

In this multi-part series, I’ll walk you through how I set up an on-premise machine learning pipeline with open-source tools and frameworks.
Key Takeaways
- Utilizing on-premise Kubernetes allows for greater control and customization of machine learning pipelines, essential for startups with limited budgets.
- Rancher Kubernetes Engine simplifies the installation of Kubernetes, making it more accessible for those with basic Docker and Linux experience.
- On-premise setups can avoid unexpected costs associated with cloud services, providing a predictable budgeting benefit.
- The series provides a practical approach to building and managing machine learning pipelines using open-source tools, ideal for those new to the field.
- Setting up Kubernetes on-premise involves preparing machines, installing Docker, and configuring network settings before deploying the cluster.
- By the end of the setup, users will have a functional Kubernetes cluster managed via Rancher, ready for deploying machine learning models.
Prologue: Model Training is Just A Tiny Part
When most people think about machine learning, they imagine engineers and data scientists tweaking network architectures, loss functions, and tuning hyper-parameters, coupled with the constant retraining until the results are satisfactory.
Indeed, training machine learning models takes a lot of hard work. A tremendous amount of time and resources are expended on research and experimentation.
However, there comes a point in time when you need to start to productionize the model that you’ve lovingly trained and tuned. And oh, by the way, the model is expected to perform as well on next weeks’ batch of data.
It slowly dawns on you that Machine Learning is much bigger than models, hyper-parameters, and loss functions. It’s also what happens before, during, and after training. And it doesn’t end there, because you would also need to think about re-training, especially when you get new data, since there’s no guarantee that the model is going to generalize as well.
There’s a very well known diagram that succinctly illustrates the issue:
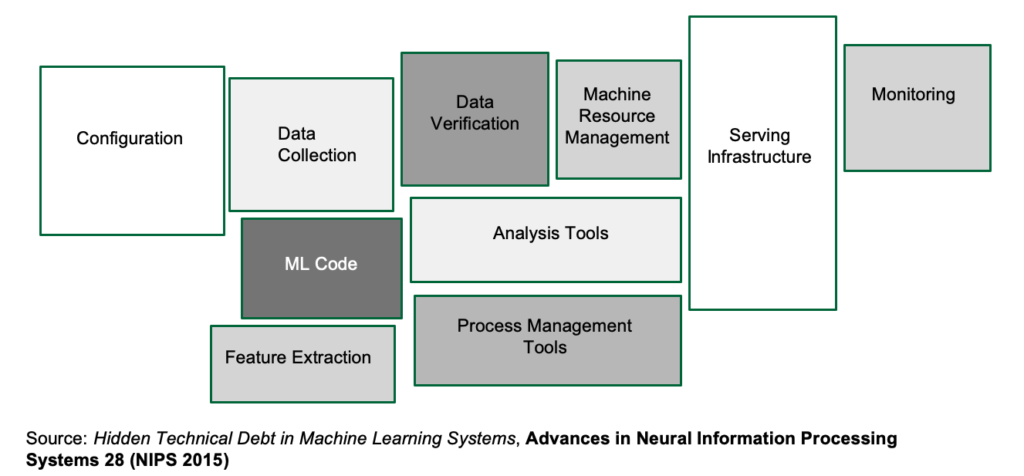
In short, you need to build a machine learning pipeline that can get you from raw data to the trained model in the shortest possible time. But here’s the catch: because you’re part of a scrappy startup and not flushed with VC money, you’re going to have to make do with the servers you have, and not rely on the paid cloud offerings of Amazon, Microsoft or Google, at least for the time being.
This is because you need a safe environment to learn and experiment in — one that won’t unexpectedly shock you with a nasty bill at the end of the month.
Who You Are
You could be a software engineer at a company that’s starting to think about putting its machine learning models to production, or you could be running solo and curious about what “real-world” machine learning looks like. In both cases, you would need to know about machine learning pipelines.
What You Need to Know
You should be comfortable with Linux. The examples will assume Ubuntu Linux 18.04, though slightly dated or more recent versions shouldn’t cause any major issues.
You should have some working knowledge of Docker. If you know how to build images in Docker, and how to execute containers, you should be good to go. If you don’t, you shouldn’t worry too much: I’ll guide you with enough background information, and code examples will be explained.
While this is an article about Machine Learning pipelines, this article is not about the intricacies involved in training a model.
We’re going to use Kubernetes. You don’t need to be an expert in it. If you are completely new to Kubernetes, that’s OK. By the end of the series, you’ll have at least some hands-on experience. On the other hand, I’m not going to go very deep into Kubernetes specifics. Some commands I’ll have to gloss over in the interests of brevity. Besides, the real objective here to help you deploy machine learning pipelines as efficiently as possible.
