An Introduction to Cloud Computing and AWS Certification


In this article, we’ll look at what cloud computing is, the different types of cloud computing, what a cloud provider is, and why you might want to use one. We’ll also survey the best cloud providers, and dig into AWS services in particular and what cloud certification is all about.
Key Takeaways
- Cloud computing involves using remote servers hosted on the internet to store, manage, and process data, offering flexibility and cost efficiency over local servers.
- AWS (Amazon Web Services) is the largest cloud provider, offering a comprehensive certification program that can enhance career opportunities in IT.
- AWS certifications are structured into different levels: Foundational, Associate, Professional, and Specialty, each designed to validate specific expertise in cloud computing.
- The AWS Certified Cloud Practitioner certificate is an entry-level certification ideal for beginners to understand the basics of cloud computing and AWS.
- Key benefits of using cloud computing include cost-effectiveness, scalability, speed, global deployment capabilities, and the absence of upfront capital expenditure.
- AWS offers an extensive range of services across computing, storage, database management, and security, supporting a wide variety of business needs.
- Security in AWS follows a shared responsibility model, where AWS secures the infrastructure, while customers are responsible for securing their data and applications.
Getting Started with Cloud Computing
When starting your cloud computing career, one of the first steps is to choose a cloud provider. Using that cloud provider’s services, you’ll be able to learn about various cloud computing concepts and get to practice your skills .
What is a cloud provider?
A cloud provider is a company that offers you computing services over the Internet. In the simplest terms, it allows you to store and run your applications on somebody else’s computers.
In reality, you can do more than this with a cloud provider, and you’ll get a glimpse of that in this article!
Why use a cloud provider?
Rather than purchasing equipment, setting up your infrastructure, and maintaining it, you can use a cloud provider.
This way, you can focus on building and maintaining your applications without worrying about the physical infrastructure.
What Cloud Provider to Use?
There are many cloud providers available, and there’s no right or wrong answer when choosing one. Some of the most popular cloud service providers are:
- Amazon Web Services (AWS)
- Microsoft Azure
- Google Cloud
- IBM
- Oracle
Amazon Web Services is the biggest and most popular cloud provider. Another strong point of AWS is its certification program. Amazon’s certifications are among the highest-paying certifications in IT.
As a result, this article focuses on AWS for your introduction to cloud computing. The AWS Cloud Practitioner Certificate is Amazon’s foundational course, which teaches the fundamentals of cloud computing and AWS.
AWS Certifications
Amazon Web Services offers 11 certifications that are divided into four categories.
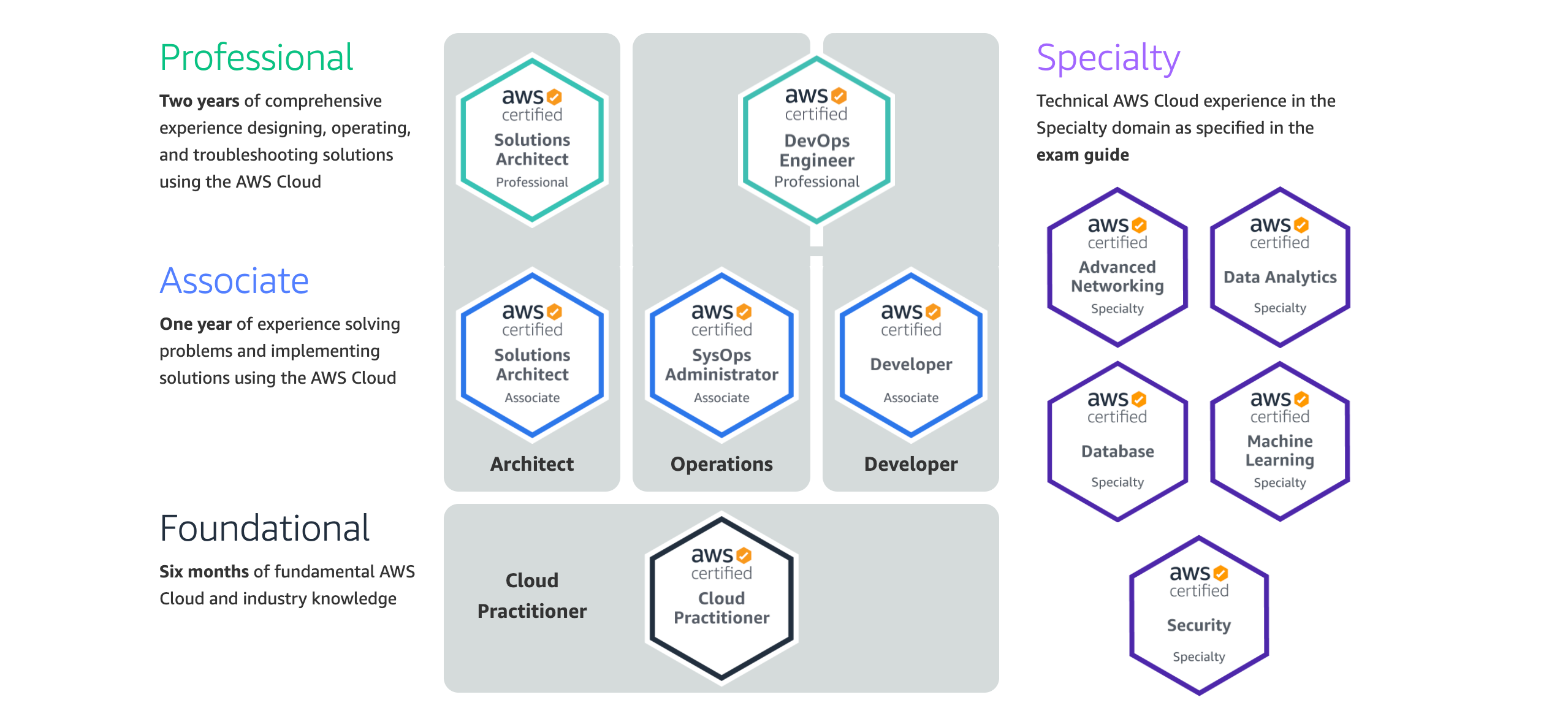
AWS certifications
The Foundational Level has only one certification, the AWS Certified Cloud Practitioner certificate. It covers topics such as:
- the fundamentals of cloud computing
- basic AWS information
- the key AWS services
- billing and pricing
- security
The Cloud Practitioner certificate is suitable and recommended for people who are getting started with cloud computing and AWS. To ease you into the cloud world, this article goes over cloud computing and AWS fundamentals. You can use it as a pre-requisite for the Cloud Practitioner certificate.
