

There was a time when any Web developer with a basic knowledge of JavaScript could pick up the essentials of ASP Web development in a couple of hours. With ASP.NET, Microsoft’s latest platform for Web application development, the bar has been raised. Though tidier and generally more developer-friendly, real-world ASP.NET development requires one important skill that ASP did not: Object Oriented Programming (OOP).
The two most popular languages that were used to write ASP scripts, VBScript and JScript, have been retrofitted with OOP features to become VB.NET and JScript.NET. In addition, Microsoft has introduced an entirely new programming language called C# (C-sharp). Unhindered by clunky syntax inherited from a non-OOP legacy, C# is arguably the cleanest, most efficient language for .NET in popular use today.
In this article, I’ll introduce you to the OOP features of C# as they apply to ASP.NET Web development. By the end, you should have a strong grasp of exactly what OOP is, and why it’s such a powerful and important aspect of ASP.NET. If you’re a seasoned pro when it comes to object oriented programming (for example, if you have some Java experience under your belt), you might like to bypass all the theory and skip straight to the section on Code-Behind Pages.
This article is the third in a series on ASP.NET. If you’re new to ASP.NET Web development and haven’t read my previous articles, check out Getting Started with ASP.NET and ASP.NET Form Processing Basics before proceeding.
Since C# is such a similar language to Java, much of this article is based on my two-part series, Object Oriented Concepts in Java. Please therefore accept my apologies if some of the examples seem eerily familiar to longtime readers.
Essential Jargon
Writing .NET applications (be they Windows desktop applications or ASP.NET Web applications) is all about constructing a web of interrelated software components that work together to get the job done. These components are called objects.
There are many different kinds of objects, and in fact a big part of programming in .NET is creating your own types of objects. To create a new type of object that you can use in your .NET programs, you have to provide a blueprint of sorts that .NET will use to create new objects of this type. This blueprint is called a class.
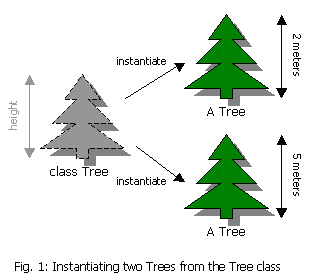 Let’s look at a conceptual example to help these ideas take hold. Say you worked for the National Forestry Commission, and your Web site needed to keep track of a group of trees in a forest; specifically, say it needed to keep track of the heights of those trees. Fig 1 shows an example of the class and objects that you might create as an ASP.NET programmer working on this site.
Let’s look at a conceptual example to help these ideas take hold. Say you worked for the National Forestry Commission, and your Web site needed to keep track of a group of trees in a forest; specifically, say it needed to keep track of the heights of those trees. Fig 1 shows an example of the class and objects that you might create as an ASP.NET programmer working on this site.
On the left we have a class called Tree. This class defines a type of object — a Tree — that will serve as the blueprint from which all Tree objects will be created. The class itself is not a Tree; it is merely a description of what a Tree is, or what all Trees have in common. In this example, our Tree class indicates that all Trees have a property called ‘height’.
On the right, we have two actual Tree objects. These are Trees, and they were created based on the blueprint provided by the Tree class. These objects are said to be instances of the Tree class, and the process of creating them is called instantiation. Thus, we can say that by instantiating the Tree class twice, we have created two instances of the Tree class, two objects based on the Tree class, or just two Trees. Notice that in creating these objects we have assigned a value to their height property. The first Tree is 2 meters high and the second is 5 meters high. Although the values of these properties differ, this does not change the fact that both objects are Trees. They are simply Trees with different heights.
Classes don’t only define properties of objects; they also define operations that may be performed by those objects. Such operations are called methods in object-oriented languages like C#. Continuing with our Tree example, we could define a method called ‘Grow’ in the Tree class. The result of this would be that every Tree object would then be able to perform the Grow operation as defined in the class. For instance, performing the Grow operation on a Tree might increase its height property by one metre.
A C# Tree
For our first foray into object-oriented programming, I propose to implement the Tree class discussed above in C# and then write an ASP.NET page that uses it to instantiate a couple of Trees and make them grow a little.
Open your text editor of choice and create a new text file called Tree.cs. This file will contain the definition of the Tree class. Type the following (the line numbers are provided for your convenience only, and should not be typed as part of the code):
1 /**
2 * Tree.cs
3 * A simple C# class.
4 */
5
6 public class Tree {Lines 1-4 are just an introductory comment (/* marks the start of a multi-line comment in C#, while */ marks the end), and will be ignored by the compiler. We begin the actual code on line 6 by announcing our intention to create a class called Tree. The word public indicates that our class may be used by any code in our program (or Web site). Note that I am observing the convention of spelling class names with a capital letter.
7 public int height = 0;
8Aside from the word public at the start of this line, this looks just like a standard variable declaration. As it would seem, we are declaring an integer variable called height and assigning it a value of zero. Again, it is a matter of convention that variable names are not capitalized. Variables declared in this way just inside a class definition become fields for objects of the class. Fields are variables that behave as properties of a class. Thus, this line says that every object of class Tree will have a field (property) called height that will contain an integer value, and that the initial value of the height field will be zero. The word public indicates that any code in your program (or Web site) can view and modify the value in this field. Later in this article, we’ll see techniques for protecting data stored in an object’s fields, but for now this will suffice.
That’s actually all there is to creating a Tree class that will keep track of its height; however, to make this example at least a little interesting, we’ll also implement the Grow method that I mentioned in the previous section. It begins with the following:
9 /**
10 * Grows this tree by 1 meter
11 */
12 public void Grow() {Let me explain this line one word at a time. The word public once again indicates that the Grow method (operation) is publicly available, meaning that it may be triggered by code anywhere in the program. Methods may also be private, protected, internal, or protected internal, and I’ll explain the meaning of each of these options later on. The word void indicates that this method will not return a value. Later on we’ll see how to create methods that produce some value as an outcome, and for such methods we would replace void with the type of value to be produced (e.g. int).
Finally, the word Grow is the actual name of the method that is to be created. Note that I am observing the convention of spelling method names starting with an uppercase letter (this .NET convention is different from some other languages, such as Java, where methods are normally not capitalized). The empty parentheses following this word indicate that it is a method we are declaring (as opposed to another field, like height above). Later on we’ll see cases where the parentheses are not empty. Finally, the opening brace signifies the start of the block of code that will be executed each time the Grow method of a Tree object is triggered.
