

Every day, millions of people turn to their computers and look for information on the Web. And, more often than not, they use a search engine to find that information. It’s estimated that more than 350 million English language Web searches are conducted every day!
The Search Engine Marketing Kit
This article is part of SitePoint’s The Search Engine Marketing Kit.
The kit comprises 300 pages of bleeding-edge insight, strategy, research, and tactics to help Website owners and developers get ahead in the search game. A CD-ROM provides easy-to-use tools to help you streamline your SEM strategies. And each kit comes with US$150-worth of advertising credits for the three major PPC players: Google Adwords, Overture, and Findwhat.
Each of the kit’s eight detailed chapters goes into considerable depth, explaining the complexities of such topics as basic keyword strategy, link building and page optimization, search engine friendly design issues, search marketing strategy, avoiding search engine spam and other underhanded techniques, pay-per-click and other paid inclusion services, and much more.
The kit also includes candid interviews with top industry experts, and a reference that provides information on the quality resources available — both online and off — for use by search engine marketers. The CD-ROM that accompanies the kit offers a range of tools that will prove invaluable to the serious search marketer or SEM service provider, from keyword ranking tools, to business documentation. The Google Adwords, Overture and FindWhat advertising credits will get beginners started, and give those already in the game a little more room to manoeuvre.
Obviously, this chapter provides only a snapshot of all the information that’s available in the kit. If you’d prefer to read this information offline, please feel free to download Chapter 1 in PDF format.
Are you ready to take your first steps toward search engine marketing success? Let’s get started!
Chapter 1 – Understanding Search Engines
In this chapter, I’ll offer a brief history of search engines, explaining the different components of search portals, and how people use them. We’ll dive into the inner workings of the major crawling search engines. Finally, we’ll conclude with a review of today’s search engine landscape, and some thoughts on the future of search engine technology.
You may be tempted to skip right past this chapter to the nitty gritty, but, trust me: this is required reading. Understanding where search results come from, how search engines work, and where the industry is headed is essential if you’re to make successful search engine marketing decisions now and in the future.
Note: In the search engine optimization business, one of the key distinctions between amateurs and professionals is that a professional truly understands how the system works, and why. An amateur might learn to tweak a page’s content and call it “optimized,” but a professional is capable of explaining the rationale behind their every action, and adapting to changing industry conditions without radically altering their methods.
A Brief History of the Search Engine
The World Wide Web was born in November, 1990, with the launch of the first Web server (and Web page) hosted at the CERN research facility in Switzerland. Not surprisingly, the purpose of the first Web page was to describe the World Wide Web project. At the time, no search engine was needed – you could literally read the entire contents of the World Wide Web in less than an hour.
By early 1993, the stage was set for the Web explosion. In February of that year, the first (alpha) release of the NCSA Mosaic graphical browser provided a client application that, by the end of the year, was available on all major desktop computing platforms. The Netscape browser, based on Mosaic, was released in 1994. By this time, dial-up Internet access had become readily available and was cheap. The Web was taking off!
The Early Days of Web Search
Even though the combination of cheap dial-up access and the Mosaic browser had made the Web semi-popular, there was still no way to search the growing collection of hypertext documents available online. Most Web pages were basically collections of links, and a popular pastime of Web users was to share their bookmark files.
This isn’t to say that attempts weren’t made to bring order to the swiftly growing chaos. The first automated Web crawler, or robot, was the World Wide Web Wanderer created by MIT student Mathew Gray. This crawler did little more than collect URLs, and was largely seen as a nuisance by the operators of Web servers. Martjin Koster created the first Web directory, ALIWeb, in late 1993, but it, like the Wanderer, met with limited success.
In February 1993, six Stanford graduate students began work on a research project called Architext, using word relationships to search collections of documents. By the middle of that year, their software was available for site search. More robots had appeared on the scene by late 1993, but it wasn’t until early 1994 that searching really came into its own.
The Great Search Engine Explosion
1994 was a big year in the history of Web search. The first hierarchical directory, Galaxy, was launched in January and, in April, Stanford students David Filo and Jerry Yang created Yet Another Hierarchical Officious Oracle, better known as Yahoo!.
During that same month, Brian Pinkerton at the University of Washington released WebCrawler. This, the first true Web search engine, indexed the entire contents of Web pages, where previous crawlers had indexed little more than page titles, headings, and URLs. Lycos was launched a few months later.
By the end of 1995, nearly a dozen major search engines were online. Names like MetaCrawler (the first metasearch engine), Magellan, Infoseek, and Excite (born out of the Architext project) were released into cyberspace throughout the year. AltaVista arrived on the scene in December with a stunningly large database and many advanced features, and Inktomi debuted the following year.