Here are some other assumptions that I’m making about you, the astute reader:
- you’re not entirely clueless about Machine Learning
- you have access to some relatively beefy servers (ideally more than one) that contain Nvidia GPUs
- you have an existing machine learning code base that’s written in Python
- you don’t work in a unicorn startup or Fortune 500 and therefore are not so flush with cash that you can happily spin up multiple V100s.
What Are We Going to Do?
Machine learning pipelines only recently have gotten more love and attention, and people are just only beginning to figure everything out. Put in another way, there are multiple ways to build machine learning pipelines, because every organization has unique requirements, and every team has their favorite tool.
What this series aims to offer is one possible way to do it, and that’s especially important when you’re starting out, because the amount of information is often very overwhelming. Also, installing Kubernetes is a daunting affair, littered with many roadblocks. I hope this article helps with smoothening that path.
After you’ve learned a way to build a machine learning pipeline, you’ll then be equipped with enough skills and knowledge to go build one to suit your organization’s needs.
Here’s a list of some of the tools I’ll cover in this series:
- Docker
- Kubernetes
- Rancher
- KubeFlow/KubeFlow Pipelines
- Minio
- Tensorflow
On On-premise
As you’ll realize soon as you follow through the series, many of these tools assume that you have storage on Amazon S3 or Google Cloud Storage, which, to put it mildly, not a very good assumption. Thus this series shows how to work around some of these limitations without losing any of the functionality.
Of course, at some point in time, you’ll outgrow and would need something more capable. However, especially when you’re starting (that is, you happen to be the first Data Engineer on the team), then on-premise would seem a more cost-effective and ultimately the more educational choice.
Installing Kubernetes the Easy Way with Rancher
Let’s start immediately with one of the harder bits — Installing Kubernetes.
The main thing you need to know about Kubernetes is that it’s a container-orchestration system for automating application deployment, scaling, and management.
There are many ways to install Kubernetes, and it’s not a trivial process. Fortunately, that’s tools like Rancher make the installation process much more pleasant and less error-prone. In particular, we’re going to use the Rancher Kubernetes Engine (RKE) to help us install Kubernetes.
At the point of this writing, the latest stable release of rke is 1.0.0.
Step 0: Prepare the Machines
The following steps assume that you have access to two Linux machines that are connected to the same LAN.
We’re going to set up a minimal cluster consisting of two machines, one named master and the other worker. Of course, you can name your machines whatever you want, as long as you designate one machine to be master, and the rest to be workers.
If you only have access to one machine, you can get by with creating two virtual machines, and make sure to enable Bridged Adapter. In fact, in preparation for this article, I’m testing everything out of Oracle’s VirtualBox. Here are my settings:
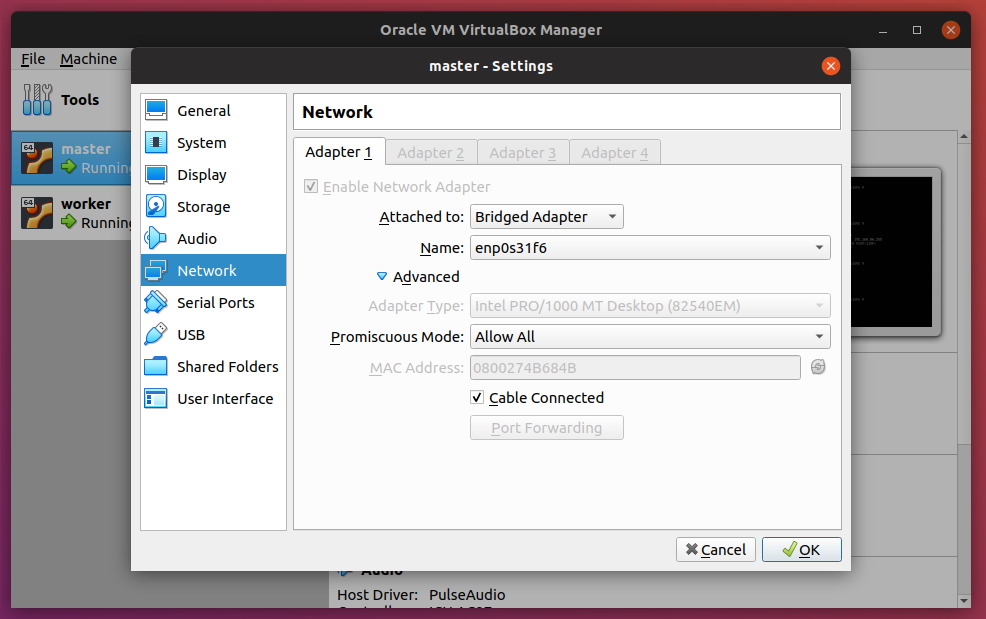
Notice here that I have two VMs: master and node. Enable the Bridged Adapter and also setting Promiscuous Mode to Allow All.
