
The FDA (Food and Drug Administration) is an agency of the United States Department of Health and Human Services. It is responsible for protecting and promoting public health through the regulation and supervision of food safety, tobacco products, dietary supplements, prescription and over-the-counter pharmaceutical drugs (medications), vaccines, biopharmaceuticals, blood transfusions, medical devices, electromagnetic radiation emitting devices (ERED), cosmetics, animal foods & feed[5] and veterinary products. exhales
The FDA provides a compressed data file of the Drugs@FDA database, which includes information on the drugs approved by the FDA. All fields in the data files are separated by tab delimiters. While the official online Drugs@FDA application is updated daily, the data file in the link above is updated once per week, usually on Wednesdays.
The Issue…
You may be asking: “Why are you telling me this?” Good question.
To make the issue clear, the first thing I want you to do is download the database drugsfda.zip (1.7 MB), and unzip the file. When you unzip the file, you will notice 9 text files (tables), as shown in the figure below:
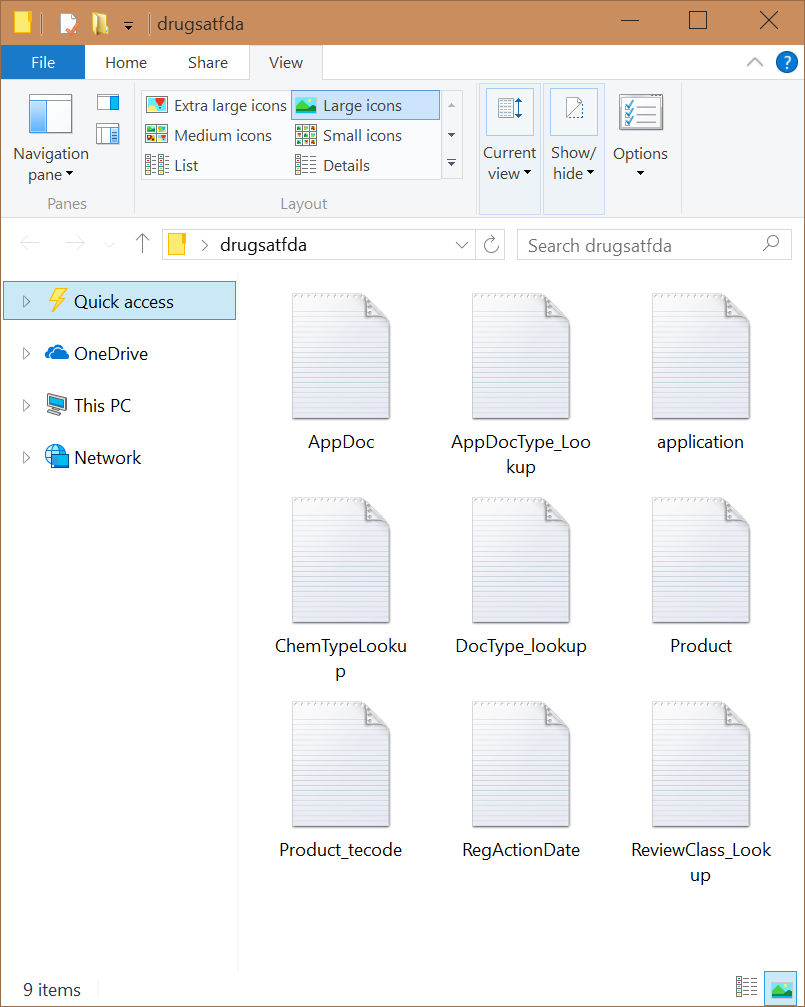
From the title of this article, you’ve probably surmised that we’re going to figure out how to make content changes to all of these files simultaneously. That’s why I like you, you are a surmiser.
Say that you decide to replace the word drug with medication in one of the FDA files. This is simple, and, of course, there are advanced forms of search and substitution. In fact, I mention a couple of these methods in the article about hunting for the gene sequence.
If we had only one file, that would be straightforward. However, in our case, we have 9 text files we want to search and alter. Obviously, the word drug occurs in more than one text file. In fact, it occurs in the following files:
- AppDoc
- application
- ChemTypeLookup
- Product
How Can Ruby Help?
Since this series is related to Ruby, let’s solve this using the “Ruby Way”.
They key is to put the list of files in our directory in an array. After that, open each file, read through it, make the desired substitution, and close the file.
