
A First Look at Beegit: The Collaborative Online Markdown Editor

Key Takeaways
- Beegit, an online markdown editor, has a project-based approach, allowing users to create and manage multiple projects featuring markdown files, similar to repositories on services like Github and Bitbucket.
- Despite its promising features, Beegit has some limitations including issues with long file names, lack of image upload functionality, and lack of a plugin architecture.
- Beegit’s collaboration features allow multiple users to work on a document simultaneously, but lack indicators to show where changes are being made, and comments are not linked to specific text.
- Beegit’s export feature does not allow for quick exports or editing of export types, and it lacks integration with popular publishing platforms. The handling of code in Beegit is also criticized for being inadequate.
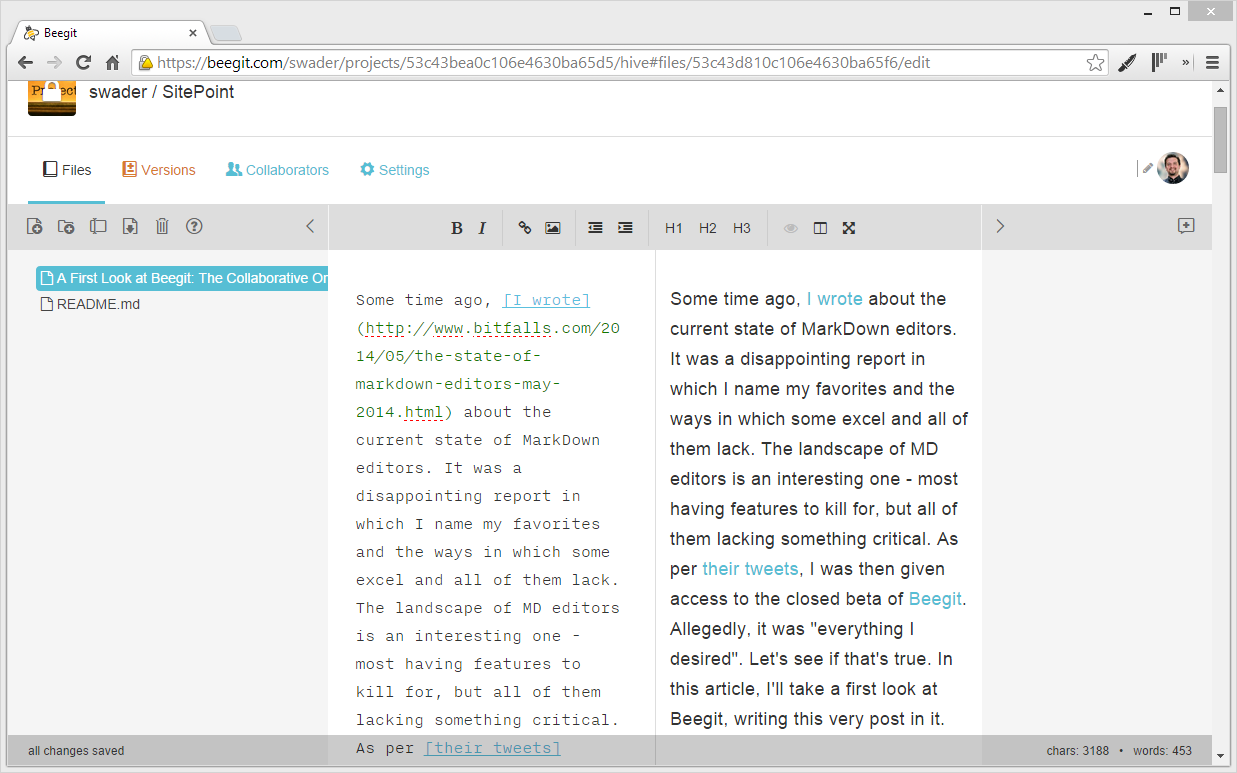
Some time ago, I wrote about the current state of MarkDown editors. It was a disappointing report in which I name my favorites and the ways in which some excel and all of them lack. The landscape of MD editors is an interesting one – most having features to kill for, but all of them lacking something critical.
Some time later, StackEdit fixed their performance issues and climbed back to the top of my list, but still lacked some things. As per their tweets, I was then given access to the closed beta of Beegit. Allegedly, it was “everything I desired”. Let’s see if that’s true. In this article, I’ll take a first look at Beegit, writing this very post in it (so meta!). Note that I’ll be comparing most features with the current reigning champion, StackEdit – in particular, their beta version.
Approach
As opposed to StackEdit’s file-based approach, Beegit has a project-based approach, very similar to repositories you might find on services like Bitbucket and Github.
Projects
Once you log in, you end up on your dashboard. The dash contains all the notifications and changes worth paying attention to, and a list of all your projects.
