
Key Takeaways
- Amazon S3, an online storage web service under Amazon Web Services (AWS), is recommended for file hosting due to its scalability and affordability. Registering for an account and acquiring Access Identifiers are the first steps to using this service.
- Services_Amazon_S3 PEAR package is the tool to interact with S3 in your application. The installation process involves creating a PEAR directory in the current working directory, which will contain the actual PHP code for the installed PEAR package and its dependencies.
- There are two ways to use Services_Amazon_S3: programmatically using the API, or via streams using the stream wrapper. The choice between these methods depends on the specific use of S3 and personal preference.
- The Services_Amazon_S3 package simplifies the interaction with S3, handling all the low-level details. It allows users to specify the data they want to operate on and the operation they want to carry out. This package, along with S3, can be integrated into applications after studying examples and API documentation.
I was recently looking for a hosting service for an application I was developing. I decided to investigate Orchestra.io, as I was expecting it to get surges of traffic at specific points during each year and needed the application to scale accordingly. In the process of reviewing documentation for Orchestra.io, I found that it doesn’t allow file uploads. Instead, it’s recommended that Amazon S3 be used for file hosting.
If you aren’t familiar with it, S3 is an online storage web service that is part of Amazon Web Services (AWS). It provides access to fairly cheap storage through a variety of web service interfaces. This article will demonstrate how to sign up for an Amazon S3 account and use PEAR’s Services_Amazon_S3 package to interact with S3 in your own application.
Registering for Amazon S3
The first step in this process is to sign up for your own S3 account at aws.amazon.com/s3. Once there, find and click the “Sign Up Now” button on the right and then simply follow the provided instructions.
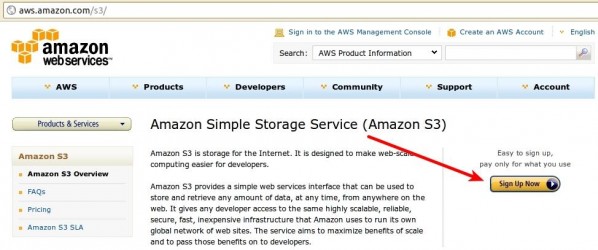
Shortly afterward, you should receive an e-mail at the address you provided with further instructions. If you don’t, or you lose your copy, you can simply go to the AWS Management Console at console.aws.amazon.com/s3. This area of the site will provide you with your Access Identifiers, credentials that are required for you to be able to write data to S3. If you’ve used a web service API that required an access token, these Access Identifiers serve the same purpose. Once you’ve opened the Console page, look in the top right-hand corner for a menu labeled with your name. Click on it to expand it and click on the “Security Credentials” option.
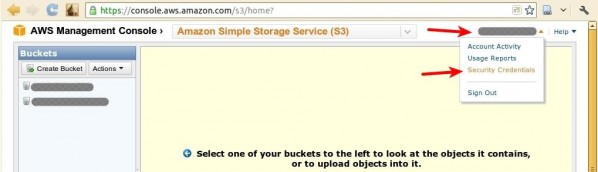
Once you’re on the “Security Credentials” page, scroll down and find the “Access Credentials” section. Here, you’ll find your Access Key ID displayed. Click on the “Show” link near it to display your Secret Access Key. These two pieces of information are all that’s needed to access your S3 account. Be sure to keep them safe.
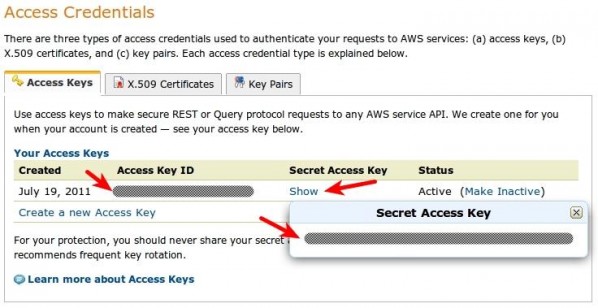
The two tabs next to the “Access Keys” tabs are specific to services other than S3. More specifically, X.509 certificates are used for making secure requests when using AWS SOAP APIs (with the exception of those for S3 and Mechanical Turk – those use Access Keys instead) and Key Pairs are used for Amazon CloudFront and EC2.
Now that you have your Access Identifiers, return to the console page. On the left you’ll find a listing of buckets, which will start out empty. A bucket is simply a named container for a set of files. If you’re using S3 on multiple sites, this mechanism can help you to keep your files for each site separate and organized. You’ll need to create a bucket before you proceed.