The downside to that is that you wouldn’t be able to access the GPUs, and you would most likely notice that the performance won’t be ideal because Kubernetes tends to be quite demanding in terms of resources. Again, that’s OK if you’re trying this at home or have only access to a single machine at the moment.
Here are some important details about the machines (you should have them on hand too for the configuration steps that follow):
| Master | Worker | |
|---|---|---|
| IP | 192.168.86.36 | 192.168.86.35 |
| User | ubuntu | ubuntu |
| Hostname | master | worker |
| SSH Keys | ~/.ssh/id_rsa.pub |
~/.ssh/id_rsa.pub |
| Role | Control Plane, Etcd | Worker |
DNS and Load Balancing
In a production environment, you would need a hostname to point to your Kubernetes cluster. However, in this article I’m assuming you don’t have one readily available, so we’re going to have to fake it.
Another thing I won’t cover — to keep things simple — is load balancing when it comes to the Rancher installation.
For our purposes, I’m going to use rancher-demo.domain.test as the hostname.
In both machines, open /etc/hosts file:
sudo vim /etc/hosts
Enter the following:
192.168.86.35 worker
192.168.86.35 rancher-demo.domain.test
192.168.86.36 master
127.0.0.1 localhost
Notice here that the worker node has the additional hostname of rancher-demo.domain.test. In a slightly more realistic environment, you’d have something like NGINX as a front-end to load balance between multiple worker nodes.
*Note: If you’re using a Virtual Machine, then most likely you’d be using the Ubuntu Server image, which typically doesn’t come with a desktop environment. Therefore, you should also have an entry in the host computer to include this:
192.168.86.35 rancher-demo.domain.test
That way, you’ll be able to access Rancher from a browser on the host computer.*
Step 1: Obtain the rke Binary
Important!: This step should only be performed on master.
Head over to the GitHub page to download the rke binary. Next, rename the binary to rke, followed by making it executable. Finally, move the binary to a location in the PATH, where /usr/local/bin is usually a good choice.
Important: make sure you select the right binary for your OS!
$ wget https://github.com/rancher/rke/releases/download/v1.0.0/rke_linux-amd64
$ mv rke_linux-amd64 rke
$ chmod +x rke
$ sudo mv rke /usr/local/bin
Now let’s see if everything works:
$ rke
This should return:
NAME:
rke - Rancher Kubernetes Engine, an extremely simple, lightning fast Kubernetes installer that works everywhere
USAGE:
rke [global options] command [command options] [arguments...]
VERSION:
v1.0.0
AUTHOR(S):
Rancher Labs, Inc.
COMMANDS:
up Bring the cluster up
remove Teardown the cluster and clean cluster nodes
version Show cluster Kubernetes version
config Setup cluster configuration
etcd etcd snapshot save/restore operations in k8s cluster
cert Certificates management for RKE cluster
encrypt Manage cluster encryption provider keys
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
--debug, -d Debug logging
--quiet, -q Quiet mode, disables logging and only critical output will be printed
--help, -h show help
--version, -v print the version
Step 2. Preparing the Linux Hosts
Important: these steps are to be performed on all of the machines.
a) Install Docker
First, make sure that Docker 19.03 is installed on all the Linux hosts:
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
$ sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable edge"
$ sudo apt-get update
$ sudo apt-get install -y docker-ce
To make sure that the Docker service is running correctly, execute the following:
$ sudo systemctl status docker
This should return:
● docker.service - Docker Application Container Engine
Loaded: loaded (/lib/systemd/system/docker.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2019-12-28 03:01:03 UTC; 27s ago
Docs: https://docs.docker.com
Main PID: 4118 (dockerd)
Tasks: 8
CGroup: /system.slice/docker.service
└─4118 /usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock
Dec 28 03:01:03 master dockerd[4118]: time="2019-12-28T03:01:03.179311453Z" level=warning msg="Your kernel does not support swap memory limit"
Dec 28 03:01:03 master dockerd[4118]: time="2019-12-28T03:01:03.179509363Z" level=warning msg="Your kernel does not support cgroup rt period"
Dec 28 03:01:03 master dockerd[4118]: time="2019-12-28T03:01:03.179608175Z" level=warning msg="Your kernel does not support cgroup rt runtime"
Now execute the following command so that you can use the docker command without sudo:
$ sudo usermod -aG docker $USER
Let’s try it out:
$ docker run hello-world
Whoops!
docker: Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Post http://%2Fvar%2Frun%2Fdocker.sock/v1.40/containers/create: dial unix /var/run/docker.sock: connect: permission denied.