Over the next few years, new search engines would appear every few months, but many of these differed only slightly from their competitors. Yet the occasional handy innovation would find its way into practical use. Here are a few of the most successful ideas from that time:
- GoTo (now Overture) introduced the concept of pay-per-click (PPC) listings in 1997. Instead of ranking sites based on some arcane formula, GoTo allowed open bidding for keywords, with the top position going to the highest bidder. All major search portals now rely on PPC listings for the bulk of their revenues.
- Metasearch engines, which combine results from several other search engines, proliferated for a time, driven by the rise of pay-per-click systems and the inconsistency of results among the major search engines. Today, new metasearch engines are rarely if ever seen, but those that remain possess a loyal following. The current crop of metasearch engines display mostly pay-per-click listings.
- The Mining Company (now About) launched in February 1997, using human experts to create a more exclusive directory. Many topic-specific (vertical) directories and resource sites have been created since, but About remains a leading resource.
- DirectHit introduced the concept of user feedback in 1998, allocating a higher ranking to sites whose listings were clicked by users. DirectHit’s data influenced the search results on many portals for a long time, but, because of the system’s susceptibility to manipulation, none of today’s search portals openly use this form of feedback. DirectHit was later acquired by Ask Jeeves (now Ask), and user behavior may well be factored into the Ask/Teoma search results we see today.
- Pay-to-play was introduced, as search engines and directories sought to capitalize on the value of their editorial listings. The LookSmart and Yahoo! directories began to charge fees for the review and inclusion of business Websites. Inktomi launched “paid inclusion” and “trusted feed,” allowing site owners to ensure their inclusion (subject to editorial standards) in the Inktomi search engine.
- The examination of linking relationships between pages began in earnest, with AltaVista and other search engines adding “link popularity” to their ranking algorithms. At Stanford University, a research project created the Backrub search engine, which took a novel approach to ranking Web pages.
Google Dominates, the Field Narrows
The Backrub search engine eventually found its way into the public consciousness as Google. By the time the search engine was officially launched as Google in September 1998, it had already become a very popular player.
The development of search engines since that time has been heavily influenced by Google’s rise to dominance. More than any other search portal, Google has focused on the user experience and quality of search results. Even at the time of its launch, Google offered users several major improvements, some of which had nothing to do with the search results offered.
One of the most appealing aspects of Google was its ultra-simple user interface. Advertising was conspicuously absent from Google’s homepage – a great advantage in a market whose key players typically adorned their pages with multiple banners – and the portal took only a few seconds to load even on a slow dial-up connection. Users had the option to search normally, but a second option, called “I’m Feeling Lucky,” took users directly to the page that ranked at the top of the results for their search.
Like its homepage, Google’s search results took little time to appear and carried no advertising. By the time Google began to show a few paid listings through the AdWords service in late 2000, users didn’t mind: Google had successfully established itself as the leading search portal and, unlike many other search engines, it didn’t attempt to hide paid advertising among regular Web search results.
Many other search portals recognized the superiority of Google’s search results, and the loyalty that quality generated. AOL and Yahoo! made arrangements to display Google’s results on their own pages, as did many minor search portals. By the end of 2003, it was estimated that three-quarters of all Web searches returned Google-powered results.
Within a few years, the near-monopoly that Google achieved in 2003 will be recognized as a high water mark, but the development of this search engine is by no means finished.
The years 2001–2003 saw a series of acquisitions that rapidly consolidated the search industry into a handful of major players. Yahoo! acquired the Inktomi search engine in March 2003; Overture acquired AltaVista and AllTheWeb a month later; Yahoo! announced the acquisition of Overture in August 2003.
In 2004, a new balance of power took shape:
- Yahoo! released its own search engine powered by a fusion of the AltaVista, Inktomi, and AllTheWeb technology they acquired in 2003. Yahoo! stopped returning Google search results in January 2004.
- Google’s AdWords and AdSense systems, which deliver pay-per-click listings to search portals and Websites respectively, grew dramatically. Google filed for an initial public offering (IPO).
- The popularity of the Ask search portal, powered by the innovative Teoma search engine, steadily increased. Like most portals that Yahoo! doesn’t own, Ask uses Google’s AdWords for paid listings.
- The 800-lb gorilla of the computing world, Microsoft, announced plans for its own search engine, releasing beta versions for public use in January and June of 2004, and formally launching the service in February 2005. Microsoft now offers MSN search results on the MSN portal.
That’s enough history for now. We’ll take a closer look at the current search engine landscape a little later in this chapter, when I’ll introduce you to the major players, and explain how all this will affect your search engine strategy.
Anatomy of a Web Search Portal
Today, what we call a search engine is usually a much more complex Web search portal. Search portals are designed as starting points for users who need to find information on the Web. On a search portal, a single site offers many different search options and services:
- AOL’s user interface gives users access to a wide variety of services, including email, online shopping, chat rooms, and more. Searching the Web is just one of many choices available.
- MSN features Web search, but also shows news, weather, links to dozens of sites on the MSN network, and offers from affiliated sites like Expedia, ESPN, and others.