Installing Services_Amazon_S3
Next, you need an installation of the Services_Amazon_S3 PEAR package. It’s possible but unlikely that your server already has one unless you have administrative privileges. As such, you’ll probably need a local PEAR copy suitable for a shared hosting environment.
The easiest way to do this is to create this installation on a machine for which you do have administrative privileges and an existing PEAR installation, then copy that installation to your intended hosting environment. On a *NIX system, this can be accomplished by running the following commands from a terminal:
root@foobox:~# pear config-create `pwd` .pearrc root@foobox:~# pear -c .pearrc install -o Services_Amazon_S3
This will create a pear directory within the current working directory. Within that directory is a php directory that contains the actual PHP code for the installed PEAR package and its dependencies. This is the only directory you need to make use of the S3 code in your own code; you can copy it or its contents as-is into whatever directory in your project is reserved for third-party dependencies.
In order to actually make use of the code, you’ll need to add the directory containing the Services subdirectory to your include_path. If /path/to/dir is the full path to the directory containing Services, it can be added to the include_path like so:
<?php
set_include_path(get_include_path() . PATH_SEPARATOR . "/path/to/dir");The remainder of this article assumes that you have a proper autoloader in place to load classes from this directory as they’re used.
Using Services_Amazon_S3
There are two ways to use Services_Amazon_S3: programmatically using the API, or via streams using the stream wrapper. While code using streams can be more concise, it can also be susceptible to bugs in the PHP core related to stream contexts. An example of this is a bug fixed in PHP 5.3.4 where the copy() function did not actually use the $context parameter value if one was provided. It’s recommended that you check the PHP changelog against your PHP version before deciding which method to use.
Using the S3 Stream Wrapper
Let’s look at the streams method first. In addition to the access key ID and secret access key, there are two pieces of information that S3 needs about a file: a string defining who has access to the file (which is private by default) and a MIME type indicating the file’s content type (which defaults to a generic binary type that browsers won’t attempt to render). When using the streams wrapper, all this information is communicated using stream contexts. Let’s look at what processing a file upload might look like:
<?php
if (is_uploaded_file($_FILES["fieldname"]["tmp_name"])) {
Services_Amazon_S3_Stream::register();
$context = stream_context_create(array(
"s3" => array(
"access_key_id" => "access_key_id",
"secret_access_key" => "secret_access_key",
"content_type" => $_FILES["fieldname"]["type"],
"acl" => "public-read")));
copy($_FILES["fieldname"]["tmp_name"],
"s3://bucketname/" . $_FILES["fieldname"]["name"],
$context);
}This code processes a file upload submitted using an HTML form. This form contains a file field with the name
fieldname
. The content_type context option is assigned the MIME type provided for this field by the $_FILES superglobal. The acl context option controls who can access the file once it’s uploaded. In this case, because I was using S3 to host public static files, I used a simple public-read canned ACL that allows anyone to view it. S3 access control allows for much more fine-grained permissions; mine was a very common but simple use case.
Once the stream context is created, the file can be uploaded to S3 by using the copy() function. The source is a path provided by $_FILES that points to a temporary local copy of the uploaded file; once the request terminates, this copy will be deleted. The destination references the s3 wrapper, the name of the bucket to contain the file (bucketname), and finally a name for the file, in this case the original name of the file as it was uploaded as retrieved from $_FILES.
Note that it is possible to specify a relative path instead of just a name. If strict mode is disabled (which it is by default), S3 will simply accept the path and use the appropriate directory structure in the AWS console. Directories do not need to be created in advance in this case.
One other circumstance of my particular use case was that a file may have previously been uploaded to S3 that corresponded to a particular database record. Multiple file extensions were supported and maintained when files were uploaded to S3. As such, the name of a file for a record wouldn’t always necessarily be the same and I would need to delete any existing file corresponding to a record before uploading a new one.
If I stored the name of any existing file for a record, doing this was relatively trivial. Otherwise, it was is a bit clunky because of how the stream wrapper uses the API; I had to iterate over the files in a directory to find a file matching a predetermined prefix that indicated it corresponded to the record. Here’s how to handle both situations:
<?php
// If the existing filename is known...
unlink("s3://bucketname/path/to/file");
// If the existing filename is not known...