See 'docker run --help'.
The reason you are getting this is that you need to log out first:
$ exit
Once you’re logged in, try again:
$ docker run hello-world
You should see this:
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
1b930d010525: Pull complete
Digest: sha256:4fe721ccc2e8dc7362278a29dc660d833570ec2682f4e4194f4ee23e415e1064
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
b) Set up SSH keys
In case you haven’t had SSH keys set up, perform the following step on master:
$ ssh-keygen
$ eval "$(ssh-agent -s)"
$ ssh-add ~/.ssh/id_rsa
Then, copy the public key to all the worker nodes. Since we only have one worker node:
$ ssh-copy-id ubuntu@192.168.86.36
You need to make sure that $USER can SSH into the nodes. For example, make sure you can access worker from master:
ubuntu@master:~$ ssh ubuntu@192.168.86.36
On both nodes, configure the SSH server to allow port-forwarding:
% sudo vim /etc/ssh/sshd_config
Uncomment the following:
AllowTcpForwarding yes
c) Turn swap off
To turn off swap:
$ sudo swapoff -a
Open /etc/fstab in your favorite editor and comment out the swap file entry :
$ sudo vim /etc/fstab
d) Apply sysctl settings
$ sudo sysctl net.bridge.bridge-nf-call-iptables=1
e) DNS on Ubuntu 18.04
In this version of Ubuntu onwards, the way DNS is set up has changed. To revert to the previous behavior:
$ sudo apt install resolvconf
Edit the nameserver settings:
sudo vim /etc/resolvconf/resolv.conf.d/head
Add the following entries:
nameserver 8.8.4.4
nameserver 8.8.8.8
Restart the resolveconf service:
% sudo service resolvconf restart
Step 3: Creating the Cluster Configuration File
Important: the following step should only be performed on master.
It’s time to finally install Kubernetes with rke!
Before doing this, make sure that you have a list of IPs and hostnames for the nodes. The table from Step 0 would be very helpful for this step.
You’ll need to run rke config to create a cluster configuration file. It will present you with a bunch of questions that are used to generate the configuration file:
$ rke config
Here’s an example of the questions and answers based on the table. Remember to adapt it to your users, hostnames, IP addresses, and SSH key locations. Also note that the master node should have the role of control plane and etcd, while the worker nodes should have the role of worker. If you ever make a mistake, you can always start over with Ctrl + C and running the command again:
[+] Cluster Level SSH Private Key Path [~/.ssh/id_rsa]:
[+] Number of Hosts [1]: 2
[+] SSH Address of host (1) [none]: 192.168.86.36
[+] SSH Port of host (1) [22]:
[+] SSH Private Key Path of host (192.168.86.36) [none]: ~/.ssh/id_rsa
[+] SSH User of host (192.168.86.36) [ubuntu]: ubuntu
[+] Is host (192.168.86.36) a Control Plane host (y/n)? [y]: y
[+] Is host (192.168.86.36) a Worker host (y/n)? [n]: n
[+] Is host (192.168.86.36) an etcd host (y/n)? [n]: y
[+] Override Hostname of host (192.168.86.36) [none]: master
[+] Internal IP of host (192.168.86.36) [none]:
[+] Docker socket path on host (192.168.86.36) [/var/run/docker.sock]:
[+] SSH Address of host (2) [none]: 192.168.86.35
[+] SSH Port of host (2) [22]:
[+] SSH Private Key Path of host (192.168.86.35) [none]: ~/.ssh/id_rsa
[+] SSH User of host (192.168.86.35) [ubuntu]: ubuntu
[+] Is host (192.168.86.35) a Control Plane host (y/n)? [y]: n
[+] Is host (192.168.86.35) a Worker host (y/n)? [n]: y
[+] Is host (192.168.86.35) an etcd host (y/n)? [n]: n
[+] Override Hostname of host (192.168.86.35) [none]: worker
[+] Internal IP of host (192.168.86.35) [none]:
[+] Docker socket path on host (192.168.86.35) [/var/run/docker.sock]:
[+] Network Plugin Type (flannel, calico, weave, canal) [canal]: flannel
[+] Authentication Strategy [x509]:
[+] Authorization Mode (rbac, none) [rbac]:
[+] Kubernetes Docker image [rancher/hyperkube:v1.16.3-rancher1]:
[+] Cluster domain [cluster.local]:
