

In this tutorial, we’re going to see how we can deploy serverless functions alongside our front-end application and create an API that generates images and grabs metadata from links.
With serverless functions, developers can create and implement modern features and functionalities in their applications without going through the pain of setting up and managing back-end servers. The functions are hosted and deployed by cloud computing companies.
Netlify functions make creating and deploying serverless functions easy for applications hosted on Netlify.
Key Takeaways
- Utilize Puppeteer and Netlify Functions to build a serverless link previewer that fetches metadata and screenshots from URLs.
- Start by setting up a Vue 3 application with Tailwind CSS for styling, ensuring a modern and responsive design.
- Implement Netlify Functions to handle backend processes like API creation without managing servers, enhancing scalability and ease of deployment.
- Use Puppeteer within Netlify Functions to automate browser tasks, such as capturing screenshots and extracting metadata from web pages.
- Deploy the application on Netlify, leveraging continuous deployment from Git repositories for streamlined updates and maintenance.
- Enhance user experience by incorporating a Vue component that interacts with the serverless function to display link previews dynamically on the frontend.
Prerequisites
To follow along with this tutorial, you’ll need to be familiar with JavaScript, Vue.js, Git, GitHub, and Netlify. You should also have a text editor — such as VS Code) with Vetur installed (for IntelliSense) — and a recent version of Node installed on your machine. You can install Node here. You can check your version of Node by running the command node -vin your terminal.
You should also have an account on Netlify. You can create one if you haven’t already.
What We’re Building
To show how we can easily set up serverless functions with our front-end application, we’ll be building an app with a custom link previewer component.
This component sends a request with a URL to our serverless function. The function then uses Puppeteer to get metadata from the target site using the URL and to generate a screenshot of the site.
The function sends the metadata and screenshots back to the component on our front-end to display it as a link preview in the application.
Here’s the link to the example project deployed on Netlify. And here’s the GitHub Repo to follow along.
Create and Set Up the Vue Application
We’re going to create a Vue 3 application using Vue CLI. We’ll also install and set up Tailwind CSS, a utility-first CSS framework that provides classes we can use for our app without having to write a lot of custom CSS.
Install and set up Vue
To quickly scaffold a Vue application, we’ll use Vue CLI. To install Vue CLI, run:
npm install -g @vue/cli
Once the CLI has been installed, we can create a project by running:
vue create link-previewer
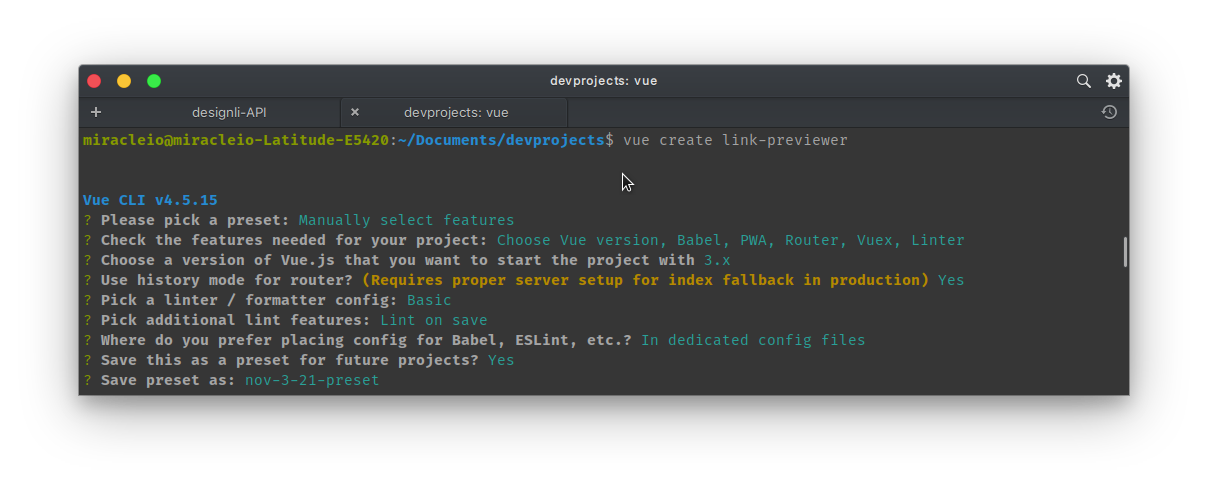
This will prompt us to pick a preset for our installation. We’ll select “Manually select features” so that we can pick the features we need. Here are the options I selected:
Please pick a preset: Manually select features
? Check the features needed for your project: Choose Vue version, Babel, PWA, Router, Vuex, Linter
? Choose a version of Vue.js that you want to start the project with: 3.x
? Use history mode for router? (Requires proper server setup for index fallback in production) Yes
? Pick a linter / formatter config: Basic
? Pick additional lint features: Lint on save
? Where do you prefer placing config for Babel, ESLint, etc.? In dedicated config files
After selecting these options, we’ll be asked if we want to save the options as a preset for later use. Select Y (yes) or N (no) and continue with the installation.
Run cd link-previewer to enter the newly created project.
Install and set up Tailwind CSS
To install Tailwind, we’ll use the PostCSS 7 compatibility build, since Tailwind depends on PostCSS 8 — which at the time of writing is not yet supported by Vue 3. Uninstall any previous Tailwind installation and re-install the compatibility build:
npm uninstall tailwindcss postcss autoprefixer
npm install -D tailwindcss@npm:@tailwindcss/postcss7-compat postcss@^7 autoprefixer@^9
Create the Tailwind configuration files
Next, generate tailwind.config.js and postcss.config.js files:
npx tailwindcss init -p
This will create a minimal tailwind.config.js file at the root of the project.
Configure Tailwind to remove unused styles in production
In the tailwind.config.js file, configure the purge option with the paths to all of the pages and components so Tailwind can tree-shake unused styles in production builds:
// ./tailwind.config.js
module.exports = {
purge: ['./index.html', './src/**/*.{vue,js,ts,jsx,tsx}'],
...
}
Include Tailwind in the CSS file
Create the ./src/assets/css/main.css file and use the @tailwind directive to include Tailwind’s base, components, and utilities styles:
/* ./src/assets/css/main.css */
@tailwind base;
@tailwind components;
@tailwind utilities;
body{
@apply bg-gray-50;
}
Tailwind will swap these directives out at build time with all of the styles it generates based on the configured design system.
