
Key Takeaways
- Graph databases, such as Neo4j, use structures like nodes, properties, and edges to represent and store data, offering a more flexible and efficient way to handle complex and interconnected data.
- Unlike traditional SQL databases, graph databases do not have a set structure or schema for data, allowing for easy modification of data properties on a per-node level instead of a table-wide transaction.
- Graph databases can be used in numerous scenarios including social networking, fraud detection, recommendation engines, and more, due to their ability to easily handle complex relationships between data points.
- Integrating Neo4j with Ruby can be achieved through different methods, with features like Object Oriented Mapping, “Drop-in” replacement for ActiveModel, and indexing for full-text search. The gems that can be used for this purpose include Neo4j.rb, Neoid, and Neography.
Disclaimer: There are several Graph database projects available, including open-source and commercial projects, projects that aim to be APIs to Graph databases, and projects that are specialized in Distributed Graph Processing. For the articles in the series “Using a Graph Database with Ruby”, I’m going to be discussing and using Neo4j exclusively.
Before we delve into the benefits, differences and intricacies of Neo4j and how it can be used with Ruby, we first need to understand what a Graph Database is, its advantages over traditional databases, and what are some of the scenarios in which we can successfully use a Graph database.
What is a Graph Database?
A Graph Database is not a database to store graphics or images as its name may suggest. It’s a database that uses graph structures such as nodes, properties and edges to represent and store data. In addition, it allows you to represent any kind of data without the limitation of regular databases.
To better understand, let’s talk about each of these structures individually and what they represent:
Node: A node can be used to represent any type of entity that you can think of, be it a business, a blog post, a location, an oil rig, a city, etc. Graph databases don’t care what type of data they’re representing.
Properties: Properties, sometimes called attributes, are named values that relate to nodes. For example, if we take into consideration our City representation of a node, one of the properties would be “name”, another would be “population”, and so on.
Edges: Edges, sometimes called Relationships, connect nodes-to-nodes and organize them into arbitrary structures such as a Map, List or a Tree. It’s important to note that when a node is the start node of a relationship, the relationship from that node’s perspective will be an outgoing relationship. And when a node is at the end of a relationship, the relationship from that node’s perspective will be an incoming relationship. Understanding this will make it easier for you to follow the examples.
What can a Graph Database be used for?
There are many scenarios for which one could consider using a Graph Database. Before I list a few examples, as with any architectural and technical decision, you need to analyze all possible solutions. Then, you can select those that are best for you, according to your specifications.
Some of these scenarios include: social networking, fraud detection, people/movie/music recommendation, manufacturing, etc. Using the social networking example, it would be somewhat trivial to do something like “given the fact that Bob is my friend, give me all friends that are friend’s of friend’s of friend’s of Bob”. This is possible because of the path-finding algorithms involved are easy to implement by traversing through the graph. Imagine doing that through a relational database? A nightmare!
Another advantage when using a Graph database is that you can easily and more naturally model a domain using a whiteboard or a piece of paper. Specifically, nouns that are used become nodes, verbs become relationships, and adjectives and adverbs become properties.
Graph Database Example
Let’s examine the following scenario and how we would structure it using a Graph Database: John is friends with Bob, and Bob is friends with Mark. Visually, this is how we could represent the scenario:
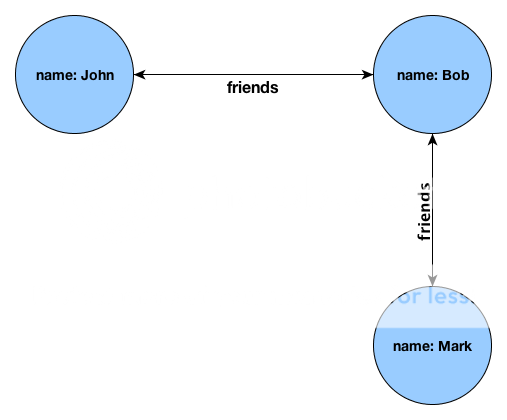
You notice that the visual representation is pretty much how we verbally expressed our scenario. This is a very simple example that we can use to compare the implementation of a traditional SQL database structure versus a Graph database structure:
Traditional SQL
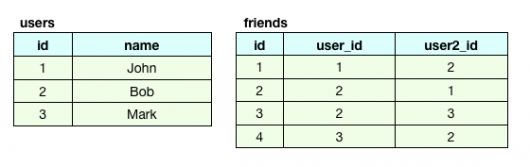
In a traditional SQL structure, each row in the users table represents a user, and each row in the friends table represents a relationship between two users. If we decide to add additional properties to the users table at a later time, we would have to alter the base structure of that table. And if we wanted to add new properties to only a subset of users we would still have to alter the entire users table, or create a new table to accommodate the new values just for the subset of users. Not an ideal scenario when dealing with tens of millions of records.
Graph Database
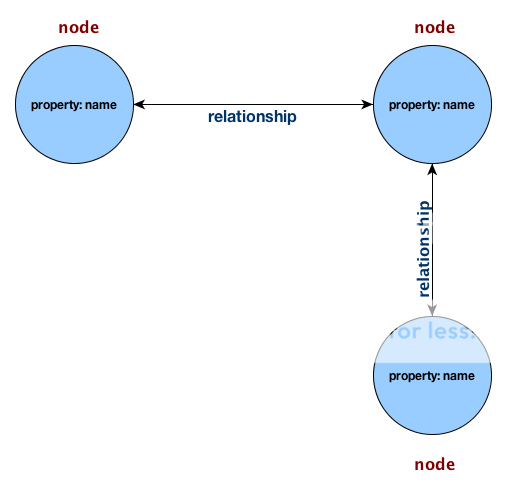
On the other hand, a Graph database has no set structure or schema for the data, much like a NoSQL database. Now, let’s understand what the graph above is representing: each node represents an entity – a User in our case; each node contains property values, in this case it’s the User’s name; and each line represents a relationship between the nodes. This is as simple as it gets. And to complement the scenario described in the traditional SQL example, if we did decide to add additional properties to a subset of users, we could easily perform this action on a per-node level instead of a table-wide transaction.