The next level is the Associate Level, which has three certifications:
- Solutions Architect
- SysOps Administrator
- Developer Associate
These certifications are more complex than the foundational level, and they teach you how to implement solutions using the AWS infrastructure. With the “Associate Level” certificates, you deep dive into services rather than getting an overview of them.
The certificate you choose depends on the path you want to follow. The AWS Solutions Architect certificate helps you gain general AWS expertise. Since it enables you to gain general AWS expertise, you can use it as the foundation for your following certificates.
After the AWS Certified Cloud Practitioner certificate, you could work towards the Solutions Architect one.
The following levels, Professional Level and Specialty, are the most difficult certifications. You don’t have to worry about them for now.
What Cloud Computing Is
Let’s start with some fundamental information on cloud concepts. The first question you might ask yourself is “what is cloud computing?”
In layman’s terms, cloud computing is simply like using someone else’s computer. Instead of having your servers, you rent the servers from someone like AWS.
In more sophisticated terms, cloud computing is the on-demand delivery of IT resources over the Internet on a pay-as-you-go basis.
The Benefits of Cloud Computing
When it comes to cloud computing, there are six significant benefits:
- Variable expense versus capital expense. This means you only pay when you use resources, unlike on-premise resources, where you need to invest a hefty sum beforehand.
- No capacity guessing. You avoid under-utilization or over-utilization of resources. That means you don’t have to pay for underutilized resources, or have your applications down from over-utilized resources. Cloud computing enables you to rapidly scale up or down in response to changing business needs.
- Increased speed and agility. Cloud computing allows you to create or terminate resources within minutes. You don’t have to wait for your IT team for weeks to implement on-premise solutions.
- Benefit from massive economies of scale. You’re splitting the cost with other customers to receive significant discounts.
- Go global. Deploy your applications to various locations worldwide with minimal effort.
- Spending money on running and maintaining data centers. Avoid the headaches, costs, time, and other resources associated with infrastructure development. Let others handle it and focus on your applications.
Now you know what cloud computing is and its six significant benefits. The next stage is to become familiar with the various types of cloud computing.
Types of Cloud Computing
There are three types of Cloud Computing:
- IaaS (Infrastructure as a Service – for admins). You are responsible for managing your servers (either physical or virtual).
- PaaS (Platform as a Service – for developers). There’s no need for you to manage the underlying architecture. You’re only concerned with deploying and running your applications. An example would be Heroku (where you deploy and run web applications).
- SaaS (Software as a Service – for customers). This is a final product that the service provider runs and manages. Google’s Gmail is one example. You don’t have to worry about anything other than using the service.
Cloud Computing Deployments
In addition to the three cloud computing services, there are four cloud computing deployments. These are:
- Public: fully utilizing cloud computing. Examples are AWS, GCP, Azure, IBM, Alibaba, and so on.
- Hybrid: using a mix of public and private deployments. Sensitive and critical information might be stored in a “private” cloud, whereas other information is stored on the “public” cloud.
- Private: deploying resources on-premise and using virtualization and resource management tools.
- Multi-Cloud: a multi-cloud architecture uses various cloud service providers. For instance, you could use a mix of AWS and Google Cloud.
AWS Infrastructure
At the time of writing, Amazon has 81+ availability zones within 25+ geographic regions. There are over 230+ points of presence, split as follows:
- 218+ edge locations
- 12+ regional edge caches
A region is a geographic area, and it consists of at least two availability zones (AZs). The reason for having at least two AZs is in case one of the data centers goes down. For example, one region is eu-west-1 (Ireland). Every region is independent of each other, and the US-EAST is the largest region. As a result, almost all services become available first in this region.
An availability zone is a data center (a building containing lots of physical servers). An availability zone might consist of several data centers, but they’re counted as one AZ because they’re close to each other.
Points of presence are data centers placed at the edge of the networks.
An edge location is an AWS endpoint for caching content. That’s typically CloudFront, which is AWS’s content delivery network. The purpose of these edge locations is to provide low latency for the end users.
There’s a unique region that’s not available to everyone. This region is called GovCloud, and it’s only accessible to companies from the US and US citizens. You also have to pass a screening process. GovCloud allows users to host sensitive Controlled Unclassified Information such as military information.
AWS Technology
This section comprises the different AWS technologies such as computing services, storage services, logging services, and many more.
IAM (Identity Access Management)
Identity Access Management, or IAM, is one of the essential tools in AWS. IAM is global, which means you don’t have to choose a specific region to use it.
A company has several departments, which means they need different types of access. You can define specific permissions for each department using IAM. IAM allows you to create users, groups, roles. It also allows you to apply a password policy. A password policy specifies what the password needs to contain — for example, numbers, characters, and so on. All the users and groups created are created globally.
According to AWS best practices, you should never use or grant root access to anyone. When someone gains access to the root account, they have complete control over the account. You should also turn on multi-factor authentication (MFA).
AWS Organizations and account
AWS Organization is an account management service that allows users to consolidate various AWS accounts into a single organization. It enables you to manage billing, access, security, compliance, and resource sharing across your AWS accounts. You can, for example, make billing easier by setting up a single payment for all of your AWS accounts.
Organizational units are groups within an organization that can contain other organization units. AWS Organization allows you to isolate different departments in the company — for instance, separate developers from human resources.
The goal of creating organizations for your teams is to attach policies and control access for each team individually. Service control policies define the rules for each organizational unit, ensuring that your accounts follow the guidelines set out by your department.
AWS Compute Services
There are several AWS Compute Services. However, we’re only looking at EC2, ECS, Elastic Beanstalk, Fargate, EKS, Lambda, and Batch for this exam.
