

Key Takeaways
- Java Util Logging, Log4j 2.x, and Logback are the primary Java logging frameworks evaluated for performance, each offering distinct features and configurations.
- Performance benchmarks indicate that Java Util Logging is not recommendable due to its lack of a buffered handler, which significantly impacts its performance.
- Log4j 2.x’s synchronous appender outperforms other frameworks in terms of speed, making it a preferable choice for scenarios requiring high logging throughput.
- Logback, while slightly behind Log4j in performance, offers a unique logger name abbreviation feature which can be advantageous in specific logging contexts.
- The use of asynchronous loggers, designed for lower latency in infrequent logging scenarios, does not deliver higher throughput under continuous heavy logging loads compared to synchronous loggers.
- Effective logging configuration, including the use of buffered loggers, is crucial for optimizing performance, with a recommendation to flush logs at least every 100ms to balance real-time log monitoring and system performance.
Table of Contents
- Logging Shims
- Logging Frameworks
- Logging Framework Performance
- Structure of the Benchmark
- The Point of the Strawman
- Benchmark Results
- Logging to Nowhere
- Java Util Logging Output Format
- Log4j 2.x Default Output Format
- Logback Default Output Format
- A Message to Logging Framework Developers
- Conclusions
- Comments
Java is blessed with three big Java logging frameworks: Java Util Logging, Log4j 2, and Logback. When picking one for your project, did you ever wonder about their performance? After all, it would be silly to slow down the application just because you picked a sluggish logging framework or a suboptimal configuration.
Whenever the subject of logging in Java comes up on Twitter, you can be sure you’ll be in for a lot of ranting. This is perhaps best summarised by this tweet from Dan Allen:
The logging situation in Java is still so screwed up. Millions of dollars are lost on this ridiculous problem.
— Dan Allen 🇺🇦 ☮️ (@mojavelinux) January 28, 2017
There are actually quite a lot of people who are “lucky” enough to remain isolated from the question of logging in Java:
- Junior developers are typically not empowered with making this type of choice.
- Intermediate developers are often working on a code base where the choice has already been made.
- Senior developers can have the choice forced on them by their CTO or some other external decision maker.
Sooner or later, however, you will reach the point where you have to make the choice of logging framework. In 2017 we can break down the choice into 4 options:
- Refuse to make a choice and use a logging shim
- Use Java Util Logging.
- Use Log4j 2.x
- Use Logback
Logging Shims
If you are…
- developing an API
- developing a shared library
- developing an application that will be deployed to an execution environment that is not your responsibility (for example a
.waror.earfile that gets deployed in a shared application container)
… then the choice of logging framework is not your responsibility and you should use a logging shim.
You would be forgiven for thinking that there is a choice:
- Apache Commons Logging
- SLF4J
But the Apache Commons logging API is so basic and restricted that the only recommendation is Do not use unless you like to write your logging statements like this:
if (log.isDebugEnabled()) {
log.debug("Applying widget id " + id + " flange color " + color);
}
Recommendation: SLF4J
Logging Frameworks
If you are developing a microservice, or some other application where you have control over the execution environment, you are probably responsible for selecting the logging framework. There may be cases where you decide to defer picking one by using a logging shim, but you are still going to have to make a choice eventually.
Changing from one logging framework to another is typically a simple search and replace, or worst case a more advanced “structural” search and replace available in more advanced IDEs. If logging performance is important to you, the logging framework’s idiomatic logging API will always out-perform a shim and given that the cost of switching is lower than with other APIs, you are probably better off coding direct to the logging framework.
I should also mention that there is a philosophical difference between the frameworks:
- Java Util Logging comes from the school of thought that logging should be the exception and not the norm.
- Log4j 2.x and Logback both show their shared heritage, and place importance on performance when logging
All three frameworks are hierarchical logging frameworks that allow for runtime modification of configuration and various output destinations. To confuse users, the different frameworks sometimes use different terminology for the same things, though:
HandlervsAppender– these are the same thing, putting the log message into the log file.FormattervsLayout– these are the same thing, responsible for formatting the log message into a specific layout.
We could make a feature comparison, but in my opinion the only feature worth differentiating on is mapped diagnostic contexts (MDCs), as all other feature differences can be coded around relatively easily. Mapped diagnostic contexts provide a way to enhance the log messages with information that would not be accessible to the code where the logging actually occurs. For example, a web application might inject the requesting user and some other details of a request into the MDC, which allows any log statements on the request handling thread to include those details.