Finally, ensure the CSS file is being imported in the ./src/main.js file:
// ./src/main.js
import { createApp } from 'vue'
import App from './App.vue'
import './registerServiceWorker'
import router from './router'
import store from './store'
import './assets/css/main.css'
createApp(App).use(store).use(router).mount('#app')
And that’s it, we can run our server:
npm run serve
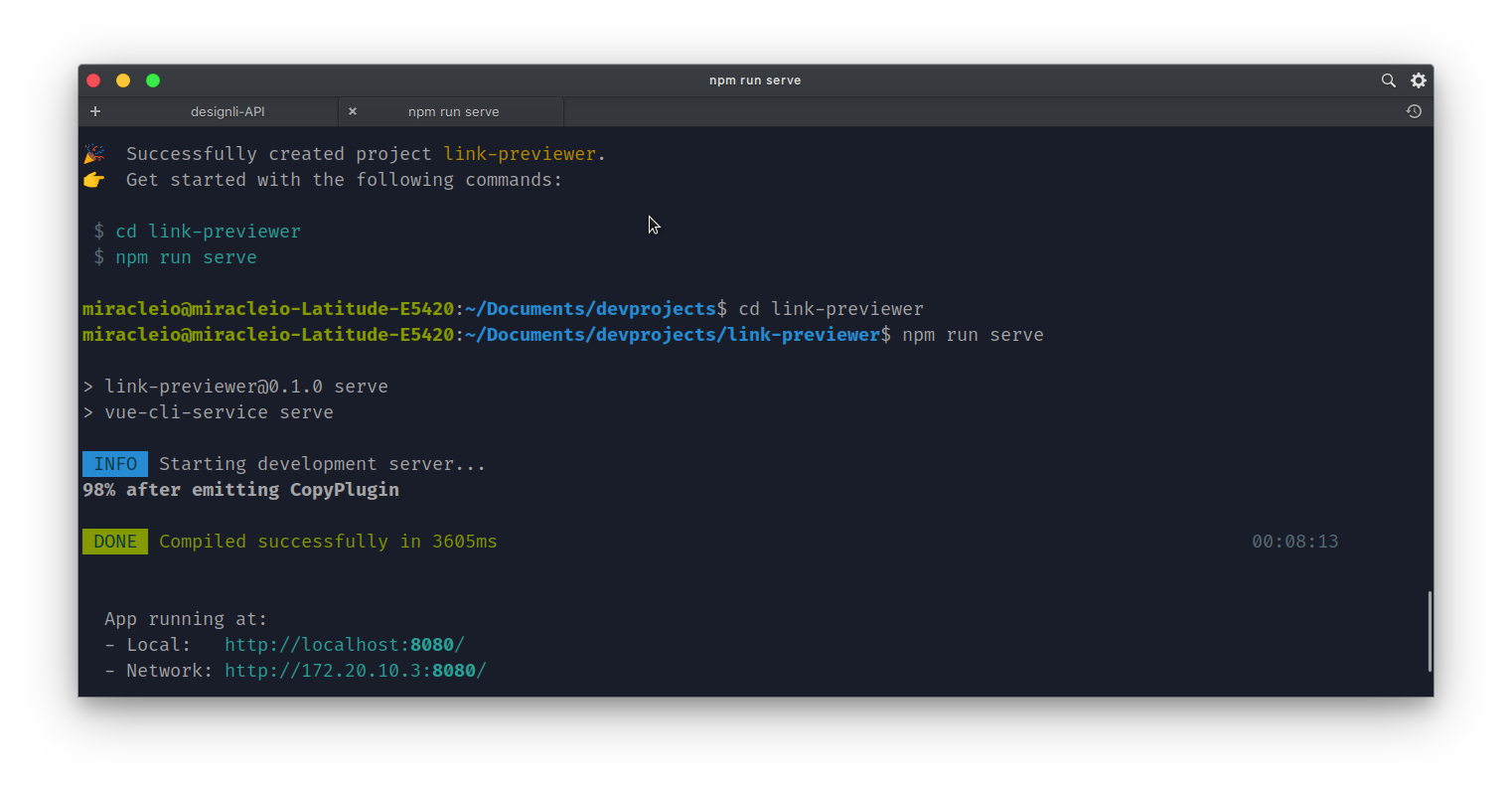
Now that the app is running, if we go to the URL provided, we should see the default demo app for Vue and see that Tailwind’s preflight base styles have been applied.
Install Tailwind CSS IntelliSense extension
For a smoother development experience, install the Tailwind CSS Intellisense extension for VS Code.
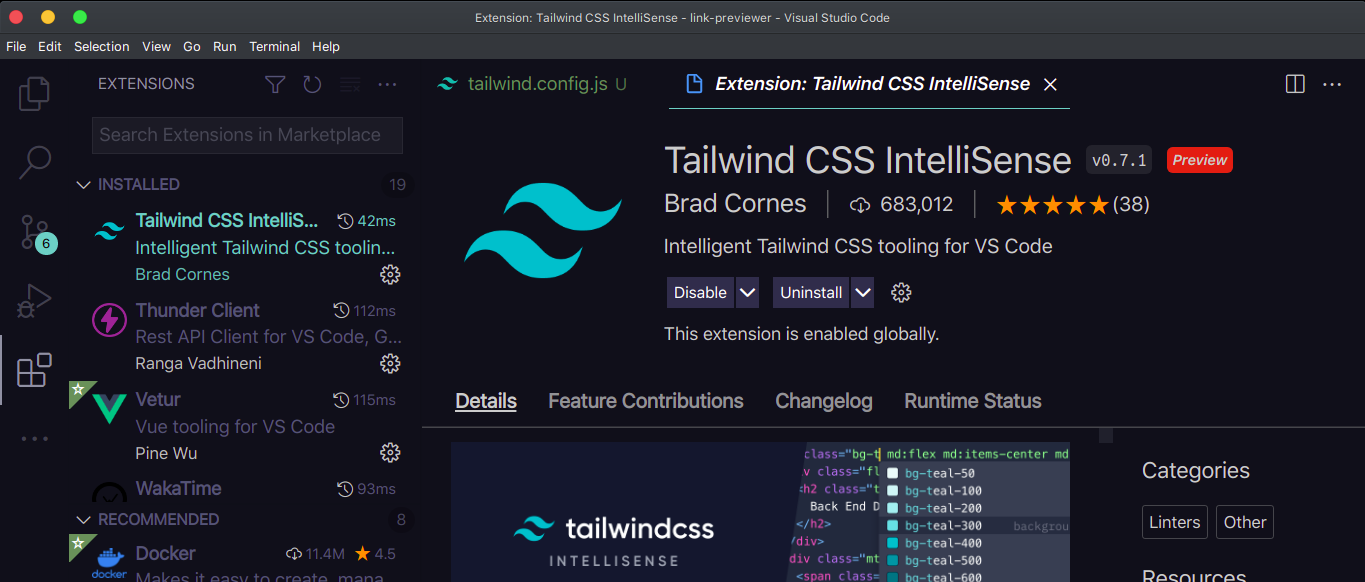
Basic app structure
Here’s an overview of what our project folder should look like:
link-previewer/
├─ functions/
│ ├─ generate-preview.js
│ └─ hello.js
├─ public/
│ ├─ favicon.ico
│ ├─ img/
│ │ └─ icons/
│ ├─ index.html
│ └─ robots.txt
├─ src/
│ ├─ main.js
│ ├─ App.vue
│ ├─ registerServiceWorker.js
│ ├─ assets/
│ │ ├─ css/
│ │ │ └─ main.css
│ │ └─ logo.png
│ ├─ components/
│ │ └─ LinkPreviewer.vue
│ ├─ router/
│ │ └─ index.js
│ ├─ store/
│ │ └─ index.js
│ └─ views/
│ ├─ About.vue
│ └─ Home.vue
├─ .git
├─ .gitignore
├─ .browserslistrc
├─ .eslintrc.js
├─ babel.config.js
├─ netlify.toml
├─ package-lock.json
├─ package.json
├─ postcss.config.js
├─ README.md
└─ tailwind.config.js
A Quick Introduction to Netlify Functions
Netlify Functions is a Netlify product that simplifies the process of creating and deploying serverless functions. According to the product’s home page, it’s used to:
Deploy server-side code that works as API endpoints, runs automatically in response to events, or processes more complex jobs in the background.