13 height = height + 1;This operation happens to be a simple one. It takes the value of the height field and adds one to it, storing the result back into the height field. Note that we did not need to declare height as a variable in this method, since it has already been declared as a field of the object on line 7 above. If we did declare height as a variable in this method, C# would treat it as a separate variable created anew every time the method was run, and our class would no longer function as expected (try it later if you’re curious).
14 }
15 }The closing brace on line 14 marks the end of the Grow method, while that on line 15 marks the end of the Tree class. After typing all this in, save the file. Your next job is to compile it.
If you installed the Microsoft .NET Framework SDK separately (as opposed to getting it with a product like Visual Studio .NET), you should be able to open a Command Line window and run the C# compiler (by typing csc) from any directory. If you’re using the Framework SDK that comes with Visual Studio .NET, you need to launch the special Visual Studio .NET Command Prompt instead (Start | Programs | Microsoft Visual Studio .NET | Visual Studio .NET Tools | Visual Studio .NET Command Prompt).
If you’ve never used the Command Line before, read my cheat sheet on the subject before proceeding. When you’re ready, navigate to the directory where you created Tree.cs and type the following to compile the file:
C:CSTree>csc /target:library Tree.csAssuming you typed the code for the Tree class correctly, a file called Tree.dll is created in the same directory. This is the compiled definition of the Tree class. Any .NET program (or Web page) that you try to create a Tree in will look for this file to contain the blueprint of the object to be created. In fact, that’s our next step.
Using the Tree Class
Okay, so now you have the blueprint of a tree. Big deal, right? Where things get interesting is when you use that blueprint to create and manipulate Tree objects in a .NET program such as an ASP.NET Web page. Create a new file in your text editor called PlantTrees.aspx and follow along as I talk you through writing such a page.
First, here’s a look at the full code for the page:
1 <%@ Page Language="C#" %>
2 <html>
3 <head>
4 <title>Planting Trees</title>
5 <script runat="server">
6 protected void Page_Load(Object Source, EventArgs E)
7 {
8 string msg = "Let's plant some trees!<br/>";
9
10 // Create a new Tree
11 Tree tree1 = new Tree();
12
13 msg += "I've created a tree with a height of " +
14 tree1.height + " metre(s).<br/>";
15
16 tree1.Grow();
17
18 msg += "After a bit of growth, it's now up to " +
19 tree1.height + " metre(s) tall.<br/>";
20
21 Tree tree2 = new Tree();
22 Tree tree3 = new Tree();
23 tree2.Grow();
24 tree3.Grow();
25 tree2.Grow();
26 tree3.Grow();
27 tree2.Grow();
28 msg += "Here are the final heights:<br/>";
29 msg += " tree1: " + tree1.height + "m<br/>";
30 msg += " tree2: " + tree2.height + "m<br/>";
31 msg += " tree3: " + tree3.height + "m<br/>";
32
33 Output.Text = msg;
34 }
35 </script>
36 </head>
37 <body>
38 <p><asp:label runat="server" id="Output" /></p>
39 </body>
40 </html>If you look at the bottom of the code, you’ll see the HTML section basically just contains a single <asp:label> tag. Our Page_Load function is where all the action will happen, and it will use that <asp:label> to display the results of our messing around.
So let’s focus on the code within Page_Load:
8 string msg = "Let's plant some trees!<br/>";Here we’re creating a text string (string) called msg. We’ll use it to store the message that we’ll eventually tell the <asp:label> tag to display. To begin with, it contains a little introductory message, with a <br/> tag at the end to create a new line on the page.
10 // Create a new Tree
11 Tree tree1 = new Tree();As the comment on line 10 suggests, line 11 achieves the feat of creating a new Tree out of thin air. This is a really important line; so let me explain it in depth. The line begins by declaring the class (type) of object to be created (in this case, Tree). We then give a name to our new Tree (in this case, tree1). This is in fact identical to declaring a new variable by specifying the type of data it will contain followed by the name of the variable (e.g. string msg).
The rest of the line is where the real magic happens. The word new is a special C# keyword that triggers the instantiation of a new object. After new comes the name of the class to be instantiated, followed by a pair of parentheses (again, in more complex cases that we shall see later, these parentheses may not be empty).
In brief, this line says, “create a variable of type Tree called tree1, and assign it a value of a new Tree.” So in fact this line isn’t just creating a Tree, it’s also creating a new variable to store it in. Don’t worry if this distinction is a little hazy for you at this point; later examples will serve to clarify these concepts significantly.
Now that we’ve created a tree, let’s do something with it:
13 msg += "I've created a tree with a height of " +
14 tree1.height + " metre(s).<br/>";This should not be too unfamiliar to you. The += near the start of the line tells C# to add the following string to the string already stored in the msg variable. In other words, msg += is shorthand for msg = msg +. So this two-line command is just adding another line of text to the message, except that part of the line of text takes its value from the height of the tree1 variable (tree1.height). If you simply typed height instead of tree1.height, C# would think you were referring either to a variable called height declared in this method, or a tag with ID height (in the PlantTrees.aspx page itself). Unable to find either of these, your Web server would print out an error message when you tried to view the page. In order to tell C# that you are referring to the height field of the Tree in tree1, you need to tack on tree1 followed by the dot operator (.).
The dot operator may be thought of sort of like the C# way of saying “belonging to” when you read the expression backwards. Thus, tree1.height should be read as “height belonging to tree1.” Since Trees are created with a height of zero, lines 13 and 14 should print out “I’ve created a tree with a height of 0 metre(s).”
Calling (or triggering) methods belonging to an object is accomplished in a similar way:
16 tree1.Grow();This line calls the Grow method belonging to the Tree in tree1, causing it to grow by a metre. Again, the set of parentheses indicate that it is a method we are referring to, not a field. So after this line if we print out the height of tree1 again…
18 msg += "After a bit of growth, it's now up to " +
19 tree1.height + " metre(s) tall.<br/>";This line will print out “After a bit of growth, it is now up to 1 metre(s) tall.”
