

We take for granted that ruby my_app.rb will execute our code. But how does it work? What’s happening under the hood? Let’s walk through the internals and find out.
Key Takeaways
- The lexer, also known as the tokenizer, is the first step in executing Ruby code. It reads the code and breaks it into ‘tokens’, which are the smallest meaningful units of the code, such as keywords, identifiers, operators, and literals.
- The parser is responsible for organizing the tokens produced by the lexer into an Abstract Syntax Tree (AST). The parser ensures that the tokens follow the correct syntax rules of Ruby, and if it encounters a syntax error, it will stop and report the error.
- The Abstract Syntax Tree (AST) is a tree representation of the abstract syntactic structure of the Ruby code. Each node of the tree denotes a construct occurring in the code. The syntax of the Ruby code is abstracted away in the AST, which allows the compiler to focus on the semantics of the code during the compilation process.
- The Ruby Virtual Machine (RVM) is responsible for executing the bytecode produced by the compiler. The RVM interprets the bytecode and performs the operations specified by the instructions, providing a layer of abstraction between the Ruby code and the underlying hardware.
Lexer
The first port of call is the lexer. The lexer reads your code and breaks it up into ‘tokens’ (for this reason, you may hear Tokenizer and Lexer used interchangeably). What’s a token you ask? Great question! Let’s take a look at an example:
5.times do |x|
puts x
end
When you run ruby my_app.rb, Ruby opens the file and reads in each character sequentially. The first is an integer (5), so the lexer knows that the type it is dealing is an integer object. The 0 is also an integer (interestingly, . also counts as an integer because it could be denoting a floating point) but once it hits the t, the lexer recognizes the numerical part of this process is over, backtracks, and assigns type tINTEGER to the token.
After the ., the lexer encounters times. This is classified as an identifier which is a technical way of denoting a class, variable, or method name. Next, it encounters do which is a reserved word as it is a keyword in the language. How does the lexer differentiate between a reserved word and an identifier? Well, Ruby itself must be aware of what is a keyword and what isn’t, so internally it keeps a list of reserved words. Here is an example – you can see this imported atop the parsing file we’ll dig into in a moment.
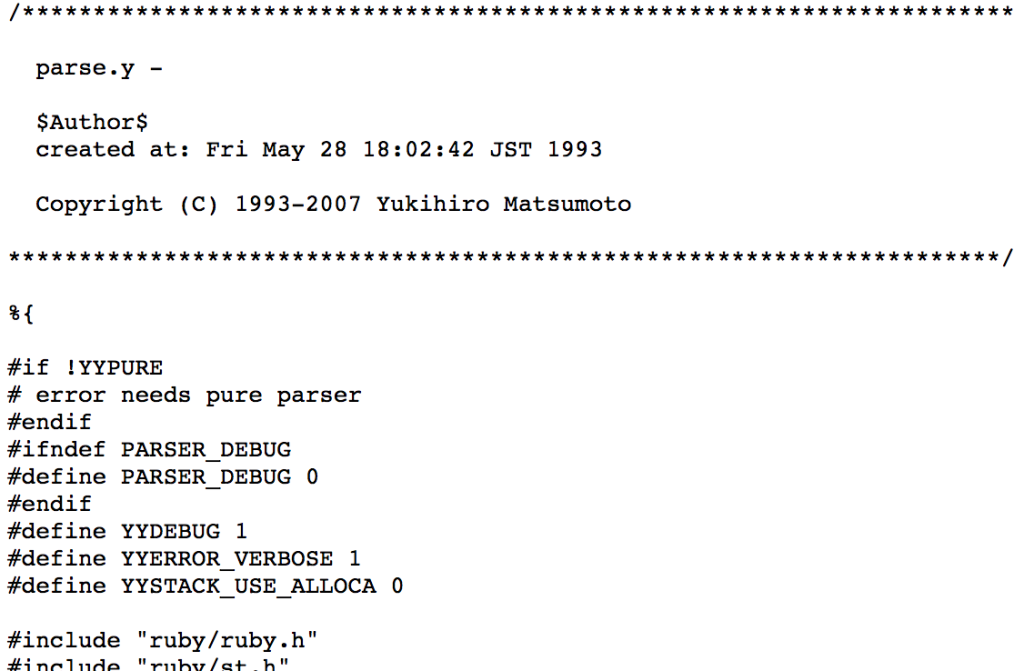
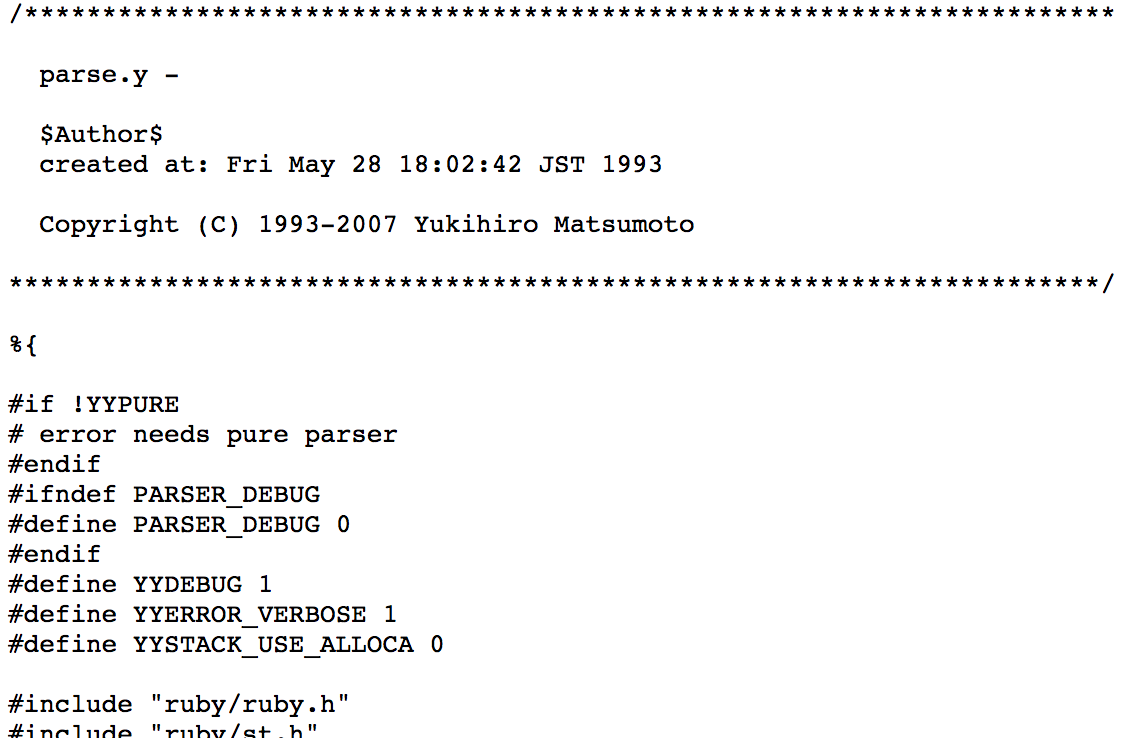
In reality, I am slightly simplifying things. The lexing and parsing process has been streamlined in modern Ruby to be more efficient. What actually happens is that the lexing function is called as part of the parsing process. This is done in a grammar rules file called parse.y – 11,000 lines of complex logic and low level wrangling of your source file. See this 600+ line case statement? That’s your lexer.