What is Neo4j
Neo4j is “The World’s Leading Graph Database” according to Neo Technology, the developer behind the project. It’s a commercially supported open-source graph database implemented in Java and some of the key characteristics include:
- Data representation using an intuitive graph-oriented model.
- Binding for a number of languages, including Ruby, Python and Closure.
- Disk-based, native storage manager completely optimized for storing graph structures for maximum performance and scalability.
- Massive scalability, it can handle graphs of several billion nodes/relationships/properties on a single machine.
- Easy to use and convenient object-oriented API.
- Handles large graphs that don’t fit in memory with durability and a fully persistent transactional store.
- Powerful traversal framework for high-speed traversals in the node space.
- Optimized for highly connected data.
- Small footprint, only about 750k jar file.
- It provides a REST interface for languages not supported by its bindings.
- It’s capable of traversing depths of over 1000 levels at millisecond speeds.
- It provides a dual license: open source and commercial.
- It integrates seamlessly with Lucene, providing full-text search to nodes and relationships, including phrase queries, wildcard queries, proximity queries, ranked searching, sorting, and more.
Using Neo4j with Ruby
There are different ways of integrating Neo4j with a Ruby (or Rails) application and before I list them here, below are a few of the combined features from the available solutions:
- Object Oriented Mapping
- “Drop-in” replacement for ActiveModel
- Embedded database
- Thin Ruby wrapper to the Neo4j REST Api
- Indexing for full-text search
- Chainable methods, e.g: method(x).method(y).method(z)…
- When using with Rails, the syntax is very similar to ActiveRecord
Neat, isn’t it? And without much further ado, here are the gems that we’ll be using an evaluating in the next article:
- Neo4j.rb: A graph database for JRuby
- Neoid: Uses Neo4j.rb to power its searchable objects
- Neography: Rest API for the Neo4j server
If you’re curious, I encourage you to look into those projects to have a better understanding of what they do and how complex or simple they are. This way you’ll have a better chance to comprehend the examples in the next article.
What’s next
The Part II of this series will cover the different ways that Neo4j can be integrated with Ruby by using the aforementioned methods. Trust me, you don’t want to miss it.
Frequently Asked Questions about Using a Graph Database with Ruby
What are the benefits of using a graph database with Ruby?
Graph databases offer a flexible and efficient way to represent complex and interconnected data. When used with Ruby, a high-level programming language known for its simplicity and productivity, it allows developers to create robust applications with less code. Graph databases are particularly useful for handling big data, social networking, recommendation engines, and any other applications where relationships between data points are as important as the data itself.
How does a graph database differ from a traditional relational database?
Unlike traditional relational databases that store data in tables, a graph database uses nodes, edges, and properties to represent and store data. This structure allows for more efficient querying and handling of complex relationships between data points. It also provides more flexibility as it can easily adapt to changes in your data model without requiring significant modifications to your existing code.
How can I get started with using a graph database in Ruby?
To get started, you’ll need to install a graph database system like Neo4j or Memgraph. Then, you can use a Ruby gem like ‘neo4j’ or ‘memgraph’ to interact with the database from your Ruby code. These gems provide a high-level API that abstracts the underlying database operations, making it easier to work with the graph database.
What are some common use cases for graph databases?
Graph databases are commonly used in social networking applications to represent relationships between users. They’re also used in recommendation engines, where the relationships between products and user preferences can be modeled as a graph. Other use cases include fraud detection, network analysis, and managing hierarchical data.
Are there any limitations or challenges in using a graph database with Ruby?
While graph databases offer many benefits, they also come with their own set of challenges. One of the main challenges is the learning curve associated with understanding graph theory and how to model your data as a graph. Additionally, while Ruby has libraries for interacting with graph databases, they may not offer the same level of functionality and performance as libraries in other languages like Java or Python.
How does a graph database handle complex queries?
Graph databases excel at handling complex queries that involve multiple relationships. They use graph traversal algorithms to efficiently navigate the connections between nodes. This allows them to execute complex queries much faster than traditional relational databases, which would require multiple joins to retrieve the same information.
Can I use a graph database with Ruby on Rails?
Yes, you can use a graph database with Ruby on Rails. There are several gems available that provide integration with Rails, such as ‘neo4j-rails’ for Neo4j and ‘activerecord-neo4j’ for ActiveRecord.
How secure is a graph database?
The security of a graph database depends on the specific database system you’re using. Most graph databases offer features like authentication, access control, and encryption to protect your data. However, it’s important to follow best practices for database security, such as using strong passwords and keeping your database software up to date.
Can I migrate my existing relational database to a graph database?
Yes, it’s possible to migrate your existing relational database to a graph database. The process involves transforming your tabular data into a graph structure, which can be a complex task depending on the size and complexity of your data. There are tools and services available that can help with this process.
What is the future of graph databases?
The future of graph databases looks promising. As the amount of complex and interconnected data continues to grow, the need for efficient ways to represent and query this data will also increase. Graph databases are well-suited to meet this need, and we can expect to see continued growth and innovation in this field.