

Key Takeaways
- The Stack-Walking API, introduced in Java 9, provides an efficient way to access the execution stack, which represents the chain of method calls.
- The StackWalker type gives access to the stack and allows users to perform simple stack walks. It can also be specified to retain class references and show hidden frames.
- StackWalker’s functionality allows for more advanced operations, such as taking a function instead of just returning the stream, and providing an optimized way to get the caller class.
- StackWalker offers performance advantages over previous methods of accessing the stack, being faster than using Throwable when avoiding instantiating the StackTraceElement. Performance can be further improved by reducing the number of recovered frames with Stream.limit.
- The Stack-Walking API’s default behavior excludes hidden and reflection frames, exposes the declaring class, and provides lazy access to the stack trace information for improved efficiency.
Table of Contents
- Who Called Me?
- StackWalker Basics
- Getting a StackWalker
- The forEach Method
- Walk the walk
- Advanced StackWalker
- Why Taking a Function Instead of Just Returning the Stream?
- The getCallerClass Method
- The StackFrame
- The StackWalker Options
- Frame Visibility Options
- Retain Class Reference
- Performance
- Exception vs StackWalker
- Partial Stack Capture
- Conclusion
- Comments
The stack-walking API, released as part of Java 9, offers an efficient way to access the execution stack. (The execution stack represents the chain of method calls – it starts with the public static void main(String[]) method or the run method of a thread, contains a frame for each method that was called but did not yet return, and ends at the execution point of the StackWalker call.) In this article we will explore the different functionalities of the stack-walking API, followed by a look at its performance characteristics.
This article requires working knowledge of Java, particularly lambda expressions and streams.
Who Called Me?
There are situations when you need to know who called your method. For example, to do security checks or to identify the source of a resource leak. Every method call creates a frame on the stack and Java allows code to access the stack, so it can analyze it.
Before Java 9, the way most people would access the stack information was via instantiating a Throwable and use it to get the stack trace.
StackTraceElement[] stackTrace = new Throwable().getStackTrace();
This works but it is quite costly and hacky. It captures all the frames – except the hidden ones – even if you need only the first 2 and does not give you access to the actual Class instance in which the method is declared. To get the class you need to extend SecurityManager that has a protected method getClassContext that will return an array of Class.
To address those drawbacks Java 9 introduces the new stack-walking API (with JEP 259). We will now explore the different functionalities of the API followed by a look at its performance characteristics.
StackWalker Basics
Java 9 ships with a new type, the StackWalker, which gives access to the stack. We will now see how to get an instance and how to use it to execute a simple stack walk.
Getting a StackWalker
A StackWalker is easily accessible with the static getInstance methods:
StackWalker stackWalker1 =
StackWalker.getInstance();
StackWalker stackWalker2 =
StackWalker.getInstance(RETAIN_CLASS_REFERENCE);
StackWalker stackWalker3 =
StackWalker.getInstance(
Set.of(RETAIN_CLASS_REFERENCE, SHOW_HIDDEN_FRAMES));
StackWalker stackWalker4 =
StackWalker.getInstance(Set.of(RETAIN_CLASS_REFERENCE), 32);
The different calls allow you to specify one option or a set of them as well as the estimated size of the number of frames to capture – I will discuss both further below.
Once you have your StackWalker you can access the stack information using the following methods.
The forEach Method
The forEach method will forward all the unfiltered frames to the specified Consumer<StackFrame> callback. So, for example, to just print the frames you do:
stackWalker.forEach(System.out::println);
Walk the walk
The walk method takes a function that gets a stream of stack frames and returns the desired result. It has the following signature (plus some wildcards that I removed to make it more readable):
<T> T walk(Function<Stream<StackWalker.StackFrame>, T> function)
You might ask why does it not just return the Stream? Let’s come back to that later. First, we’ll see how we can use it. For example, to collect the frames in a List you would write:
// collect the frames
List<StackWalker.StackFrame> frames = stackWalker.walk(
frames -> frames.collect(Collectors.toList()));
To count them:
// count the number of frames
long nbFrames = stackWalker.walk(
// the lambda returns a long
frames -> frames.count());
One of the big advantages of using the walk method is that because the stack-walking API lazily evaluates frames, the use of the limit operator actually reduces the number of frames that are recovered. The following code will retrieve the first two frames, which, as we will see later, is much cheaper than capturing the full stack.