Enough theory. Lets get to something practical! Since Ruby 1.9, Ruby ships with an API to interface with its Lexer. It’s called Ripper, and it’s an interesting exercise. So, let’s try it. Fire up the excellent Pry or irb and follow along:
[1] pry(main)> require 'Ripper'
=> true
[2] pry(main)> to_lex = <<STR
[2] pry(main)* 5.times do |n|
[2] pry(main)* puts n end
[2] pry(main)* STR
=> "5.times do |n|\nputs n end\n"
[3] pry(main)> pp Ripper.lex(to_lex)
[[[1, 0], :on_int, "5"],
[[1, 2], :on_period, "."],
[[1, 3], :on_ident, "times"],
[[1, 8], :on_sp, " "],
[[1, 9], :on_kw, "do"],
[[1, 11], :on_sp, " "],
[[1, 12], :on_op, "|"],
[[1, 13], :on_ident, "n"],
[[1, 14], :on_op, "|"],
[[1, 15], :on_ignored_nl, "\n"],
[[2, 0], :on_ident, "puts"],
[[2, 4], :on_sp, " "],
[[2, 5], :on_ident, "n"],
[[2, 6], :on_sp, " "],
[[2, 7], :on_kw, "end"],
[[2, 10], :on_nl, "\n"]]
=> [[[1, 0], :on_int, "5"],
[[1, 2], :on_period, "."],
[[1, 3], :on_ident, "times"],
[[1, 8], :on_sp, " "],
[[1, 9], :on_kw, "do"],
[[1, 11], :on_sp, " "],
[[1, 12], :on_op, "|"],
[[1, 13], :on_ident, "n"],
[[1, 14], :on_op, "|"],
[[1, 15], :on_ignored_nl, "\n"],
[[2, 0], :on_ident, "puts"],
[[2, 4], :on_sp, " "],
[[2, 5], :on_ident, "n"],
[[2, 6], :on_sp, " "],
[[2, 7], :on_kw, "end"],
[[2, 10], :on_nl, "\n"]]
Straightforward enough – we require Ripper, pass in some source as a heredoc and call Ripper’s to_lex method. The output is our tokenizer in action; the numbers on the left are in the format [line, position] and the prefix :on_ denotes the type of token. Let’s look at a similar example:
[5] pry(main)> pp Ripper.lex(to_lex)
[[[1, 0], :on_int, "5"],
[[1, 2], :on_period, "."],
[[1, 3], :on_ident, "times"],
[[1, 8], :on_sp, " "],
[[1, 9], :on_kw, "do"],
[[1, 11], :on_ignored_nl, "\n"],
[[2, 0], :on_ident, "puts"],
[[2, 4], :on_sp, " "],
[[2, 5], :on_ident, "n"],
[[2, 6], :on_sp, " "],
[[2, 7], :on_kw, "end"],
[[2, 10], :on_nl, "\n"]]
=> [[[1, 0], :on_int, "5"],
[[1, 2], :on_period, "."],
[[1, 3], :on_ident, "times"],
[[1, 8], :on_sp, " "],
[[1, 9], :on_kw, "do"],
[[1, 11], :on_ignored_nl, "\n"],
[[2, 0], :on_ident, "puts"],
[[2, 4], :on_sp, " "],
[[2, 5], :on_ident, "n"],
[[2, 6], :on_sp, " "],
[[2, 7], :on_kw, "end"],
[[2, 10], :on_nl, "\n"]]
In this example, I’ve removed the block (|x|) from the heredoc so it reads:
"5.times do\nputs n end\n"
This would be a syntax error within the bounds of the Ruby runtime. The lexer doesn’t care though, because its job is simply to tokenize the input as syntax checks are enforced at a different level. Enter: The Parser
The Parser
We have our tokens, but we still need to execute them. How do we do that? Well, we need something to understand them, and this is the job of a Parser Generator. A Parser Generator takes a series of defined rules (not unlike grammar in language) and checks the input for validity against this. Ruby uses a Parser Generator called Bison and the rules against which the language is defined can be found in the previously mentioned parse.y. This is literally where Ruby as a language is defined.
