
Key Takeaways
- Nokogiri is a popular Ruby gem used for parsing and extracting data from structured documents such as HTML and XML, with over 37 million downloads at the time of writing.
- Learning to use Nokogiri effectively requires understanding how to select HTML elements, with a significant amount of time spent on finding patterns in the HTML structure of web pages.
- Nokogiri supports two main ways to describe HTML elements: xPath expressions and CSS selectors, both of which require practice to use effectively.
- When using Nokogiri, it’s common to create a new Nokogiri object, try to get HTML elements using a specific xPath/CSS pattern, and then get the text attribute of those elements.
- Nokogiri also provides methods to navigate the Document Object Model (DOM) of a match, such as parent, children, next_sibling, and previous_sibling. It also allows for modification of HTML documents by changing the properties of elements.

Most people get very confused when they try to learn Nokogiri without mastering some fundamentals first. There is a reason for this. Trying to learn Nokogiri without learning the things that make it work is like trying to learn the features of Word without knowing how to type. By the end of this article, you’ll be comfortable with taking a web site and extracting any piece of data from it.
Nokogiri is one of the most popular Ruby gems, with over 37 million downloads at publication time . Just as a comparison, Rails has 47 million downloads currently. My first thought after seeing this was: “Wow, if this gem is so popular, there must be some pretty comprehensive tutorials for it, right?” If you type “rails tutorial” into Google, you’ll get over 280,000 results. A search for “nokogiri tutorial” gives you…less than 3000 results (on the bright side, this number should get bigger after this article is released!).
Nokogiri is a Parser…What?
To make things worse, most tutorials confuse rather than clarify things. When describing Nokogiri, for example, most articles describe it as a “parser”. Most people have no clear definition on what a parser is. To answer this question, take a look at this StackOverflow answer where it is described as “something that turns some kind of data (usually a string) into another kind of data (usually a data structure)”. This makes things a bit clearer now.
Why So Many People Use Nokogiri?
The most common use for a parser like Nokogiri is to extract data from structured documents. Data that matters to you. Examples:
- A list of prices from a price comparison website.
- Search result links from a search engine.
- A list of answers from a Q&A site.
Before answering why would you want to use Nokogiri for this, let’s take a more manual approach. Back in 2009 the SitePoint homepage had a “Topics” tag cloud at the bottom:
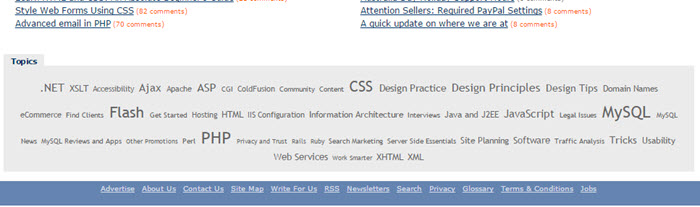
Let’s say I wanted you to write a program to scrape all of the topics inside that cloud (text like Flash, Php, Architecture and so on). What would you do? If I asked you to describe the steps your program would take on a very high-level, it would likely start with two things:
- Download the content of the HTML file (the content will be some text data)
- Extract the relevant data from the content you got in step 1.
You can accomplish step 1 in many ways in Ruby:
- Use
open-urito store the HTML content in a string variable (an example of doing this is provided later) - Use
watir-webdriverto navigate to the web page and get its HTML (a short explanation is provided here)
Step 2 is the tricky one. After you get the actual HTML content of the page, how do you extract the relevant data, like the “Topics” items? You could certainly use regular expressions (after all, the HTML content is just text). But it’s a terrible, terrible idea. HTML text is unlike regular text (an example of regular text is the words you’re reading right now) and there are far better methods to extract relevant data from it.
Most Of Your Time Will Be Spent Finding Patterns
On the journey of extracting data from web pages, you’ll actually spend the least amount of time interacting with Nokogiri. Most of your time will be spent finding a way to select the data you want from a web page. It’s the same principle as regular expressions; you spend most of your time figuring out the actual expression to select the text you want. With a parser like Nokogiri, instead of text, most of your time will be spent figuring out ways to select HTML elements (technically speaking, you’re selecting nodes, and there are 3 types of nodes: element, attribute and text nodes, however, the vast majority of the time you’ll be writing expressions to select element nodes because Nokogiri allows you to easily get the attribute/text node information afterwards. This is a great tutorial if you’re not familiar with nodes).