- Yahoo! still features Web search prominently on its homepage, but also offers a dazzling array of other services, from news and stock quotes to personal email and interactive games.
- Even Google, the most search-focused portal, offers links to breaking news, Usenet discussion groups, Froogle shopping search, a proprietary image search system, and many other options.
In this section, we’ll examine the makeup of a typical search engine results page (SERP). Every portal delivers search results from different data sources. The ways in which these sources are combined and presented to the user is what gives each Web search portal its own unique flavor.
Changes to the way a major portal presents its search results can have a significant impact on the search engine strategy you craft for your Website. As we look at the different sources of search results, and the ways in which those results are handled by individual portals, I’ll offer examples to illustrate this point.
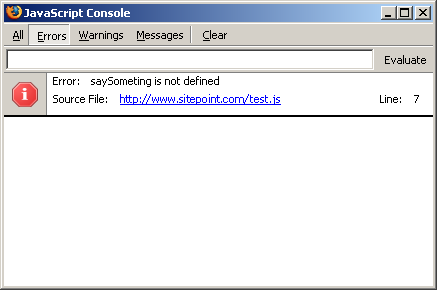
A typical search engine results page has three major components: crawler-based listings, sponsored listings, and directory listings. Not all SERPs contain all three elements; some portals incorporate additional data sources depending on the search term used. Figure 1.1, from Yahoo!, shows a typical SERP:
Figure 1.1. A typical SERP.
Crawler-Based (Organic) Listings
Most search portals feature crawler-based search results as the primary element of their SERPs. These are also referred to as editorial, free, natural, or organic listings. Throughout the rest of this kit, we will refer to crawler-based listings as organic listings.
Crawler-based search engines depend upon special programs called robots or spiders. These spiders crawl the Web, following one link after another, to build up a large database of Web pages. We will use the words spider, crawler, or robot to refer to these programs throughout this kit.
Each crawler-based search engine uses its own unique algorithm, or formula, to determine the order of the search results. The databases that drive organic search results primarily contain pages that are found by Web-crawling spiders. Some search engines offer paid inclusion and trusted feed programs that guarantee the inclusion of certain pages in the database.
Paid inclusion is one of many ways in which search engines have begun to blur the line between organic and paid results. Trusted feed programs allow the site owner to feed the search engine an optimized summary of the pages in question; the pages may be ranked on the basis of their content summaries rather than their actual content.
Although all the search engines claim that paid inclusion does not give their customers a ranking benefit, the use of paid inclusion does offer SEO consultants an opportunity to tweak and test copy on Web pages more frequently. We will learn more about this in Chapter 2, Search Engine Optimization Basics.
Organic search listings are certainly the primary focus for search engine marketers and consultants, but they’re not the only concern. In many cases, the use of pay-per-click is essential to a well-rounded strategy.
Most of today’s search portals do not operate their own crawler-based search engine; instead, they acquire results from one of the major organic search players. The major providers of organic search listings are Google and Yahoo! who, in addition to operating their own popular search portals, also provide search results to a variety of different portals.
Aside from Google and Yahoo!, only a few major players operate crawling search engines. Ask uses its own Teoma search engine, LookSmart owns Wisenut, Lycos, too, has its own crawler-based engine, and Microsoft’s MSN search is also in the mix. That’s a grand total of six crawler-based search engines accounting for nearly all of the organic search results available in the English language.
Note: In order to have a meaningful chance to gain traffic from organic search listings, a Web page must appear on the first or second page of search results. Different search portals show varying numbers of results on the first page: Google displays ten, Yahoo! shows 15, and MSN’s search presents eight. Any changes a major search portal might make to the listing layout will affect the amount of traffic your search engine listings attract.
Sponsored (Pay-Per-Click) Listings
It costs a lot of money to run a search portal. Crawler-based search engines operate at tremendous expense – an expense that most portals can’t afford. Portals that don’t operate their own crawler-based search engines must pay to obtain crawler-based search results from someone who does.
Either way, the delivery of unbiased organic search results is expensive, and someone has to pay the bill. In the distant past, search portals lost money hand over fist, but today, even very small search portals can generate revenue through sponsored listings. Metasearch engines typically use sponsored listings as their primary search results.
In addition to helping search portals stay afloat, sponsored listings provide an excellent complement to organic search results by connecting searchers with advertisers whose sites might not otherwise appear in the search results.
Most portals do not operate their own pay-per-click (PPC) advertising service. Instead, they show sponsored results from one or more partners and earn a percentage of those advertisers’ fees. The major PPC providers are Google AdWords and the Overture service offered by Yahoo! (Note that, at the time of this writing, Overture is expected to announce a rebranding in Q2 2005, under which it would adopt the name “Yahoo! Search Marketing Solutions.”) Other PPC providers with a significant presence include Findwhat and LookSmart.