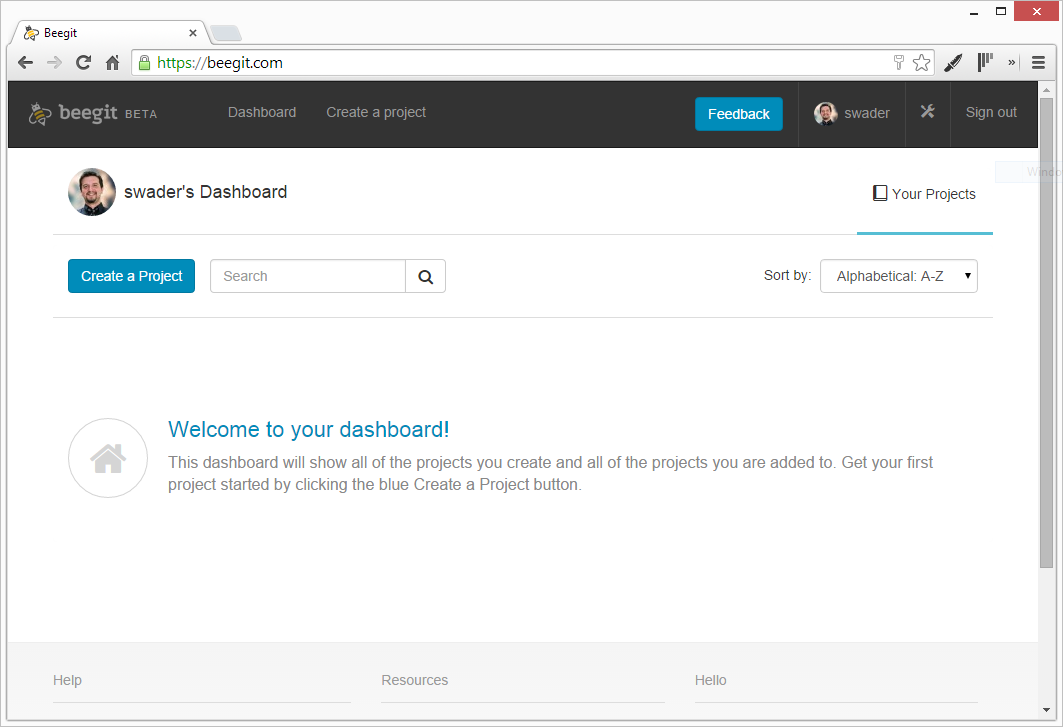
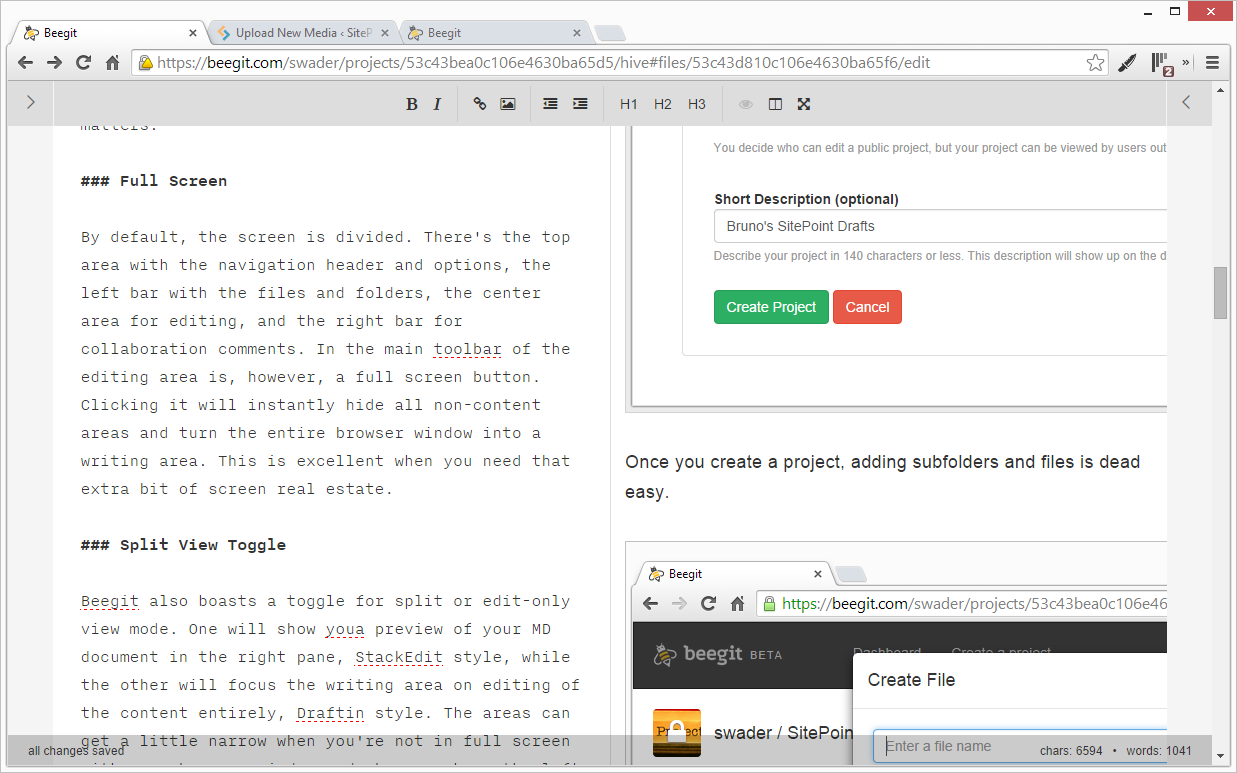
Projects are like Github repositories. You can have public or private ones, and they all contain folders and other files. You can share them with other people, give them descriptions, rename them, change their cover image, and more. Additionally, you can switch them from private to public at will.