EC2 (Elastic Compute Cloud)
EC2 stands for Elastic Compute Cloud, a virtual server (or servers) in the cloud. EC2 makes it simple to scale up or down, depending on how your requirements change.
There are different types of pricing for EC2 instances. They are as follows:
- On-demand
- It’s less expensive and more flexible because it doesn’t require an upfront payment or a long-term commitment.
- Pay a fixed amount per hour of usage.
- Suitable for applications with short-term, spiky and unpredictable workloads that can’t be interrupted.
- Spot
- The price moves all the time, and you have to bid a price. Your instance runs when your bid exceeds the spot price.
- This sort of pricing is ideal for applications with no set start or end times. It’s suitable for data analysis, batch processing, background processing, and optional tasks.
- Reserved
- The most cost-effective solution in the long run.
- You’re tied to a contract. You have the option of signing a one-year or three-year contract.
- The longer the contract and the more money you pay upfront, the less expensive it is.
- It gives you the ability to resell unused reserved instances.
- It’s appropriate for applications with predictable usage and a steady state.
- You can pay all upfront, partial upfront, and no upfront.
- Dedicated
- The most expensive of all these pricing models.
- These are physical Amazon EC2 servers that are exclusively dedicated to you.
- Can be purchased on-demand (per hour basis) or as reserved instances for up to 70% off the on-demand price.
- Useful when regulatory requirements might not support multi-tenant virtualization or for licensing that doesn’t support tenancy cloud deployments.
- Savings Plans
- It provides a low price if you commit to a certain amount of usage for one or three years. The usage is calculated in dollars per hour.
- As a result, you save money by committing to a specific usage.
If Amazon shuts down your EC2 instance, you won’t be charged for the remaining hour of usage. However, if you terminate your EC2 instance, you’ll be charged for any hours that the instance was running.
AWS EBS (Elastic Block Store)
EBS is just a virtual hard drive disk that gets attached to your EC2 instances. Once EBS is attached to an EC2 instance, you can use it in any other way you would use an HDD. The EC2 instance needs to be in the same Availability Zone as the EBS. EBS comes in two flavors: SSD and Magnetic.
AWS ELB (Elastic Load Balancing)
AWS ELB is used to balance the traffic between your resources. For instance, if one EC2 instance is down, the traffic is redirected to another one or creates another EC2 instance. The same happens if one of your resources is overloaded with traffic. That means your application is always available to users instead of being “down”. There are three types of load balancers:
- Classic Load Balancer, which is being phased out. It’s helpful for dev/test environments.
- Application Load Balancer
- Network Load Balancer
The critical difference between these Elastic Load Balancers is that the Application Load Balancer can “look” into your code and make decisions based on that. In contrast, the Network Load Balancer is used when you need extremely high performance and static IP addresses.
ECS (Elastic Container Service)
ECS is a highly scalable, high-performance container orchestration service that supports Docker containers. It enables you to deploy and run containerized applications on AWS. You must select the type of ECS instance you want, which comes pre-configured with Docker.
You can quickly start or stop an application and access other services and resources such as IAM, CloudFormation templates, a load balancer, CloudTrail logs, or CloudWatch events. You must pay for the EC2 instances that ECS utilizes.
Fargate
When you think of Fargate, I want you to think of the phrase serverless containers. Fargate enables you to run containers without the need to manage servers or clusters. Essentially, you deploy applications without having to worry about the infrastructure. You no longer need to select server types or decide how and when to scale your clusters.
ECS has two launch options: Fargate and EC2. All you have to do for the Fargate launch type is package your application in a container, specify the CPU and memory, and define the network and IAM policies. After that, your application is ready for deployment.
Fargate charges you per task and per CPU utilization. You don’t have to pay for EC2 instances. Fargate is best suited for applications with consistent workloads that are Docker containerized.
EKS (Elastic Kubernetes Service)
EKS also manages your Kubernetes management infrastructure across several AWS availability zones. The reason for that is to remove a single point of failure.
Finally, EKS is better suited for architectures with thousands of containers than ECS, which is better suited for simpler architectures.
Lambda
These are just serverless functions that take care of everything after you’ve uploaded your code. AWS Lambda allows you to run your code without provisioning or managing servers.
You pay for the compute time you consume. There’s no charge when the Lambda isn’t running. A use case for Lambda functions would be unpredictable and inconsistent workloads.
Elastic Beanstalk
AWS Elastic Beanstalk is a fast and straightforward way to deploy your application on AWS. This service handles capacity provisioning, load balancing, autoscaling, and health monitoring automatically.
Elastic Beanstalk is covered in greater detail later in the “AWS Provisioning Services” section.
AWS Batch
AWS Batch allows you to plan, manage and execute your batch processing jobs. This service plans, manages, and runs batch processing workloads across the entire AWS Compute Services portfolio, including EC2 and spot instances.
AWS Storage Services
We also need to store our data somewhere, right? Not to worry, as AWS allows us to do just that with a wide range of services.
S3 (Simple Storage Service)
The first in line is one of the oldest and most fundamental AWS services — Amazon Simple Storage Service (S3).
S3 allows users to store and retrieve any amount of data from anywhere in the world. It provides a highly scalable, secure and durable object storage. In simpler words, S3 is a safe place where you can host (store) your flat stuff (such as videos and images). By “flat”, I mean that the content doesn’t change. (For example, you can’t store a database in S3, as it continuously changes.) The data from your S3 buckets are spread across multiple facilities and devices in case of failures.
But wait, what do you mean by “object storage”? Data is stored in buckets, and each bucket consists of key–value pairs. The key represents the file’s name, whereas the value represents the contents of the file.
Some essential quick points about S3 are:
- it’s object-based
- files can range from O bytes to 5TB
- you have unlimited storage
- files are stored in buckets
- buckets must have unique names, because the S3 namespace is universal — meaning that there can’t be two buckets with the same name in the world.
- when an object is uploaded successfully in the bucket, it returns the status code 200
What are the features of the S3 service?
- Tiered storage available: different types of storage for different use cases.