The PPC advertising model is simple. Advertisers place bids against specific search terms. When users search on those terms, the advertiser’s ads are returned with the search results. And, each time a searcher clicks on one of those ads, the advertiser is charged the per-click amount he or she bid for that term. PPC providers have added a few twists to this model over the years, as we’ll see in Chapter 4, Paying To Play: Pay-Per-Click And Paid Inclusion.
Different PPC providers use different methods to rank their sponsored listings. All methods start with advertisers bidding against one another to have their ads appear alongside the results returned for various search terms, but each method has its own broad matching options to allow a single bid to cover multiple search terms.
Note: The bidding for extremely popular search terms can be quite fierce: it’s not unusual to see advertisers bidding $10 per click – or more – for the privilege of appearing at the top of the sponsored listings. Reviewing the amounts that bidders are willing to pay for clicks to sponsored listings can give SEO practitioners a very good idea of the popularity of particular search terms – terms that may also be suitable for organic optimization.
In addition, PPC ranking systems are no longer as simple as allocating the highest position to the highest bidder. Google’s methodology, for example, combines the click-through rate of an advertiser’s listing (the number of clicks divided by the number of times it’s displayed) with that advertiser’s bid in assessing where the PPC advertisement will be located. Google’s method tends to optimize the revenue generated per search, which is one of the reasons why its AdWords service has gained significantly on Overture.
Note: In the example SERP shown above (Figure 1.1), Yahoo! displays the first two sponsored listings in a prominent position above the organic results. Understanding which sponsored results will be displayed most prominently will help you determine how much to bid for different search terms. For example, it may be worth bidding higher to get into the #1 or #2 position for the most targeted search terms, since those positions will gain the most traffic from Yahoo!.
Directory (Human-Edited) Listings
Directory listings come from human-edited Web directories like LookSmart, The Open Directory, and the Yahoo! Directory. Most search portals offer directory results as an optional search, requiring the user to click a link to see them.
Because directories usually only list a single page (the homepage) of a Website, it can be difficult for searchers to find specific information through a directory search. As the quality of organic search results has improved, search portals have gradually reduced their emphasis on directory listings.
Currently, only Lycos displays a significant number of directory listings (from LookSmart), and that’s likely to change as LookSmart transitions from its old business model (paid directory) into a standard PPC service.
The decline of directory listings within search results does not diminish the importance of directory listings in obtaining organic search engine rankings. All crawler-based search engines take links into account in their rankings, and links from directories are still extremely important.
Note: The way that Yahoo! makes directory results available to users should be a significant factor in helping the site owner decide whether or not to pay for a listing in the directory. At $299 per year, a paid listing in the Yahoo! Directory is a considerable expense for small businesses. Yet, while there is value in any link, the directory itself no longer generates significant traffic.
In addition, it is by no means clear whether the display of a directory category link below a site’s organic search result listing may contribute to the click-through rate for that listing. In fact, it’s possible that users might click this directory link and arrive at the directory category page, where the given listing could be buried at the bottom of a long list of competing sites.
Compared to other advertising options, paying $299 for a link buried deep within the Yahoo! Website is not as appealing as it once was. In addition, sites listed in the Yahoo! Directory automatically have a title and description displayed alongside each of their listings in the organic search results. This style of listing can actually generate a lower click-through than an ordinary listing within the organic results.
Whether or not you currently have a Yahoo! Directory listing, you owe it to yourself to discuss other ways to make use of those funds. For example, at an average of 20 cents per click, you could bring in nearly 1500 visitors per year through PPC advertising.
Other Listings
In addition to the three main types of search results, most search portals now offer additional types of search listings. The most common among these are:
- Multimedia searches, which help users find images, sounds, music etc.
- Shopping searches to help those searching for specific products and services.
- Local searches to find local business and information resources.
- People searches, including white pages, yellow pages, reverse phone number lookups.
- Specialized searches, covering government information, universities, scientific papers, maps, and more.
Search Engine Marketing Defined
Throughout this kit, I’ll use search engine marketing (SEM) to describe many different tasks. We’ll talk about this concept a lot, so it will be helpful to have a working definition. For the purposes of these discussions, we’ll define search engine marketing as follows:
Search engine marketing is any legal activity intended to bring traffic from a search portal to another Website.
The term search engine marketing, therefore, covers a lot of ground. Wherever people search the Web, whatever they search for, and wherever the search results come from – if you’re trying to reach out to target visitors, you’re undertaking search engine marketing. The goal of SEM is to increase the levels of high-quality, targeted traffic to a Website. In this kit, we’ll focus on the two primary disciplines of SEM, which are:
- Search Engine Optimization (SEO)
The function of SEO is to improve a Website’s position within the organic search results for specific search terms, and to increase the overall traffic the site garners from crawler-based search engines. This is accomplished through a combination of on-page content and off-page promotion (such as directory submissions). - Pay-Per-Click Advertising (PPC)
PPC involves the management of keyword-targeted advertising campaigns through one or more PPC service providers, such as Google’s AdWords, or Overture from Yahoo!. The advertiser’s goal is to profitably increase the amount of targeted traffic that his or her Website receives from search portals.