Most websites have a predictable structure in their HTML code, and that’s to your advantage. All you need to do is describe that structure using xPath/CSS expressions (which we’ll talk about later) and most of your work is done. Think of xPath/CSS expressions as regular expressions for HTML.
Let’s take the SitePoint tag cloud as an example. If you analyze the HTML code using a tool like Chrome inspector (right click on anything in the tag cloud and press “Inspect element”) you’ll notice that the tag cloud itself is a big ul element with a class attribute set to tagcloud. Inside the list, the individual tag names are stored in li elements, and directly inside the li elements you have a elements where the data we want to obtain is stored inside the a element’s as the text.
You could certainly write one complex, giant regular expression to describe this data, but as we saw, it’s a terrible idea. There are 2 main ways Nokogiri supports to describe the HTML elements:
xPath Expressions
Most of the definitions of xPath are quite cryptic. Basically, xPath is a language which locates elements in a document. The document can be either HTML or XML (most xPath tutorials use XML documents in their examples), it doesn’t matter as long as the whole document is a structured collection of elements, the building blocks of HTML/XML.
Previously, we described where to locate our tag cloud items using plain English. We mentioned they are stored in a elements directly inside li elements which are themselves inside a ul element with a class attribute tagcloud. Let’s translate this into xPath:
//ul[@class='tagcloud']/li/a
Confused? Let’s analyze everything step by step:
// - Start anywhere in the HTML document
ul - get a <li>
[@class="tagcloud"] - where the class attribute equals to tagcloud
/li/a - get a <li> element with <a> child.
My advice is always to start your xPath expression with // instead of a single / because a single slash will start you at the root of the document. With a double slash, you’re searching the entire document. If we used a single slash in the above example, we’d need to do something like this:
/html/body/p/ul ..and so on
Spend at least 2 hours PRACTICING xPath. If someone had told me this back when I was starting with Nokogiri, it would have saved me lots of headaches!
How to Practice xPath
The most efficient way to learn xPath is to practice it in an environment that would provide you with instant feedback on whether your xPath expression worked (like Rubular for regular expressions).
My recommendation is to install xPath Helper for Chrome and use it on your favorite websites. Go to the Archive.org site we’ve used through this article and type the expression above to see what you’ll get (the matches have yellow background):
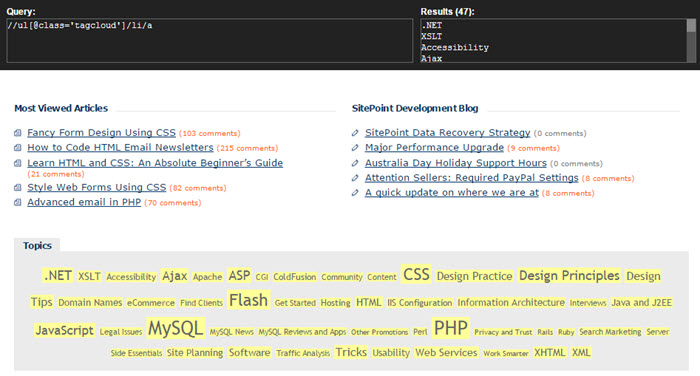
This is also a good resource for practicing xPath on a specific HTML content. As for good tutorials to get you started, see:
-
w3cSchools xPath tutorial (don’t get confused by the fact they work with XML instead of HTML, the fundamental structure of both types of documents is the same).
-
xPath cheat sheet (it also contains notes on how to select elements with CSS selectors).
I cannot emphasize this enough: Spend at least few hours practicing xPath if you want to work with Nokogiri. Learning Nokogiri without first learning how to select HTML elements using something like xPath is like learning Word without knowing how to type! Write your own xPath expressions to select the data you want from your favorite websites. Some browsers have an option to generate xPath expression for you, but they make them more complex than they need to be. Test your own expressions by entering them into xPath helper and checking if they match anything.