A basic Netlify Function file exports a handler method with the following syntax:
exports.handler = async function(event, context){
return {
statusCode: 200,
body: JSON.stringify({message: "Hello World!"})
}
}
Netlify provides the event and context parameters when the function is called/invoked. When a function’s endpoint is called, the handler receives an event object like this:
{
"path": "Path parameter (original URL encoding)",
"httpMethod": "Incoming request’s method name",
"headers": {Incoming request headers},
"queryStringParameters": {Query string parameters},
"body": "A JSON string of the request payload",
"isBase64Encoded": "A boolean flag to indicate if the applicable request payload is Base64-encoded"
}
The context parameter, on the other hand, includes information about the context in which the function was called.
Within the function, we’re returning an object with two important properties:
statusCode, which is200in this casebody, which is a stringified object.
The function will be called from our site at /.netlify/functions/hello and on success, it would return the 200 status code and the message, “Hello, World!”.
Now that we have an idea of how Netlify functions work, let’s see them in practice.
Creating Our First Netlify Function
To create our first Netlify function, we’ll create a new file functions/hello.js in the project directory and enter the following:
// functions/hello.js
exports.handler = async function(event, context){
return {
statusCode: 200,
body: JSON.stringify({message: "Hello World!"})
}
}
Once we’ve created the function file, we have to make some necessary configurations in order for us to run our function locally.
Set up Netlify configuration
We’ll create a netlify.toml file at the root of our project folder that will tell Netlify where to find our functions:
# ./netlify.toml
[functions]
directory = "./functions"
Netlify will now locate and deploy the functions in the functions folder at build time.
Install Netlify CLI
To run our functions locally without having to deploy to Netlify, we need to install Netlify CLI. The CLI allows us to deploy our projects with some great Netlify features locally.
To install the CLI, make sure you have Node.js version 10 or later, then run:
npm install netlify-cli -g
This installs Netlify CLI globally, so we can run netlify commands from any directory. To get the version, usage, and so on, we can run:
netlify
Run the App with Netlify Dev
To run our project locally with Netlify CLI, stop the dev server (if it’s active), then run:
netlify dev
And here’s what we should see:
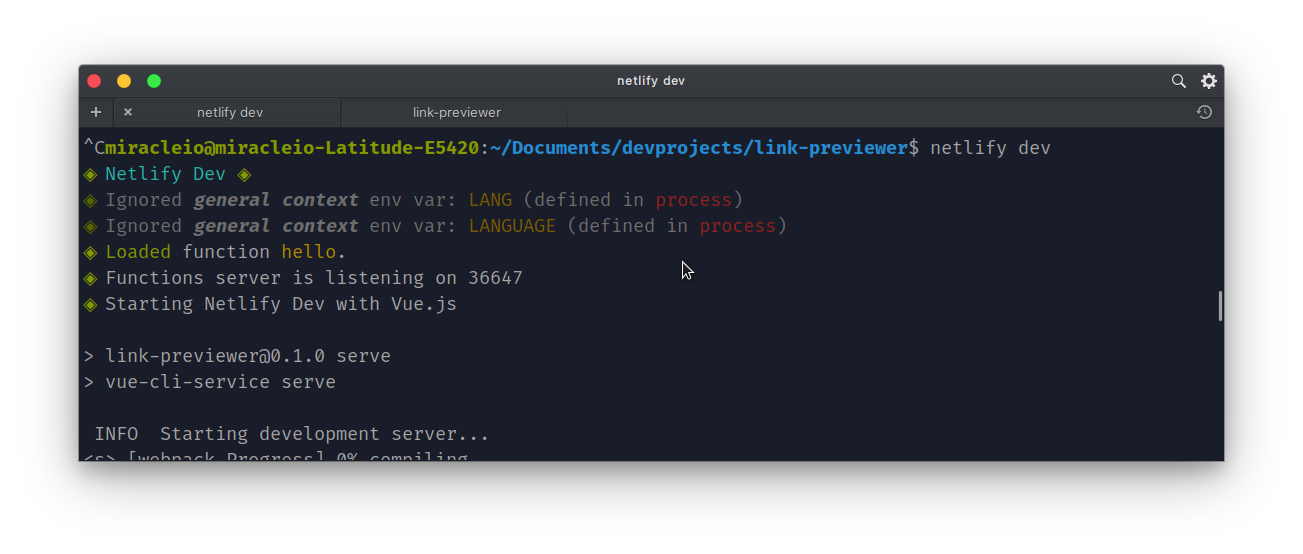
If you look closely, you’ll see a few things going on there:
-
Netlify tries to inject environment variables from our
.envfiles into the build process, which can then be accessed by our Netlify Functions. In this case, we have no.envfile, so it loads the defaults defined inprocess. -
Secondly, it loads or deploys our functions located in the functions directory. The Functions server is deployed on a different and random port —
36647. -
Lastly, it automatically detects what framework the application is built with and runs the necessary build processes to deploy the application. In this case, you can see “Starting Netlify Dev with Vue.js”. It also supports React and other popular frameworks.
Netlify then starts our development server on http://localhost:8888.
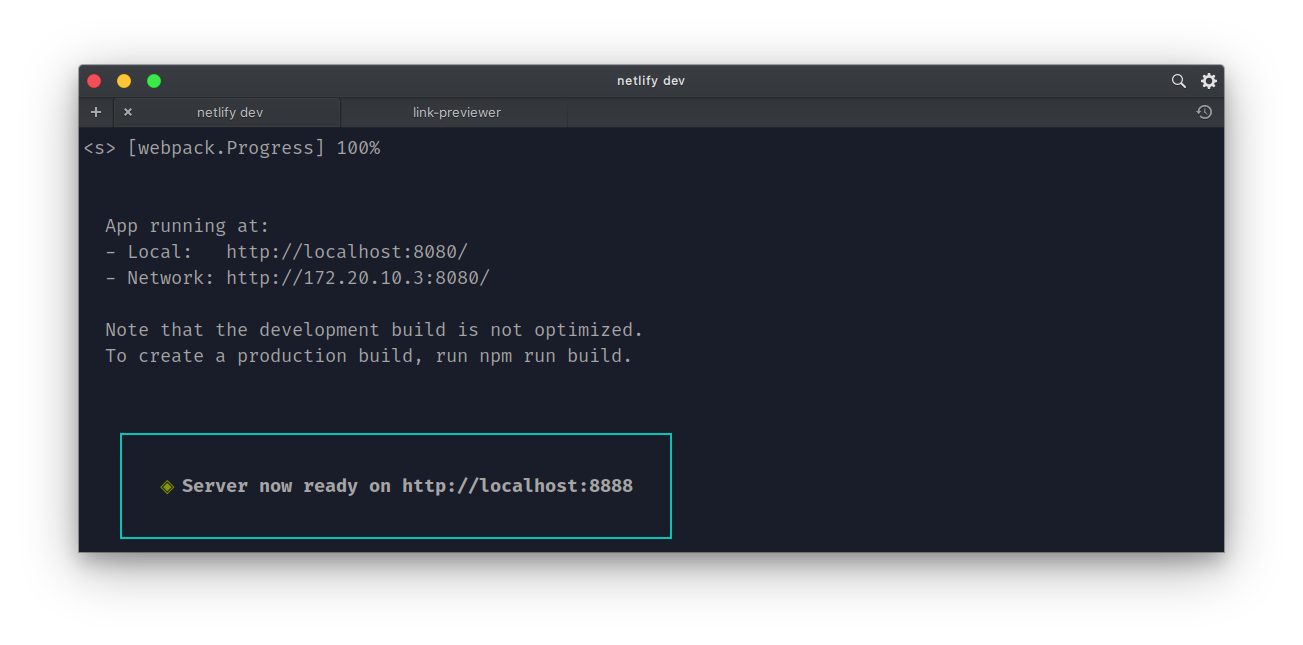
Now that our server has started and our functions arevloaded, we can call/invoke it. By default, we can access our functions using this route: /.netlify/functions/<function name>.