- Versioning: meaning that it keeps multiple versions for the same file. This allows recovering files in the event of failure or unintended user actions.
- Lifecycle management: represents a set of rules to decide what to do with your data stored. For example, you could define when a group of objects should be transferred to another storage class — such as for archiving data — or set a rule to delete the files after they expire.
- Encryption: allows you to set necessary encryption behavior for your S3 buckets. For instance, encrypt the files before they’re uploaded and decrypt them when they’re downloaded.
- You secure your data through Access Control Lists (on an individual file basis) and Bucket Policies (applied across entire buckets).
S3 data consistency is of vital importance as well. What about it, though?
- Read after Write consistency for PUTS of new objects. That means you can access the data uploaded to the S3 buckets as soon as the data is uploaded. You can access and view the new file immediately.
- Eventual consistency for overwriting DELETE and PUTS. That means after deleting a file, you might still be able to access it for a little while. It also means that when you update an existing file, you might get the old file if you try to access it straight after updating it. Why is that? It takes time for the changes to propagate. As we’ve seen above, the data in S3 buckets is spread across multiple devices and facilities.
How does S3 charge you? S3 charges you based on:
- storage
- requests
- storage management pricing
- data transfer pricing
- transfer acceleration
- cross-region replication
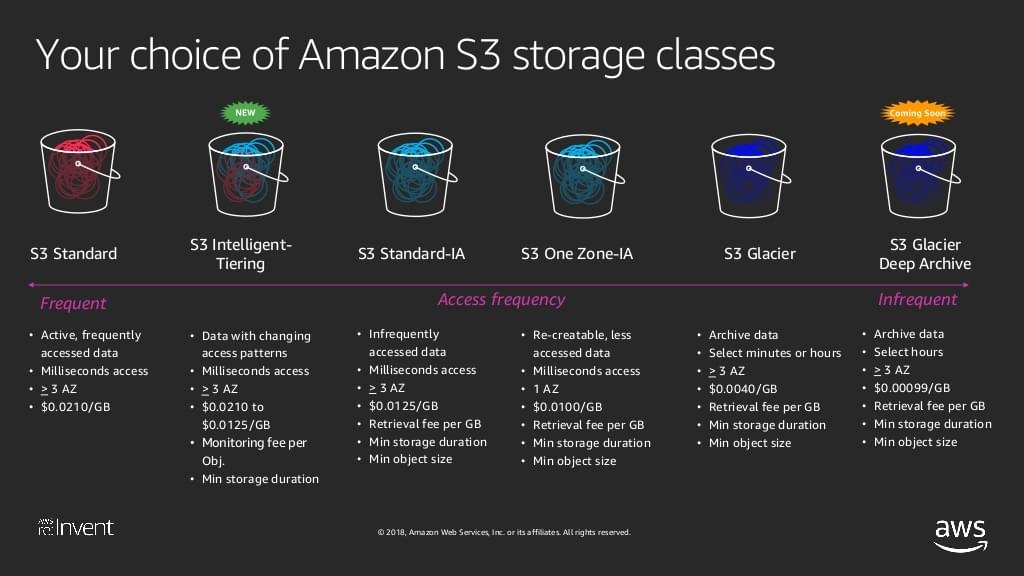
The last thing that remains is to look at the different S3 storage classes. They are as follows:
- S3 Standard. This storage class comes with 99.99% availability and 99.999999999% durability. The data is stored on multiple systems across multiple facilities to sustain the loss of two facilities at the same time.
- S3 IA (Infrequently Accessed). This storage class is for data that’s infrequently accessed but requires quick access when it’s needed. Even though it’s cheaper than the standard storage, it charges you per file retrieval.
- S3 One Zone IA. Basically, it’s the same thing as S3 IA, with the only difference being that your data is stored in one place only — no multiple AZs.
- S3 Intelligent Tiering. This storage class automatically moves your data to the most cost-efficient storage tier. For example, it could push your data from S3 Standard to S3 One Zone IA to reduce costs. It doesn’t impact performance.
- S3 Glacier. S3 Glacier is suitable for data archiving where retrieval times between minutes to hours are accepted. It’s the second-lowest-cost storage class.
- S3 Glacier Deep Archive. Basically, it’s the same as S3, with one significant difference: data retrieval takes twelve hours. It is also the lowest-cost storage class.
The figure below compares the S3 storage classes.
AWS Database Services
There are multiple database services, but they’re split into two parts. There are NoSQL and SQL (relational) databases. The NoSQL databases available on AWS are:
- DynamoDB — AWS’s flagship database
- DocumentDB
The SQL (relational) databases are:
- Aurora — Amazon’s product (5 times faster than MySQL)
- MySQL
- PostgreSQL
- MariaDB
- Oracle
- Microsoft SQL Server
The relational databases have two key features:
- Multi-AZ. They’re deployed in multiple availability zones for disaster recovery.
- Read replicas. Data is read from replicas instead of being read from the database itself. The writes are done to the database, but the data is read from replicas.
AWS Provisioning Services
Provisioning refers to the creation of resources and services for a customer. It’s a way of creating resources for your AWS resources. The AWS provisioning resources are:
- CloudFormation
- Elastic Beanstalk
- OpsWorks
- AWS QuickStart
- AWS Marketplace
Let’s start with CloudFormation, one of the most powerful and helpful tools in AWS.
CloudFormation is a JSON or YAML template that turns your infrastructure into code and consists of stacks. “Turning infrastructure into code” means programmatically specifying all the resources needed by your application, after which they’ll be created automatically. That means you don’t have to manually create resources in the AWS console and then link them together.
See an example of a CloudFormation template that creates an EC2 instance with security groups here (it’s in YAML format).
Elastic Beanstalk allows you to upload your application code. It automatically creates all the resources for you (provisioning your EC2 instances, your security groups, your application load balancers, all with the click of a button). It automatically handles the details of capacity provisioning, load balancing, scaling, and application monitoring.
Elastic Beanstalk is an excellent service for quickly deploying and managing applications in the cloud without you having to worry about the infrastructure if you’re unfamiliar with AWS. It automates everything for you. If you want to associate this service with something more familiar, Elastic Beanstalk is AWS’s own Heroku.