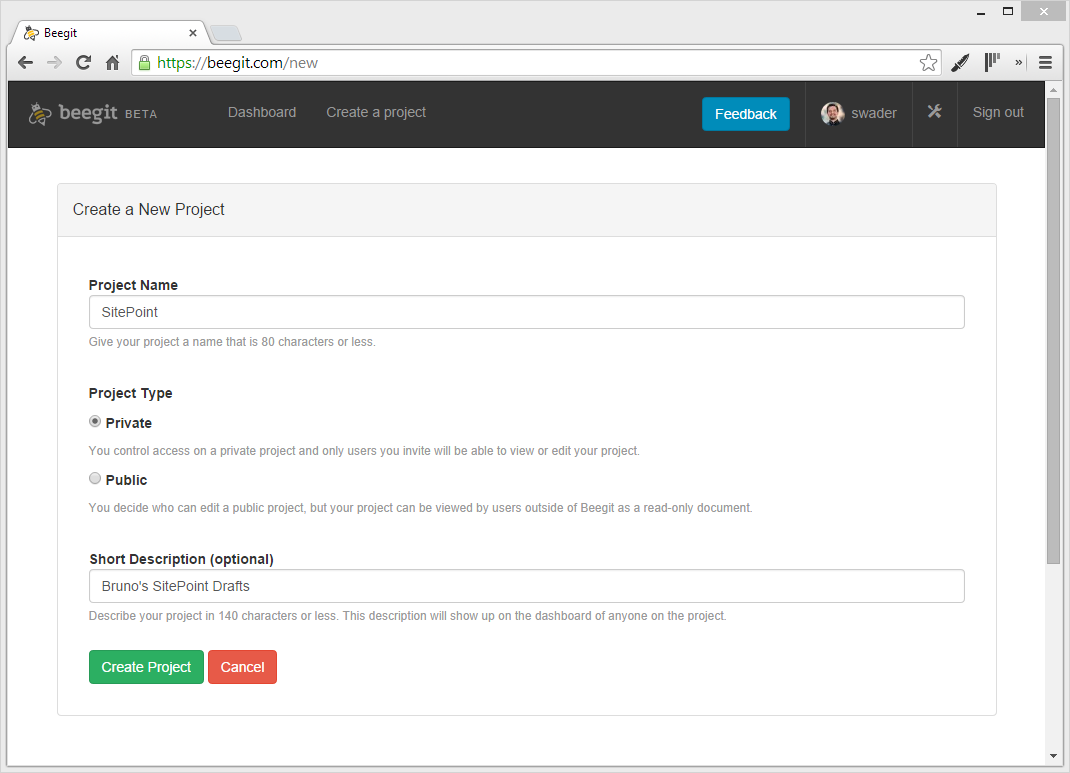
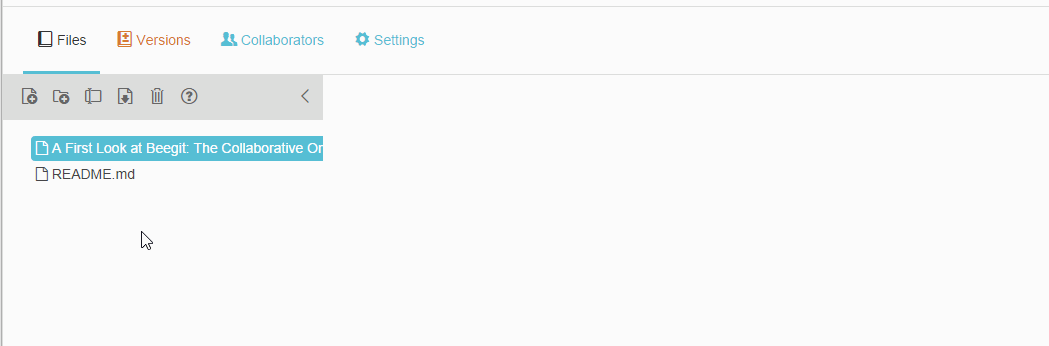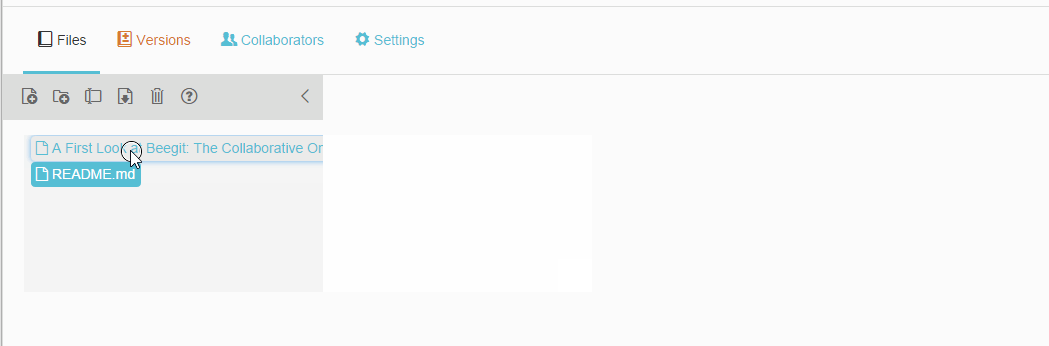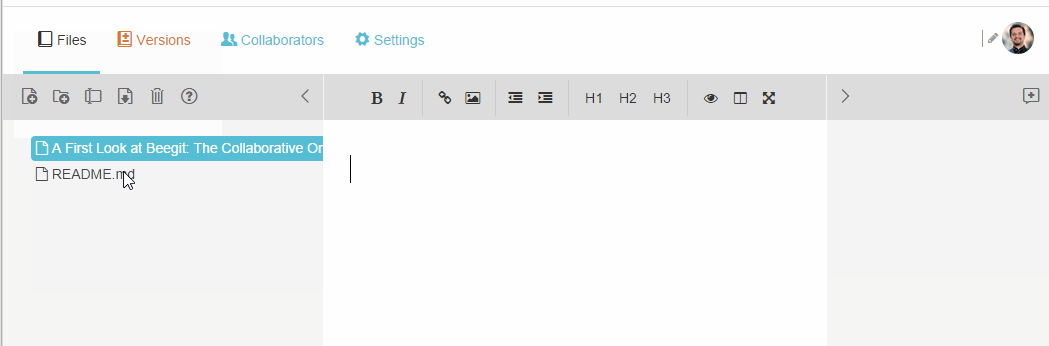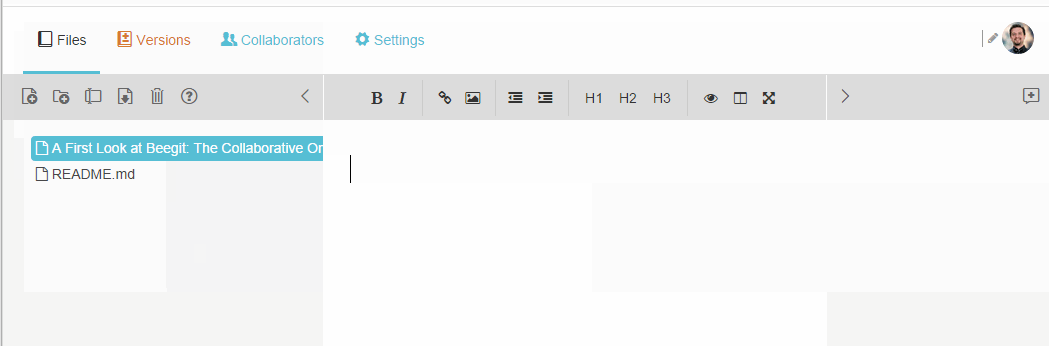
Files
Files are exclusively MarkDown files, even if they don’t end in .md. To edit them, you click on the file name and the contents, along with a toolbar, appear in the central area of the screen. They’re dead simple to create:
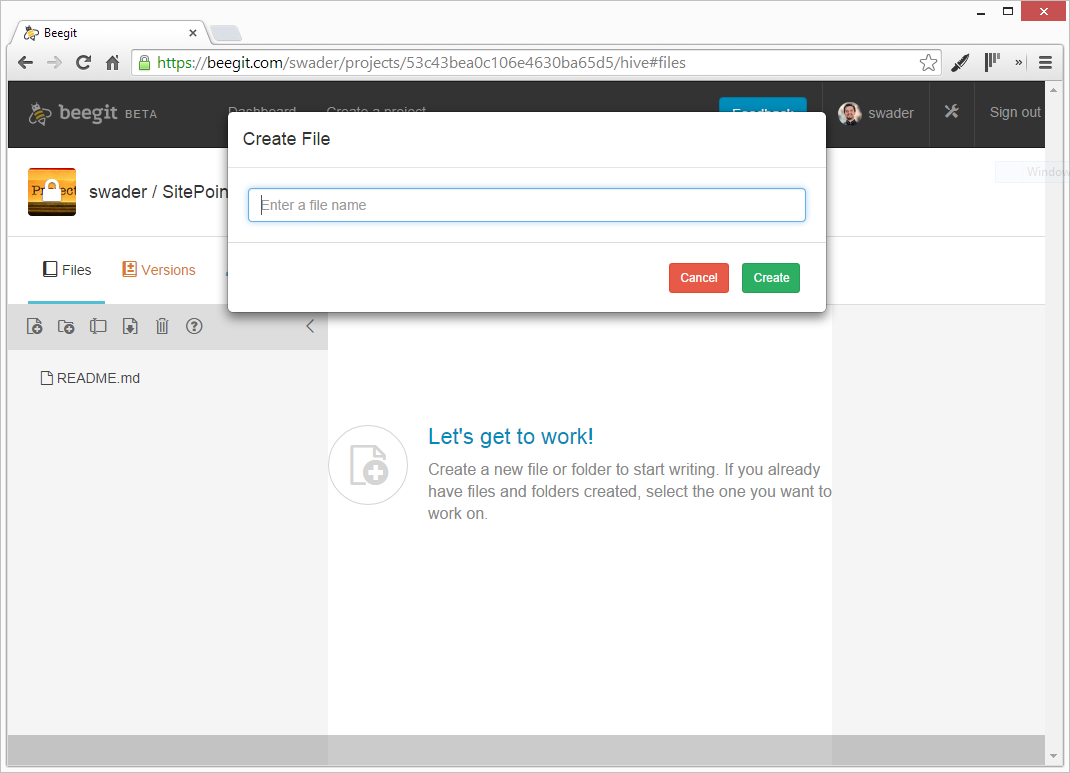
However, this is also where I first encountered some problems.
- Files of long names get cropped, instead of wrapped.
- Sometimes, the toolbar and content fail to load. This requires a refresh of the page.
Both problems can be seen in the GIF below.
User Interface
Let’s see how the UI stacks up now. All in all, compared to StackEdit, the UI is just as good, if not better.
Toolbar
The toolbar offers a set of familiar buttons – bold, italic, indent, outdent, headings, image, link, and some non-formatting related buttons: preview, split screen toggle, and full screen.

Full Screen
By default, the Beegit editor screen has a top area with navigation and options, a left bar with the project structure, a right area with collaboration comments, and the main area of the text