In order to do those steps, we’ll leverage the Dir class. An example on the use of the class is:
Dir['C:/Users/Abder-Rahman/Desktop/drugsatfda/*.txt']
=> ["C:/Users/Abder-Rahman/Desktop/drugsatfda/AppDoc.txt", "C:/Users/Abder-Rahman/Desktop/drugsatfda/AppDocType_Lookup.txt", "C:/Users/Abder-Rahman/Desktop/drugsatfda/application.txt", "C:/Users/Abder-Rahman/Desktop/drugsatfda/ChemTypeLookup.txt", "C:/Users/Abder-Rahman/Desktop/drugsatfda/DocType_lookup.txt", "C:/Users/Abder-Rahman/Desktop/drugsatfda/Product.txt", "C:/Users/Abder-Rahman/Desktop/drugsatfda/Product_tecode.txt", "C:/Users/Abder-Rahman/Desktop/drugsatfda/RegActionDate.txt", "C:/Users/Abder-Rahman/Desktop/drugsatfda/ReviewClass_Lookup.txt"]Dir returns an array of string that are he file names matching the *.txt glob pattern
With the file names of interest in hand, it’s time to read the contents of each file in the directory. In Ruby, a file can be read using IO.read, which will read the file and return its contents:
IO.read("C:/Users/Abder-Rahman/Desktop/drugsatfda/AppDoc.txt")
=>...[contents of the file]...Having read the file, let’s make the desired substitutions. Here, we are interested in substituting medication for every instance of drugs. A Ruby function that comes in handy is gsub, which substitutes all the occurences of the first argument by the second argument. The first argument is typically a regular expression, but can be a simple string.
For instance, for the above substitution, we can write the following:
file_content.gsub!(/drugs/,'medication')where file_content is a variable that holds the content of a file read in with IO.read.
We must be careful here, though. In the provided text files , drugs may ber written in uppercase in some text files and lowercase in others. It may be capitalized in some places, as well. In order to substitute all the occurences of drugs with medication in a case insensitive manner, write the above substitution statements as follows:
file_content.gsub!(/drugs/i,'medication')Putting it All Together
At this point, let’s see how our Ruby script looks. The script will go through all the text files in the drugsatfda directory, search for the word drugs in each file, and substitute drugs with medication:
files = Dir['C:/Users/Abder-Rahman/Desktop/drugsatfda/*.txt']
files.each do |filename|
file_content = IO.read(filename)
file_content.gsub!(/drugs/i,'medication')
output = File.open(filename,'w')
output.write(file_content)
output.close
end
exitAs you can see, once the file has been read and the substitutions made, the text file is saved with the new content through writing a file with the same name. Finally, the file needs to be closed.
Final Thoughts Before Running the Program
The program above had no issues when I ran it on the Windows 8.1 operating system. I however had an issue, specifically with the file AppDoc.txt, when trying to run the program on both Ubuntu 15.04 and MAC OS X Yosemite operating systems. If you are using one of the latter systems, you might get the following error:
program.rb:4:ingsub!’: invalid byte sequence in UTF-8 (ArgumentError)
In order to solve this issue, based on this thread, you can simply insert the following code after the second line (also remove the fourth line) in the original program above:
if ! file_content.valid_encoding?
file_content = file_content.encode('UTF-16be', :invalid=>:replace, :replace=>'?').encode('UTF-8')
file_content.gsub!(/drugs/i,'medication')
end
file_content.gsub!(/drugs/i,'medication')Another thought is that if you look inside AppDoc.txt , you will notice that drugs is part of a URL, and changing that may result in invalid web links in the document. So, we want to tell our program to replace drugs whenever it appears, in all its forms (i.e. Drug, drug, DRUG, dRuG, …etc), except those in a URL. This can be a little tricky, and regular expressions play a significant role in solving such an issue. Based on the appearance of drugs in the URL, we can write the following to substitute drugs with medication, in any form and location, except within a URL:
file_content.gsub!(/(?<!http:\/\/www\.)(?<!http:\/\/www\.accessdata.fda.gov.)[Dd]rugs/i, 'medication')An updated version of the program now looks as follows:
files = Dir['C:/Users/Abder-Rahman/Desktop/drugsatfda/*.txt']
files.each do |filename|
file_content = IO.read(filename)
if ! file_content.valid_encoding?
file_content = file_content.encode('UTF-16be', :invalid=>:replace, :replace=>'?').encode('UTF-8')
file_content.gsub!(/(?<!http:\/\/www\.)(?<!http:\/\/www\.accessdata.fda.gov.)[Dd]rugs/i, 'medication')
end
file_content.gsub!(/(?<!http:\/\/www\.)(?<!http:\/\/www\.accessdata.fda.gov.)[Dd]rugs/i, 'medication')
output = File.open(filename,'w')
output.write(file_content)
output.close
end
exitRunning the Program
I have named the Ruby script substitute.rb. I ran the script on a Windows OS, using Command Prompt With Ruby, as follows:
application.txt contained the following:
HETERO DRUGS LTDAfter running the script, it now looks like:
HETERO medication LTDConclusion
Sometimes, it’s necessary to replace a specific string with another across multiple files. This can be further complicated by files that are very large in size. Doing such a task manually is tedious and time consuming. Ruby, again, proves its ability to make developers happy with quick, intuitive language that handles our task easily.
Happy Rubying!
 Abder-Rahman Ali
Abder-Rahman AliDoctor and author focussed on leveraging machine/deep learning and image processing in medical image analysis.