[+] Service Cluster IP Range [10.43.0.0/16]:
[+] Enable PodSecurityPolicy [n]:
[+] Cluster Network CIDR [10.42.0.0/16]:
[+] Cluster DNS Service IP [10.43.0.10]:
[+] Add addon manifest URLs or YAML files [no]:
This generates cluster.yml, the RKE cluster configuration file:
nodes:
- address: "192.168.86.36"
port: "22"
internal_address: ""
role:
- controlplane
- etcd
hostname_override: ""
user: ubuntu
docker_socket: /var/run/docker.sock
ssh_key: ""
ssh_key_path: ~/.ssh/id_rsa
ssh_cert: ""
ssh_cert_path: ""
labels: {}
taints: []
- address: "192.168.86.35"
port: "22"
internal_address: ""
role:
- worker
hostname_override: ""
user: ubuntu
docker_socket: /var/run/docker.sock
ssh_key: ""
ssh_key_path: ~/.ssh/id_rsa
ssh_cert: ""
ssh_cert_path: ""
labels: {}
taints: []
services:
etcd:
image: ""
extra_args: {}
extra_binds: []
extra_env: []
external_urls: []
ca_cert: ""
cert: ""
key: ""
path: ""
uid: 0
gid: 0
snapshot: null
retention: ""
creation: ""
backup_config: null
kube-api:
image: ""
extra_args: {}
extra_binds: []
extra_env: []
service_cluster_ip_range: 10.43.0.0/16
service_node_port_range: ""
pod_security_policy: false
always_pull_images: false
secrets_encryption_config: null
audit_log: null
admission_configuration: null
event_rate_limit: null
kube-controller:
image: ""
extra_args: {}
extra_binds: []
extra_env: []
cluster_cidr: 10.42.0.0/16
service_cluster_ip_range: 10.43.0.0/16
scheduler:
image: ""
extra_args: {}
extra_binds: []
extra_env: []
kubelet:
image: ""
extra_args: {}
extra_binds: []
extra_env: []
cluster_domain: cluster.local
infra_container_image: ""
cluster_dns_server: 10.43.0.10
fail_swap_on: false
generate_serving_certificate: false
kubeproxy:
image: ""
extra_args: {}
extra_binds: []
extra_env: []
network:
plugin: flannel
options: {}
node_selector: {}
authentication:
strategy: x509
sans: []
webhook: null
addons: ""
addons_include: []
system_images:
etcd: rancher/coreos-etcd:v3.3.15-rancher1
alpine: rancher/rke-tools:v0.1.51
nginx_proxy: rancher/rke-tools:v0.1.51
cert_downloader: rancher/rke-tools:v0.1.51
kubernetes_services_sidecar: rancher/rke-tools:v0.1.51
kubedns: rancher/k8s-dns-kube-dns:1.15.0
dnsmasq: rancher/k8s-dns-dnsmasq-nanny:1.15.0
kubedns_sidecar: rancher/k8s-dns-sidecar:1.15.0
kubedns_autoscaler: rancher/cluster-proportional-autoscaler:1.7.1
coredns: rancher/coredns-coredns:1.6.2
coredns_autoscaler: rancher/cluster-proportional-autoscaler:1.7.1
kubernetes: rancher/hyperkube:v1.16.3-rancher1
flannel: rancher/coreos-flannel:v0.11.0-rancher1
flannel_cni: rancher/flannel-cni:v0.3.0-rancher5
calico_node: rancher/calico-node:v3.8.1
calico_cni: rancher/calico-cni:v3.8.1
calico_controllers: rancher/calico-kube-controllers:v3.8.1
calico_ctl: ""
calico_flexvol: rancher/calico-pod2daemon-flexvol:v3.8.1
canal_node: rancher/calico-node:v3.8.1
canal_cni: rancher/calico-cni:v3.8.1
canal_flannel: rancher/coreos-flannel:v0.11.0
canal_flexvol: rancher/calico-pod2daemon-flexvol:v3.8.1
weave_node: weaveworks/weave-kube:2.5.2
weave_cni: weaveworks/weave-npc:2.5.2
pod_infra_container: rancher/pause:3.1
ingress: rancher/nginx-ingress-controller:nginx-0.25.1-rancher1
ingress_backend: rancher/nginx-ingress-controller-defaultbackend:1.5-rancher1
metrics_server: rancher/metrics-server:v0.3.4
windows_pod_infra_container: rancher/kubelet-pause:v0.1.3
ssh_key_path: ~/.ssh/id_rsa
ssh_cert_path: ""
ssh_agent_auth: false
authorization:
mode: rbac
options: {}
ignore_docker_version: false
kubernetes_version: ""
private_registries: []
ingress:
provider: ""
options: {}
node_selector: {}
extra_args: {}
dns_policy: ""
extra_envs: []
extra_volumes: []
extra_volume_mounts: []
cluster_name: ""
cloud_provider:
name: ""
prefix_path: ""
addon_job_timeout: 0
bastion_host:
address: ""
port: ""
user: ""
ssh_key: ""
ssh_key_path: ""
ssh_cert: ""
ssh_cert_path: ""
monitoring:
provider: ""
options: {}
node_selector: {}
restore:
restore: false
snapshot_name: ""
dns: null
Time to bring the cluster up!