$it = new DirectoryIterator("s3://bucketname/path/to/dir");
foreach ($it as $entry) {
$filename = $entry->getFilename();
if (strpos($filename, $prefix) === 0) {
unlink("s3://bucketname/path/to/dir/$filename");
break;
}
}
Using the S3 API
The same file upload using the S3 API would look like this:
<?php
$s3 = Services_Amazon_S3::getAccount("access_key_id", "secret_access_key");
$bucket = $s3->getBucket("bucketname");
$object = $bucket->getObject($_FILES["fieldname"]["name"]);
$object->acl = "public-read";
$object->contentType = $_FILES["fieldname"]["type"];
$object->data = file_get_contents($_FILES["fieldname"]["tmp_name"]);
$object->save();All the same information is being provided to the code, it’s just done via method calls and value assignments to public properties instead of stream contexts and URLs. Again, a relative path within the bucket can be provided in place of the name in this example. As you can see, using the API to upload files requires a bit more hoop-jumping in terms of retrieving objects and manually reading in the file data before explicitly saving the object out to S3.
However, the API does make deleting an existing file with a given prefix a bit easier than it is with the s3 stream wrapper. After obtaining the object representing the bucket containing the file, you can simply do this:
<?php
foreach ($bucket->getObjects($prefix) as $object) {
$object->delete();
}Summary
The Services_Amazon_S3 package makes it fairly easy to get up and running quickly with S3 even if you’ve never use the service before. It handles all the low-level details of interacting with S3 for you, leaving you to specify what data you want to operate on and what operation you want to carry out.
Which method you choose, streams or API, really comes down to how you’re using S3 and what your personal preference is. As this article shows, code can be more or less verbose with either method depending on what it is that you’re doing.
Hopefully this article has given you a small taste of the capabilities of S3 as a service. I encourage you to read more about S3, study examples and API documentation for Services_Amazon_S3, and consider integrating them both into your applications.
Image via Marcin Balcerzak / Shutterstock
Frequently Asked Questions on Integrating Amazon S3 Using PEAR
What is Amazon S3 and why should I use it?
Amazon S3, or Simple Storage Service, is a scalable object storage service offered by Amazon Web Services (AWS). It allows you to store and retrieve any amount of data at any time, from anywhere on the web. It’s designed for 99.999999999% durability and 99.99% availability of objects over a given year. This makes it a reliable and secure option for backup and restore, archive, enterprise applications, IoT devices, and websites.
What is PEAR and how does it work with Amazon S3?
PEAR, or PHP Extension and Application Repository, is a framework and distribution system for reusable PHP components. It works with Amazon S3 by providing a structured library of PHP code that can be used to interact with the S3 service. This includes functions for uploading, downloading, and managing files stored in S3.
How do I set up PEAR to work with Amazon S3?
To set up PEAR to work with Amazon S3, you first need to install the PEAR package manager. Once installed, you can use it to install the necessary PEAR packages for working with S3. These include the HTTP_Request2 and Services_Amazon_S3 packages. After installing these packages, you can use the provided PHP classes to interact with the S3 service.
How do I upload files to Amazon S3 using PEAR?
Uploading files to Amazon S3 using PEAR involves creating an instance of the Services_Amazon_S3 class with your AWS access key and secret key. You then create an instance of the Services_Amazon_S3_Bucket class for the bucket you want to upload to. Finally, you use the putObject method of the bucket class to upload the file.
How do I download files from Amazon S3 using PEAR?
Downloading files from Amazon S3 using PEAR involves creating an instance of the Services_Amazon_S3 class with your AWS access key and secret key. You then create an instance of the Services_Amazon_S3_Bucket class for the bucket you want to download from. Finally, you use the getObject method of the bucket class to download the file.
How do I manage files in Amazon S3 using PEAR?
Managing files in Amazon S3 using PEAR involves using the various methods provided by the Services_Amazon_S3_Bucket class. These include methods for listing objects in a bucket, deleting objects, and getting information about objects.
How do I handle errors when using PEAR with Amazon S3?
When using PEAR with Amazon S3, errors can be handled using the PEAR_Error class. This class provides methods for getting information about the error, including the error message and code.
How do I secure my files in Amazon S3 when using PEAR?
Securing your files in Amazon S3 when using PEAR involves setting the appropriate access control lists (ACLs) for your buckets and objects. This can be done using the setAcl method of the Services_Amazon_S3_Bucket class.
Can I use PEAR with other AWS services?
Yes, PEAR provides packages for interacting with many other AWS services, including EC2, RDS, and DynamoDB. These packages provide PHP classes that make it easy to interact with these services in a structured and consistent way.
What are the alternatives to using PEAR with Amazon S3?
Alternatives to using PEAR with Amazon S3 include using the AWS SDK for PHP, which provides a more comprehensive and up-to-date set of tools for interacting with AWS services. Other options include using the AWS CLI or one of the many third-party libraries available for working with AWS in PHP.