AWS Quick Starts allow you to quickly deploy applications in the cloud by using existing CloudFormation templates built by experts. Let’s say you want to deploy a WordPress blog on AWS. You can go to AWS Quick Starts and use a template that does just that, so you don’t have to build it yourself.
Amazon describes AWS Marketplace like this:
AWS Marketplace is a digital catalogue with thousands of software listings from independent software vendors that make it easy to find, test, buy, and deploy software that runs on AWS.
You could use AWS Marketplace to buy a pre-configured EC2 instance for your WordPress blog.
Lastly, OpsWorks is a configuration management service that allows you to manage instances of Chef and Puppet. It gives you the ability to use code to automate the configuration of your servers. More OpsWorks information can be found here.
AWS Logging Services
One important area we need to cover is logging. If your services go down, you surely want to know why that happened. Thus, AWS provides two logging services that help you with that:
- AWS CloudTrail. CloudTrail is a service that monitors all API calls made on the AWS platform. It’s helpful to figure out who did what. For example, we can use this service to determine who terminated an EC2 instance, or who created a new S3 bucket.
- AWS CloudWatch. CloudWatch is a service that monitors AWS and on-premises resources and applications. It can, for example, keep track of CPU, memory, and network consumption. You can use CloudWatch to monitor your environments, set alarms, visualize logs and analytics, automate actions, troubleshoot issues, and gain insights into your applications.
It can be easy to confuse these two services, so you can read more about the difference between AWS CloudTrail and AWS Cloudwatch if you’re interested.
AWS CloudFront is Amazon’s content delivery network (CDN). A CDN is a system of distributed servers worldwide that serves web content to users based on their geographical location and the web page origin.
- Origin: this represents the origin of all the files that the CDN distributes. The origin can be an S3 bucket, EC2, Elastic Load Balancer, or Route53.
- Distribution: the name of the CDN that consists of a collection of edge locations.
- Edge locations: an edge location is a location where the content is cached.
- A file is cached for a period specified by the TTL (time-to-live) (usually 48 hours). You can clear the cached objects, but you will be charged.
There are two types of CloudFront distributions:
- Web distributions: for websites
- RMTP: for media streaming
Billing and Pricing
This is an essential section. The reason is that you don’t want to incur any unnecessary expenses (which is relatively easy to do with AWS), and it’s also a vital component of the exam.
Paying principles
You must remember the AWS paying principles. These are as follows:
- You pay as you go (reduces the risks of under-provisioning or over-provisioning).
- You pay less when you reserve.
- You pay even less per unit by using more services/resources.
- You pay even less as AWS grows.
Also, on AWS you pay for:
- compute capacity
- storage
- outbound data
AWS is smart. To entice you to use their services, they don’t charge you for migrating your data to them. They do, however, charge you when you transfer data from their cloud.
The other two important terms you should know are CAPEX and OPEX. CAPEX stands for Capital Expenditure, and it means to pay upfront. It’s a fixed cost. OPEX stands for Operational Expenditure, and it means paying only for what you use.
Key pricing principles
There are four fundamental pricing principles. These are:
- Understand the fundamentals of pricing. This is essentially what we previously discussed. As previously stated, we pay for computing capacity, storage capacity, and outbound data in AWS.
- Start early with cost optimization. All this policy implies is that you establish cost controls before your environments become massive. As a result, cloud investment management does not become a concern as the infrastructure increases.
- Maximize the power of flexibility. Essentially, this policy states that because you are paying for something as you need it, you can focus on the environment rather than the infrastructure. You maximize the power of flexibility by using your environment only when you need it. One significant advantage is that you don’t pay for your resources when they’re not in use, allowing you to be cost-effective.
- Use the right pricing model for the job. AWS offers several pricing models depending on the product. The pricing models are as follows:
- on-demand
- dedicated instances
- spot instances
- reserved instances
These are the critical pricing policies, and you can read more about them here.
Budgets and Billing Alarms
One of the downsides of AWS is how easy it is to generate a massive bill. If you don’t pay attention and don’t make the most out of the budgets and billing alarms, you may rack up a bill of a few thousand dollars and even more.
The billing alarm enables you to set money limits to ensure that you don’t overspend. You’ll be warned when you reach a certain threshold and are near to exceeding the set limit.
Learn how to set a budget on AWS
AWS Free Services
Let’s ease in with the free services from AWS. The free AWS services are as follows:
- OpsWorks
- IAM
- Organizations & Consolidated Billing
- VPC
- Elastic Beanstalk
- CloudFormation
- Auto Scaling
- AWS Cost Explorer
There is, however, a catch. These services are free, but the resources they use/create aren’t. Although CloudFormation is free, the resources it generates aren’t. You’ll be charged for the EC2 instances as well as whatever it creates/uses. Keep this in mind at all times.
AWS Support Plans
There are currently four support plans with different features. The different AWS support plans are Basic, Developer, Business, and Enterprise. Let’s see how they differ and what do they offer.
Basic support plan
This is the most basic plan, with actually no support (huh). This plan could be used for testing AWS or very small applications.
- Cost: free.
- Tech support: none. You have to use only forums such as the AWS forum.
- Who opens cases: nobody.
- Case severity/response times: none, as you can’t open cases.
- Technical Account Manager: No.
Developer support plan
With the developer support plan, things get better. We have more benefits, which means that this service is paid.
- Cost: $20/month.
- Tech support: business hours via email.
- Who opens cases: One person only. Can open unlimited cases.
- Case severity/response times: general guidance in less than business 24 hours. System impaired in less than 12 business hours.
- Technical Account Manager: no.
This service is better than the basic plan.
Business support plan
This support plan is even better.
- Cost: $100/month.
- Tech support: 24/7 email & chat & phone.
- Who opens cases: unlimited persons/unlimited cases.
- Case severity/response times: general guidance in less than business 24 hours. System impaired in less than 12 business hours. Production system down in less than one hour.
- Technical Account Manager: no.