editor. The full screen button removes all but the main area, and makes for a distraction-free writing experience. When writing in split screen mode (see below), the experience is even smoother.
Split Screen Toggle
The Split Screen toggle switches the editor view from single-screen edit mode (Draftin-style) to two-column edit+preview mode, StackEdit style.
State
The UI typically remembered the position of elements and frames when refreshing the screen or opening other files. However, when I entered another screen, like settings, and came back, the defaults were reloaded – for example, the right pane, which I explicitly closed, was opened again. This is a minor annoyance, but still an annoyance.
Features
Let’s talk about the internals now.
Image Embeds
Image embedding is a tricky one in this editor. While it does work adequately, it’s not as good as it should or could be. For one, you cannot upload images – there is no option to bind the editor to a CDN endpoint. The only thing the toolbar shortcut does is actually open a popup that lets you input alt text and the URL of the image, which is literally just a shortcut for writing the MD syntax. Writing a plugin that forwards uploads to a Google Drive or Dropbox is fairly simple, and should be done.
Furthermore, after a while and once you add some images, the editor text and the preview text are out of sync, due to Beegit trying to keep them in sync. Instead, they should adopt StackEdit’s approach in which only the editor side is measured for scroll percentage, and that is then applied to the preview pane’s percentage – this means images get scrolled through much faster, but the text stays in sync. In Beegit, we get this:
Autosave
The autosave is, as expected, automatic and works well – or so it seems. However, due to a launch overload bug on Beegit’s side, this is in fact the second time I’m writing this article, by reproducing it from memory. What happened was that the editor was reporting successful autosaves all the time, when in fact my changes never reached the server. After one of many successful refreshes, I ended up with an empty file, losing a 1000-word draft.
They say this won’t happen again, but the fact of the matter is, the editor failed in one thing it should never fail in – data safety. A simple ping that checks an endpoint for a successful ping seems like an upgrade that could have prevented such a problem, or at the very least some local storage backups, though that might interfere with our next point.