To show that each Tree has its own height value that is independent of those of the other Trees, we’ll polish off this example by creating a couple more Trees and having them grow by different amounts:
21 Tree tree2 = new Tree();
22 Tree tree3 = new Tree();
23 tree2.Grow();
24 tree3.Grow();
25 tree2.Grow();
26 tree3.Grow();
27 tree2.Grow();
28 msg += "Here are the final heights:<br/>";
29 msg += " tree1: " + tree1.height + "m<br/>";
30 msg += " tree2: " + tree2.height + "m<br/>";
31 msg += " tree3: " + tree3.height + "m<br/>";Finally, we assign our completed msg variable as the Text property of the <asp:label id="Output"/> tag:
33 Output.Text = msg;
34 }Ok, so now we’ve got a class (Tree) and an ASP.NET page that uses it. Let’s deploy these on an IIS Web server to try them out!
Create a new directory in your Web root directory (e.g. c:inetpubwwwroot) called Trees (i.e. c:inetpubwwwrootTrees). This will be the root directory of our little ASP.NET Web application. Copy PlantTrees.aspx into that directory, then load the page in your browser (http://localhost/Trees/PlantTrees.aspx). Fig. 2 illustrates what you should see.
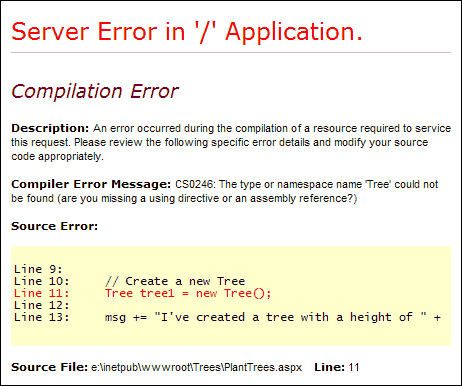 Fig. 2 Compilation error due to a missing class
Fig. 2 Compilation error due to a missing classIf you sift through the technical mumbo jumbo, you can see that this error screen is complaining that ASP.NET has no idea what a Tree is. We need to put our Tree.dll file (which contains the Tree class) where ASP.NET can find it.
ASP.NET looks for class files in the bin directory of the current Web application. So deploying our Tree class is a two-step process:
- Ensure that IIS is configured so that the
Treesdirectory is a Web application. - Place the
Tree.dllfile into theTreesbindirectory.
To make the Trees directory a Web application, open the Windows Control Panel on your server, open Administrative Tools, then Internet Information Services. Under local computer, Web Sites, Default Web Site, you’ll see the Trees directory listed. The plain folder icon next to it indicates that it’s just a regular directory, as opposed to a Web application.
 Right-click the
Right-click the Trees directory and choose Properties…. On the Directory page, click the Create button under Application Settings. Click OK to close the Window, and you’ll see that Trees now has a nice blue Web Application icon next to it. It looks like a little box with a Web page in it (see Fig. 3).
Now when IIS loads an ASP.NET page in Trees or one of its subdirectories, it will look in Treesbin for any class files that might be needed. In this case, drop Tree.dll into the bin directory (you’ll need to create the bin directory if you haven’t already).
With your Web Application created and Tree.dll in the bin directory, try loading http://localhost/Trees/PlantTrees.aspx again. This time, you should see the expected output, as shown in Fig. 4.
 Fig. 4 Output of
Fig. 4 Output of PlantTrees.aspxInheritance
One of the strengths of object-oriented programming is inheritance. This feature allows you to create a new class that is based on an old class. Let’s say your program also needed to keep track of coconut trees, so you would need a new class called CoconutTree that kept track of the number of coconuts in each tree. You could write the CoconutTree class from scratch, copying all the code from the Tree class that is responsible for tracking the height of the tree and allowing the tree to grow, but for more complex classes that could involve a lot of duplicated code. What would happen if you later decided that you wanted your Trees to have non-integer heights (like 1.5 metres)? You would have to adjust the code in both classes!
Inheritance allows you to define your CoconutTree class as a subclass of the Tree class, such that it inherits the fields and methods of that class in addition to its own. To see what I mean, here’s the code for CoconutTree:
1 /**
2 * CoconutTree.cs
3 * A more complex kind of tree.
4 */
5
6 public class CoconutTree : Tree {
7 public int numNuts = 0; // Number of coconuts
8
9 public void GrowNut() {
10 numNuts = numNuts + 1;
11 }
12
13 public void PickNut() {
14 numNuts = numNuts - 1;
15 }
16 }The code : Tree on line 6 endows the CoconutTree class with a height field and a Grow method in addition to the numNuts field (yes, this example was fiendishly conceived to produce a childishly amusing variable name — what of it?) and the GrowNut and PickNut methods that are declared explicitly for the class. The diagram in Fig. 5 shows the relationship of our two classes.
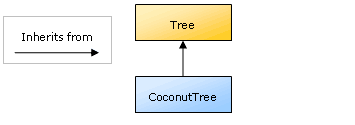 Fig. 5
Fig. 5 CoconutTree is a subclass of TreeBy building up a hierarchical structure of classes with multiple levels of inheritance, you can create powerful models of complex Objects with little or no duplication of code (which makes for less typing and easy maintenance). We’ll see a very important example of the power of inheritance for ASP.NET developers before the end of this article.
Compiling Multiple Classes
You should now have two C# source files in your working directory — Tree.cs and CoconutTree.cs. Tree.cs can still be compiled on its own as before, but since CoconutTree.cs refers to the Tree class, the compiler needs to know where to find that class to successfully compile CoconutTree.cs.
In most cases, the easiest way to proceed is to compile all your related classes into a single DLL (also known as an assembly in .NET terminology). To compile Tree.cs and CoconutTree.cs into a single DLL file called trees.dll that will contain the definitions of both classes, type the following command in the directory that contains the C# source files:
csc /target:library /out:trees.dll Tree.cs CoconutTree.csIf the files you want to compile are the only C# source files in the directory, you can use a wildcard as a shortcut:
csc /target:library /out:trees.dll *.csYou can then just plop the trees.dll file in the bin directory of your Web application and it will have access to both classes.
Passing Parameters and Returning Values
Most of the methods we have looked at so far have been of a special type. Here is a declaration of one such method, the PickNut method for the CoconutTree class that we developed above:
public void PickNut() {
numNuts = numNuts - 1;
}What makes this, and the other methods we have looked at so far, special is the fact that it doesn’t require any parameters, nor does it return a value. As you’ll come to discover as we look at more practical examples of C# classes later in this series, most methods do one or both of these.