The response times are very good with this support plan. If your production system is down, you get an answer in less than one hour. That is admirable.
Enterprise support plan
This plan is the best support plan. However, it comes with a hefty price tag.
- Cost: $15000/month.
- Tech support: 24/7 email & chat & phone.
- Who opens cases: unlimited persons/unlimited cases.
- Case severity/response times: general guidance in less than business 24 hours. System impaired in less than 12 business hours. Production system down in less than one hour. Business-critical system down in less than 15 minutes.
- Technical Account Manager: yes.
The main benefit of this support plan is that you’ll be assigned a technical account manager. This is an Amazon employee who’s solely responsible for your account.
The main key takeaway from the AWS support plans is to remember the case severities and response times. Also, remember which support plan you get a Technical Account Manager with. In the exam, you get a scenario, and you have to choose a support plan.
AWS Marketplace
You can go to the Marketplace and buy a pre-configured WordPress blog that runs on AWS, for example. You can purchase CloudFormation templates, Amazon Machine Images, AWS Web Application Firewall rules, and other items.
Be warned that while the Marketplace service may be free, there may be additional fees related to the software you buy. AWS deducts the charges from your account before paying the vendor.
AWS Consolidated Billing
AWS allows you to create a paying account to aggregate your payments from all of your AWS accounts. To put it another way, you can pay all of your bills from a single account.
Keep in mind that the paying account is separate from all other accounts and has no access to their resources.
What are the advantages of using this service?
- one bill for all your accounts
- it gives a simple way to manage charges
- it offers a volume pricing reduction (the more you use, the less you pay)
- there’s no additional payment to use it
AWS Budgets vs AWS Cost Explorer
In this section, we’ll go through AWS Budgets and AWS Cost Explorer.
AWS Budgets allows you to build custom budgets that warn you when you’re about to go over your budget limit, or when that limit is exceeded.
AWS Cost Explorer is a tool for checking and managing your AWS expenditures over time.
The difference between them is that AWS Budgets enables you to explore costs prior to being charged, whereas AWS Cost Explorer can be used to investigate costs after you’ve been charged.
AWS TCO Calculator
TCO stands for Total Cost of Ownership, and it helps you compare the costs of your AWS cloud infrastructure to the costs of your on-premises infrastructure.
AWS TCO indicates how much you may save by migrating from on-premises to AWS cloud. It only provides an estimate, so the actual expenses may differ.
AWS Trusted Advisor
The AWS Trusted Advisor is a tool that helps users reduce costs, improve performance, and increase security by implementing the recommendations it provides. In other words, the Trusted Advisor provides users with advice on cost optimization, performance, security, fault tolerance, and service limits. It also ensures that users adhere to AWS best practices by providing real-time guidance.
There are three types of trusted advisors: free, and business/enterprise. With the free trusted advisor, you get seven trusted advisor checks, whereas with the business/enterprise advisor, you get all trusted advisor checks.
Resource groups and tagging
Tags are metadata (information about data) and are represented as key–value pairs. These tags are associated with AWS resources and can contain information such as EC2 public and private addresses, ELB port configuration, or RDS database engines.
Resource groups allow you to categorize your resources based on the tags that have been assigned to them. They may include information such as the region, name, or department.
Simply put, tags and resource groups allow you to organize your resources.
What determines the pricing
The final phase is to investigate what factors influence costs for various services such as EC2, Lambda, S3, and others.
What determines EC2 price
- clock hours of server time
- instance type
- number of instances
- load Balancing
- detailed Monitoring
- auto scaling
- elastic IP addresses
- licensing
What determines Lambda price
- compute time (duration)
- number of invocations (requests)
- additional charges if it uses other AWS services or transfers data
What determines EBS price
- volumes (per GB)
- snapshots (per GB)
- data transfer
What determines S3 price
- storage class
- storage
- number of requests
- type of requests
- data transfer
What determines Glacier price
- amount of data stored
- data retrieval time
What determines Snowball price
- service fee per job (50TB – $200, 80TB – $250)
- daily charge (10 days free, then $15 per day)
- data transfer (data transfer into AWS is free, data out is charged)
What determines CloudFront price
- number of requests
- outbound data
- traffic distribution
What determines DynamoDB price
- number of writes
- number of reads
- indexed data storage
What determines RDS price
- clock hours of server time
- database characteristics
- database purchase type
- number of database instances
- provisioned storage
- additional storage
- number of requests
- deployment type
- data transfer
Security in the Cloud
Security is an essential topic, especially in the cloud.
The shared responsibility model
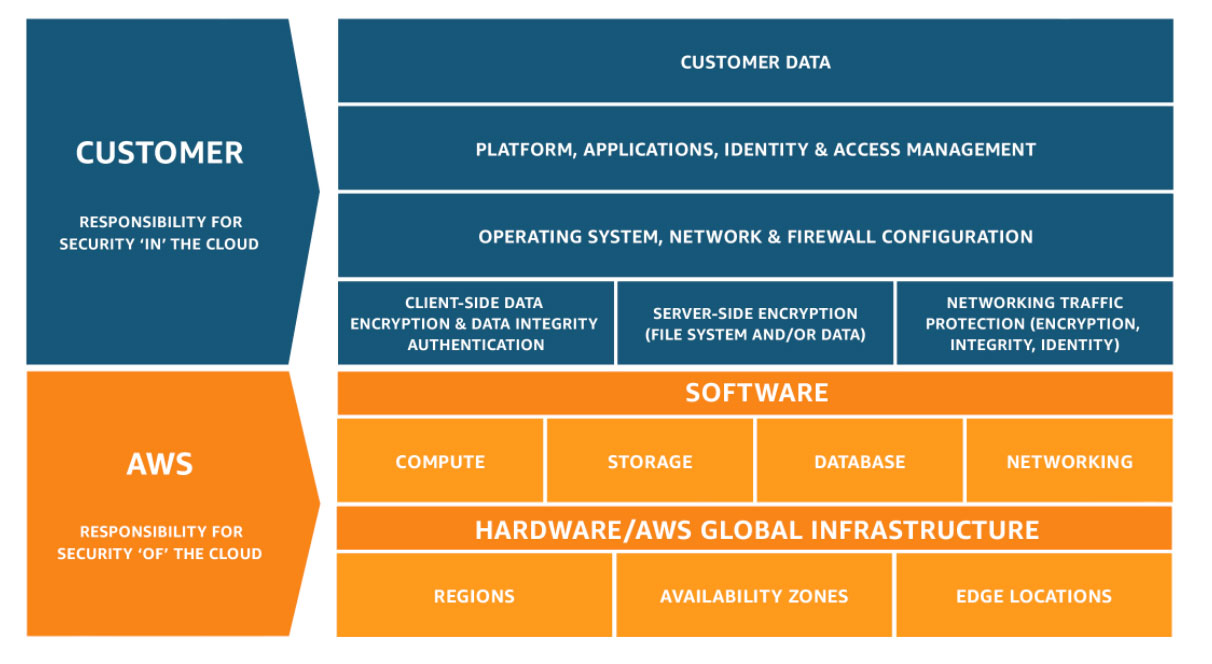
According to the shared responsibility model, Amazon AWS is responsible for security of the cloud, while customers are responsible for security in the cloud.