There are some cases where a lack of MDC support may not be as important, for example:
- In a microservice architecture, there is no shared JVM so you have to build equivalent functionality into the service APIs, typically by explicitly passing the state that would be in the MDC.
- In a single user application, there typically is only ever one context and typically not much concurrency, so there is less need for MDCs.
We could compare based on ease of configuration. Sadly, all three are equally bad at documenting how to configure logging output. None provide a sample “best-practice” configuration file for common use cases:
- Sending logging to a log file, with rotation
- Sending logging to operating system level logging systems, e.g. syslog, windows event log, etc
The information is typically there, but hidden in JavaDocs and couched in such a way as to leave the software engineer or operations engineer wondering if the configuration is compromising the application.
This leaves us with performance.
Logging Framework Performance
Ok, let’s benchmark the different logging frameworks then. There is a lot that you can mess up when trying to write micro-benchmarks in Java. The wise Java engineer knows to use JMH for micro-benchmarking.
One of the things that is often missed in logging benchmarks is the cost of not logging. In the ideal world, a logging statement for a logger that is not going to log should be completely eliminated from the execution code path. One of the features of a good logging framework is the ability to change logging levels of a running application. In reality we need at least a periodical check for a change in the logger’s level, so we cannot have the logging statement completely eliminated.
Another aspect of logging benchmarks, is selective configuration. Each of the different logging frameworks come with their own different default output configuration. If we do not configure all the loggers to use the same output format, we will not be comparing like with like. Conversely, some logging frameworks may have special case optimisations that work for specific logging formats which could distort the results.
So here are the cases we want to test:
- logging configured to not log
- logging configured to output in the Java Util Logging default style
- logging configured to output in the Log4j 2.x default style
- logging configured to output in the Logback default style
We will just look at the performance writing the logs to a rolling log file. We could test performance of things like syslog handlers / appenders or logging to the console, but the risk there is that there is some additional side-effects from the external system (syslogd or the terminal) may compromise the test.
The source code for the benchmarks is available on GitHub.
Structure of the Benchmark
Each benchmark is essentially the following:
@State(Scope.Thread)
public class LoggingBenchmark {
private static final Logger LOGGER = ...;
private int i;
@Benchmark
public void benchmark() {
LOGGER.info("Simple {} Param String", new Integer(i++));
}
}
- The reference to the logger is stored as a static final field.
- Each thread has independent state
i. This is to prevent false sharing accessing the state field. - In order to prevent optimization of the string concatenation, the parameter is mutated with each invocation of the benchmark method.
- The construction with
new Integer(i++)is necessary to counteract the autoboxing cache. Becauseiis very rarely in the range-128..127, we need to use explicit boxing as the implicitInteger.valueOf(int)would pollute the benchmark results with checking the cache and we expect a cache miss.
JMH provides a number of different modes to run in, the two we are most interested in are:
- Throughput mode – which measures how many calls to the target method can be completed per second. Higher is better.
- Sample mode – which measures how long each call takes to execute (including percentiles). Lower is better.
The Point of the Strawman
When benchmarking and comparing differences between vendors it can sometimes be helpful to know how far performance can be pushed. For this reason, my benchmarks contain a number of different strawman implementations. In the graphs that follow, I have selected the best strawman for each scenario. In providing the strawman, my aim is not to attack the performance of the different vendor solutions. My aim is to provide a context within which we can compare the performance of the different logging frameworks.
My strawman shows as high a performance as I could achieve to perform the equivalent operation. The cost of this higher performance is the loss of general utility. By providing the strawman, however, we can see what the test machine is capable of.
By way of an example, the strawman for logging to nowhere does the following:
- Sets up a background daemon thread that wakes up once every second and sets an
enabledfield based on the presence of a file that does not exist. - Each log statement checks the
enabledfield and only iftruewill it proceed to log.
It would be easy to just have an empty log statement that didn’t even check an enabled field, but the JVM would inline that empty method and completely remove the logging. If we didn’t have the background thread periodically writing to the field (the fact that it will always write false is unknowable to the JVM) then the JVM could conclude that nobody will ever write to that field and inline the resulting constant condition. Where the strawman can gain performance, for this case, is by dropping hierarchical configuration.