Parsing Algorithms
A Parsing Algorithm is the process used to parse the tokens. There are many different types, but the one we will be concerning ourselves with is the Look Ahead Lefr-to-right Rightmost Deviation (or LALR for short). My word count constraint won’t permit me to go into the depths of compiler engineering, but here are some resources if you’d like to better acquaint yourself with some of the terminology.
In a nutshell, this is what the parser is doing:
- Moves from left to right processing the tokens
- Takes the current token and pushes it onto a stack
- Checks the grammar rules for a match; adds matching rules to a table of states and removes rules that are no longer possible
- Pushes the next token onto the stack and applies the same process
- Performs a process similar to reduce the stack if it’s applicable
- Looks ahead to check that the next token is compatible with the remaining rules in the state table. If it is, then it continues, and if not then this portion of the parsing is complete and the process is restarted. This is the
LRportion ofLALR. - It repeats this process until the reduced content of the stack matches on a single grammatical rule (or errors out because your syntax is wrong!)
The parser records both a list of applied states and a list of potential states to which it can move. In other words, the parser is essentially just an admittedly complex Finite State Machine which Bison is maintaining for you. If, for some reason, you would like to see Ruby’s state transitions, you can run your program with the -y flag, which prints out debug information:
Starting parse
Entering state 0
Reducing stack by rule 1 (line 939):
lex_state: EXPR_NONE -> EXPR_BEG at line 940
-> $$ = nterm $@1 ()
Stack now 0
Entering state 2
lex_state: EXPR_BEG -> EXPR_END at line 7386
Reading a token: Next token is token tINTEGER ()
Shifting token tINTEGER ()
Entering state 41
...
Hopefully some of this output makes sense now: tINTEGER is the token type the lexer assigned to the token, states are handled by the parser and Reducing and Shifting are the parser traversing the token stream.
What is the result of the parsing? An Abstract Syntax Tree
Abstract Syntax Trees
Lisp) users will be on familiar ground here. The Abstract Syntax Tree (AST) is comprised of a tree of ‘Symbolic Expressions’ (sexpressions or sexprs for short) and it exists as the final stage before our Ruby program is converted to bytecode. The AST lends itself well to this, because the possible paths through the program are all mapped out which makes generating bytecode a derivative excerise. It is at this point in the compilation progress that our program is checked for correctness semantic analysis), and if you were writing a transpiler to change your Ruby code into a different target language (or a templating engine for your Rack app perhaps), this is where you would hook in.