Parameters are pieces of information that must be provided when invoking a function to completely specify the action to be taken. For example, if we wanted to make the PickNut method above more powerful, we could give it a parameter to indicate the number of nuts to be picked:
public void PickNut(int numberToPick) {
numNuts = numNuts - numberToPick;
}In this new version of the PickNut method, we have specified that the function takes an integer (int) parameter, the value of which is stored in a variable called numberToPick. The code of the method then uses it as the number to be subtracted from the numNuts field. Thus, we can now pick as many nuts as we want from a CoconutTree with a single invocation of the PickNut method. Here are a few sample invocations of PickNut:
CoconutTree ct = new CoconutTree(); // New tree
// Presumably we grow a few nuts first...
ct.PickNut(1); // Picks one nut
ct.PickNut(5); // picks five nuts
ct.PickNut(0); // Doesn't do anything
int nuts = 10;
ct.PickNut(nuts); // Picks ten nuts
ct.PickNut(-1); // Picks -1 nut (??)As this last line demonstrates, there is a problem with this method. Since it accepts any integer as the number of nuts to be picked, there is nothing stopping a program that uses it to pick a negative number of nuts. Looking at the code of our method, this would actually just add more nuts to the tree, but we should not allow operations on our object that do not make sense in the real world. Another operation that would not make sense would be to pick more nuts than there are available for picking on the tree! With the existing code, this would result in our tree reporting a negative number of nuts — hardly a realistic situation.
These two problems reveal an important issue when designing methods that require parameters. You should always make sure that the value passed to a method makes sense before using it. Even if you’re only planning on using a class in your own programs, it’s surprisingly easy to forget what values will and will not cause problems when you aren’t checking the values automatically.
The following modified version of PickNut checks the parameter to make sure that it is not negative, and that it is no larger than the number of nuts on the tree:
public void PickNut(int numberToPick) {
if (numberToPick < 0) return; // Cannot pick negative number
if (numberToPick > numNuts) return; // Not enough nuts
numNuts = numNuts - numberToPick;
}The return command immediately terminates the method. Thus, the operation of picking the nuts (subtracting from the numNuts field) will only occur if both of the conditions in the if statements are false. This ensures that our two constraints are met before we allow the picking operation to go ahead.
One problem still remains, here. How can the code that invokes the PickNut method know whether the picking operation was successful? After all, if the picking operation fails because one of the constraints was not satisfied, we don’t want our program to carry on as if it was able to pick the nuts. To resolve this issue, we must once again alter PickNut; this time, we will make it return a value:
public bool PickNut(int numberToPick) {
if (numberToPick < 0) return false;
if (numberToPick > numNuts) return false;
numNuts = numNuts - numberToPick;
return true;
}Not only can methods receive parameter values when they are invoked, but they can also send a value back by specifying the value as part of the return command. In this new version of the code, we have replaced the word void in the method declaration with the word bool. This indicates that the function will return a Boolean (true/false) value when it terminates. In this particular case, we have elected to return true if the picking operation succeeded, and false if it failed for any reason. This allows us to structure the code of the program that invokes the method as follows:
if (!ct.PickNut(10)) {
ErrorLabel.Text = "Error: Could not pick 10 nuts!";
return;
}
nutsInHand = nutsInHand + 10;The condition of the if statement calls PickNut with a parameter value of 10, and then checks its return value to see if it’s false (note the ! operator). If it is, an error message is printed out. The return command then terminates the Page_Load function immediately, which is a reasonable response to an unexpected error. Otherwise, the program proceeds as usual.
Another common use for return values is to create methods that perform some common calculation and return the result for the program to use. There will be plenty more examples in the rest of this series for you to learn from.
Access Modifiers
As we have already seen, classes should usually be set public to allow code elsewhere in your application to make use of it. But there are times when you’ll want to restrict access to a class; for example, you might only want to allow other classes in the same assembly (DLL file) to use it. That’s when you’ll want to specify a different access modifier. Class members, which include fields and methods, can be similarly modified to control access to them.
Here are the access modifiers supported by C#:
public: any code may access the class or class member.private: the class or class member is not accessible outside of the class that contains it (yes, in advanced cases, you can put a class inside another class).protected: the class or class member is only accessible by the class that contains it, or any subclass of that class.internal: the class or class member is only accessible by code in the same assembly (DLL).protected internal: the class or class member is accessible by code in the same assembly (DLL), or by any subclass of the class that contains it.
If you don’t specify any access modifier, C# will default to private.
Consider the following sample declarations:
int numNuts = 0;
bool PickNut(int numberToPick) {
...
}Since no access modifiers are specified, both of these members will act as if they were declared private. Even if the class is declared public, the value of the above numNuts field (assuming it is declared as the field of the class) may only be accessed or modified by code inside the same class. Similarly, the PickNut method shown above may only be invoked by code elsewhere in the class.
Distinguishing the situations in which each access control setting is appropriate takes a little experience. It’s tempting at first to just declare everything public to save yourself the trouble of worrying when something is accessible and when it isn’t. While this will certainly work, it is definitely not in the spirit of object oriented programming. Code that you plan to reuse or distribute, especially, will benefit from being assigned the most restrictive access control settings that are appropriate. One reason for this is illustrated in the following section.
For now, just take note of the choices I make for access modifiers. I’ll explain my reasons in each case, and before long you’ll be able to choose your own!
C# Properties
Previously, we modified the PickNut method so that it would not accept too high a number, which would cause our CoconutTree to think it contained a negative number of coconuts. But there is a much simpler way to produce this unrealistic situation:
CoconutTree ct = new CoconutTree();
ct.numNuts = -10;How can we protect object fields like numNuts from being assigned values like this that don’t make sense? The solution is to make the fields themselves private, and permit access to them using a C# Property.
A C# Property is a pair of methods that is used to read and write a property of an object. From here on, C# Properties will be called simply properties.