Multiple Instances
Beegit allows you to use multiple instances of its editor. This is important to me because I regularly edit different parts of a long article, or need to refer to older drafts when putting together or editing new ones. While it isn’t possible to ctrl+click on a file name to open it in a new tab, you can load it up in another tab from scratch and just get to the file from there. The problem with adding local storage for autosave safety (as mentioned above) might be some race conditions, so I’d rather implement a proper safety ping into the autosave than remove support for multiple instances.
Spell Checker
The spell checker is lightning fast, and checks your typing without delay. However, it’s not native (not your browser’s) which means you cannot change the language, and you cannot add new words to the dictionary. This is annoying, and the distracting red underlines on words like “isn’t” and “autosave” are just a nuisance.

Typing Speed
Even though the spell checker is both very fast and non-native, it still doesn’t do anything to hinder the typing speed. There is a very, very small delay that can be felt on keypresses, but it’s unnoticable unless you’re really used to a better speed (like in Draftin or StackEdit nowadays).
Word and Character Counters
Another tricky feature – to me, an always visible word counter is absolutely essential. But due to this feature’s nature, it usually ends up in a very awkward position, like the bottom-right corner of the screen – and that corner of the screen is often reserved for some always-on-top IM apps like Google Hangouts. This is why I prefer to be able to move it around (like in StackEdit’s beta version) and out of the way. Another problem with the word counter being where it is is the fact that its container (the grey bar) is transparent. This makes the text interfere with any text below, so if you have some text or, even worse, an image with text under it, some readability is lost:

Extensibility
StackEdit is impressive in its open source nature, and its plugin support. Not only can you outright extend it with new features, you can change parameters on the fly just by going to Settings and then to Custom Extensions where you write plain old JavaScript to get it to do what you want.
Unfortunately, Beegit has no plugin architecture whatsoever and cannot be tweaked to individual needs. This is a huge detriment – a tool needs to be tweakable to maintain a smooth workflow.
Collaboration
Let’s test some collab features now.
Collaborators
