

Key Takeaways
- Puppeteer is a Node library developed by the team behind Google Chrome, providing a high-level API to control Chrome or Chromium over the DevTools Protocol. It allows users to perform a variety of tasks such as web scraping, generating screenshots or PDFs of websites, crawling single-page applications, and automating form submissions or performance analysis.
- To use Puppeteer, users need a basic knowledge of JavaScript, ES6+, and Node.js, and the latest version of Node.js installed. Yarn is used throughout the tutorial, and Puppeteer is compatible with at least Node v6.4.0. The library can be installed through the command ‘yarn add puppeteer’ in the terminal.
- The tutorial provides practical examples of using Puppeteer, including generating a screenshot of a website, creating a PDF of a website, and automating a sign-in process to a website. The author emphasizes the simplicity and ease-of-use of Puppeteer’s API, as well as its suitability for automating repetitive tasks.
Browser developer tools provide an amazing array of options for delving under the hood of websites and web apps. These capabilities can be further enhanced and automated by third-party tools. In this article, we’ll look at Puppeteer, a Node-based library for use with Chrome/Chromium.
The puppeteer website describes Puppeteer as
a Node library which provides a high-level API to control Chrome or Chromium over the DevTools Protocol. Puppeteer runs headless by default, but can be configured to run full (non-headless) Chrome or Chromium.
Puppeteer is made by the team behind Google Chrome, so you can be pretty sure it will be well maintained. It lets us perform common actions on the Chromium browser, programmatically through JavaScript, via a simple and easy-to-use API.
With Puppeteer, you can:
- scrape websites
- generate screenshots of websites including SVG and Canvas
- create PDFs of websites
- crawl an SPA (single-page application)
- access web pages and extract information using the standard DOM API
- generate pre-rendered content — that is, server-side rendering
- automate form submission
- automate performance analysis
- automate UI testing like Cypress
- test chrome extensions
Puppeteer does nothing new that Selenium, PhantomJS (which is now deprecated), and the like do, but it provides a simple and easy-to-use API and provides a great abstraction so we don’t have to worry about the nitty-gritty details when dealing with it.
It’s also actively maintained so we get all the new features of ECMAScript as Chromium supports it.
Prerequisites
For this tutorial, you need a basic knowledge of JavaScript, ES6+ and Node.js.
You must also have installed the latest version of Node.js.
We’ll be using yarn throughout this tutorial. If you don’t have yarn already installed, install it from here.
To make sure we’re on the same page, these are the versions used in this tutorial:
- Node 12.12.0
- yarn 1.19.1
- puppeteer 2.0.0
Installation
To use Puppeteer in your project, run the following command in the terminal:
$ yarn add puppeteer
Note: when you install Puppeteer, it downloads a recent version of Chromium (~170MB macOS, ~282MB Linux, ~280MB Win) that is guaranteed to work with the API. To skip the download, see Environment variables.
If you don’t need to download Chromium, then you can install puppeteer-core:
$ yarn add puppeteer-core
puppeteer-core is intended to be a lightweight version of Puppeteer for launching an existing browser installation or for connecting to a remote one. Be sure that the version of puppeteer-core you install is compatible with the browser you intend to connect to.
Note: puppeteer-core is only published from version 1.7.0.
Usage
Puppeteer requires at least Node v6.4.0, but we’re going to use async/await, which is only supported in Node v7.6.0 or greater, so make sure to update your Node.js to the latest version to get all the goodies.
Let’s dive into some practical examples using Puppeteer. In this tutorial, we’ll be:
- generating a screenshot of Unsplash using Puppeteer
- creating a PDF of Hacker News using Puppeteer
- signing in to Facebook using Puppeteer
1. Generate a Screenshot of Unsplash using Puppeteer
It’s really easy to do this with Puppeteer. Go ahead and create a screenshot.js file in the root of your project. Then paste in the following code:
const puppeteer = require('puppeteer')
const main = async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://unsplash.com')
await page.screenshot({ path: 'unsplash.png' })
await browser.close()
}
main()
Firstly, we require the puppeteer package. Then we call the launch method on it that initializes the instance. This method is asynchronous as it returns a Promise. So we await for it to get the browser instance.
Then we call newPage on it and go to Unsplash and take a screenshot of it and save the screenshot as unsplash.png.
