

Key Takeaways
- Shadow DOM provides encapsulation for widgets, allowing developers to manage their own data and restrict access to it, preventing CSS and JavaScript collisions. It achieves this by keeping functional subtrees separate from the document tree, a separation known as the shadow boundary.
- Any element in the document tree can host one or more shadow DOM subtrees, known as shadow hosts. The shadow DOM subtrees and document tree are rendered as a single tree, but when a shadow host is encountered, the browser disregards its document subtree and instead renders the node’s shadow DOM subtree.
- ShadowRoot objects provide many common DOM-related functions for accessing their shadow DOM subtree, and a ShadowRoot object can allow CSS rules to cross the shadow boundary via the “applyAuthorStyles” Boolean property. However, Shadow DOM is currently only supported as an experimental feature in Chrome.
Modern websites often contain data and widgets from multiple sources, mashed up on a single page. For example, a single site can easily contain a YouTube video player, a Facebook “Like” button, a Twitter “Tweet” button, and much more. The fact that code from so many vendors can coexist on a single page is nothing short of a small miracle. And, while current implementations work, they are far from ideal. For example, adding a “Like” button to a page requires the use of a clunky <iframe> tag. There is not currently an elegant way of providing encapsulation for these widgets.
Encapsulation is a feature of object-oriented programming languages which allows objects to manage their own data, and restrict access to it. Under this paradigm, an object exposes an interface to the outside world which can be used to interact with its data. By maintaining this interface, an object can stop third-party code from arbitrarily wiping out its private data. Unfortunately for web developers, HTML doesn’t offer such an interface yet. CSS and JavaScript collisions are a source of constant concern for library and widget developers. Encapsulation would allow developers to write their code and know that it will work properly, even in the presence of other scripts and stylesheets. The W3C is addressing this problem with the shadow DOM specification, currently under development.
Shadow DOM Subtrees
The DOM tree is made up of numerous functional subtrees ― one or more DOM nodes which implement a certain functionality. For example, the “Like” button functionality is implemented by one collection of nodes, while the “Tweet” button is implemented by another collection. The goal of the shadow DOM is to provide functional encapsulation for these subtrees. This is achieved by keeping functional subtrees separate from the document tree (and each other). This separation of shadow DOM subtrees is known as the shadow boundary. CSS rules and DOM queries do not cross the shadow boundary, and thus provide encapsulation.
Any element in the document tree is capable of hosting one or more shadow DOM subtrees. Nodes that host shadow DOM subtrees are known as shadow hosts. However, because the shadow DOM subtrees do not interact with the normal document tree, it is possible for a node to be a shadow host and still have child nodes in the document tree.
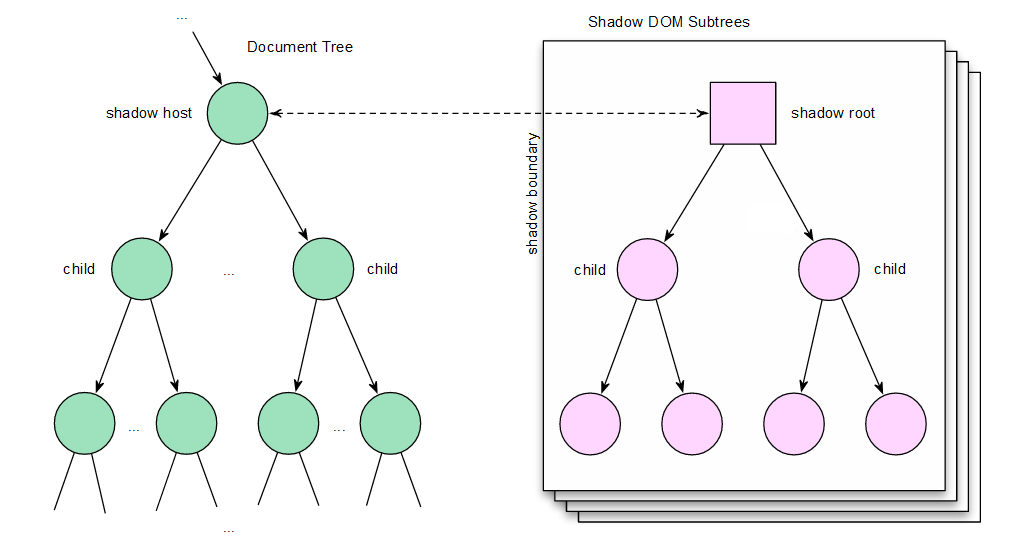
Figure 1, taken from the W3C specification, illustrates the concept of shadow DOM subtrees. The green nodes on the left represent the typical document tree. One of the DOM nodes is labeled as a shadow host. The dashed arrow coming out of this node crosses the shadow boundary and references several shadow DOM subtrees. At the root of each shadow DOM subtree is a shadow root (represented by the square node in the figure). The shadow root is a special document fragment DOM node type which encapsulates its children from the outside world. The children of the shadow root, however, are just standard DOM nodes.