Collaboration is done simply via inviting someone in the collaboration menu. There are three collab levels: observer, editor and admin, and they all apply to the entire project. There is no way to only collab with someone on a single document, keeping other documents hidden. Right now, the collab features are limited to websocket integration of real-time changes, so if you type something in one window with one user, it will change in the other window for the other user. However, this is distracting because the other collaborator doesn’t know who’s doing what where – there is no indicator as to where the changes are being made (as in Google Docs, for example), the words just appear. Observe:
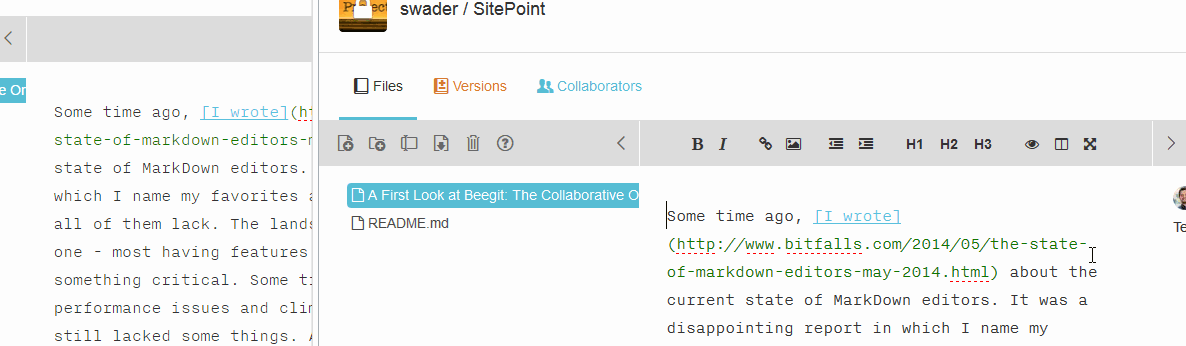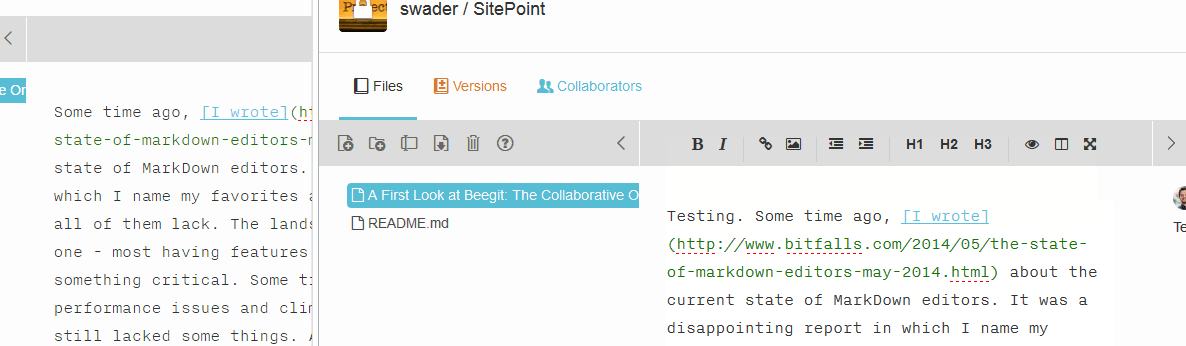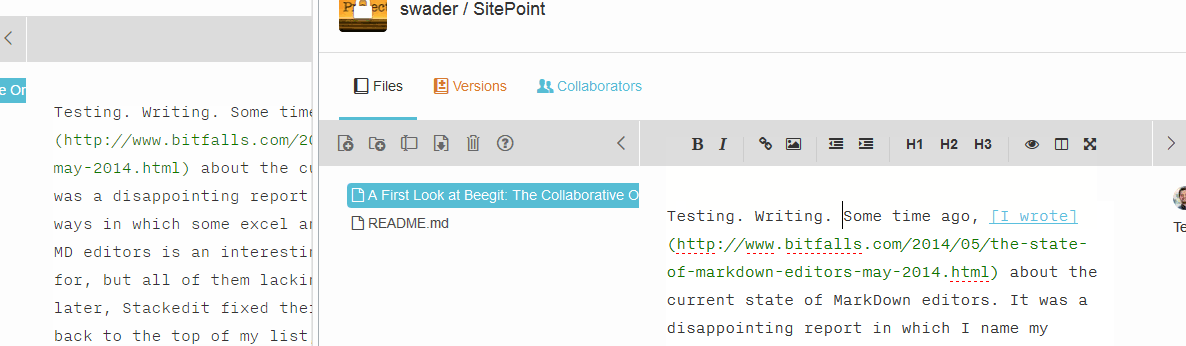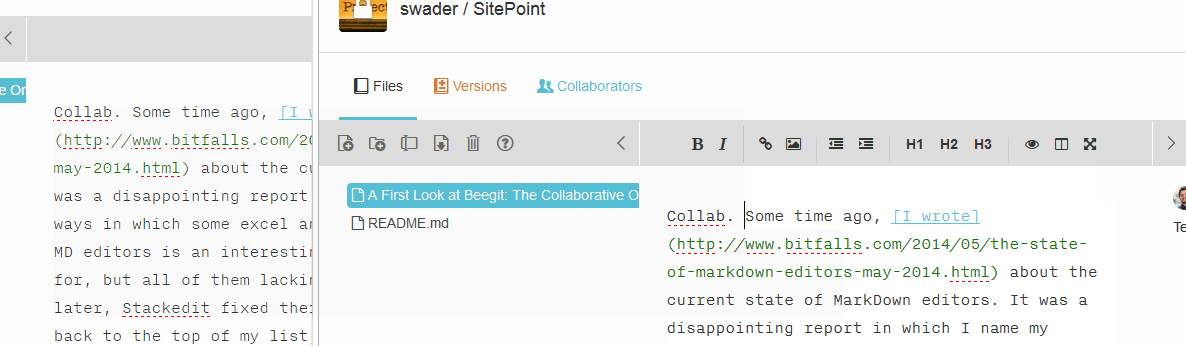
Collaboration will also put the other person(s) into read-only mode. I’m torn on whether that’s good or bad – I think it’s detrimental to work efficiency, especially considering it’s all versioned and can easily be processed, merged and fixed after the fact.
Comments
When a comment is placed onto a document, it simply enters a comments column. There is no way to apply it to a certain bit of text (as in Google Docs) or to resolve it – it’s a one-dimensional conversation among all collaborators. Hardly collaborative, what with tools like Slack at our disposal.
It’s handy to get an email when a comment is posted, but I can imagine it getting spammy when a real conversation heats up.
Needless to say, the collaboration features won’t be winning any awards.
Export
When writing articles in MD or doing my daily edits, I need to use the HTML export button quite a lot. It goes without saying, then, that I rather dislike Beegit’s way of HTML exporting. Not only does it not allow me to edit my export type (for example, completely altering the export of code blocks, but leaving the export of the rest of the text as is), it also has no “quick” export – I need to literally download the HTML file, open it up, select the HTML, then copy and paste it into the back end of my choice (there is no publishing integration directly with popular publishing platforms either, so no hooking into WP, Ghost, Tumblr, etc).
The export itself isn’t bad – it does its job – but it’s not what I’m looking for in terms of speed and use flow. I don’t want a file ever touching my hard drive – they should consider me a user on a Chromebook. I want the HTML to go directly into my clipboard, and I want to be able to tweak individual parts of that HTML that gets generated.