The other strawman implementations all have to write the same format log messages and the performance gains are from hard-coding the log formatter / layout for things like the date formatting and string concatenation. The strawmen all parse the parameterized logging message and format that on the fly, but without some of the safety checks of the frameworks.

Benchmark Results
The following versions were tested:
- Java 8 build 121
- Apache Log4J version 2.7
- Logback version 1.2.1
Logging to Nowhere
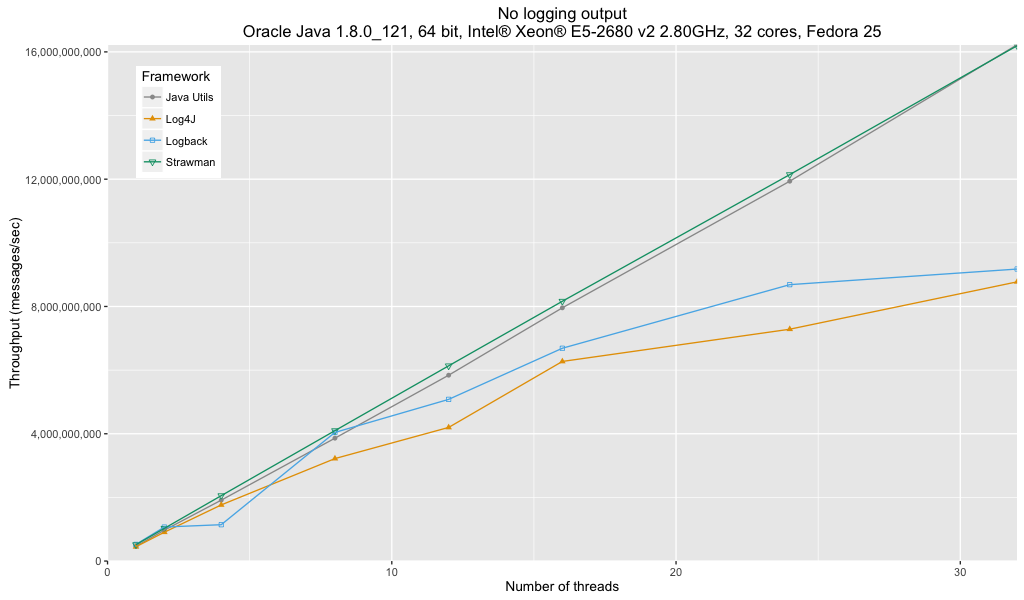
Looking at the throughput graph, we might think that we have found an immediate winner in Java Util Logging. Certainly the throughput seems to scale linear with the number of threads, just behind the strawman while the throughput of Log4J and Logback seems to drop off with higher numbers of threads. However, this is an artifact of the throughput benchmarking mode of JMH.
The true comparison of the frameworks is revealed by looking at the amount of time that it takes for the benchmark method to run, rather than the number of operations per second.
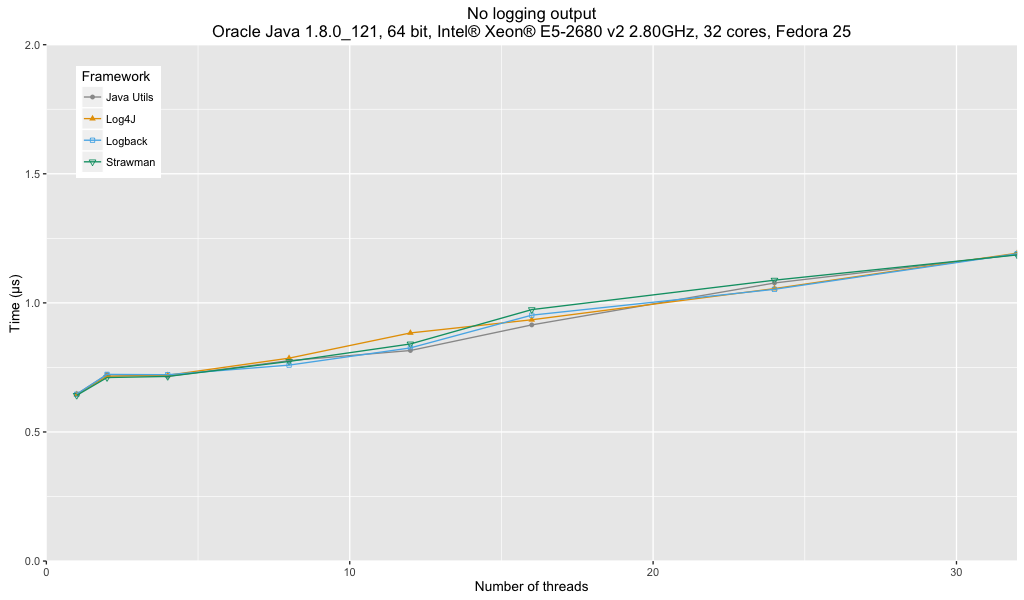
These results show virtually no difference in the performance of all three frameworks.