Now go ahead and run the above code in the terminal by typing:
$ node screenshot
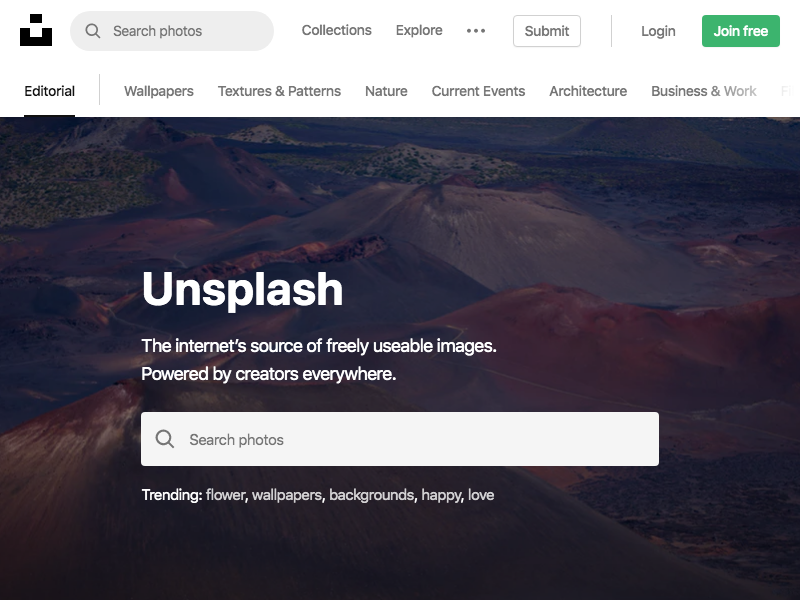
Now after 5–10 seconds you’ll see an unsplash.png file in your project that contains the screenshot of Unsplash. Notice that the viewport is set to 800px x 600px as Puppeteer sets this as the initial page size, which defines the screenshot size. The page size can be customized with Page.setViewport().
Let’s change the viewport to be 1920px x 1080px. Insert the following code before the goto method:
await page.setViewport({
width: 1920,
height: 1080,
deviceScaleFactor: 1,
})
Now go ahead and also change the filename from unsplash.png to unsplash2.png in the screenshot method like so:
await page.screenshot({ path: 'unsplash2.png' })
The whole screenshot.js file should now look like this:
const puppeteer = require('puppeteer')
const main = async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.setViewport({
width: 1920,
height: 1080,
deviceScaleFactor: 1,
})
await page.goto('https://unsplash.com')
await page.screenshot({ path: 'unsplash2.png' })
await browser.close()
}
main()
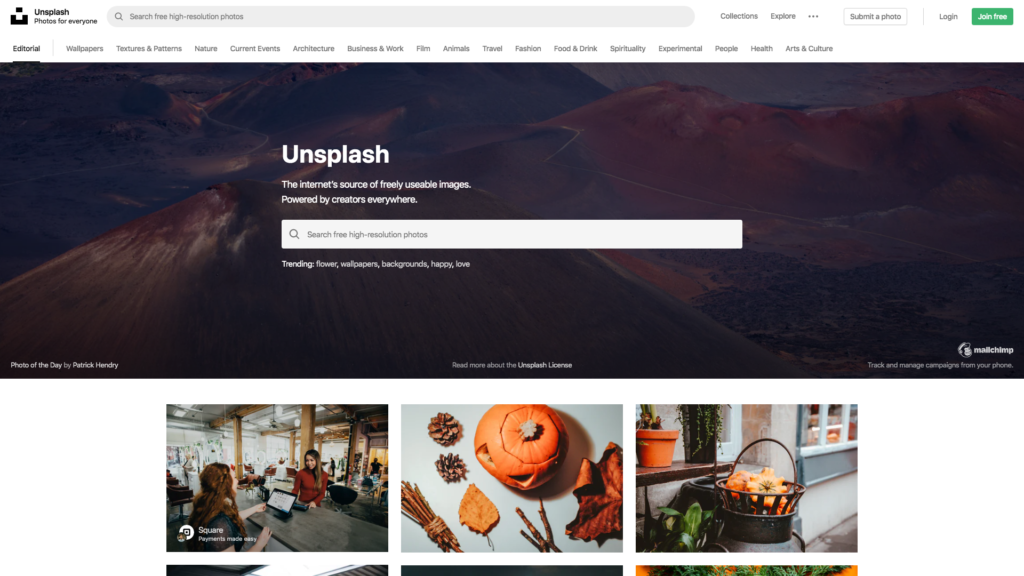
2. Create PDF of Hacker News using Puppeteer
Now create a file named pdf.js and paste the following code into it:
const puppeteer = require('puppeteer')
const main = async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.goto('https://news.ycombinator.com', { waitUntil: 'networkidle2' })
await page.pdf({ path: 'hn.pdf', format: 'A4' })
await browser.close()
}
main()
We’ve only changed two lines from the screenshot code.