% rke up
Wait as rke sets up the Kubernetes cluster:
INFO[0000] Running RKE version: v1.0.0
INFO[0000] Initiating Kubernetes cluster
INFO[0000] [certificates] Generating admin certificates and kubeconfig
INFO[0000] Successfully Deployed state file at [./cluster.rkestate]
INFO[0000] Building Kubernetes cluster
INFO[0000] [dialer] Setup tunnel for host [192.168.86.35]
INFO[0000] [dialer] Setup tunnel for host [192.168.86.36]
# Many more lines ...
INFO[0044] Finished building Kubernetes cluster successfully
A few more files would have been created at this point:
$ ls
cluster.rkestate cluster.yml kube_config_cluster.yml
You should keep these files in a safe location if ever you need to recreate the cluster. You’ll need to copy kube_config_cluster.yml to a location where Kubernetes can find it:
$ mkdir ~/.kube
$ cp kube_config_cluster.yml $HOME/.kube/config
Install Kubectl
Note: this step should only be done on the master node.
Next, you should install the Kubernetes command-line tool, kubectl:
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" | sudo tee -a /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubectl
Once this step is completed, we can test it out by listing all the nodes that rke created:
% kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.86.35 Ready worker 53m v1.16.3
192.168.86.36 Ready controlplane,etcd 53m v1.16.3
Success! Let’s do something else. We can inspect what containers were created:
% kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
ingress-nginx default-http-backend-67cf578fc4-dk9l4 1/1 Running 0 49m
ingress-nginx nginx-ingress-controller-bnwlv 1/1 Running 0 49m
kube-system coredns-5c59fd465f-7gbff 1/1 Running 0 49m
kube-system coredns-5c59fd465f-mhzdb 1/1 Running 0 49m
kube-system coredns-autoscaler-d765c8497-p2zj4 1/1 Running 0 49m
kube-system kube-flannel-vkxc6 2/2 Running 0 54m
kube-system kube-flannel-xjtst 2/2 Running 0 54m
kube-system metrics-server-64f6dffb84-hs99g 1/1 Running 0 49m
kube-system rke-coredns-addon-deploy-job-kdwxm 0/1 Completed 0 49m
kube-system rke-ingress-controller-deploy-job-rpvrq 0/1 Completed 0 49m
kube-system rke-metrics-addon-deploy-job-x2m2j 0/1 Completed 0 49m
kube-system rke-network-plugin-deploy-job-h5ffz 0/1 Completed 0 55m
Don’t worry about what pods are at this point. Just think of them as containers for now.
Install Helm 3
Note: this step should only be done on the master node.
Helm is a Kubernetes package manager and is very handy for deploying applications and services onto Kubernetes clusters. We’ll use Helm to install Rancher and some other supporting services.
$ curl https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 | bash
helm should be installed into the PATH:
Downloading https://get.helm.sh/helm-v3.0.2-linux-amd64.tar.gz
Preparing to install helm into /usr/local/bin
helm installed into /usr/local/bin/helm
Install Rancher Using Helm
Note: This step should only be done on the master node.
$ helm repo add rancher-stable https://releases.rancher.com/server-charts/stable
Create a namespace for Rancher:
$ kubectl create namespace cattle-system
Install cert-manager
Note: this step should only be done on the master node.
Cert Manager helps with automatically provisioning and managing TLS certificates in Kubernetes. There are options to use certificates from Let’s Encrypt for example, but for now, we shall keep things simple and use the default certificates generated by Rancher.
Note: here we are installing a slightly outdated version of cert-manager because the latest one (0.12) seems to have installation issues.
Follow these steps to install cert-manager onto the Kubernetes cluster:
$ kubectl apply -f https://raw.githubusercontent.com/jetstack/cert-manager/release-0.9/deploy/manifests/00-crds.yaml
$ kubectl create namespace cert-manager
$ kubectl label namespace cert-manager certmanager.k8s.io/disable-validation=true
$ helm repo add jetstack https://charts.jetstack.io
$ helm repo update
$ helm install --name cert-manager \
--namespace cert-manager \
--version v0.9.1 \
jetstack/cert-manager
Check that everything went well:
kubectl get pods --namespace cert-manager
NAME READY STATUS RESTARTS AGE
cert-manager-5b9ff77b7-x6vgn 1/1 Running 0 44s
cert-manager-cainjector-59d69b9b-nrgkf 1/1 Running 0 44s
cert-manager-webhook-cfd6587ff-8tcgt 1/1 Running 0 44s
Note that you might have to wait for some time (usually just a few minutes) for all the STATUS to turn to Running.