Java Util Logging Output Format
One of the interesting factors of Java Util Logging’s default format is that it includes detail of the source class and method. If you want to get the details of the source class and method, prior to Java 9 there is one and only one way: create an exception and walk the stack trace. It will be interesting to see if Java 9’s new stack walker API can improve performance.
However, at the time of writing, neither Log4J nor Logback have integrated the pre-release stack walker API, so it would not be fair to compare pre-release builds of Java 9 with the other frameworks.
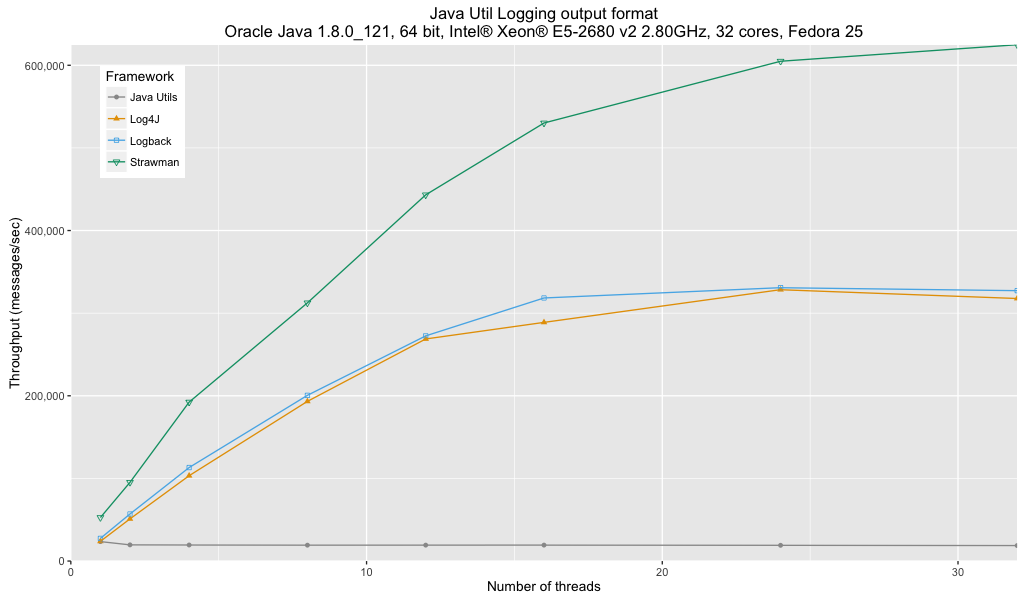
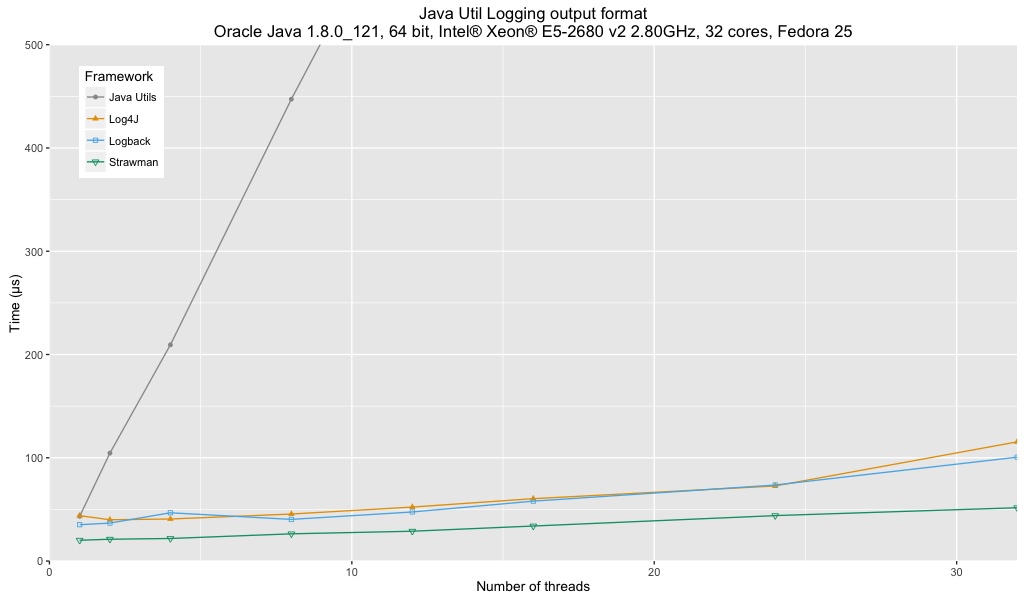
Analysis:
- Java Util Logging performance is significantly affected by the lack of a buffered handler.