In addition to these two major disciplines, there are other aspects of search engine marketing that we’ll discuss to a lesser degree, including:
- Contextual advertising
, which is offered by many PPC service providers. Contextual advertising delivers targeted advertising based on the content of each individual Web page that carries an ad. Advertisers who have used PPC to target people searching on the term fishing can also have their ads distributed across a great many Websites on which fishing is discussed. This is a fast-growing market, and one that’s sure to become a very significant part of SEM over time.
, which involves the submission of Websites to general-purpose and vertical (topic-specific) directories, or vortals. We will discuss this mainly in the context of SEO, but many directories (both general-purpose and vertical) provide search-driven traffic to the Websites they list. Many operate on a paid advertising or PPC basis. As searchable business directories like Verizon’s SuperPages and the already established Business.com grow, so too will this area of search engine marketing.
Search engine marketing is a fast-growing and rapidly changing field. Before we get too far ahead of ourselves, though, let’s take a close look at where organic search results come from: the crawling search engines.
The Crawling Search Engines
In this discussion, we’ll explore the major components of a crawler search engine, and understand how they work. The typical Web user assumes that when they search, the search engine actually goes out onto the Web to look around. In fact, the job of searching the Web is vastly more complex than that, requiring massive amounts of hardware, software, and bandwidth.
To give you an idea of just how much hardware it takes to run a large-scale, modern search engine, here’s a staggering figure: Google runs what is believed to be the world’s largest Linux server cluster, with over 10,000 servers at present, and more being added all the time (it was “only” 4,000 in June, 2000).
Searching a small collection of well-structured documents, such as scientific research papers, is difficult enough, but that task is relatively easy compared to searching the Web. The Web is massive and mobile, consisting of billions of documents in over 100 languages, many of which change or disappear on a daily basis. To make matters worse, there is very little consistency in terms of how information is organized and presented on the Web.
Major Tasks Handled by Search Engines
There are five major tasks that each crawling search engine must handle, and significant computing resources are dedicated to each. These tasks are:
- Finding Web pages and downloading their contents.
The bulk of this task is handled by two components: the crawler and the scheduler. The crawler’s job is to interact with Web servers to download Web pages and/or other content. The scheduler determines which URLs will be crawled, in what order, and by which crawler. Large crawling search engines are likely to have multiple types of crawlers and schedulers, each assigned to different tasks.
The primary components at this stage are the database/repository and parser modules. The database/repository receives the content of each URL from the crawlers, then stores it. The parser modules analyze the stored documents to extract information about the text content and hyperlinks within. Depending on the search engine, there may be multiple parser modules to handle different types of files, including HTML, PDF, Flash, Microsoft Word, and so on.
This is handled by the document indexer. The text content is analyzed by the indexer and stored in a set of databases called indexes. For simplicity’s sake, I’ll refer to these indexes as simply “the index.” Included in the indexing process is the preliminary analysis of hyperlinks within the documents, feeding URLs back into the scheduler and building a separate index of links. The main focus of this phase is the on-page content of Web documents.
This is the work of the link analyzer component. All of the major crawling search engines analyze the linking relationships between documents to help them determine the most relevant results for a given search query. Each search engine handles this differently, but they all have the same basic goals in mind. There may be more than one type of link analyzer in use, depending on the search engine.
The query processor and ranking/retrieval module are responsible for this important task. The query processor must determine what type of search the user is conducting, including any specialized operations that the user has invoked. The ranking/retrieval module determines the ranking order of the matching documents, retrieves information about those documents, and returns the results for presentation to the user.
The Crawling Phase: How Spiders Work
As mentioned above, one of the largest jobs of a crawling search engine is to find Web documents, download them, and store them for further analysis. To simplify matters, we’ve combined the work of tasks 1 and 2 above into a single activity that we’ll refer to as the crawling phase.
Every crawling search engine is assigned different priorities for this phase of the process, depending on their resources and business relationships, and what they’re trying to deliver to their users. All search engines, however, must tackle the same set of problems.
How Search Engines Find Documents
Every document on the Web is associated with a URL (Uniform Resource Locator). In this context, we will use the terms “document” and “URL” interchangeably. This is an oversimplification, as some URLs return different documents to the user depending on such factors as their location, browser type, form input etc., but this terminology suits our purposes for now.
To find every document on the Web would mean more than finding every URL on the Web. For this reason, search engines do not currently attempt to locate every possible unique document, although research is always underway in this area. Instead, crawling search engines focus their attention on unique URLs; although some dynamic sites may display different content at the same URL (via form inputs or other dynamic variables), search engines will see that URL as a single page.