Here is an updated version of our CoconutTree class that makes use of this technique:
1 public class CoconutTree : Tree {
2 private int numNuts = 0;
3
4 public void GrowNut() {
5 numNuts = numNuts + 1;
6 }
7
8 public bool PickNut(int numToPick) {
9 if (numToPick < 0) return false;
10 if (numToPick > numNuts) return false;
11 numNuts = numNuts - numToPick;
12 return true;
13 }
14
15 public int NumNuts {
16 get {
17 return numNuts;
18 }
19 set {
20 if (value < 0) return;
21 numNuts = value;
22 }
23 }
26 }As you can see on line 2, the numNuts field is now private, meaning that only code within this class is allowed to access it. The GrowNut and PickNut methods remain unchanged; they can continue to update the numNuts field directly (the constraints in PickNut ensure that the value of numNuts remains legal). Since we still want code to be able to determine the number of nuts in a tree, we have added a public NumNuts property (note the capitalization, which distinguishes NumNuts the property from numNuts the field — a pair of numNuts, so to speak):
15 public int NumNuts {
16 get {
17 return numNuts;
18 }
19 set {
20 if (value < 0) return;
21 numNuts = value;
22 }
23 }The declaration of a property starts off just like a field, with an access modifier (public), the type (int), and the name (NumNuts), which is capitalized by convention. After those preliminaries, we define the accessors. The get accessor is used to retrieve the value of the property, while the set accessor is used to change it.
Accessors behave just like methods. The get accessor, which must always return a value of the type assigned to the property, in this example simply returns the value of the private numNuts field. Nothing too fancy here. The set accessor, however, which is always provided with a variable called value that contains the value that is to be assigned to the property, checks that this variable is greater or equal to zero (since we can’t have a negative number of nuts) before storing it in the numNuts field.
Even in cases where any value is acceptable, you should make your objects’ fields private and provide a property to access them. Doing this allows your programs to exhibit an important feature of object oriented programming called encapsulation.
Encapsulation means that the internal representation of an object is separated from the interface it presents to other objects in your program. In other words, a programmer that uses your class only needs to know what the public methods and properties do, not how they work. The advantage is that you can change how your class works to improve performance or add new features without breaking any code that relies on the methods provided by your original class.
For example, if you decided you wanted to represent each coconut as an individual object of class Coconut instead of using a single integer variable to keep count, you could make the necessary changes and still have the same property and two methods as the implementation above. Old code that was written with the original interface in mind would continue to work as before, while new code could take advantage of the new features (which would of course be provided by new methods).
As an exercise, rewrite the Tree class so that it correctly encapsulates its height field with a property.
Constructors
A constructor is a special type of method that is invoked automatically when an object is created. Constructors allow you to specify starting values for properties, and other such initialization details.
Consider once again our Tree class; specifically, the declaration of its height field (which should now be private and accompanied by a public property):
private int height = 0;It’s the = 0 part that concerns us here. Why should all new trees be of height zero? Using a constructor, we can let users of this class specify the initial height of the tree. Here’s what it looks like:
private int height;
public Tree(int height) {
if (height < 0) this.height = 0;
else this.height = height;
}At first glance, this looks just like a normal method. There are two differences, however:
- Constructors never return a value; thus, they don’t have a return type (
void,int,bool, etc.) in their declaration. - Constructors have the same name as the class they are used to initialize. Since we are writing the
Treeclass, its constructor must also be namedTree.
So dissecting this line by line, the first line states that we are declaring a public constructor that takes a single parameter and assigns its value to an integer (int) variable height. Note that this is not the object field height, as we shall see momentarily. The second line checks to see if the height variable is less than zero. If it is, we set the height field of the tree to zero (since we don’t want to allow negative tree heights). If not, we assign the value of the parameter to the field.
Notice that since we have a local variable called height, we must refer to the height field of the current object as this.height. this is a special variable in C# that always refers to the object in which the current code is executing. If this confuses you (no pun intended), you could instead name the constructor’s parameter something like newHeight. You’d then be able to refer to the object field simply as height.
Since the Tree class now has a constructor with a parameter, you must specify a value for that parameter when creating a new Tree:
Tree myTree = new Tree(10); // Initial height 10Overloaded Methods
Sometimes it makes sense to have two different versions of the same method. For example, when we modified the PickNut method in the CoconutTree class to require a parameter that specified the number of nuts to pick, we lost the convenience of being able to pick a single nut by just calling PickNut(). C# actually lets you declare both versions of the method side by side and determines which one to use by the number and type of the parameters passed when the method is called. Methods that are declared with more than one version like this are called overloaded methods.
Here’s how to declare the two versions of the PickNut method:
public bool PickNut() {
if (numNuts == 0) return false;
numNuts = numNuts - 1;
return true;
}
public bool PickNut(int numToPick) {
if (numToPick < 0) return false;
if (numToPick > numNuts) return false;
numNuts = numNuts - numToPick;
return true;
}One way to save yourself some typing is to notice that PickNut() is actually just a special case of PickNut(int numToPick); that is, calling PickNut() is the same as calling PickNut(1), so you can implement PickNut() by simply making the equivalent call:
public bool PickNut() {
return PickNut(1);
}
public bool PickNut(int numToPick) {
if (numToPick < 0) return false;
if (numToPick > numNuts) return false;
numNuts = numNuts - numToPick;
return true;
}Not only does this save two lines of code, but if you ever change the way the PickNut method works, you only have to adjust one method instead of two!
Constructors can be overloaded in the same way as normal methods. If you miss the convenience of being able to create a new Tree of height zero, you can declare a second constructor that takes no parameters:
private int height;
public Tree() {
this(0);
}
public Tree(int height) {
if (height < 0) this.height = 0;
else this.height = height;
}Note that we have once again saved ourselves some typing by implementing the simpler method (Tree()) by invoking a special case of the more complex method (Tree(0)). In the case of a constructor, however, you call it by the special name this.
Advanced Inheritance: Overriding Methods
I covered inheritance earlier in this article, but I left out one advanced issue for the sake of brevity that I’d like to cover now: overriding methods. As you know, an object of class CoconutTree inherits all of the features of the Tree class, on which it is based (i.e. CoconutTree is a subclass of Tree). Thus, CoconutTrees have Grow methods just like Trees do.
But what if you wanted CoconutTrees to sprout new coconuts when they grew? Sure, you could call the GrowNut method every time you caused a CoconutTree to grow, but it would be nicer if you could treat Trees and CoconutTrees exactly the same way (i.e. call their Grow method) and have them both do what they’re supposed to do when objects of their type grow.