Let’s take a look at our code represented as an AST:
[1] pry(main)> require 'Ripper'
=> true
[2] pry(main)> to_ast = <<STR
[2] pry(main)* 5.times do |n|
[2] pry(main)* puts n end
[2] pry(main)* STR
=> "5.times do |n|\nputs n end\n"
[3] pry(main)> pp Ripper.sexp(to_ast)
This will yield:
[:program,
[[:method_add_block,
[:call, [:@int, "5", [1, 0]], :".", [:@ident, "times", [1, 3]]],
[:do_block, nil, [[:command, [:@ident, "puts", [2, 0]], [:args_add_block, [[:vcall, [:@ident, "n", [2, 5]]]], false]]]]]]]
You can also retrieve this information is by running ruby --dump parsetree your_program.rb.
Similar to before, the numbers are the line/character numbers. This is how your stack trace can tell you exactly where in your source that you made a mistake. ident is of course short for identifier and is the reference to a method or variable’s identifier which we covered in the Lexer section.
From this AST, we can now run our code! Ruby will traverse the AST, converting each node into instructions for its virtual machine (Yet Another Ruby VM, or YARV). There are some slight optimizations at this point, like custom instructions for commonly used operations such as addition. How YARV works is an entire post in itselfe. Suffice to say, Ruby’s pleasing syntax has been changed into code our computers understand and runs as written. The build process really isn’t as complicated as it may initially appear. It’s simply a pipeline that takes some input, applies a set of rules and returns an object – in this case, executable code that we can take for granted as working.
Frequently Asked Questions (FAQs) about Lexers, Parsers, and ASTs in Ruby
What is the difference between a lexer and a parser in Ruby?
In Ruby, a lexer and a parser play different roles in the process of interpreting code. A lexer, also known as a tokenizer, breaks down the code into individual pieces known as tokens. These tokens are the smallest meaningful units of the code, such as keywords, identifiers, operators, and literals. On the other hand, a parser takes these tokens and organizes them into a structure that represents the logical syntax of the code. This structure is known as an Abstract Syntax Tree (AST). The parser ensures that the code follows the correct syntax rules of Ruby.
How does Ruby execute code?
Ruby executes code through a series of steps. First, the lexer breaks down the code into tokens. Then, the parser organizes these tokens into an Abstract Syntax Tree (AST). The AST represents the logical structure of the code. After that, the AST is converted into bytecode by the compiler. Finally, the Ruby Virtual Machine (RVM) executes the bytecode.
What is an Abstract Syntax Tree (AST) in Ruby?
An Abstract Syntax Tree (AST) in Ruby is a tree representation of the abstract syntactic structure of the Ruby code. Each node of the tree denotes a construct occurring in the code. The syntax of the Ruby code is abstracted away in the AST, which allows the compiler to focus on the semantics of the code during the compilation process.
How does a lexer work in Ruby?
A lexer in Ruby works by scanning the Ruby code from left to right and breaking it down into individual tokens. These tokens represent the smallest meaningful units of the code. The lexer categorizes each token based on its type, such as keyword, identifier, operator, or literal.
How does a parser work in Ruby?
A parser in Ruby works by taking the tokens produced by the lexer and organizing them into an Abstract Syntax Tree (AST). The parser ensures that the tokens follow the correct syntax rules of Ruby. If the parser encounters a syntax error, it will stop and report the error.
What is bytecode in Ruby?
Bytecode in Ruby is a low-level representation of the Ruby code that is produced by the compiler. The bytecode is a series of instructions that can be executed by the Ruby Virtual Machine (RVM). The bytecode is platform-independent, which means it can be executed on any machine that has a Ruby interpreter.
What is the role of the Ruby Virtual Machine (RVM)?
The Ruby Virtual Machine (RVM) is responsible for executing the bytecode produced by the compiler. The RVM interprets the bytecode and performs the operations specified by the instructions. The RVM provides a layer of abstraction between the Ruby code and the underlying hardware, allowing the Ruby code to be executed on any machine that has a Ruby interpreter.
What is a token in Ruby?
A token in Ruby is the smallest meaningful unit of the Ruby code. Tokens are produced by the lexer during the process of breaking down the code. Tokens can be of various types, such as keywords, identifiers, operators, and literals.
What happens if the parser encounters a syntax error in Ruby?
If the parser encounters a syntax error in Ruby, it will stop and report the error. The parser checks the syntax of the Ruby code and ensures that it follows the correct syntax rules. If the code does not follow these rules, the parser will not be able to construct a valid Abstract Syntax Tree (AST), and a syntax error will occur.
Can I write my own lexer and parser in Ruby?
Yes, it is possible to write your own lexer and parser in Ruby. However, it requires a deep understanding of the Ruby syntax and the principles of lexical analysis and parsing. There are also libraries available in Ruby that can help with this task, such as the Racc library for writing parsers.