What exactly do they mean when they say “security of the cloud”? They claim that AWS is responsible for the infrastructure that the services run on. The physical servers, the location where they’re stored, the networking, and the facilities that run the AWS cloud services are all part of the infrastructure.
What do they mean by “security in the cloud”? Customers are responsible for patching their EC2 instances, securing their customer data, ensuring compliance with various legislations, and employing IAM (Identity Access Management) solutions, among other things. The customer’s responsibilities are determined by the AWS service they’re using. You are directly responsible for the data you put on AWS and for enabling monitoring tools.
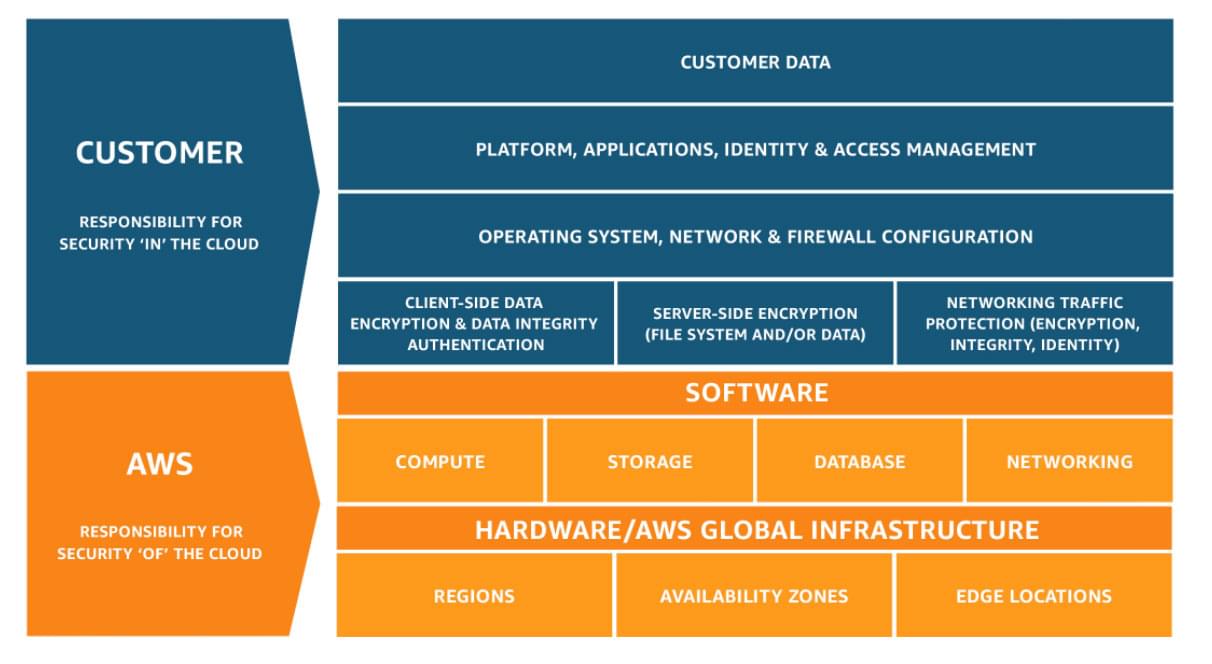
AWS Shared Responsibility Model
The figure above illustrates the shared responsibilities between the customers and AWS.
AWS Compliance Programs: AWS Artifact
First of all, let’s define what compliance programs are. Compliance programs are a set of internal policies and procedures of the company to comply with laws and regulations.
For example, if you’re a hospital that uses AWS services, you must comply with HIPAA. Another example is when you accept credit card payments and must be PCI DSS compliant. We have AWS Artifact to ensure that you’re complying with regulations.
AWS Artifact is a service that provides access to AWS compliance programs. AWS Artifact allows you to find, accept, and manage AWS agreements for a single account or all accounts within your organization. It also allows you to cancel any previously accepted agreement if it is no longer required.
Amazon Inspector
AWS Inspector is an automated security service that evaluates your applications hosted on AWS to improve their security and compliance.
AWS Inspector examines your applications to see if they deviate from existing best practices and if they contain any security flaws. When the assessment is finished, it will generate a report with all the findings organized by severity level.
Its goal is to remove as many security flaws as possible.
AWS WAF (Web Application Firewall)
I’m sure you’ve heard of web attacks like SQL injections, cross-site scripting (XSS), and sensitive data exposure, among other things. The AWS WAF service’s purpose is to protect your applications from common web exploits like those, as well as many others.
This service allows you to filter traffic based on the contents of HTTP requests. That is, depending on the contents of the incoming HTTP requests, you can DENY or ALLOW traffic to your application. You could also use a pre-existing ruleset from the AWS WAF Rules marketplace.
AWS WAF can be attached to CloudFront, your Application Load Balancer, or the Amazon API Gateway.
The cost of AWS WAF is determined by the number of rules you deploy and the number of requests your applications receive.