- There is no major difference between Log4j and Logback.
- Both Log4j and Logback show about 50% of the performance of my special case optimized strawman.
Based on performance, Java Util Logging cannot be recommended for this output format. There is no significant difference between Log4j or Logback in terms of performance.
Careful analysis would be needed to determine whether the performance difference with respect to the strawman is a result of the general utility nature of the logging frameworks or a potential source of further optimisations that has been missed.
Log4j 2.x Default Output Format
Log4j’s is the one format that all logging frameworks can be easily configured to provide. We use it to also compare the synchronous and asynchronous appenders.
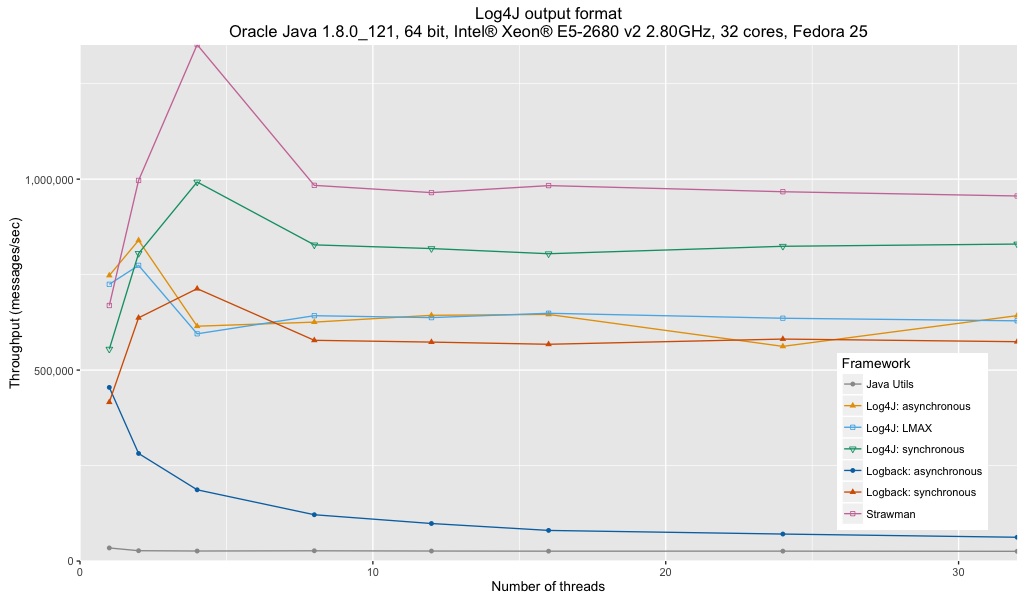
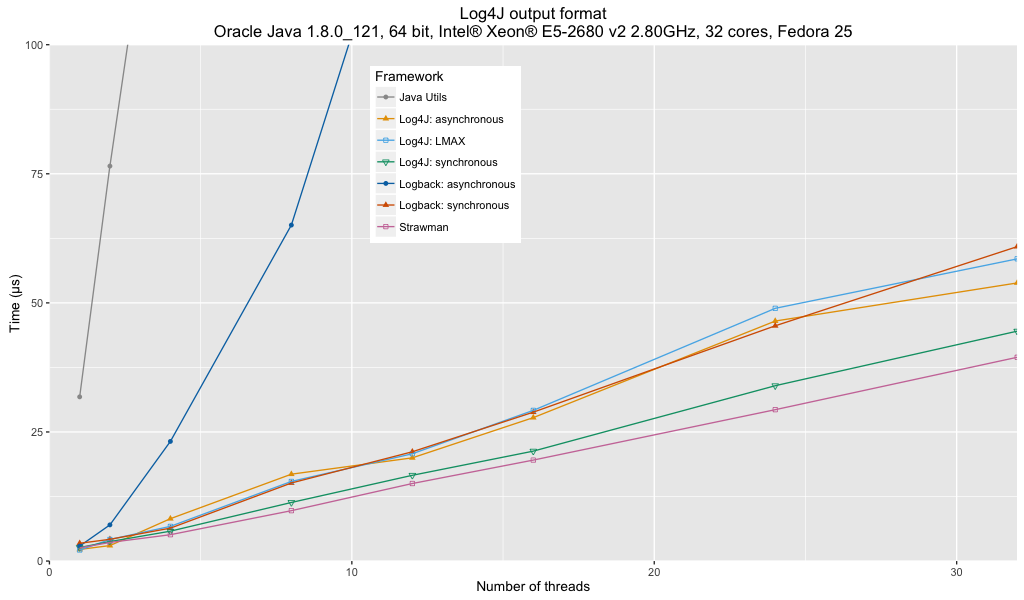
Analysis:
- Java Util Logging performance is significantly affected by the lack of a buffered handler.