To have the same method do something different in a subclass, you must override that method with a new definition in the subclass. Put simply, you can re-declare the Grow method in the CoconutTree class to make it do something different! Here’s a new definition for grow that you can add to your CoconutTree class:
public void Grow() {
height = height + 1;
GrowNut();
}Simple, right? But what if you added new functionality to the Grow method in the Tree class (e.g. to grow leaves)? How could you make sure that this was still inherited by the CoconutTree class without having to make the change in both places? Like in our discussion of overloaded methods, where we implemented a simple method by calling a special case of the more complicated method, we can implement a new definition for a method in a subclass by referring to its definition in the base class (also called the parent class or superclass):
public void Grow() {
base.Grow();
GrowNut();
}The base.Grow() line invokes the version of Grow defined in the base class (Tree), thus saving us from having to reinvent the wheel. This is especially handy when you are creating a class that extends a class for which you do not have the source code (e.g. a class provided by another developer, or built into .NET). By simply calling the base class versions of the methods you are overriding, you can ensure that your objects aren’t losing any functionality.
Constructors may be overridden just like normal methods, but calling the version of the constructor in the base class is slightly different. Here’s a set of constructors for the CoconutTree class, along with the new declaration of the numNuts field without an initial value:
private int numNuts;
public CoconutTree() : base() {
numNuts = 0;
}
public CoconutTree(int height) : base(height) {
numNuts = 0;
}
public CoconutTree(int height, int numNuts) : base(height) {
if (numNuts < 0) this.numNuts = 0;
else this.numNuts = numNuts;
}The first two constructors override their equivalents in the Tree class, while the third is completely new. Notice that we call the constructor of the base class as base(), but instead of putting this call inside the constructor body, we add it to the end of the constructor declaration, using the : operator. All three of our constructors call a constructor in the base class to ensure that we are not losing any functionality.
Namespaces
For much of this article, we have worked with a class called Tree. Now, while Tree isn’t an especially original name for a class, it fits the class perfectly. The problem is that the same name might fit another class just as well, and you’ll have a naming conflict on your hands. Such conflicts aren’t too serious when you get to write all your own classes; however, when you need to bring in a set of classes that someone else wrote for use in your program, things can get messy.
Consider, for example, what would happen if you’d designed all of the classes to handle the logic for a Web site that will track the sales of buttons for clothing. In such a case it would be natural to have a class called Button, but then your boss tells you he or she wants a nice, graphical user interface for the program. To your dismay, you find that the class built into the .NET Framework for creating buttons on user interfaces is called (you guessed it) Button. How can this conflict be resolved without having to go back through your code and change every reference to your Button class?
Namespaces to the rescue! C# provides namespaces as a way of grouping together classes according to their purpose, the company that wrote them, or whatever other criteria you like. As long as you ensure that your Button class is not in the same namespace as C#’s built-in Button class, you can use both classes in your program without any conflicts arising.
By default, classes you create reside in the default namespace, an unnamed namespace where all classes that are not assigned namespaces go. For most of your programs it is safe to leave your classes in the default namespace. All of the .NET Framework’s built-in classes as well as most of the classes you will find available on the Internet and from other software vendors are grouped into namespaces, so you usually don’t have to worry about your classes’ names clashing with those of other classes in the default namespace.
You will want to group your classes into namespaces if you intend to reuse them in future projects (where new class names may clash with those you want to reuse), or if you want to distribute them for use by other developers (where their class names may clash with your own). To place your class in a namespace, you simply have to surround your class declaration with a namespace declaration. For example, classes that we develop at SitePoint.com are grouped in the Sitepoint namespace by adding the following to our C# files:
namespace SitePoint {
// Class declaration(s) go here
}If we were to place our Tree class inside the SitePoint namespace in this way, the class’ full name would become SitePoint.Tree. You can also declare namespaces within namespaces to further organize your classes (e.g. SitePoint.Web.Tree).
As it turns out, the Button class built into the .NET Framework is actually in the System.Windows.Forms namespace, which also contains all of the other classes for creating basic graphical user interfaces in .NET. Thus, the fully qualified name of .NET’s Button class is System.Windows.Forms.Button. To make use of this class without your program thinking that you’re referring to your own Button class, you can use this full name instead. For example:
// Create a Windows Button
System.Windows.Forms.Button b = new System.Windows.Forms.Button();In fact, C# requires that you use the full name of any class that is not in the same namespace as the current class!
But what if your program doesn’t have a Button class to clash with the one built into .NET? Spelling out the full class name every time means a lot of extra typing. To save yourself this annoyance, you can import the System.Windows.Forms namespace into the current namespace by putting a using line at the top of your C# file (just inside the namespace declaration(s), if any):
namespace SitePoint {
using System.Windows.Forms;
// Class declaration(s) go here
}Once its namespace is imported, you can use the class by its short name (Button) as if it were part of the same namespace as your class.
So if you put your Tree class into a namespace called SitePoint, any class not also declared to be in the SitePoint namespace that needed to use it would either have to call it SitePoint.Tree or import the SitePoint namespace.
For code in an ASP.NET page (.aspx file), the following namespaces are automatically imported:
SystemSystem.CollectionsSystem.Collections.SpecializedSystem.ConfigurationSystem.IOSystem.TextSystem.Text.RegularExpressionsSystem.WebSystem.Web.CachingSystem.Web.SecuritySystem.Web.SessionStateSystem.Web.UISystem.Web.UI.HtmlControlsSystem.Web.UI.WebControls
But if you wanted to access the newly-namespaced SitePoint.Tree class in your PlantTrees.aspx file, you’d either have to call it by its full name, or use an import directive.
Like a page directive, an import directive is a special tag that goes at the top of your file to provide special information about your ASP.NET page. Here’s what the import directive to use the SitePoint namespace would look like:
<%@ Import namespace="SitePoint" %>Static Members
All class members (including methods, fields and properties) can be declared static. Static members belong to the class instead of to objects of that class. Since static members aren’t that common in basic ASP.NET development, I won’t dwell on static members too heavily; but for the sake of completeness, let’s look at a simple example.
It might be useful to know the total number of trees that had been created in our program. To this end, we could create a static field called totalTrees in the Tree class, and modify the constructor to increase its value by one every time a Tree was created. Then, using a static property called TotalTrees, for which we would only define a get accessor (making it a read-only property), we could check the value at any time by checking the value of Tree.TotalTrees.