The typical crawling search engine uses three main resources to build a list of URLs to crawl. Not all search engines use all of these:
- Hyperlinks on existing Web pages
The bulk of the URLs found in the databases of most crawling search engines consists of links found on Web pages that the spider has already crawled. Finding a link to a document on one page implies that someone found that link important enough to add it to their page. - Submitted URLs
All the crawling search engines have some sort of process that allows users or Website owners to submit URLs to be crawled. In the past, all search engines offered a free manual submission process, but now, many accept only paid submissions. Google is a notable exception, with no apparent plans to stop accepting free submissions, although there is great doubt as to whether submitting actually does anything. - XML data feeds
Paid inclusion programs, such as the Yahoo! Site Match system, include trusted feed programs that allow sites to submit XML-based content summaries for crawling and inclusion. As the Semantic Web begins to emerge, and more sites begin to offer RSS (RDF Site Summary) news feed files, some search engines have begun to read these files in order to find fresh content.
Search engines run multiple crawler programs, and each crawler program (or spider) receives instructions from the scheduler about which URL (or set of URLs) to fetch next. We will see how search engines manage the scheduling process shortly, but first, let’s take a look at how the search engine’s crawler program works.
The Robot Exclusion Protocol
The first search spiders developed a very bad reputation in a hurry. Web servers in 1993 and 1994 were not as powerful as they are today, and an aggressive spider could bring an underpowered Web server to a crashing halt, or use up the server’s limited bandwidth, by fetching pages one after another.
Clearly, rules were needed to control this new type of automated user, and they have developed over time. Spiders are supposed to fetch no more than one document per minute (a rate that’s probably much slower than necessary) from a given Web host, and they’re expected to obey the Robot Exclusion Protocol.
In a nutshell, the Robot Exclusion Protocol allows Website operators to place into the root directory of their Web server a text file named robots.txt that identifies any URLs to which search spiders are denied access. We’ll address the format of this file later; the important point here is that spiders will first attempt to read the robots.txt file from a Website before they access any other resources.
When a spider is assigned to fetch a URL from a Website, it reads the robots.txt file to determine whether it’s permitted to fetch that URL. Assuming that it’s permitted access by robots.txt, the crawler will make a request to the Web server for that URL. If no robots.txt file is present, the spider will behave as if it has been granted permission to fetch any URL on the site.
There are no specific rules about this, and each search engine will implement this differently, but it is considered poor behavior for a search engine to rely on a cached copy of the robots.txt file without confirming that it’s still valid. In order to save resources, schedulers can assign the crawler program a set of URLs from the same site, to be fetched in sequence, before it moves on to another site. This allows the crawler to check robots.txt once and fetch multiple pages in a single session.
What Happens in a Crawling Session?
For the sake of clarity, let’s walk through a typical crawling session between a spider and a Website. In this particular scenario, we’ll assume that everything works perfectly, so the spider doesn’t have to deal with any unusual problems.
Let’s say that the spider has a URL it would like to fetch from our Website, and that this URL has been fetched before. The scheduler will supply the spider with the URL, along with the date and time of the most recent version that has been fetched. It will also supply the date and time from the most recent version of robots.txt that has been fetched from this site.
The communication between a user agent (such as your Web browser or our hypothetical spider) and a Web server is conducted via the HTTP protocol. The user agent sends requests, the server sends responses, and this communication goes back and forth.
Once the document has been downloaded from the Web server, the crawler’s job is nearly done. It hands the document off to the database/repository module, and informs the scheduler that it has finished its task. The scheduler will respond with another task, and it’s back to work for the spider.
Practical Aspects of Crawling
If only things could always be as simple as our hypothetical session above! In reality, there are a tremendous number of practical problems that must be overcome in the day-to-day operations of a crawling search engine.
Dealing with DNS
The first problem that crawlers have to overcome lies in the domain name system that maps domain names to numeric addresses on the Internet. The root name servers for each top level domain, or TLD (e.g. .com, .net etc.), keep records of the domain name server (DNS server) that handles the addressing for each second level domain name (e.g. example.com).
Thousands of secondary and tertiary name servers across the Internet synchronize their DNS records with these root name servers periodically. When the DNS server for a domain name changes, this change is recorded by the domain name registrar, and given to the root name server for the TLD.
Unfortunately, this change is not reflected immediately in all name servers all over the world. In fact, it can easily take 48–72 hours for the change to propagate from one name server to the next, until the entire Internet is able to recognize the change.
A search engine spider, like any other user, must rely on the DNS in order to find the resources that it’s been sent to fetch. Although the major search engines all have reasonably fast updates to their DNS records, when DNS servers are changed, it’s possible that a spider will be sent out to fetch a page using the wrong DNS server address. When this happens, there are three possibilities:
- The DNS server from which the spider requests the site’s Web server address no longer has a record of the domain name supplied. In this case, the spider will probably hand the URL back to the scheduler, to be tried again later.
- The DNS server does have a record for the domain name, and dutifully gives the spider an address for the wrong Web server. In this case, the spider may end up fetching the wrong page, or no page at all. It may also receive an error status code.
