Keep up to date on current trends and technologies
Web

Don’t Choose the Wrong Web Team — Here’s Why It Matters
Jerry Zhang
Droip Review: Why You Should Choose Droip Over Traditional WordPress Page Builders in 2025
SitePoint Sponsors
5 Best Payment Gateways for SaaS: Your Ultimate Guide
SitePoint Sponsors

How OpenTelemetry Improved Its Code Integrity for Arm64 by Working With Ampere
Scott M. Fulton, III

Cost Effective Reseller Platforms for Buying SSL Certificates
SitePoint Sponsors

Angular Signals: A New Mental Model for Reactivity, Not Just a New API
Sonu Kapoor

The Developer’s Shortcut To Your Udemy-like Platform
SitePoint Sponsors

Best Crypto Payment Gateway for High Risk
NOWPayments

Why WordPress Scalability Starts with Smart Site Structure from Day One
Fred Morpeth

Best Crypto Payments Gateways in 2025
NOWPayments

The Ampere Porting Advisor Tutorial
Dave Neary
Why Your Automation Needs AI Decision-Making (And How Wordware Delivers)
SitePoint Sponsors

CNCF Triggers a Platform Parity Breakthrough for Arm64 and x86
Scott M. Fulton, III

Benefits of Custom Telecommunication Software
SitePoint Sponsors

5+ WordPress Plugins for Developers To Use in 2025
SitePoint Sponsors

Top 21 Developer Newsletters to Subscribe To in 2025
Anna Hrechka

Serverless Image Processing Pipeline with AWS ECS and Lambda
Raju Dandigam

CNCF Arm64 Pilot: Impact and Insights
Craig Hardy

Building a Multi-Tenant SaaS Application with Next.js (Backend Integration)
Juliet Ofoegbu

Building a Network Vulnerability Scanner with Go
Rez Moss

14 Best SEO Tools for Agencies to Boost Client Results in 2025
SitePoint Sponsors

The Best Free Backlink Checker Tools: Overview and Comparison
SitePoint Sponsors

Prompt Engineering for Web Development
Kevin Leary

Meeting European Accessibility Act (EAA) Standards: A Developer’s Checklist
Ran Ronen

10 Common Web Development Mistakes to Avoid Right Now
James Fox

What Is Cloud Computing?
Dianne Pena

ZEISS Demonstrates the Power of Scalable Workflows with Ampere Altra and SpinKube
Scott M. Fulton, III
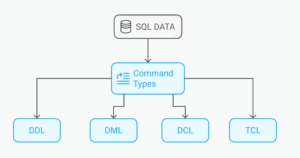
SQL Commands: The List of Basic SQL Language Commands
Dianne Pena
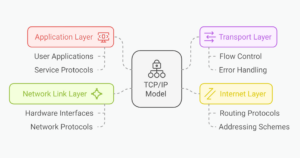
What is TCP/IP Model and How Does The Protocol Work
Dianne Pena
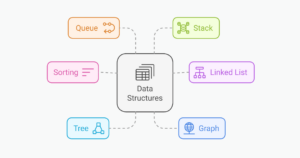
Data Structures and Algorithms (DSA): A Complete Tutorial
Dianne Pena
How Game Developers Detect and Prevent Modding and Scripting
SitePoint Sponsors

How to Conduct Accessibility Testing with Screen Readers
Ran Ronen
Showing 32 of 1548