- Logback’s asynchronous appender is not recommended for multi-threaded logging due to an unresolved bug in the current implementation.
- Log4j’s synchronous appender is the fastest of all the frameworks.
- Log4j’s asynchronous appenders (either with or without LMAX) are about the same throughput as Logback’s synchronous appender.
- My synchronous strawman is about 10% faster than Log4j’s synchronous appender. I suspect that this is the cost of general utility.
Logback Default Output Format
This format has a subtle quirk. There is an abbreviation algorithm applied to the name of the logger. Only Logback has native support for this format.
This provides us with the opportunity to use a custom Java Util Logging formatter that will allow us to see where some of the issues with Java Util Logging performance originate from. In order to maximize the utility of the comparison we also include results of the other frameworks when using an unbuffered appender.
As Log4J does not support Logback’s style of abbreviating logger names, I have substituted the right-most 36 characters of the logger name in the Apache Log4J configuration.
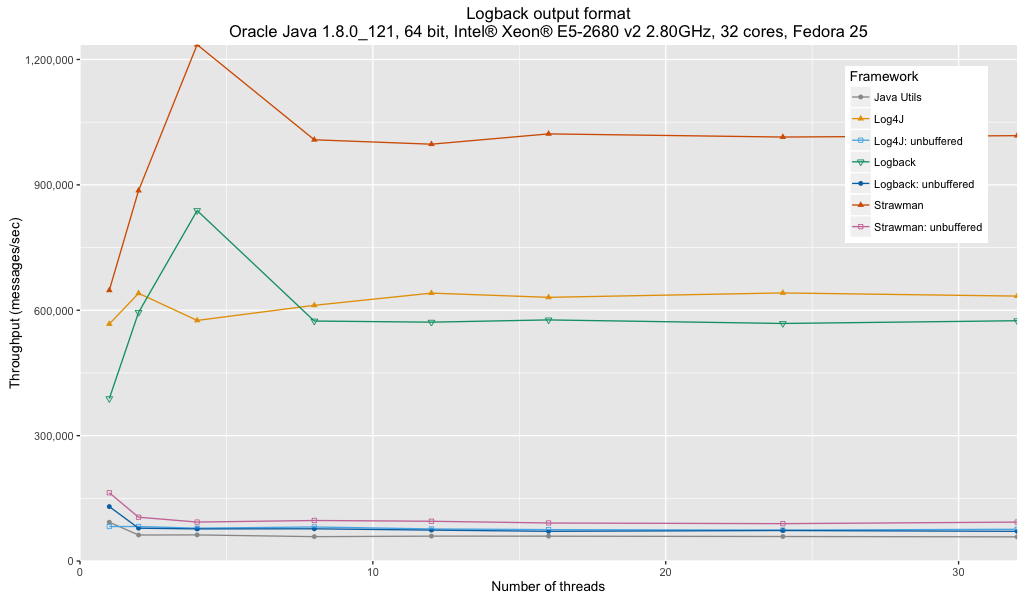
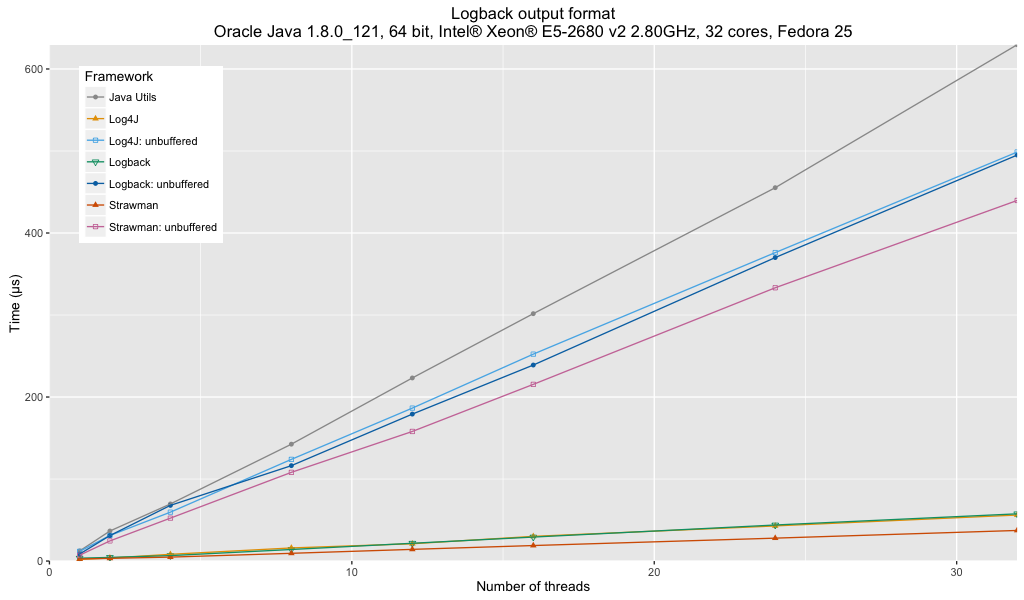
Analysis:
- Java Util Logging is using a custom format that is more optimized and unwinds some of the issues with Java Util Logging, bringing it nearer to the performance of the other frameworks when unbuffered. The performance is still behind that of the other frameworks.
- Use of unbuffered handlers / appenders have a significant effect on logger throughput. When logging performance is critical, buffered loggers are the clear winner.
- Log4j’s performance is slightly ahead of Logback’s but this could be due to the simpler logger name formatting that Log4j is configured with.
- The performance of Log4j, Logback and strawman buffered loggers are comparable with the Log4j format results.
A Message to Logging Framework Developers
The real challenge with logging in Java is in configuring these frameworks for your use-case. It took a lot of digging, research and experimentation to get what I believe to be a performant and fair set of configurations to use as a basis for comparison. I am quite sure that some of the developers of logging frameworks will take issue with some aspects of my configurations.