Here’s the code for the modified Tree class:
public class Tree {
private static int totalTrees = 0;
private int height;
public Tree() {
this(0);
}
public Tree(int height) {
if (height < 0) this.height = 0;
else this.height = height;
totalTrees = totalTrees + 1;
}
f
public static int TotalTrees {
get {
return totalTrees;
}
}
// ... rest of the code here ...
}Static members are useful in two main situations:
- When you want to keep track of some information shared by all members of a class (as above).
- When it doesn’t make sense to have more than one instance of a property or method.
As I said, static members don’t tend to crop up in basic ASP.NET applications, but it’s useful to know about them so you’re not totally bamboozled if you see someone accessing a method in a class instead of an object!
Code-Behind Pages in ASP.NET
Okay, so I’ve waffled on for what must seem like forever, and all you’ve learned how to do is grow trees (and nuts!). “When’s he going to get to the point?!” you must be asking. Either that, or you already know the basic concepts of OOP and you’ve skipped directly here for the meat.
Well here’s the payoff:
Everything… including the pages themselves. Every .aspx page you write is automatically compiled into a class that inherits from the System.Web.UI.Page class, which is built into the .NET Framework.
Everything that ASP.NET pages do automatically is handled by that class (e.g. calling the Page_Load function — which is actually a method — before the page is displayed). So creating a site of ASP.NET pages is actually a process of creating subclasses of System.Web.UI.Page. This is illustrated in Fig. 6.
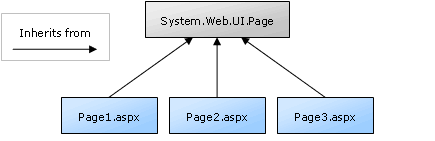 Fig. 6 ASP.NET pages inherit from
Fig. 6 ASP.NET pages inherit from System.Web.UI.Page by defaultOkay, I can see you’re getting impatient again. How about I tell you what this gives you (besides a headache)?
The object-oriented nature of ASP.NET lets you achieve complete separation of design code (HTML) and server-side code. The technique for doing this is called Code-Behind. The idea is that you create a subclass of System.Web.UI.Page that contains all your server-side code, and then make your .aspx page (which contains all your design code) inherit from that class instead of from System.Web.UI.Page (see Fig. 7).
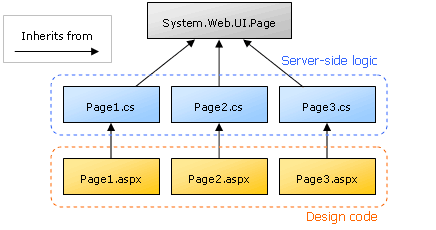 Fig. 7 Code-Behind files: server-side logic, and design code are kept separate
Fig. 7 Code-Behind files: server-side logic, and design code are kept separateNot convinced? Let’s look at an example.
Here’s the code for the last example we saw in ASP.NET Form Processing Basics:
<%@ Page Language="C#" %>
<html>
<head>
<title>My First ASP.NET Form</title>
<script runat="server">
protected void Page_Load(Object Source, EventArgs E) {
if (IsPostBack) {
NameForm.Visible = false;
NameLabel.Text = NameBox.Text;
NameLabel.Style.Add( "font-weight", "bold" );
}
TimeLabel.Text = DateTime.Now.ToString();
}
</script>
</head>
<body>
<p>Hello <asp:label runat="server" id="NameLabel">there
</asp:label>!</p>
<form runat="server" id="NameForm">
<p>Do you have a name?</p>
<p><asp:textbox runat="server" id="NameBox" />
<input type="submit" value="Submit" /></p>
</form>
<p>The time is now: <asp:label runat="server" id="TimeLabel" /></p>
</body>
</html>Now, this is a relatively simple ASP.NET page, and yet the server-side code (the Page_Load method) takes up about half the page. An HTML-and-JavaScript designer who had to tweak the design of a more typical ASP.NET page would suffer a coronary at the sight of the code in the file (many ASP developers had trouble keeping designers around for this very reason).
In addition, if a Web development team composed of server-side developers and Web designers had to work on a site collaboratively, the tug-of-war involved in letting team members of both types work on a page at the same time would be next to unmanageable!
Let’s create a class called HelloTherePage that contains all the server-side code:
using System;
using System.Web;
using System.Web.UI;
using System.Web.UI.HtmlControls;
using System.Web.UI.WebControls;
public class HelloTherePage : Page {
protected HtmlForm NameForm;
protected Label NameLabel;
protected Label TimeLabel;
protected TextBox NameBox;
protected void Page_Load(Object Source, EventArgs E) {
if (IsPostBack) {
NameForm.Visible = false;
NameLabel.Text = NameBox.Text;
NameLabel.Style.Add( "font-weight", "bold" );
}
TimeLabel.Text = DateTime.Now.ToString();
}
}First note the block of using commands at the top of the file. Since we’re not inside a .aspx file anymore, we don’t have the benefit of all the automatic namespace imports we had before; therefore, we must explicitly import the namespaces we want to use. The five namespaces I’ve used here are the most common for ASP.NET programs.
The Page_Load method is defined exactly as it was in the .aspx page above. Note that it is declared protected, since the only class that needs to call this class is the subclass we’re going to create with our .aspx file (recall that protected means a member is accessible only by the class itself or any of its subclasses).
Also declared in this class are four protected fields: NameForm, NameLabel, TimeLabel, and NameBox. These are the ID‘s of the page elements that Page_Load accesses in the page. In the .aspx subclass, these fields will be overridden by the actual elements (e.g. <asp:label id="NameLabel"> overrides NameLabel), but they must be declared in this class so that C# doesn’t get confused when we refer to them in Page_Load.
Since NameLabel and TimeLabel represent <asp:label> tags in the .aspx page, they should be objects of class System.Web.UI.WebControls.Label (which we can abbreviate as Label, since our file is using the System.Web.UI.WebControls namespace). NameBox is a <asp:textbox> and is therefore a System.Web.UI.WebControls.TextBox. NameForm is an HTML <form> tag, which is represented by an object of class System.Web.UI.HtmlControls.HtmlForm. In general, all ASP.NET tags (<asp:tagName>) have their corresponding classes in the System.Web.UI.WebControls namespace, while HTML tag classes are in System.Web.UI.HtmlControls, and have names of the form HtmlTagName.