One important thing to note is that we don’t need to specify the port where our Functions server is running. We can use the default route above to communicate with our Functions server. Netlify automatically resolves the URL and port behind the scenes.
if we send a GET request to http://localhost:8888/.netlify/functions/hello, we should get a response of {"message":"Hello, World!"}.

Great! Our first serverless function works!
Create the Preview Function API
Now that our Netlify function works, we can begin building the preview API. Here’s a quick rundown of what our Functions API is going to do:
- it receives the target URL that will be sent from the front end
- it passes the data to Puppeteer
- Puppeteer then launches a new headless browser instance
- Puppeteer opens a new page in the browser and navigates to the target URL
- Puppeteer then extracts the content of the
<title>and<meta>tags for the description of the target page - it captures a screenshot of the page
- it sends the screenshot data back to the front end
Now that we have a basic idea of what our Functions API is going to do, we can start creating Functions. Let’s start by installing and setting up Puppeteer for Netlify Functions.
Install and configure Puppeteer
Puppeteer is a Node library that provides a high-level API to control headless Chrome or Chromium browsers. It can also be configured to use the full (non-headless) chrome or Chromium. You can do most things that you can do manually in the browser using Puppeteer. More about Puppeteer can be found in the Puppeteer documentation.
To get started with Puppeteer, we’ll install it in our project.
Puppeteer for local development and production
Puppeteer downloads a recent version of Chromium (~170MB macOS, ~282MB Linux, ~280MB Windows) that’s guaranteed to work with the API.
We can’t use the full puppeteer package for production. This is because Netlify Functions has a maximum size of 50MB, and the Chromium package is too large.
Thanks to this very useful article by Ire Aderinokun, we can still work with Puppeteer both locally and in production. Here’s what we have to do:
Install puppeteer as a development dependency* for local deployment:
npm i puppeteer --save-dev
For Puppeteer to work both locally and in production, we have to install puppeteer-core and chrome-aws-lambda as production dependencies.
You can check out the difference between puppeteer and puppeteer-core here. The main difference, though, is that puppeteer-core doesn’t automatically download Chromium when installed.
Since puppeteer-core doesn’t download a browser, we’ll install chrome-aws-lambda, a “Chromium Binary for AWS Lambda and Google Cloud Functions” which we can use in our Netlify Functions. These are the packages that will work in production:
npm i puppeteer-core chrome-aws-lambda --save-prod
Now that we’ve installed our packages, let’s create our function.
Use already installed browser for Puppeteer
If Puppeteer installing a full browser to work with locally is going to be an issue, that may be due to slow network or bandwidth concerns. There’s a workaround, which is to use our already installed Chrome or Chromium browser for Puppeteer.
What we need is the path to the browser in our local machine. We’ll use this as our executablePath, which we’ll pass to the puppeteer.launch() method. This tells Puppeteer where to find the browser executable file.
If you don’t know exactly where to find the executable path, open up your browser and go to chrome://version/ to display the version of chrome.

Copy the path and create a .env file in the root of the project.
# ./.env
EXCECUTABLE_PATH=<path to chrome>
To get the content of the .env file, we’ll install another package — dotenv:
npm install dotenv
Now that we’ve successfully installed the package, let’s create the Netlify function.
Create the generate-preview function
Create a new file, ./functions/generate-preview.js:
// ./functions/generate-preview.js
const chromium = require('chrome-aws-lambda')
const puppeteer = require('puppeteer-core')
exports.handler = async function (event, context) {
// parse body of POST request to valid object and
// use object destructuring to obtain target url
const { targetURL } = JSON.parse(event.body)
// launch browser
const browser = await puppeteer.launch({
args: chromium.args,
// get path to browser
executablePath: process.env.EXCECUTABLE_PATH || await chromium.executablePath,
headless: true
})
// open new page in browser
const page = await browser.newPage()
// set the viewport of the page
await page.setViewport({
width: 768,
height: 425,
deviceScaleFactor: 1
})
// set the prefers-color-scheme to dark
await page.emulateMediaFeatures([
{name: 'prefers-color-scheme', value:'dark'}
])
// navigate to target URL and get page details and screenshot
try{
...
}
}
In the code above, we’re doing a number of things. First, we obtain the targetURL from the request payload in event.body. This would be sent with a POST request.
Next, we launch the browser using the chrome-aws-lambda package. We do this using the puppeteer.launch() method. This method takes in an object as an argument with a few optional properties. An important property we pass to this method is the executablePath.
We assign the executablePath to process.env.EXCECUTABLE_PATH || await chromium.executablePath enabling the package to locate the available headless browser to launch.
Once the browser is launched, we open a new page in the browser using the browser.newPage() method. We also set our desired browser viewport for the page using the page.setViewport() method.
Notice that we’re using the await keyword when running any function. This is because Puppeteer works asynchronously and some functions might take some time before they execute.
We can also do things like define the media features of the page with Puppeteer using the page.emulateMediaFeatures() method, which takes an array of media feature objects. That’s how we set the prefers-color-scheme to dark.
Get site meta data and screenshot
Next, we’ll navigate to the target URL and get our title, description and screenshot:
// ./functions/generate-preview.js
...
// navigate to target URL and get page details and screenshot
try {
// navigate to the targetURL
await page.goto(targetURL)
// get the title from the newly loaded page
const title = (await page.$eval(`head > title`, el => el.textContent) || null)
// get the descriptions of the page using their CSS selectors
const descriptions = await page.evaluate(() => {
let descriptions = {}
let desc = document.querySelector(`meta[name='description']`)
let og = document.querySelector(`meta[property='og:description']`)
let twitter = document.querySelector(`meta[property='twitter:description']`)
desc ? descriptions.desc = desc.content : descriptions.desc = null
og ? descriptions.og = og.content: descriptions.og = null
twitter ? descriptions.twitter = twitter.content : descriptions.twitter = null
return descriptions
})
// screenshot the page as a jpeg with a base64 encoding
const screenshot = await page.screenshot({
type: 'jpeg',
encoding: 'base64'
})
// close the browser
await browser.close()
// send the page details
return {
statusCode: 200,
body: JSON.stringify({
title,
screenshot,
descriptions
})
}
} catch (error) {
// if any error occurs, close the browser instance
// and send an error code
await browser.close()
return {
statusCode: 400,
body: JSON.stringify({
error
})
}
}
In the code above, we’re using a trycatch block to wrap our code so that, if anything goes wrong, starting from await page.goto(targetURL), which navigates to the target URL, we can catch the error and send it to our front end. An error might occur through providing an invalid URL.
If the URL was valid, we get the title using the page.$eval() method, which is similar to the usual document.querySelector method in JavaScript. We pass in the CSS selector — head > title — of the title tag as the first argument. We also pass a function el => el.textContent as the second argument, where el is a parameter we pass to the function and is the title element. We can now get the value using title.textContent.
Notice that all this is wrapped in a parentheses (()) and we have a || null after page.$eval. This is so that title is assigned null if page.$eval() fails to get the title of the page.
To get the descriptions of the page, we’ll use the page.evaluate() method, which allows us to run some client-side JavaScript and return a value to the assigned variable — descriptions.
We pass a function as and argument to the page.evaluate() method. Within the function we use document.querySelector to get the various meta descriptions, such as <meta name="description" content="<site description>" /> for the default description, and <meta property="og:description" content="<site description>" /> for the OpenGraph description.