List<StackWalker.StackFrame> caller = stackWalker.walk(
frames -> frames
.limit(2)
.collect(Collectors.toList()));

Advanced StackWalker
With the basics of how to get a stack walker and how use it to access the frames under our belt, it is time to turn to more advanced topics.
Why Taking a Function Instead of Just Returning the Stream?
When discussing the stack, it is easiest to imagine it as a stable data structure that the JVM only mutates at the top, either adding or removing individual frames when methods are entered or exited. This is not entirely true, though. Instead, you should think of the stack as something that the VM can restructure anytime (including in the middle of your code being executed) to improve performance.
So for the walker to see a consistent stack, the API needs to make sure that the stack is stable while it is building the frames. It can only do that if is in control of the call stack, which means your processing of the stream must happen within the call to the API. That’s why the stream can not be returned but must be traversed inside the call to walk. (Furthermore, the walk callbacks are executed from a JVM native function, as you can see on the comment for walk on StackStreamFactory and doStackWalk.)
If you try to leak the stream by passing an identity function it will throw an IllegalStateException once you try to process it.
Stream<StackWalker.StackFrame> doNotDoThat =
stackWalker.walk(frames -> frames);
doNotDoThat.count(); // throws an IllegalStateException
The getCallerClass Method
To make the common case fast and simple, the StackWalker provides an optimized way to get the caller class.
Class<?> callerClass = StackWalker
.getInstance(RETAIN_CLASS_REFERENCE)
.getCallerClass()
This call is faster than doing the equivalent call through the Stream and is faster than using the SecurityManager (more details in the benchmark)
The StackFrame
The methods forEach and walk will pass StackFrame instances in the stream or to the consumer callback. This class allows direct access to:
- Bytecode index: the index of the current bytecode instruction relative to the start of the method.
- Class name: the name of the class declaring the called method.
- Declaring class: the
Classobject of the class declaring the called method (You can’t just useClass.forName(frame.getClassName())as you might not have the rightClassLoader; only accessible if RETAIN_CLASS_REFERENCE is used.) - Method name: the name of the called method.
- Is native: whether the method is native.
It also gives lazy access to file name and line number but this will create a StackTraceElement to which it will delegate the call. The creation of the StackTraceElement is costly and deferred until it is needed for the first time. The toString method also delegates to StackTraceElement.
The StackWalker Options
Now that we walk the walk lets have a look at the impact of the different StackWalker options. Because some of them handle frames with special properties, a normal call hierarchy does not suffice to demonstrate them all. We will hence have to do something more fancy, in this case use reflection to create a more complex stack.
We will look at the frames produced by the following call hierarchy:
public static void delegateViaReflection(Runnable task)
throws Exception {
StackWalkerOptions
.class
.getMethod("runTask", Runnable.class)
.invoke(null, task);
}
public static void runTask(Runnable task) {
task.run();
}
The Runnable task will be a lambda printing the stack using the StackWalker::forEach. The execution stack then contains the reflective code of delegateViaReflection and a hidden frame associated with the lambda expression.
Frame Visibility Options
By default the stack walker will skip hidden and reflective frames.