CSS Selectors
If you’ve ever done any CSS, you’ll know that a CSS rule consists of a selector (where you give instructions on what element the rule applies to) and a declaration. You can use the selector part alone to select any HTML element in Nokogiri. A good extension like SelectorGadget gives instant feedback for the selectors you type and is your best bet in learning them. For our tag cloud example, here’s the equivalent CSS selector expression, which will select the same elements as the previous xPath expression:
ul.tagcloud > li > a
If you’re clueless about CSS selectors, you probably don’t know CSS neither. Head over to w3c schools and get started (selectors are covered at the beginning after you get through the very basic topics).
Let’s write your first Nokogiri program utilizing selectors.
Your First Nokogiri Program
This program will output all the tag names inside our SitePoint tag cloud:
require 'nokogiri'
require 'open-uri'
html_data = open('http://web.archive.org/web/20090220003702/https://www.sitepoint.com/').read
nokogiri_object = Nokogiri::HTML(html_data)
tagcloud_elements = nokogiri_object.xpath("//ul[@class='tagcloud']/li/a")
tagcloud_elements.each do |tagcloud_element|
puts tagcloud_element.text
end
I’ve deliberately made this program a bit larger, skipping some syntactic sugar, to make it easier to explain.
This line is where EVERYTHING starts:
nokogiri_object = Nokogiri::HTML(html_data)
Nokogiri needs some CONTENT in order to create an object. In our example, that content comes from grabbing the HTML data from an external website. But it doesn’t have to be that way! Let’s say I saved a local copy of the HTML file (you can download it here) and place it inside the same folder as your Ruby program. Then can replace the data where the html_data variable is declared with this:
html_data = File.read('index.html')
Now, run the program. Everything will work as intended. Nokogiri needs some data to get started, and it doesn’t matter whether that data comes from a remote location or your hard disk. You’ll often see something like this:
nokogiri_object = Nokogiri::HTML(open('http://web.archive.org/web/20090220003702/https://www.sitepoint.com/'))
This is a shortcut version where there are several things going on in a single line. The data is being grabbed and loaded immediately into Nokogiri. If you use this, you don’t need the line where html_data is declared.
The following part:
Nokogiri::HTML(html_data)
creates a new Nokogiri OBJECT. You can’t edit a picture in Photoshop unless you first open it inside the program, right? Imagine creating a Nokogiri object the same way: You can’t do stuff with HTML unless you first “load” it into Nokogiri.
Once we have the Nokogiri object in place, we can call methods on it. How? By instructing it WHERE to find the HTML element(s) we need (just like typing a specific word in Notepad to find all occurrences of it, we do the same with xPath/CSS selectors). This is where you’ll spend most of your time, figuring out the “right” selector and so on.
One big mistake I made early on was coming up with an xPath/CSS expression and entering it directly into Nokogiri. Most of the time, my expression was wrong and nothing was selected, resulting in unexpected Ruby errors. The way to avoid this is to first test your xPath/CSS expression using something like the Chrome extension recommended above and see if they produce a match.
The next line is where we ask our Nokogiri object to give the HTML element MATCHES (if any) of the provided expression:
nokogiri_object.xpath("//ul[@class='tagcloud']/li/a")
If you want to use the CSS version, replace it with:
nokogiri_object.css("ul.tagcloud > li > a") # The white space in the CSS selector is optional
Great! We now have a bunch of tag cloud_elements stored as an array. They’re stored as a NodeSet, which is an array of nodes. We talked previously about nodes and my recommendation was to view them as HTML elements for now since 99% of xPath/CSS expressions will be selecting HTML elements. There are variations to select only text/attribute info, but I’d much rather put that logic into Nokogiri than xPath/CSS. The next code snippet shows that.
Once you have the elements stored in an array, loop to get the text inside them. That’s what is happening in the last part:
tagcloud_elements.each do |tagcloud_element|
puts tagcloud_element.text
end
Suppose the requirement changed and, instead of the text, we want to get the value of the href attribute. To do that, change tagcloud_element.text to tagcloud_element['href'] or tagcloud_element.attribute('href'). This is how you get any attribute value. Replace href with any other attribute (id, class, and so on) to get the value of that attribute. If you try to get an attribute that doesn’t exist for the element, you’ll get nil as a result.