If we want to move logging in Java forward I would recommend first and foremost a concerted effort on documentation. Apart from Java Util Logging, performance is reasonably close to my strawman implementations which either indicates that the Java logging frameworks are very performant for general utility code or I cannot write fast single-purpose code.
Logging frameworks should provide significantly better documentation on how to configure logging. Ideally, they should provide examples of the best configurations for logging to:
- the console
- a rolling size limited file and will roll at least once a day
- syslog
Each of these has different requirements:
- Logging to the console needs to ensure that the logs are flushed at least once every 100ms so that the human watching the logs perceives them as real-time. In addition, the visual space should be maximized: omit the date, abbreviate logger names, etc.
- Logging to a file needs to ensure that the space occupied by the logs is bounded. When searching log files for a specific event using command line tooling, it can be helpful if the date is included. Similarly, visual space is not at quite the same premium, so abbreviation of logger names is less important.
- Logging to syslog requires a very strict format that can be hard to configure using the various pattern formatters / layouts.
Conclusions
Java Util Logging cannot be recommended based on performance. The lack of a buffered handler implementation has a significant impact on logging performance.
When configuring logging, the ability to buffer file I/O is the major impact in terms of performance. The risk with enabling buffering is that the log statements immediately prior to your process crashing may not get flushed to disk, so it may be impossible to identify the root cause. The other issue with buffering is that it can make it hard to tail the log files and follow the system in real time. It would be nice if the different logging frameworks providing buffering with a guaranteed maximum time before flushing. Ensuring a flush once every 100ms would not have as much of an impact on the system performance as flushing after every log statement and would allow humans to follow the log with the perception of real-time logging.