After getting the elements, we use ternary operators to get the content and add it to the descriptions object if the elements exist, or null if the element doesn’t exist.
Once we’ve gotten the descriptions, we take a screenshot of the page using the page.screenshot() method and close the browser with browser.close().
Finally, we’re sending the page details in the body property a JSON object with a statusCode of 200. If an error occurs in any of the previous steps, it’s caught in the catch block and we send a statusCode of 400 and the error message instead.
Test and deploy function
Let’s test our function using an API tester. You can install Postman or Talend API tester in your browser or use the Thunder Client extension, an API tester for VS Code.
You can also use cURL:
curl -X POST -H "Content-Type: application/json" -d '{"paramName": "value"}' <URL>
Run the function using the netlify dev command.
We can send a request using the port for the functions server or the default :8888 port for the Netlify dev server to send a request to our functions. I’ll be using http://localhost:8888/.netlify/functions/generate-preview to send a POST request with an object containing the targetURL in the body:
{
"targetURL" : "https://miracleio.me"
}
When we send the request, here’s the response we get.
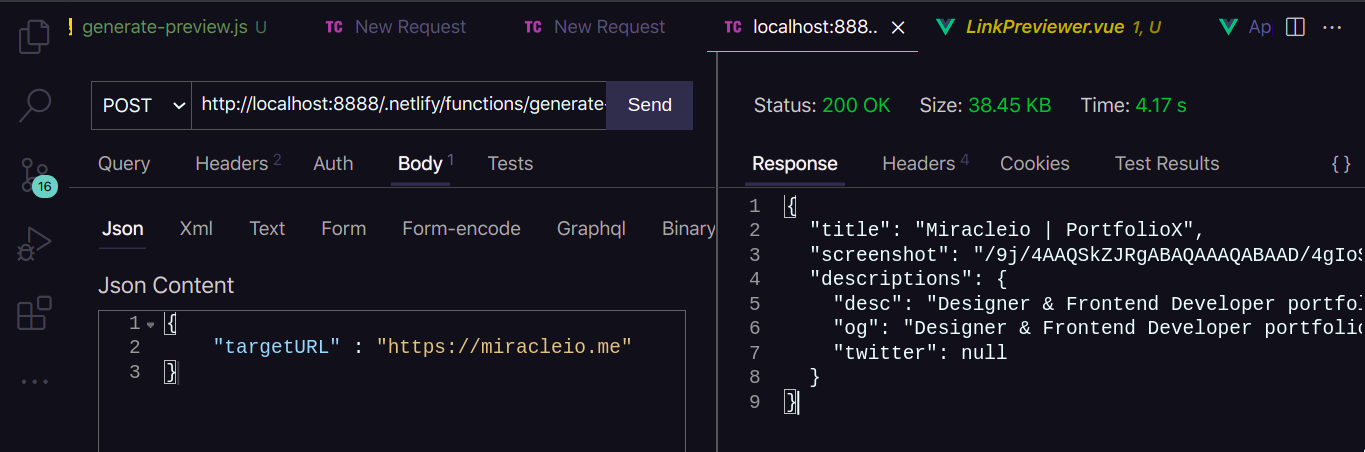
We get a JSON object containing our preview data:
{
"title": "Miracleio | PortfolioX",
"screenshot": "/9j/4AAQSkZJRgABAQAAAQABAAD...",
"descriptions": {
"desc": "Designer & Frontend Developer portfolio site. Built by Miracleio with love ❤",
"og": "Designer & Frontend Developer portfolio site. Built by Miracleio with love ❤",
"twitter": null
}
}
Now that our serverless function works, let’s see how we can use it in our front end.
Building the Link Preview Functionality on the Client
In order to interact with our generate-preview function, we’ll need to send POST requests containing our targetURL.
We’ll create LinkPreview components that will display normal links. These components will be passed their target URLs as props. Before the component is mounted in the application, it’ll send a POST request with the targetURL to our serverless function, get the preview data, and display it once we hover on the link.
Creating the link preview component
First, let’s create our link preview component src/components/LinkPreviewer.vue.
In our <script>, we’ll get the link preview data by sending a request to our serverless function and save the data in previewData object. We’ll use this later in our template to display the data:
// ./src/components/LinkPreviewer.vue
...
<script>
import { computed, onBeforeMount, ref } from '@vue/runtime-core'
export default {
// define targetURL as a prop
props: ['targetURL'],
setup(props) {
// create a reactive previewData object using ref
const previewData = ref({})
// function to send a POST request containing the targetURL
// to the serverless function
const generatePreview = async () => {
try {
const res = await fetch('/.netlify/functions/generate-preview', {
method: 'POST',
body: JSON.stringify({
targetURL : props.targetURL
})
})
const data = await res.json()
return data
} catch (err) {
console.log(err)
return null
}
}
// run function before component is mounted
onBeforeMount(async ()=>{
// run generatePreview() to get the preview data and assign to previewData
previewData.value = await generatePreview()
// use object destructuring to get the different descriptions
// from the preview data
const {desc, og, twitter} = previewData.value.descriptions
// assign only one valid value to the description property
// in the previewData object
previewData.value.description = computed(()=>(desc || og || twitter || ""))
})
// make the following entities available to the component
return { generatePreview, previewData}
}
}
</script>
In the code above, we get the targetURL as a prop that will be passed into our component.
In the setup(), we pass props as an argument in order for us to access component props like targetURL.
Then, we create a reactive peviewData object using ref: const previewData = ref({}). In a new generatePreview() function, we’re using fetch to send a POST request containing the targetURL to our serverless function. This function returns the response or null if an error occurs.
Next, to run the function before the component is mounted, we use the onBeforeMount() hook. We pass an async function as an argument. Within the function, we assign previewData.value to the generatePreview() function. The descriptions (desc, og, twitter) are then gotten from the descriptions property.
To get the description that will be displayed in the preview, we’ll assign previewData.value.description to (desc || og || twitter || ""). This way, the first property with a value gets assigned to the description.
Do this to display the preview data in our template:
<!-- ./src/components/LinkPreviewer.vue -->
<template>
<div class="inline relative">
<!-- display targetURL link -->
<a class="link underline text-blue-600"
:href="targetURL"
:target="previewData ? previewData.title : '_blank'">
{{targetURL}}
</a>
<!-- display preview data if object exists -->
<div v-if="previewData" class="result-preview absolute top-8 left-0 w-72 transform translate-y-4 opacity-0 invisible transition bg-white overflow-hidden rounded-md shadow-lg z-10">
<!-- display image using the base64 screenshot data -->
<img v-if="previewData.screenshot"
:src="`data:image/jpeg;base64,${previewData.screenshot}`"
:alt="previewData.description" />
<!-- display title and description -->
<div class="details p-4 text-left">
<h1 class=" font-extrabold text-xl"> {{previewData.title}} </h1>
<p> {{previewData.description}} </p>
</div>
</div>
</div>
</template>
<script> ... </script>
<style scoped>
.link:hover ~ .result-preview{
@apply visible opacity-100 translate-y-0;
}
</style>
In the above code, in order to display our image — which is essentially a base64 string — we have to pass the string along with data like the image type and encoding into the src-"" attribute.