Useful Nokogiri Snippets
I’ve spend over 2 hours analyzing code on GitHub that uses Nokogiri and 90% of the time, the same pattern was occurring: People were creating a new Nokogiri object, trying to get HTML elements using a specific xPath/CSS pattern, and then getting the text attribute of those elements. We’ve already covered all of these things. Here are a few other useful things you can do with Nokogiri, once you learn the basics. We’ll use the same tag cloud example I’ve used through the article.
nokogiri_object.at_xpath("//ul[@class='tagcloud']/li/a")
Using at_xpath (or at_css) instead of xpath/css will get you only the first match. If no match is found, nil is returned.
tagcloud_elements.each do |tagcloud_element|
puts tagcloud_element.to_html
end
Get the HTML of the matched HTML elements by using the to_html method.
tagcloud_elements.each do |tagcloud_element|
puts tagcloud_element.parent
puts tagcloud_element.children
puts tagcloud_element.next_sibling
puts tagcloud_element.previous_sibling
end
These are methods to navigate through the Document Object Model of your match.
Now you’re now ready to get started with Nokogiri, without the headaches most beginners have! Feel free to comments below if you have any questions.
Frequently Asked Questions about Nokogiri Fundamentals
How do I install Nokogiri?
Nokogiri is a Ruby gem, so you can install it using the gem command in your terminal. Simply type gem install nokogiri and hit enter. Make sure you have Ruby and RubyGems installed on your system before you try to install Nokogiri.
What is the purpose of Nokogiri?
Nokogiri is a Ruby library used for parsing HTML, XML, SAX, and Reader. It allows you to search, navigate, and manipulate these documents, which is particularly useful when you’re working with web scraping or any task that involves dealing with structured data in these formats.
How do I parse an HTML document with Nokogiri?
To parse an HTML document with Nokogiri, you first need to require the Nokogiri gem in your Ruby script. Then, you can use the Nokogiri::HTML method to parse the HTML. Here’s a basic example:require 'nokogiri'html = "<html><body><h1>Hello World!</h1></body></html>"doc = Nokogiri::HTML(html)
How do I search for specific elements in a document using Nokogiri?
Nokogiri provides several methods to search for specific elements in a document. The css method allows you to find elements using CSS selectors, while the xpath method lets you find elements using XPath expressions. For example, to find all h1 elements in a document, you could use doc.css('h1') or doc.xpath('//h1').
How do I extract text from an element using Nokogiri?
Once you’ve found an element using Nokogiri, you can extract its text using the text method. For example, if node is a Nokogiri element, you can get its text with node.text.
How do I navigate the DOM with Nokogiri?
Nokogiri provides several methods to navigate the DOM. For example, you can use the children method to get an element’s child elements, the parent method to get an element’s parent, and the next and previous methods to get an element’s next and previous siblings.
How do I modify an HTML document with Nokogiri?
Nokogiri allows you to modify HTML documents by changing the properties of elements. For example, you can change the text of an element with node.content = 'New text', or you can add a new attribute with node['new_attribute'] = 'value'.
How do I handle namespaces in XML documents with Nokogiri?
Nokogiri provides the remove_namespaces! method to remove all namespaces from an XML document. If you want to keep the namespaces but still be able to search the document easily, you can use the collect_namespaces method to get a hash of all namespaces, which you can then use in your XPath expressions.
How do I handle errors and exceptions with Nokogiri?
Nokogiri raises exceptions when it encounters errors while parsing a document. You can handle these exceptions using standard Ruby exception handling techniques. For example, you might use a begin/rescue block to catch exceptions and handle them gracefully.
How do I save a modified document with Nokogiri?
After you’ve made changes to a document with Nokogiri, you can save it to a file using the to_html or to_xml methods, depending on whether you’re working with an HTML or XML document. For example, you might use File.write('output.html', doc.to_html) to save an HTML document.