AWS Shield
AWS WAF doesn’t protect your applications from all attacks and exploits. Applications must also be protected from DDoS attacks. A DDoS attack is an attempt to make an application unresponsive by overwhelming it with requests. The server can’t handle all the requests and the application breaks. As a result, users can no longer access the application.
This is where AWS Shield comes in handy. AWS Shield is a security service that protects AWS-hosted applications. It’s always on and actively scans the applications. Its goal is to reduce downtime and latency by protecting your application against DDoS attacks. When you route your traffic through Route53 or CloudFront, you’re automatically using AWS Shield.
AWS Shield comes in two flavors — basic and advanced. The basic version is free and used by default. The advanced version will cost you $3000 per month, but it’s worth the money. The reason is that you aren’t charged for the charges incurred during the DDoS attack. It doesn’t matter if your resources were maxed out during the attack; you won’t pay anything. That’s not the case with the basic service, and a DDoS attack can result in massive charges.
AWS Shield protects an application against three layers of attack:
- Layer 3: The Network Layer
- Layer 4: The Transport Layer
- Layer 7: The Application Layer
AWS GardDuty
AWS GuardDuty is a threat-detection service that continuously monitors AWS-hosted applications for malicious and suspicious activity, as well as unauthorized behavior.
This service scans CloudTrail, VPC, and DNS logs using machine learning, anomaly detection, and integrated threat intelligence. It will automatically notify you if it discovers any problems.
Amazon Macie
Amazon Macie is a security service that exclusively scans S3 buckets for sensitive information using machine learning and natural language processing. Sensitive information includes information such as credit card numbers, for example.
When it detects anomalies, it generates detailed alerts for you to review.
AWS Athena
AWS Athena allows you to query data in S3 buckets using SQL. It’s a serverless service. Therefore, no setup is required. There’s no need to set up complex Extract/Transform/Load operations.
AWS Athena charges per query or TB scanned.
AWS VPN
The AWS VPN gives you the ability to create a secure and private connection to your AWS network. There are two types of VPNs:
- AWS Site-to-Site VPN. It allows you to connect your on-premise services to the AWS cloud.
- AWS Client VPN. It allows you to connect your machine (such as a user) to the AWS cloud.
Security groups vs NACLs
The security groups act as a firewall at the instance level, and it implicitly denies all traffic. You can create allow rules to allow traffic to your EC2 instances. For example, you can enable HTTP traffic to your EC2 instances through port 80 by adding a specific rule.
The NACLs (Network Access Control Lists) act as a firewall at the subnet level. You can create ALLOW and DENY rules for the subnets. What does that mean? For example, you could restrict access to a specific IP address known for abuse.
Conclusion
Congratulations on taking your first steps towards your cloud computing journey!
After learning about the fundamental cloud concepts and AWS basics, you’re ready to start with the AWS Certified Cloud Practioner certificate.
Frequently Asked Questions (FAQs) about Cloud Computing and AWS Certification
What is the significance of AWS in cloud computing?
Amazon Web Services (AWS) is a comprehensive, evolving cloud computing platform provided by Amazon. It offers a mix of infrastructure as a service (IaaS), platform as a service (PaaS), and packaged software as a service (SaaS) offerings. AWS provides a wide range of services that help in building, deploying, and scaling applications that run on Amazon’s proven computing environment. It has become a significant player in the cloud computing industry due to its robust and flexible capabilities.
How does AWS certification benefit my career?
AWS certification validates your cloud expertise, helping you stand out among IT professionals. It demonstrates your skills and knowledge in the leading cloud computing platform. Certified professionals are in high demand due to the growing reliance on cloud technologies by businesses. AWS certification can open up opportunities for positions like cloud architect, cloud developer, and cloud security specialist, among others.
What are the different types of AWS certifications available?
AWS offers a variety of certifications to validate different levels of expertise. These include Foundational Level (AWS Certified Cloud Practitioner), Associate Level (AWS Certified Solutions Architect, AWS Certified Developer, AWS Certified SysOps Administrator), Professional Level (AWS Certified Solutions Architect, AWS Certified DevOps Engineer), and Specialty Certifications (AWS Certified Advanced Networking, AWS Certified Big Data, AWS Certified Security, AWS Certified Machine Learning, and AWS Certified Alexa Skill Builder).
How can I prepare for AWS certification?
AWS provides a range of resources to help you prepare for certification. These include training courses, whitepapers, FAQs, and exam guides. You can also use AWS Free Tier to get hands-on experience with AWS services. Practice exams are also available to help you gauge your readiness for the actual exam.
What is the cost of AWS certification?
The cost of AWS certification varies depending on the level and specialty. Foundational certification costs $100, Associate-level exams are $150 each, and Professional-level and Specialty exams are $300 each. AWS also offers practice exams at a lower cost.
How long does AWS certification last?
AWS certifications are valid for three years. To maintain your certification status, you must recertify every three years. This ensures that your AWS skills remain current and relevant.
What is the format of AWS certification exams?
AWS certification exams consist of multiple-choice and multiple-answer questions. The exams are administered at testing centers or through online proctoring. The duration of the exams varies depending on the certification level.
Can I retake the AWS certification exam if I fail?
Yes, if you do not pass an AWS certification exam, you can retake it. However, you must wait 14 days before you are eligible to retake the exam. There is no limit to the number of times you can retake an exam.
What are the job prospects after obtaining AWS certification?
AWS certification can significantly enhance your job prospects. Certified professionals are in high demand in the IT industry. Potential job roles include cloud architect, cloud developer, cloud systems engineer, cloud consultant, and more.
How does AWS compare to other cloud service providers?
AWS is considered a leader in the cloud computing industry. It offers a broad set of global cloud-based products including compute, storage, databases, analytics, networking, mobile, developer tools, management tools, IoT, security, and enterprise applications. AWS’s main competitors are Microsoft Azure and Google Cloud, but AWS generally holds a larger market share and has a more extensive global infrastructure.
A developer advocate by day, and a software engineer by night. I enjoy working with Vue, Node.Js, AWS and JavaScript. I also write articles on the same topics.






{kind=link}
{kind=link}