Rendering the Shadow DOM
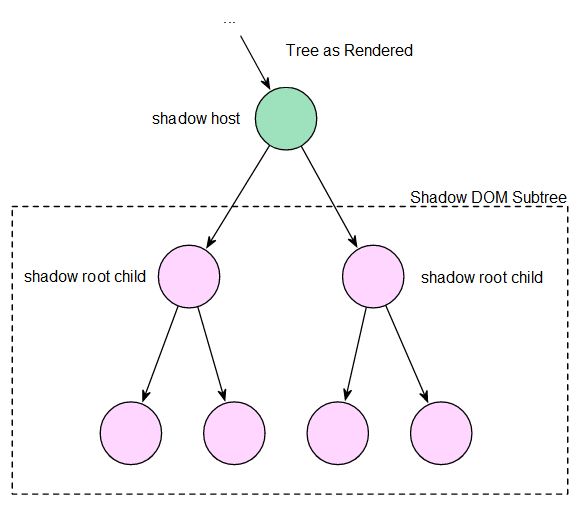
When a page is rendered, the document tree and shadow DOM subtrees are rendered as a single tree. The document tree is rendered as it normally would be. However, when a shadow host is encountered, the browser disregards its document subtree and instead renders the node’s shadow DOM subtree. Figure 2 illustrates this concept. Note that while the shadow host is rendered, the shadow root node is not.
Enabling the Shadow DOM
While the shadow DOM is a hot topic, it is currently only supported as an experimental feature in Chrome. To enable the shadow DOM in Chrome, first navigate to the URL “chrome://flags”. Next, locate the “Enable Shadow DOM” option, and click “Enable”. The option is shown below in Figure 3. Finally, Chrome will restart itself. At this point, you can begin to write pages that utilize the shadow DOM.

A Shadow DOM Example
This section explores an example shadow DOM page. The page’s HTML source is shown below. The body of the page contains a <div> element which will be used as a shadow host. Inside of the <div> is a child <span> node which clearly states that it is not part of the shadow DOM. When the page finishes loading, an event handler attaches a shadow DOM subtree to the shadow host. The shadow DOM subtree is created by instantiating a new WebKitShadowRoot object (the WebKit prefix will presumably be dropped once the shadow DOM is fully supported). The shadow host is passed as the only parameter to the ShadowRoot constructor. Next, a <span> element named “shadowChild” is added to the shadow DOM subtree. The text content of “shadowChild” indicates that it is part of the shadow DOM.
<!DOCTYPE html>
<html lang="en">
<head>
<title>Shadow DOM Example</title>
<meta charset="UTF-8" />
<style>
span {
color: red;
}
#shadowHost {
border: 1px solid black;
}
</style>
<script>
window.addEventListener("load", function() {
var shadowHost = document.getElementById("shadowHost");
var shadowRoot = new WebKitShadowRoot(shadowHost);
var shadowChild = document.createElement("span");
shadowChild.textContent = "This is part of the shadow DOM";
shadowRoot.appendChild(shadowChild);
}, false);
</script>
</head>
<body>
<div id="shadowHost">
<span id="child">This is not part of the shadow DOM</span>
</div>
</body>
</html>
The example page, as displayed by Chrome 20, is shown in Figure 4. There are several things worth noting about the page. First, the shadow DOM <span> is rendered instead of the document tree <span>. Although the document tree <span> is not displayed, it is still accessible via script. The second thing to note is that the shadow <span> is not colored red according to the CSS rule for <span> elements. This indicates that the shadow DOM is, in fact, encapsulated from the document tree.