That’s about it for our LinkPreviewer.vue component. Let’s see it in action. In ./src/views/Home.vue:
<!-- ./src/views/Home.vue -->
<template>
<main class="home">
<header>
<h1>Welcome to the link previewer app!</h1>
<p>Here are some links that you can preview by hovering on them</p>
</header>
<ul class=" mb-4">
<!-- render LinkPreviewer component for each demolink -->
<li v-for="link in demoLinks" :key="link">
<link-previewer :targetURL="link" />
</li>
</ul>
<!-- input field to add new links -->
<input class=" p-2 ring ring-blue-600 rounded-lg shadow-md" type="url" @keyup.enter="addLink" required placeholder="enter valid url">
</main>
</template>
<script>
import { ref } from '@vue/reactivity'
import LinkPreviewer from '../components/LinkPreviewer.vue'
export default{
components: { LinkPreviewer },
setup(){
// demo links
const demoLinks = ref([
'http://localhost:5000',
'https://google.com',
'https://miracleio.me',
'https://miguelpiedrafita.com/'
])
// function to add new links to the demoLinks array
const addLink = ({target}) => {
demoLinks.value.push(target.value)
target.value = ""
}
return {demoLinks, addLink}
}
}
</script>
In our Home.vue file, we’re basically using a demoLinks array of links to render a list of LinkPreviewer components, which we pass to the targetURL props of the component.
We also have an <input> element, which we use to dynamically add more LinkPreviewer components to the list.
Here’s what our simple app looks like now.
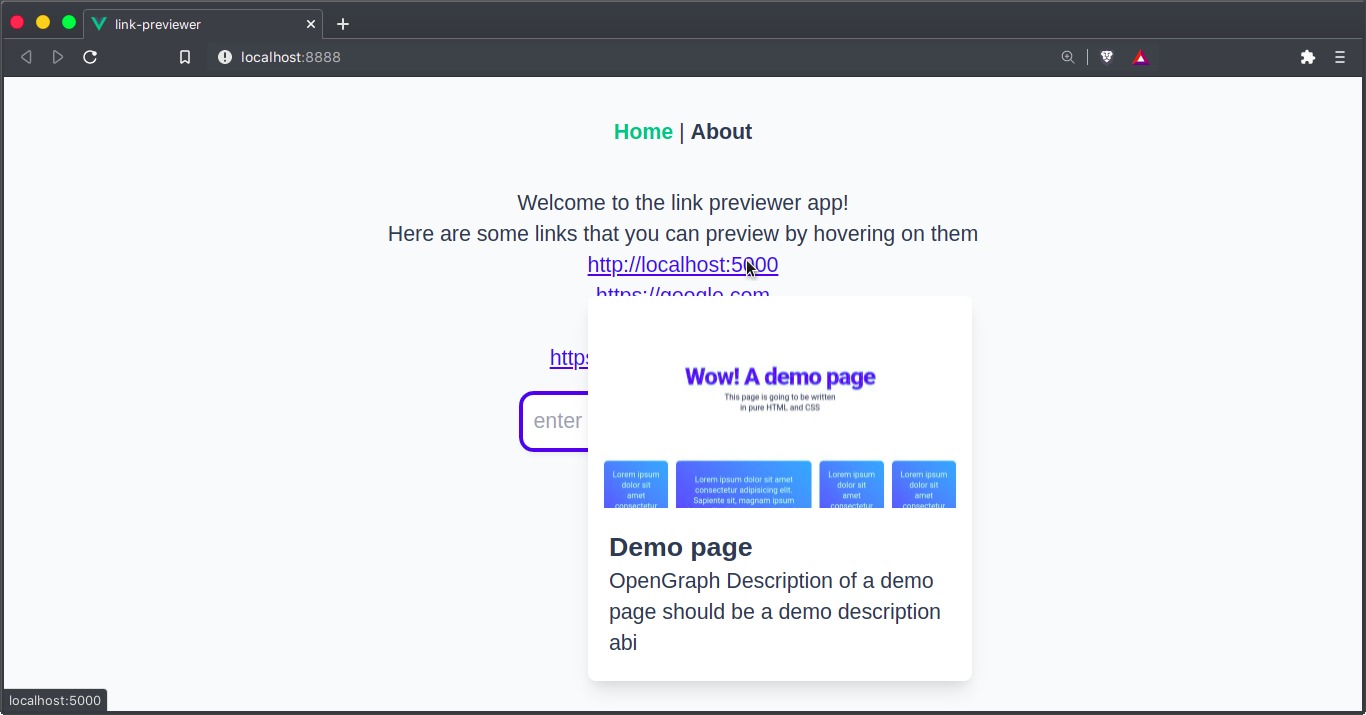
Sweet! Our app works. Since we’ve been running locally using Netlify CLI, let’s see how we can deploy to Netlify using the CLI.
Deploying the App to Netlify
Before we deploy our app to Netlify, we have to build our app for production:
npm run build
This will build our app and create a dist/ folder we can deploy to production.
Next, we need to log in to our Netlify account:
netlify deploy
This will log you into your Netlify account in your browser.
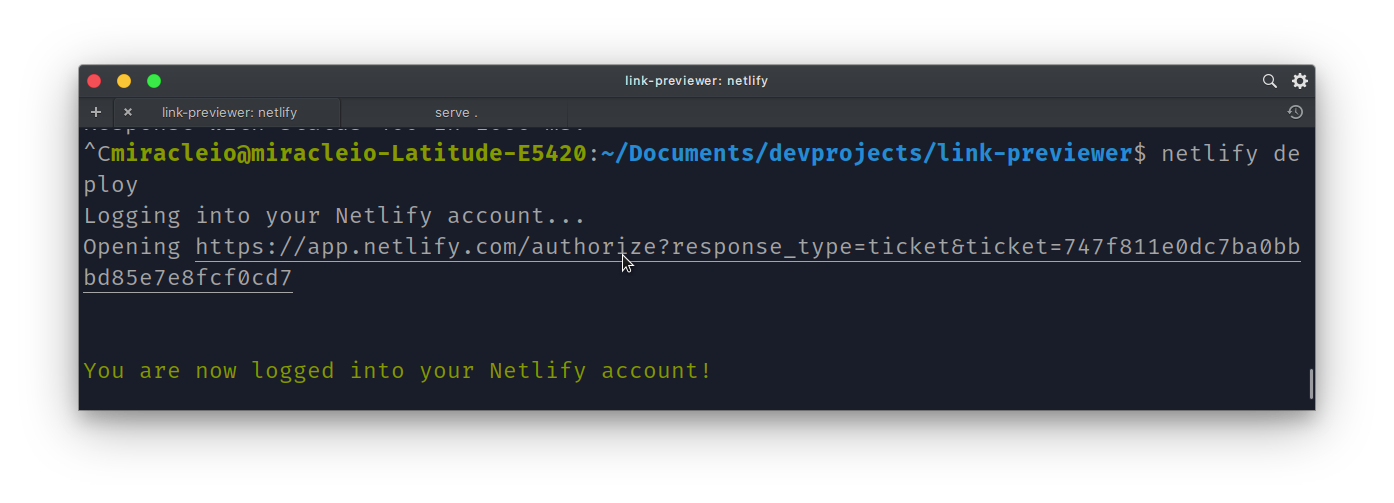
After authorizing the application, we can link our project to a new site. Netlify will ask us a bunch of questions:
- What would you like to do? Choose “Create & configure a new site”.
- Team? Choose
<your team>. - Choose a unique site name? Choose
<site name>. - Please provide a publish directory (such as “public” or “dist” or “.”). Enter
dist.
After this, Netlify will upload our files and deploy them to our new site.
Deploy using GitHub
Alternatively, we can decide to deploy our site from GitHub. All you have to do is to log in to GitHub, create a new repository, and copy the URL to our newly created repo.