- Even though it’s no longer the authoritative name server for the supplied domain name, the DNS server still provides the spider the correct address for the Web server. In this case, the spider will probably fetch the right page.
It’s also possible that a search engine could use a cached DNS record for the domain name, and go looking for the Web server without checking to ensure that the record is current. This used to be an occasional problem for Google, but probably will never be seen again. It certainly hasn’t appeared to be a problem for any of the major search engines in some time.
We will discuss exactly how to move a Website from one server to another, from one hosting provider to another, and from one DNS server to another, in Chapter 3, Advanced SEO And Search Engine-Friendly Design. For now, the key point is that the mishandling of DNS can lead to problems for search engines, and this can, in turn, create major headaches for you.
Dealing with Servers
The next challenge that spiders have to handle is HTTP error messages, servers that simply cannot be found, and servers that fail to respond to HTTP requests. There are also many other server responses that must be handled with particular care in order to avoid problems.
Rather than provide a comprehensive listing of every problem that could ever eventuate, I’ll simply list a few broad categories and note how search engines are likely to deal with them. We’ll dig more deeply into server issues in Chapter 3, Advanced SEO And Search Engine-Friendly Design.
Where’s That Server?
If a server can’t be found, or fails to respond, it’s likely a temporary condition. The crawler will inform the scheduler of the error, and move on. If the condition persists, the search engine might remove the URL in question from the index, and may even stop trying to crawl it. It usually takes a long term problem, or a very unreliable server, to elicit such a drastic response, however. If a URL (or an entire domain) is removed because of server problems, a manual submission may be required in order to have the search engine crawl it again.
Where’s That Page?
If a page does not exist at the requested URL, the server will return a 404 Not Found error. Sometimes, this means that a page has been permanently removed; sometimes, the page never existed in the first place; occasionally, pages that go missing reappear later. Search engines are usually quick to remove URLs that return 404 errors, although most of them will try to fetch the URL a couple more times before giving it up for dead. As with server issues, it may be necessary to resubmit pages that have been dropped for returning 404 errors. In Chapter 3, Advanced SEO And Search Engine-Friendly Design, we will discuss the right (and wrong) way to use custom 404 error pages.
Whoops, There Goes The Database!
Database errors are the bane of dynamic sites everywhere. Unless the code driving the site has robust error handling capabilities, most database errors will cause the Web server to return a 200 OK status code while delivering a page that contains nothing but an error message from the database. When this occurs, the error message will be stored by the spider as if it were the page’s content. Resubmission of the page is not necessary, assuming the database issues have been corrected the next time the spider visits. Chapter 3, Advanced SEO And Search Engine-Friendly Design will include some recommendations on how best to manage database errors.
Sorry, We Moved It … Or Did We?
Redirection by the Web server can be a challenge for search engines. A server response of 301 Moved Permanently should cause the search engine to visit the new URL and adjust its database to reflect the change. Trickier for spiders is the 302 Found response code, which is used by many applications and scripts to redirect Web browsers. Search engines currently have varying responses to server-based redirects. In some cases, very bad things can happen if spiders are allowed to follow 302 redirects, as we’ll see in Chapter 3, Advanced SEO And Search Engine-Friendly Design.
Handling Dynamic Sites
One of the most difficult challenges faced by today’s crawlers is the proliferation of dynamic or database-driven Websites. Depending on the way the site is configured, it’s possible for a spider to get caught in an endless loop of pages that generate more pages, with a never-ending sequence of unique URLs that deliver the same (or slightly varied) content.
In order to avoid becoming caught in such spider traps, today’s crawlers carefully examine URLs and avoid crawling any link that includes a session ID, the referring URL, or other variables that have nothing to do with the delivery of content. They also look for hints of duplicate content, including identical page titles, empty pages, and substantially similar content. Any of these gotchas can stop a spider from fully crawling a dynamic site. We will review crawler-friendly SEO strategies for dynamic sites in Chapter 3, Advanced SEO And Search Engine-Friendly Design.
Scheduling: How Search Engines Set Priorities
In addition to the challenges that must be overcome in crawling the Web, there are a great number of issues with which search engines must grapple in order to properly manage their crawling resources. As mentioned previously, each search engine’s priorities are different.
Five years ago, the major competition between the search engines was to build the largest index of documents. News networks like CNN played up each succeeding announcement of what was described as the new “biggest search engine,” which, no doubt, pleased many dot-com investors, even if some of the search engines played it a little fast and loose when it came to the numbers.
Today, the total index size is no longer seen as a key indicator of a search engine’s quality. Nonetheless, any search engine must index a substantial portion of the Web in order to deliver relevant search results. Google currently has by far the largest index, which is especially evident to those searching for detailed technical information, as relevant pages may be buried deep within a site.