delegateViaReflection(() -> StackWalker
.getInstance()
.forEach(System.out::println));
That’s why we only see frames in our own code:
org.github.arnaudroger.StackWalkerOptions.lambda$main$0(StackWalkerOptions.java:15) org.github.arnaudroger.StackWalkerOptions.runTask(StackWalkerOptions.java:10) org.github.arnaudroger.StackWalkerOptions.delegateViaReflection(StackWalkerOptions.java:6) org.github.arnaudroger.StackWalkerOptions.main(StackWalkerOptions.java:15)
With the SHOW_REFLECT_FRAMES option we will see the reflection frames but the hidden frame is still skipped:
delegateViaReflection(() -> StackWalker
.getInstance(Option.SHOW_REFLECT_FRAMES)
.forEach(System.out::println)
);
org.github.arnaudroger.StackWalkerOptions.lambda$main$1(StackWalkerOptions.java:18)
org.github.arnaudroger.StackWalkerOptions.runTask(StackWalkerOptions.java:10)
java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.base/java.lang.reflect.Method.invoke(Method.java:538)
org.github.arnaudroger.StackWalkerOptions.delegateViaReflection(StackWalkerOptions.java:6)
org.github.arnaudroger.StackWalkerOptions.main(StackWalkerOptions.java:18)
And finally, with SHOW_HIDDEN_FRAMES it outputs all the reflection and hidden frames:
delegateViaReflection(() -> StackWalker
.getInstance(Option.SHOW_HIDDEN_FRAMES)
.forEach(System.out::println)
);
org.github.arnaudroger.StackWalkerOptions.lambda$main$2(StackWalkerOptions.java:21)
org.github.arnaudroger.StackWalkerOptions$$Lambda$11/968514068.run(Unknown Source)
org.github.arnaudroger.StackWalkerOptions.runTask(StackWalkerOptions.java:10)
java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
java.base/java.lang.reflect.Method.invoke(Method.java:538)
org.github.arnaudroger.StackWalkerOptions.delegateViaReflection(StackWalkerOptions.java:6)
org.github.arnaudroger.StackWalkerOptions.main(StackWalkerOptions.java:21)
Retain Class Reference
By default, if you try to access the getDeclaringClass method it will throw an UnsupportedOperationException:
delegateViaReflection(() -> StackWalker
.getInstance()
.forEach(frame -> System.out.println(
"declaring class = "
// throws UnsupportedOperationException
+ frame.getDeclaringClass())));
You will need to add the RETAIN_CLASS_REFERENCE option to gain access to it.
delegateViaReflection(() -> StackWalker
.getInstance(Option.RETAIN_CLASS_REFERENCE)
.forEach(frame -> System.out.println(
"declaring class = "
+ frame.getDeclaringClass())));
Performance
A main reason for the new API was to improve performance, so it makes sense to have a look and benchmark it. The following benchmarks were created with JMH, the Java Microbenchmarking Harness, which is a great tool to test small snippets of code without unrelated compiler optimizations (dead code elimination for example) skewing the numbers. Check out the GitHub repository for the code and instructions on how to run it.
Exception vs StackWalker
In this benchmark we compare the performance of getting the stack via a Throwable and via the StackWalker. To make it a fair fight, we use StackWalker::forEach, thus forcing the creation of all frames (because using Throwable does the same thing). For the new API we also distinguish between operating on StackFrame vs creating the more expensive StackTraceElement.
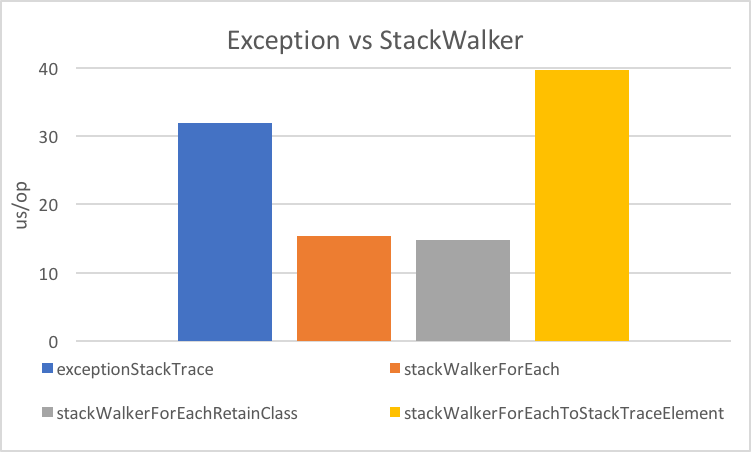
We can see that:
StackWalkeris faster than the exception as long as you don’t instantiate theStackTraceElement.- Instantiating a
StackTraceElementis quite expensive, so beware ofgetFileName,getLineNumberandtoString. - Getting access to the declaring class has no cost, it is just an access check.
Partial Stack Capture
The StackWalker is already faster when capturing the full stack, but what if we retrieve only part of the stack frames? We would expect the lazy evaluation of frames to further increase performance. To explore that we use StackWalker::walk and Stream::limit on the stream it hands us.