Save this file as HelloThere.cs in the same directory as the .aspx page (don’t worry — IIS is smart enough not to allow Web browsers to view C# and other .NET source code files in Web-accessible directories). Now let’s re-write HelloThere.aspx to use the Code-Behind file we have just written:
<%@ Page Inherits="HelloTherePage" src="HelloThere.cs" %>
<html>
<head>
<title>My First ASP.NET Form</title>
</head>
<body>
<p>Hello <asp:label runat="server" id="NameLabel">there
</asp:label>!</p>
<form runat="server" id="NameForm">
<p>Do you have a name?</p>
<p><asp:textbox runat="server" id="NameBox" />
<input type="submit" value="Submit" /></p>
</form>
<p>The time is now: <asp:label runat="server" id="TimeLabel" /></p>
</body>
</html>The changes are dramatic, but very simple! I’ve simply removed the <script> tag that contained the Page_Load method, which is now defined in HelloTherePage, the base class of this page defined in the Code-Behind file, and added two new attributes to the Page directive on the first line. I also removed the Language attribute from this directive, since there is no longer any server-side code in this file for which a language would need to be specified.
The Inherits attribute is set to the name of the class from which this page should inherit. By default, this is System.Web.UI.Page. The src attribute tells the ASP.NET page compiler where to find the source code for the class specified. ASP.NET uses this attribute to intelligently compile the Code-Behind file for you on the fly and put the resulting .dll file in the bin directory of the Web application, so that this page can find it. You could of course do this manually, but it’s much easier to let ASP.NET do the work of recompiling the Code-Behind file whenever you make changes automatically.
With HelloThere.cs and HelloThere.aspx in the same directory on your Web server, you should be able to load HelloThere.aspx as usual and find that it behaves exactly as it did before you split the server-side code into a separate file.
Summary
Well! It’s been a long trip, but in this article I’ve taken you on a tour of all the important object-oriented features of the C# language. What’s more, I’ve shown you how they apply to ASP.NET Web development.
In particular, I’ve demonstrated how to use a class to handle some of the logic in a simple page that tracks the growth of trees. In a practical system, each Tree class might for instance fetch its information from a database of national forest growth. The point is that the ASP.NET page doesn’t need to know how to track the growth of trees, because all that functionality is bottled up in a handy class that we can reuse in other projects if needed.
By far the most exciting application of object oriented programming concepts to everyday ASP.NET development, however, is the fact that everything in ASP.NET is an object. By defining a class in a Code-Behind file for each of our pages, we can totally separate the server-side logic of our pages from their design, thus letting our Web designers sleep at night. In fact, you could even make two or more different .aspx pages that inherit from the same Code-Behind file in order to experiment with different page designs (perhaps a WAP version of your site for mobile devices?) that share the same server-side logic.
In the next article in this series, I’ll introduce you to event-driven programming. It turns out that .NET classes (including most of those that make up ASP.NET) can send out events that your code can listen for and react to. We’ll see how these events are used to achieve some common tasks in ASP.NET development.
See you next time!
Frequently Asked Questions (FAQs) about C# and ASP.NET Development
What are the key differences between C# and ASP.NET?
C# and ASP.NET are both Microsoft technologies used for web development. C# is a programming language, while ASP.NET is a web application framework. C# is used to write the logic of the application, whereas ASP.NET provides the structure for the application. ASP.NET can use several languages for coding, including C#, VB.NET, and others.
How can I start learning C# and ASP.NET?
There are several resources available online to start learning C#. Microsoft’s official documentation is a great place to start. It provides a comprehensive guide to the language, including tutorials and sample code. For ASP.NET, Microsoft also provides a Getting Started guide. Additionally, there are numerous online courses, tutorials, and books available on platforms like Udemy, Coursera, and Amazon.
What are the prerequisites for learning ASP.NET?
Before starting with ASP.NET, it’s recommended to have a basic understanding of HTML, CSS, and JavaScript, as these are used for designing and structuring web pages. Knowledge of a .NET language, preferably C#, is also necessary as it’s used for writing the server-side code in ASP.NET applications.
What is Object-Oriented Programming (OOP) in C#?
Object-Oriented Programming (OOP) is a programming paradigm that uses “objects” – data structures consisting of data fields and methods together with their interactions. In C#, everything is an object. OOP aims to implement real-world entities like inheritance, hiding, polymorphism, etc in programming. It simplifies software development and maintenance by providing some concepts like Class, Object, Inheritance, Polymorphism, Abstraction, and Encapsulation.
What are the main features of ASP.NET?
ASP.NET provides several features that make it a powerful tool for web development. These include a built-in Windows authentication for secure applications, a per-application configuration that allows for easy deployment, a server-side code execution for improved performance, and a language independence that allows you to choose the language that best applies to your application.
How does ASP.NET differ from other web development frameworks?
ASP.NET stands out from other web development frameworks due to its integration with the .NET platform, its language independence, and its support for both Web Forms and MVC architecture. It also offers robust security features, including built-in Windows authentication and per-application configuration.
What is the role of the .NET framework in C# and ASP.NET development?
The .NET framework provides a runtime environment for C# and ASP.NET applications, offering a wide range of class libraries and APIs that can be used in development. It also provides services like memory management, security, and exception handling.
Can I use C# for web development without ASP.NET?
While C# is primarily used with ASP.NET for web development, it’s possible to use C# for web development without ASP.NET. There are other frameworks, like Nancy and ServiceStack, that allow for web development with C#.
What is MVC in ASP.NET?
MVC stands for Model-View-Controller. It’s a design pattern that separates an application into three main components: the Model (which represents the data and business logic), the View (which displays the data), and the Controller (which handles user input). ASP.NET MVC is a framework that implements the MVC pattern, providing a clean separation of concerns and making it easier to manage complexity in large applications.
How can I improve my C# and ASP.NET skills?
Practice is key to improving your C# and ASP.NET skills. Work on projects that challenge you and force you to learn new concepts and techniques. Participate in coding challenges on platforms like HackerRank and LeetCode. Read documentation, follow tutorials, and take online courses. Join developer communities, participate in discussions, and don’t hesitate to ask for help when you’re stuck.