Firstly, we’ve replaced the URL with Hacker News and then added networkidle2:
await page.goto('https://news.ycombinator.com', { waitUntil: 'networkidle2' })
networkidle2 comes in handy for pages that do long polling or any other side activity and considers navigation to be finished when there are no more than two network connections for at least 500ms.
Then we called the pdf method to create a PDf and called it hn.pdf and we formatted it to be A4 size:
await page.pdf({ path: 'hn.pdf', format: 'A4' })
That’s it. We can now run the file to generate a PDF of Hacker News. Let’s go ahead and run the following command in the terminal:
$ node pdf
This will generate a PDF file called hn.pdf in the root directory of the project in A4 size.
3. Sign In to Facebook Using Puppeteer
Create a new file called signin.js with the following code:
const puppeteer = require('puppeteer')
const SECRET_EMAIL = 'example@gmail.com'
const SECRET_PASSWORD = 'secretpass123'
const main = async () => {
const browser = await puppeteer.launch({
headless: false,
})
const page = await browser.newPage()
await page.goto('https://facebook.com', { waitUntil: 'networkidle2' })
await page.waitForSelector('#login_form')
await page.type('input#email', SECRET_EMAIL)
await page.type('input#pass', SECRET_PASSWORD)
await page.click('#loginbutton')
// await browser.close()
}
main()
We’ve created two variables, SECRET_EMAIL and SECRET_PASSWORD, which should be replaced by your email and password of Facebook.
We then launch the browser and set headless mode to false to launch a full version of Chromium browser.
Then we go to Facebook and wait until everything is loaded.
On Facebook, there’s a #login_form selector that can be accessed via DevTools. This selector contains the login form, so we wait for it using waitForSelector method.
Then we have to type our email and password, so we grab the selectors input#email and input#pass from DevTools and pass in our SECRET_EMAIL and SECRET_PASSWORD.
After that, we click the #loginbutton to log in to Facebook.
The last line is commented out so that we see the whole process of typing email and password and clicking the login button.
Go ahead and run the code by typing the following in the terminal:
$ node signin
This will launch a whole Chromium browser and then log in to Facebook.
Conclusion
In this tutorial, we made a project that creates a screenshot of any given page within a specified viewport. We also built a project where we can create a PDF of any website. We then programmatically managed to sign in to Facebook.
Puppeteer recently released version 2, and it’s a nice piece of software to automate trivial tasks with a simple and easy-to-use API.
You can learn more about Puppeteer on its official website. The docs are very good, with tons of examples, and everything is well documented.
Now go ahead and automate boring tasks in your day-to-day life with Puppeteer.
FAQs About Puppeteer
Puppeteer is a Node library developed by Google that provides a high-level API to control headless browsers or full browsers using the Chrome or Chromium DevTools Protocol. It’s commonly used for web scraping, automating browser tasks, taking screenshots, and generating PDFs.
A headless browser is a browser without a graphical user interface. In Puppeteer, a headless browser allows for automated browser actions without displaying the browser window, making it suitable for server-side tasks and automation where user interaction is not required.
By default, Puppeteer is designed to work with Chrome or Chromium. However, there are efforts and third-party tools that enable Puppeteer to work with other browsers like Firefox. Keep in mind that the API and features may vary when using Puppeteer with browsers other than Chrome or Chromium.
Puppeteer is commonly used for web scraping, automated testing of web pages, taking screenshots, generating PDFs, performance testing, and automating repetitive browser tasks.
Puppeteer can be used for web scraping, but developers should be mindful of ethical considerations and website terms of service. Excessive or aggressive web scraping can impact server loads and violate terms of use. Always ensure compliance with relevant policies when using Puppeteer for scraping.