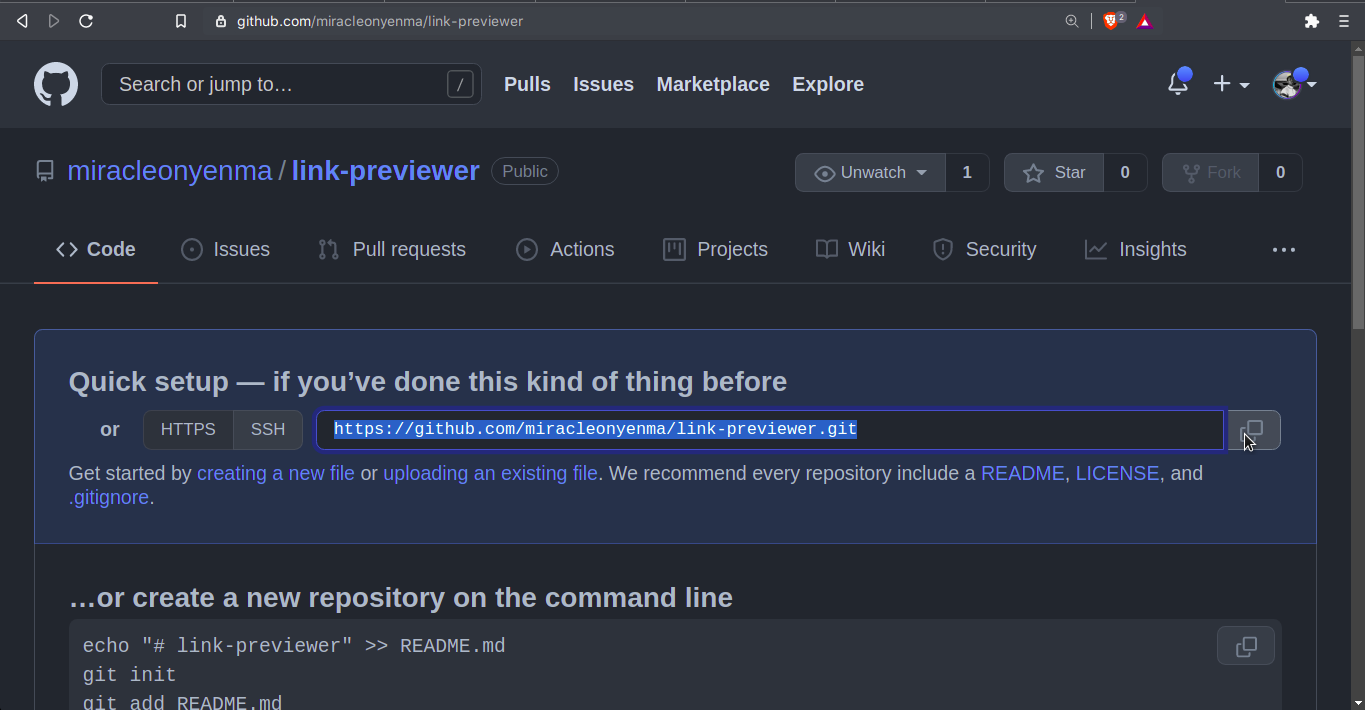
We then run the following command in our project folder:
git init
git add .
git commit -m "first commit"
git branch -M main
git remote add origin https://github.com/miracleonyenma/link-previewer.git
git push -u origin main
Note: you may not be able to push to your repo from your terminal because of authentication issues, and you might get a message from Git like this: “Support for password authentication was removed on August 13, 2021. Please use a personal access token instead.” This means that you have to create a personal access token (PAT) and use it to log in. To do that, go to GitHub token settings and generate a new token. Select all the permissions you want. Make sure you’re able to access repos. After generating your PAT, copy it and save it somewhere. Then try the git push -u origin main command again and paste in your PAT when asked for your password.
Once we’ve pushed the project to GitHub, head over to Netlify to create a new site from GitHub.
Follow the steps to choose a repository and enter the build settings for your project. For our Vue project, the build command is npm run build, and the deploy directory is dist.
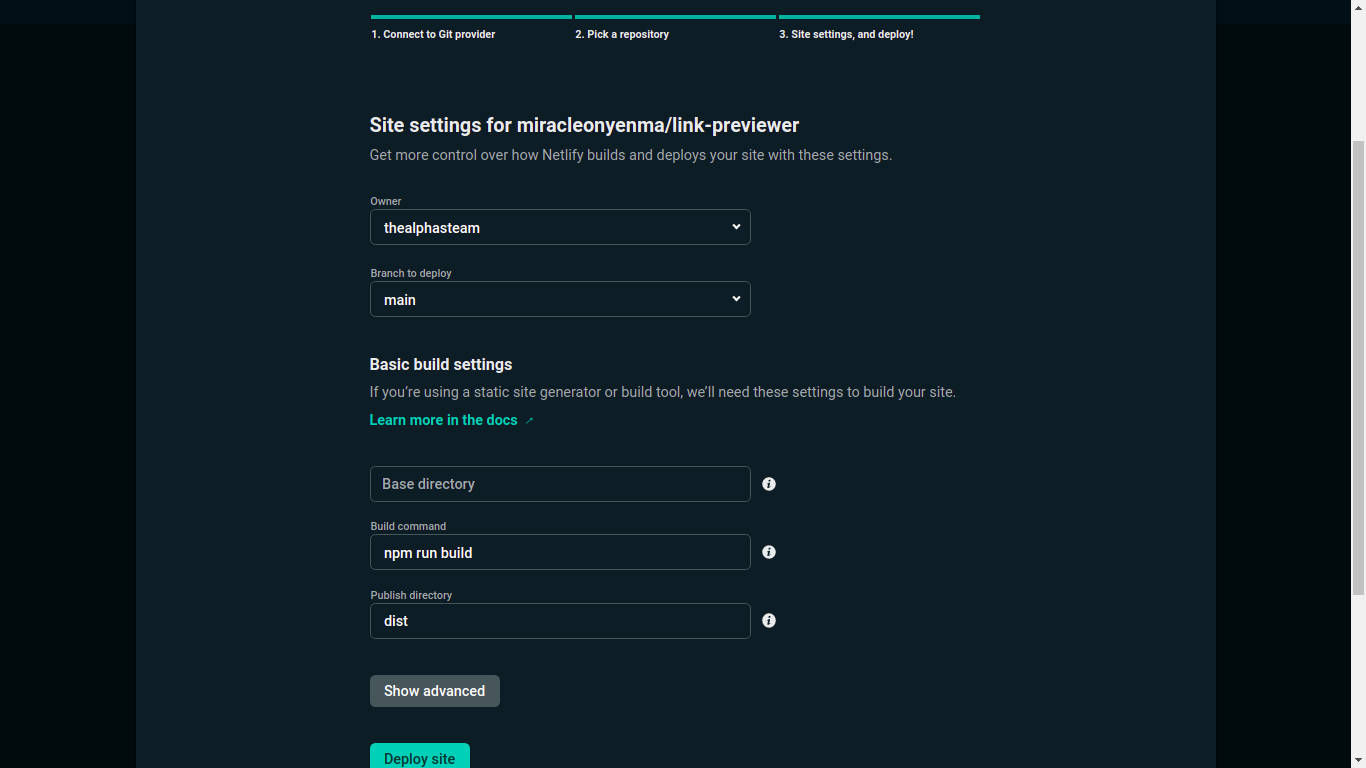
After that, click on Deploy site.
Netlify will deploy the site, and we can preview our site by clicking on the deploy link provided. We can see our functions by going over to Functions from the top menu.