Install Rancher
Finally, you can install Rancher, which, among other things, provides a nice interface to manage your Kubernetes cluster(s):
$ helm install rancher rancher-stable/rancher \
--namespace cattle-system \
--set hostname=rancher.example.com
Check that everything went well:
kubectl -n cattle-system rollout status deploy/rancher
Waiting for deployment "rancher" rollout to finish: 0 of 3 updated replicas are available...
Wait till all the replicates have been updated before performing the next step.
Now, since we don’t have a load balancer, we need to perform an additional step to be able to access the Rancher UI. Create the following file an name it ingress.yml and fill it with the following (adapt the host to whatever you have picked):
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: rancher-demo-ingress
spec:
rules:
- host: rancher-demo.domain.test
http:
paths:
- path: /
backend:
serviceName: rancher-demo
servicePort: 443
Then run:
$ kubectl apply -f ingress.yml
After that, Rancher should available at:
https://rancher-demo.domain.test
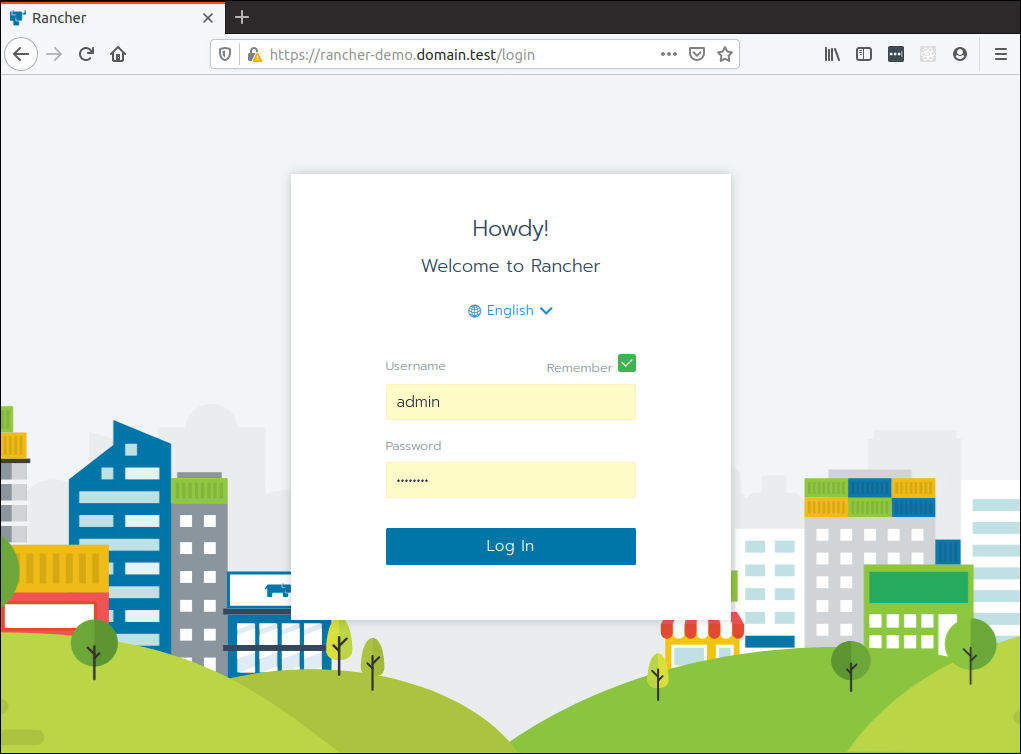
Accept the security exception your browser might complain about and you should be greeted with the following screen with a prompt to create a password and set the domain name (already pre-filled). Go ahead and do that:
Give Rancher a few moments to set things up. Once done, you should get an overview of your cluster:
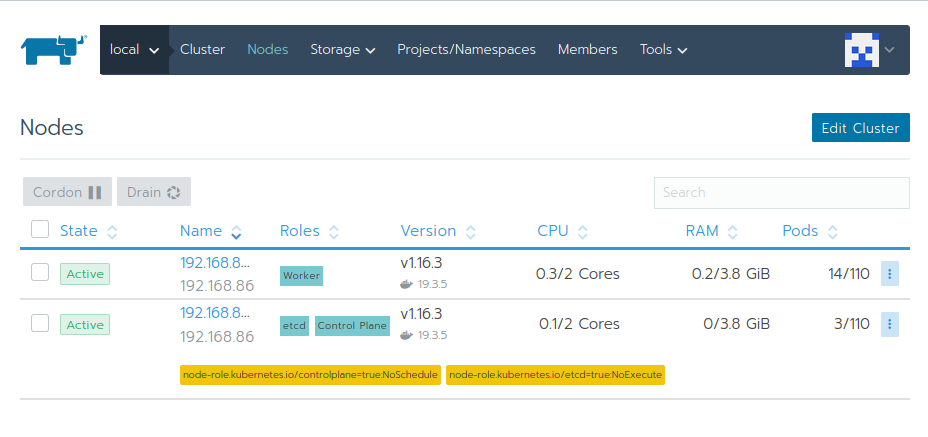
Go ahead and click around and revel in the fruits of your labor!
