, videos, and other files on your site, and the relationships between them. Search engines like Google read this file to more intelligently crawl your site. A sitemap tells the crawler which files you think are important in your site, and also provides valuable information about these files.
How does Google’s search engine work?
Google’s search engine works by using bots to crawl the web, collecting data from web pages and storing it in an index. When a user performs a search, Google uses complex algorithms to search its index and find the most relevant results. These algorithms take into account a variety of factors, including the keywords used in the search, the relevance and quality of the web pages, and the user’s location and search history.
What is domain crawling and how is it useful?
Domain crawling is the process of scanning an entire website or domain to collect data. This data can be used for a variety of purposes, such as SEO analysis, content aggregation, data mining, and more. By crawling a domain, you can gain a comprehensive understanding of its content and structure, which can be invaluable for improving your website’s performance and visibility.
How can I prevent certain pages from being crawled?
If you want to prevent certain pages from being crawled, you can use a robots.txt file. This is a file that tells search engine bots which pages or sections of your site they should not visit. You can specify which bots are affected, and which pages or directories they should not access. However, it’s important to note that not all bots respect the directives in a robots.txt file, so sensitive content should be protected by other means.
Bruno is a blockchain developer and technical educator at the Web3 Foundation, the foundation that's building the next generation of the free people's internet. He runs two newsletters you should subscribe to if you're interested in Web3.0: Dot Leap covers ecosystem and tech development of Web3, and NFT Review covers the evolution of the non-fungible token (digital collectibles) ecosystem inside this emerging new web. His current passion project is RMRK.app, the most advanced NFT system in the world, which allows NFTs to own other NFTs, NFTs to react to emotion, NFTs to be governed democratically, and NFTs to be multiple things at once.