While on the topic of code, code support is dead awful and nigh unusable – not only does Beegit not support code conversion properly and lacks any kind of Github Flavored Markdown support for code highlights, it also completely breaks the output:
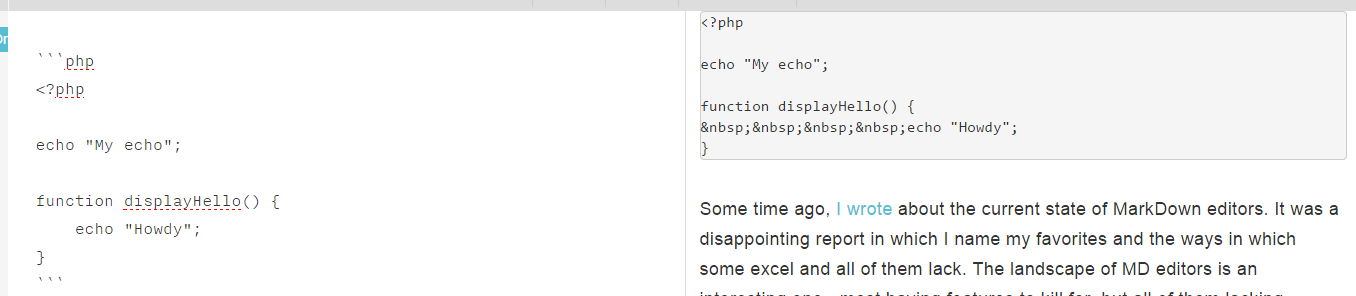
Everything to do with code is definitely an area in which they should steal ideas from StackEdit.
Conclusion
Beegit shows a lot of potential as the new kid on the block, but it has some serious downsides to turn around before being considered a serious contender. The awful code support, the lack of a plugin architecture, a non native spellchecker, and a rigid word counter are just icing on the cake of disappointment when I lost my draft an hour and a half into writing. Of course, the tool is still in beta and bugs are to be expected, so I’ll definitely keep my eye on it – but for now, StackEdit still reigns supreme.
Have you given Beegit a go? What else do you think they should change?
Frequently Asked Questions (FAQs) about Beegit Collaborative Online Markdown Editor
How does Beegit compare to other online markdown editors like HackMD, StackEdit, and HedgeDoc?
Beegit offers a unique collaborative experience for users. Unlike other markdown editors, Beegit provides a seamless interface that allows multiple users to work on a document simultaneously. It also offers a version control system, which is a feature not commonly found in other markdown editors. This ensures that all changes made to a document are tracked, allowing users to revert to previous versions if necessary.
Can I use Beegit for large-scale projects?
Absolutely. Beegit is designed to handle projects of all sizes. It has a robust infrastructure that can support multiple users working on a document simultaneously. This makes it an ideal tool for large-scale projects where collaboration is key.
Is Beegit user-friendly for beginners?
Beegit is designed with user-friendliness in mind. It has a clean, intuitive interface that is easy to navigate, even for beginners. Additionally, Beegit offers a comprehensive guide and tutorial for new users, ensuring that they can quickly get up to speed with the platform.
How secure is Beegit?
Beegit takes user security very seriously. It uses advanced encryption technologies to ensure that all data stored on the platform is secure. Additionally, Beegit has a strict privacy policy that guarantees the confidentiality of user data.
Does Beegit support real-time collaboration?
Yes, Beegit supports real-time collaboration. This means that multiple users can work on a document simultaneously, with changes being reflected in real-time. This makes Beegit an ideal tool for teams working on collaborative projects.
Can I use Beegit offline?
Currently, Beegit is an online platform and requires an internet connection to function. However, the developers are constantly working on improving the platform and may introduce offline functionality in the future.
How does Beegit handle version control?
Beegit has a built-in version control system. This means that every change made to a document is tracked, allowing users to revert to previous versions if necessary. This is a valuable feature for collaborative projects, as it ensures that no work is lost.
Can I customize the Beegit interface?
Beegit offers a range of customization options. Users can adjust the interface to suit their preferences, making it a versatile tool for all types of projects.
Is Beegit compatible with other markdown editors?
Beegit uses standard markdown syntax, making it compatible with most other markdown editors. This means that documents created in Beegit can be easily transferred to and from other markdown editors.
How does Beegit handle large documents?
Beegit is designed to handle documents of all sizes. It has a robust infrastructure that ensures smooth performance, even when dealing with large documents. This makes Beegit an ideal tool for large-scale projects.
Bruno is a blockchain developer and technical educator at the Web3 Foundation, the foundation that's building the next generation of the free people's internet. He runs two newsletters you should subscribe to if you're interested in Web3.0: Dot Leap covers ecosystem and tech development of Web3, and NFT Review covers the evolution of the non-fungible token (digital collectibles) ecosystem inside this emerging new web. His current passion project is RMRK.app, the most advanced NFT system in the world, which allows NFTs to own other NFTs, NFTs to react to emotion, NFTs to be governed democratically, and NFTs to be multiple things at once.