Impact of limit
Let’s look at a benchmark that will capture the stacks with different limits:
StackWalker
.getInstance()
.walk(frames -> {
frames.limit(limit).forEach(b::consume);
return null;
});
(The b in b::consume is a JMH class, the Blackhole. It makes sure that something actually happens, to prevent dead code elimination, but quickly, to prevent skewing the results.)
Here are the results:
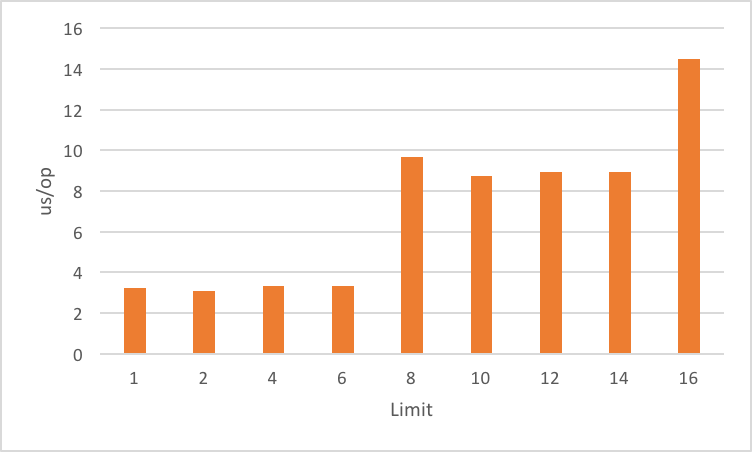
It appears that there is a threshold effect where the cost increases at 8 and 16. If you look at how the walkis implemented, it is no surprise. The StackWalker fetches the frames with an initial batch of 8 if the estimated size is not specified and will fetch another batch once all the frames are consumed.
Impact of limit and Estimated Size
Could we make the call more performant if we specified the estimated size? We will need to add 2 to the limit as the first two frames are reserved. We also need to use the SHOW_HIDDEN_FRAMES option as hidden and reflective frames will occupy a slot even if we skip them. The StackWalker call in the benchmark is as follows:
int estimatedSize = limit + 2;
StackWalker
.getInstance(Set.of(SHOW_HIDDEN_FRAMES), estimatedSize)
.walk(frames -> {
frames.limit(limit).forEach(b::consume);
return null;
});
As you can see here the threshold effect disappears:
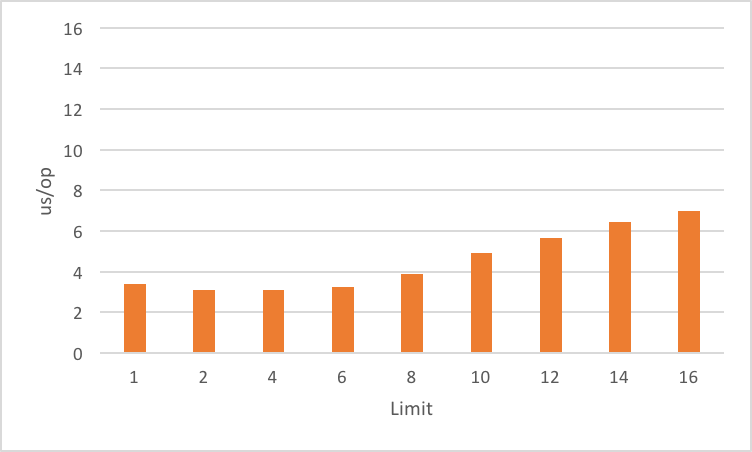
Impact of skip
If limit reduces the cost of the capture, does skip help? Another benchmark to check the impact of skip on different values:
StackWalker
.getInstance()
.walk(frames -> {
frame.skip(skip).forEach(b::consume);
return null;
});
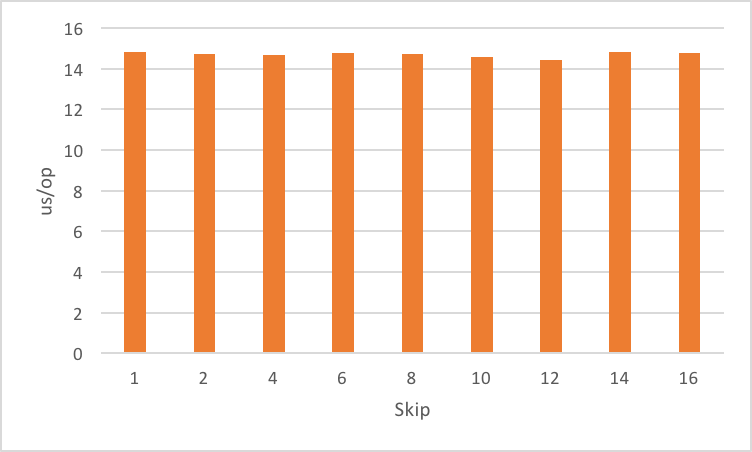
As you would expect the StackWalker still has to walk past the skipped frames resulting in no benefits.