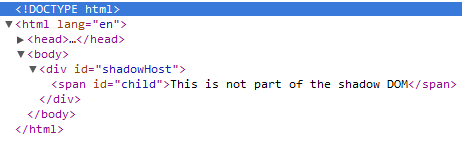
Figure 5 shows the document tree displayed by Chrome’s element inspector. The document tree does not reflect any part of the shadow DOM. Browsers that do not support the shadow DOM would render this tree instead.
ShadowRoot DOM Methods
Because shadow DOM nodes are encapsulated from the document tree, normal DOM-related methods like getElementById() cannot be used to access them. However, ShadowRoot objects provide many of the same functions for accessing their shadow DOM subtree. For example, ShadowRoot objects support the following common DOM query methods.
- getElementById()
- getElementsByClassName()
- getElementsByTagName()
- getElementsByTagNameNS()
- querySelector()
- querySelectorAll()
The ShadowRoot object also supports the “innerHTML” property for convenience. As with the normal DOM, the shadow DOM “innerHTML” can be both read and written. An example usage is shown below.
shadowRoot.innerHTML = "<span>innerHTML generated content</span>";
CSS Across the Shadow Boundary
By default, CSS rules defined outside of the shadow root are not applied to shadow DOM nodes. However, a ShadowRoot object can allow CSS rules to cross the shadow boundary via the “applyAuthorStyles” Boolean property. Setting this property to true overrides the default behavior. An example usage is shown below. In the previous example page, this would cause the shadow DOM <span> to be colored red.
shadowRoot.applyAuthorStyles = true;
Things to Remember
- The shadow DOM provides functional encapsulation to web developers.
- Shadow hosts are elements that support shadow DOM subtrees.
- The root node of a shadow DOM subtree is called a shadow root.
- Shadow DOM subtrees replace document tree subtrees during rendering.
- The ShadowRoot object provides many common DOM related functions.
Frequently Asked Questions about Shadow DOM
What is the main difference between Shadow DOM and regular DOM?
The Shadow DOM is a web standard that developers use to encapsulate their JavaScript code and CSS. This means that the code inside a Shadow DOM is separate from the main document tree, which is the regular DOM. This encapsulation allows for better code organization and prevents conflicts between styles and scripts. On the other hand, the regular DOM is the main document tree that represents the objects in the HTML of a webpage. It does not provide the encapsulation features of the Shadow DOM.
How does Shadow DOM improve performance?
Shadow DOM improves performance by isolating CSS and JavaScript. This isolation prevents the entire page from re-rendering when changes are made to a component. Only the component with changes is re-rendered, which can significantly improve the performance of web applications with many components.
Can I use Shadow DOM with any JavaScript library or framework?
Yes, you can use Shadow DOM with any JavaScript library or framework that supports it. This includes popular libraries and frameworks like React, Angular, and Vue.js. However, the implementation may vary depending on the library or framework.
What is the difference between open and closed Shadow DOM?
An open Shadow DOM allows you to access the shadow root and its children using JavaScript methods like getElementById or querySelector. A closed Shadow DOM, on the other hand, does not allow access to the shadow root or its children from outside the shadow root.
How can I style a Shadow DOM?
You can style a Shadow DOM using CSS just like you would style a regular DOM. However, styles defined inside a Shadow DOM do not leak out to the main document, and styles defined in the main document do not reach into a Shadow DOM. This encapsulation of styles is one of the main features of Shadow DOM.
Can I use Shadow DOM in all browsers?
Shadow DOM is a web standard and is supported by most modern browsers. However, it may not be supported in older browsers or some versions of Internet Explorer.
How does Shadow DOM help in building web components?
Shadow DOM provides encapsulation for JavaScript and CSS, which is a key feature for building web components. This encapsulation allows developers to write code that is isolated from the rest of the page, preventing conflicts and making the components reusable.
What is a shadow root?
A shadow root is the root node of a Shadow DOM. It is not part of the main document tree and can be either open or closed. You can attach a shadow root to any element using the attachShadow method.
Can I nest Shadow DOMs?
Yes, you can nest Shadow DOMs. This means you can have a Shadow DOM inside another Shadow DOM. This can be useful for creating complex components with their own encapsulated code.
How can I access elements inside a Shadow DOM?
You can access elements inside an open Shadow DOM using standard JavaScript methods like getElementById or querySelector. However, these methods will not work with a closed Shadow DOM. To access elements inside a closed Shadow DOM, you need to use methods provided by the element that hosts the Shadow DOM.