You can select a function to view more details and logs.
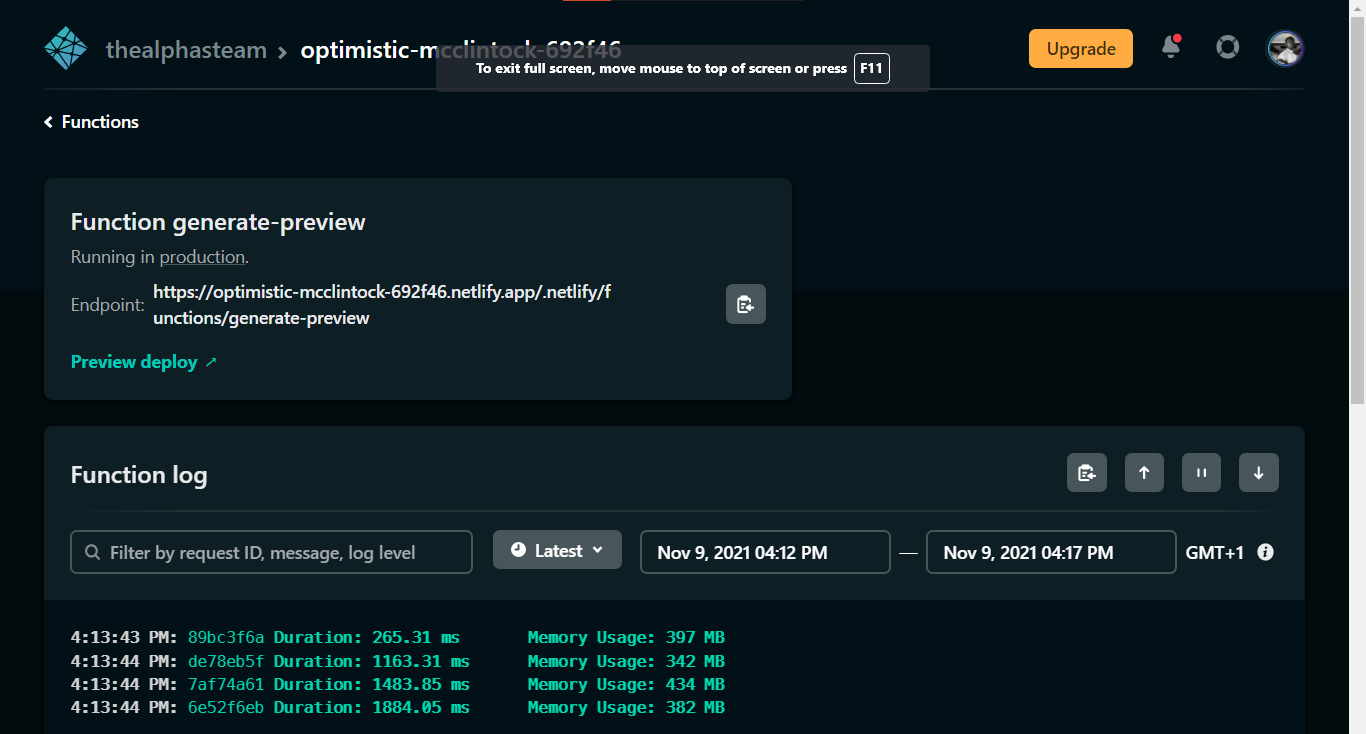
Sweet!
Here’s the link to the demo deployed on Netlify: https://lnkpreviewr.netlify.app
Conclusion
We’ve been able to create and deploy serverless functions with Netlify using Netlify functions. We’ve also seen how we can interact with the functions from our Vue front end. This time, we used to it screenshot and get data from other sites and built a link previewer component with it, but we can do so much more. With serverless functions, we can do more on the front end without having to bother on setting up a back-end server.
Further Reading and Resources
Here are some resources and content that I found useful and I think you will too:
- Project Github Repo
- Tutorials – Netlify Functions
- Up and Running with Serverless Functions – Jamstack Explorers (netlify.com)
- Getting started with Puppeteer Google developers
- How to use Puppeteer in a netlify-aws-lambda function
- How to Use Puppeteer to Automate Chrome in an API with Netlify Serverless Functions – Space Jelly
Frequently Asked Questions (FAQs) about Puppeteer and Serverless Functions
How Can I Debug My Puppeteer Code in a Serverless Function?
Debugging Puppeteer code in a serverless function can be a bit tricky due to the nature of serverless architecture. However, you can use the “console.log” function to print out the values and track the execution of your code. You can also use the “page.on(‘console’, msg => console.log(msg.text()))” function to log all console output from the browser. Remember to check the logs in your serverless function provider’s dashboard.
How Can I Handle Errors in Puppeteer within Serverless Functions?
Error handling in Puppeteer within serverless functions is crucial to ensure your application runs smoothly. You can use try-catch blocks to handle errors. In the catch block, you can log the error message and optionally send a response with the error message. This way, you can track and fix any issues that may arise.
Can I Use Puppeteer with Other Serverless Providers Apart from Netlify?
Yes, you can use Puppeteer with other serverless providers such as AWS Lambda, Google Cloud Functions, and Azure Functions. However, the setup process may vary depending on the provider. You may need to use a custom build of Puppeteer like chrome-aws-lambda for AWS Lambda.
How Can I Optimize the Performance of Puppeteer in Serverless Functions?
To optimize the performance of Puppeteer in serverless functions, you can use a few strategies. First, reuse the browser instance across multiple invocations. Second, use the ‘networkidle0’ waitUntil option to ensure all network requests have finished. Third, disable unnecessary features in Puppeteer like images, CSS, and fonts to speed up page loading.
How Can I Take Screenshots with Puppeteer in Serverless Functions?
Taking screenshots with Puppeteer in serverless functions is straightforward. You can use the “page.screenshot()” function to take a screenshot of the current page. You can specify options such as the screenshot type (JPEG or PNG), quality, and whether to include the full page or just the viewport.
Can I Use Puppeteer to Automate Form Submission in Serverless Functions?
Yes, you can use Puppeteer to automate form submission in serverless functions. You can use the “page.type()” function to fill in input fields and the “page.click()” function to click on buttons or links. After the form submission, you can use Puppeteer to navigate the resulting page and extract the data you need.
How Can I Scrape Dynamic Websites with Puppeteer in Serverless Functions?
Puppeteer is excellent for scraping dynamic websites in serverless functions because it can render JavaScript-generated content. You can use the “page.evaluate()” function to run JavaScript code in the context of the page and extract the data you need.
How Can I Handle Navigation and Page Redirects with Puppeteer in Serverless Functions?
Handling navigation and page redirects with Puppeteer in serverless functions can be done using the “page.waitForNavigation()” function. This function waits for the page to navigate to a new URL or reload. You can use it in conjunction with the “page.click()” function to wait for the page to navigate after clicking a link or button.
Can I Use Puppeteer to Test My Web Application in Serverless Functions?
Yes, you can use Puppeteer to test your web application in serverless functions. Puppeteer provides a high-level API for browser automation, which is perfect for end-to-end testing. You can simulate user interactions, check the resulting page state, and even take screenshots to visually verify your application’s behavior.
How Can I Handle Cookies and Sessions with Puppeteer in Serverless Functions?
Handling cookies and sessions with Puppeteer in serverless functions can be done using the “page.cookies()” and “page.setCookie()” functions. You can use these functions to get and set cookies, respectively. This is useful for maintaining a session or testing the behavior of your application with different cookies.