Conclusion
As we’ve seen the stack-walking API provides an easy way to access the current execution stack by just writing:
StackWalker.getInstance().walk(frames -> ...);
Its core characteristics are:
- the default behavior excludes hidden and reflection frames but options allow their inclusion
- the API exposes the declaring class, which used to be cumbersome to access
- it is significantly faster than using
Throwablewhen you avoid instantiating theStackTraceElement– includinggetLineNumber,getFileName,toString - performance can be further improved by reducing the number of recovered frames with
Stream.limit
Frequently Asked Questions (FAQs) about Java 9’s Stack-Walking API
What is the Stack-Walking API in Java 9?
The Stack-Walking API is a new feature introduced in Java 9 that provides a standard and efficient API to traverse and filter stack traces. It is part of the java.lang package and is designed to replace the traditional StackTraceElement API. The Stack-Walking API provides a lazy access to the stack trace information, which means it only computes the stack trace information that it needs, resulting in improved performance.
How does the Stack-Walking API improve performance?
The Stack-Walking API improves performance by providing lazy access to stack trace information. This means it only computes the stack trace information that it needs. In contrast, the traditional StackTraceElement API computes all stack trace information upfront, which can be inefficient if only a small portion of the information is needed.
How do I use the Stack-Walking API to get a stack trace?
To get a stack trace using the Stack-Walking API, you can use the StackWalker’s walk method. This method takes a function that will be applied to the stream of StackFrame objects. Here’s an example:StackWalker walker = StackWalker.getInstance();walker.walk(frames -> {
frames.forEach(System.out::println);
return null;});
How can I filter a stack trace using the Stack-Walking API?
The Stack-Walking API allows you to filter a stack trace by using the filter method on the stream of StackFrame objects. Here’s an example:StackWalker walker = StackWalker.getInstance();walker.walk(frames -> {
frames.filter(frame -> frame.getClassName().startsWith("com.mycompany"))
.forEach(System.out::println);
return null;});
Can I access additional information about a stack frame using the Stack-Walking API?
Yes, the Stack-Walking API provides the StackFrame class, which has methods to access additional information about a stack frame, such as the declaring class, method name, and line number.
How does the Stack-Walking API handle exceptions?
The Stack-Walking API handles exceptions by allowing you to specify a function that will be applied to the stream of StackFrame objects. If this function throws an exception, it will be propagated up to the caller of the walk method.
Can I use the Stack-Walking API to get a stack trace from another thread?
No, the Stack-Walking API can only be used to get a stack trace from the current thread. If you need to get a stack trace from another thread, you will need to use other methods, such as Thread.getStackTrace.
What are the limitations of the Stack-Walking API?
The main limitation of the Stack-Walking API is that it can only be used to get a stack trace from the current thread. It also does not provide any methods to manipulate the stack trace, such as adding or removing frames.
How does the Stack-Walking API compare to the traditional StackTraceElement API?
The Stack-Walking API is more efficient than the traditional StackTraceElement API because it provides lazy access to stack trace information. It also provides additional information about each stack frame, such as the declaring class, method name, and line number.
Is the Stack-Walking API available in all versions of Java?
The Stack-Walking API was introduced in Java 9, so it is not available in earlier versions of Java. However, it is available in all subsequent versions of Java.