These benchmarks are testing the loggers under sustained continuous load. The asynchronous loggers are designed to provide lower latency for infrequent logging. Under sustained logging, where the bottleneck is file I/O, the extra work of exchanging of logging events between different threads will impact overall throughput. As such we expect and find that the asynchronous loggers show a lower throughput that the synchronous loggers. Designing a benchmarks to show the claimed benefits of asynchronous loggers is non-trivial. You need to ensure that the logging output is not limited by file I/O, which will require capping the overall throughput. JMH is designed to measure at maximum throughput and is probably not the right benchmarking framework to use for judging the claimed benefits of asynchronous loggers.
Compared with Java Util Logging, either Logback or Log4j 2.x will wipe the floor when it comes to performance. Apache Log4J’s synchronous logger is about 25% faster than Logback’s synchronous logger which currently gives it a slight edge. I should note that Logback versions before 1.2.1 has significantly worse performance, so this is an area of competition between the frameworks and my strawmen implementations certainly identify potential room for improvement in both frameworks.
Frequently Asked Questions (FAQs) about Java Logging Frameworks
What are the key differences between Log4j, Logback, and JUL?
Log4j, Logback, and Java Util Logging (JUL) are all popular Java logging frameworks, but they have some key differences. Log4j is known for its speed and flexibility. It allows you to log at runtime without modifying the application binary. Logback, on the other hand, is designed as a successor to Log4j, offering improvements in certain areas like configuration, filtering, and attachment of additional information to logging events. JUL is a part of the Java platform and is widely used because of its simplicity and ease of use, but it lacks some of the advanced features of Log4j and Logback.
How does the performance of different Java logging frameworks compare?
The performance of Java logging frameworks can vary depending on the specific use case. In general, Log4j and Logback are considered to have better performance than JUL. This is because they offer more advanced features like asynchronous logging, which can significantly improve the performance of logging in multi-threaded applications. However, the performance difference may not be noticeable in applications with low logging activity.
What are some good examples of using Java Util Logging?
Java Util Logging (JUL) is a simple and convenient logging framework that is included in the Java platform. It provides a standard logging API that can be used in any Java application. Some common use cases of JUL include logging informational messages, warning messages, and error messages. It also supports different levels of logging, allowing you to control the granularity of the logged information.
How can I improve the performance of my Java logging framework?
There are several ways to improve the performance of your Java logging framework. One of the most effective methods is to use asynchronous logging, which can significantly reduce the overhead of logging in multi-threaded applications. Other methods include using a faster logging level, reducing the amount of logged information, and optimizing the configuration of your logging framework.
What are the advantages and disadvantages of using Log4j?
Log4j is a powerful and flexible logging framework that offers many advantages. It provides a wide range of features, including different logging levels, multiple output targets, and a flexible configuration system. However, it also has some disadvantages. For example, it can be more complex to set up and configure than simpler frameworks like JUL. Additionally, it may have a higher performance overhead in applications with high logging activity.
How does Logback compare to other Java logging frameworks in terms of performance?
Logback is designed to be a faster and more flexible alternative to Log4j. It offers several performance improvements, including a faster implementation of certain logging operations and support for asynchronous logging. However, the performance difference between Logback and other logging frameworks may not be noticeable in applications with low logging activity.
What are the key features of the Apache Log4j 2.x?
Apache Log4j 2.x is a major update to the original Log4j framework. It offers several new features, including support for asynchronous logging, a new configuration system, and improved performance. It also includes a number of bug fixes and improvements to existing features.
How can I choose the best Java logging framework for my application?
The best Java logging framework for your application depends on your specific needs and requirements. Factors to consider include the complexity of your application, the amount of logging activity, the performance impact of logging, and the features you need. In general, Log4j and Logback are good choices for complex applications with high logging activity, while JUL is a good choice for simpler applications.
What are some common use cases for Java logging frameworks?
Java logging frameworks are used in a wide range of applications to log informational messages, warning messages, and error messages. They can also be used to log debugging information, track the execution of an application, and monitor the performance of an application.
How can I configure my Java logging framework to log to different output targets?
Most Java logging frameworks allow you to log to different output targets, such as the console, a file, or a remote server. The configuration process varies depending on the specific framework and output target. In general, you will need to specify the output target in the configuration file of your logging framework, and you may also need to set up the output target itself.