Summary
If you’ve reached this stage, you should congratulate yourself on persevering. Installing a Kubernetes cluster isn’t for the faint of heart, even with tools like Rancher to somewhat ease the process.
Let’s review what we’ve done.
We went through why training ML models are just the tip of the proverbial iceberg, and that a lot of other supporting software needs to come together to put these models into production.
More importantly, we set up a non-trivial Kubernetes cluster with the Rancher Kubernetes Engine and installed Rancher to manage the cluster. This is no mean feat. However, we still haven’t done any machine learning deployment yet! That will be the next article in the series, where we install Kubeflow, an open-source machine learning platform.
Credits
Special thanks go to Sebastiaan van Steenis‘s article that showed how to set up an RKE cluster without a load balancer.
Frequently Asked Questions (FAQs) about Setting Up On-Premise Kubernetes
What are the key benefits of setting up Kubernetes on-premise?
Setting up Kubernetes on-premise offers several benefits. Firstly, it provides full control over your infrastructure, allowing you to customize and manage your resources according to your specific needs. Secondly, it ensures data security and privacy as all data remains within your organization’s network, reducing the risk of data breaches. Lastly, it can be more cost-effective in the long run, especially for larger organizations with substantial data processing needs, as it eliminates the need for ongoing cloud service fees.
How does on-premise Kubernetes compare to cloud-based Kubernetes?
On-premise Kubernetes and cloud-based Kubernetes each have their own strengths. On-premise Kubernetes offers greater control, security, and potentially lower costs for large-scale operations. On the other hand, cloud-based Kubernetes provides scalability, flexibility, and ease of setup. The choice between the two depends on your organization’s specific needs and resources.
What are the challenges of setting up Kubernetes on-premise?
Setting up Kubernetes on-premise can be challenging due to the need for in-house expertise to manage and maintain the infrastructure. It also requires significant upfront investment in hardware and software. Additionally, unlike cloud-based services, on-premise Kubernetes does not automatically scale, so capacity planning is crucial.
How can I ensure the security of my on-premise Kubernetes setup?
Ensuring the security of your on-premise Kubernetes setup involves several steps. These include configuring network policies to control traffic flow, implementing role-based access control (RBAC) to manage user permissions, regularly updating and patching your system to protect against vulnerabilities, and monitoring your system for any unusual activity.
Can I migrate from a cloud-based Kubernetes setup to an on-premise one?
Yes, it is possible to migrate from a cloud-based Kubernetes setup to an on-premise one. This process involves exporting your current configuration, setting up your on-premise infrastructure, and then importing your configuration. However, this can be a complex process and may require the assistance of a Kubernetes expert.
What hardware do I need to set up Kubernetes on-premise?
The hardware requirements for setting up Kubernetes on-premise depend on your specific needs. However, at a minimum, you will need a server or servers with sufficient CPU, memory, and storage capacity to handle your workloads. You will also need a network infrastructure that can support the communication between your Kubernetes nodes.
How can I scale my on-premise Kubernetes setup?
Scaling an on-premise Kubernetes setup involves adding more nodes to your cluster. This can be done manually or by using a cluster autoscaler. However, keep in mind that unlike cloud-based services, on-premise Kubernetes does not automatically scale, so capacity planning is crucial.
What is the role of a Kubernetes operator in an on-premise setup?
A Kubernetes operator is a method of packaging, deploying, and managing a Kubernetes application. In an on-premise setup, the operator can automate many of the tasks involved in managing your Kubernetes cluster, making it easier to maintain and update your system.
Can I use Kubernetes on-premise for machine learning workloads?
Yes, Kubernetes on-premise can be used for machine learning workloads. Kubernetes provides a flexible and scalable platform for running machine learning workloads, and setting it up on-premise can provide the added benefits of control, security, and potentially lower costs.
How can I monitor the performance of my on-premise Kubernetes setup?
Monitoring the performance of your on-premise Kubernetes setup can be done using various tools such as Prometheus for metrics collection, Grafana for data visualization, and Alertmanager for alerting. These tools can provide insights into your system’s performance and help you identify and resolve any issues.