The scheduling of crawler activity must be guided by the search engine’s individual priorities in four specific areas:
- Freshness:
In order to deliver the best possible results, every search engine must index a great deal of new content. Without this, it would be impossible to return search results on current events. Most scheduling algorithms involve a list of important sites that should be checked regularly for new content. Indexing XML data feeds helps some search engines keep up with the growth of the Web. - Depth vs Breadth:
A key strategic decision for any search engine involves how many sites to crawl (breadth) and how deeply to crawl into each site (depth). For most search engines, making the depth vs. breadth decision for a given site will depend upon the site’s linking relationships with the rest of the Web: more popular sites are more likely to be crawled in depth, especially if some inbound links point to internal pages. A single link to a site is usually enough to get that site’s homepage crawled. - Submitted Pages:
Search engines such as Google, which allow the manual submission of pages, must decide how to deal with those manually submitted pages, and how to handle repeat submissions of the same URL. Such pages might be extremely fresh or important, or they may be nothing more than spam. - Paid Inclusion:
Search engines that offer paid inclusion programs generally guarantee that they will revisit paid URLs every 24–72 hours.
In terms of priority, a search engine that offers a paid inclusion program must visit those paid URLs first. After listings for paid inclusion, most search engines will probably focus resources on any important URLs that help them maintain a fresh index. Only after these two critical groups of URLs are crawled will they pursue additional URLs. URLs submitted via a free submission page are probably the last on the list, especially if they have been submitted repeatedly.
Parsing and Caching
Once the contents of a URL have been fetched, they are handed off to the database/repository and stored. Each URL is associated with a unique ID, which will be used throughout all the search engine’s operations. Depending on the type of content, one of two things will happen next.
If the document is already in HTML format, it can be stored immediately, exactly as is. Additional metadata, such as the Last-Modified date and page title, may be stored along with the document. (Note that metadata should not be confused with <meta> tags. Metadata is “data about data.” For search engines, the primary unit of data is the Web page, so anything that describes that Web page (other than its content) is metadata. This might include the page’s title, URL, and other information such as the Website’s directory description, which Yahoo! uses within its search results.)
This stored copy of the HTML code is used by some search engines to offer users a snapshot view of the page, or access to the cached version.
For documents that are presented in formats other than HTML, such as Adobe’s popular Acrobat (PDF) or Microsoft Word, further processing is needed. Typically, search engines that attempt to index these types of documents first translate the document into HTML format with a specialized parser.
Converting non-HTML documents to an HTML representation allows search engines to offer users access to the document’s contents in HTML format (as Google does), and to conduct all further processing on the HTML version. When the document contains structural information, such as a Microsoft Word file that makes use of heading styles, search engines can make use of these elements within the HTML translation. Adobe’s PDF is notably lacking in structural elements, so search engines must rely on type styles and size to determine the most significant text elements.
At this point, all that has been accomplished is to store an HTML version of the document. Most search engines will perform further parsing at this stage, to extract the text content of the page, and catalog the various elements (headings, links etc.) for analysis by the indexing and link analysis components. Some of them may leave all of this processing to the indexer.
Results of the Crawling Phase
By the end of the crawling phase, the search engine knows that there was valid content at the URL, and it has added that content (possibly translated to HTML) to its database.
Even before a search engine crawls a page, it must “know” something about that page. It knows that the URL exists and, if the URL was found via links, the search engine may also have found within those links some text that tells it something about the URL.
Once a search engine knows that a URL exists, it’s possible that this URL could appear in search results. In Google, a page that has not yet been crawled can appear as a supplemental search result, based on the keywords contained in hyperlinks pointing to that page. At this point, the page’s title is not known, so the listing will display the page’s URL in place of the title.
After the crawling phase is complete, the search engine knows the document’s title, last-modified date, and its size. Such pages can appear in Google’s results as supplemental search results, based on keywords that appear in the page’s title and incoming links. After the crawling phase, the page title can also appear in the search results.
Tip: The Google search engine provides an unusual amount of transparency around its process and results. It’s possible, for example, to have Google return a list of all the URLs it has found within a particular site. The syntax for this search is site:example.com.
If some of the URLs listed for a site:domain search do not include page titles or page size information, this means that those URLs have not been yet been crawled. If this condition persists, as happens often with dynamic sites, there may be issues with duplicate content, session IDs, empty pages, or other problems that have caused the spider to stop crawling the site. We will cover these issues in Chapter 3, Advanced SEO And Search Engine-Friendly Design.
Indexing: How Content is Analyzed
After the content of a Web page (or HTML representation of a non-HTML document) has been stored in the database, the indexer takes over, breaking down the page piece by piece, and creating a mathematical representation of it in the search engine’s index.
The complexity of this process, the extreme variations between different search engines, and the fact that this part of the process is a closely guarded secret (a search engine’s algorithm must be kept secret, in order to prevent optimizers from unfairly manipulating search results and, of course, to prevent competitors from “borrowing” useful ideas), makes a comprehensive explanation impossible. However, we can speak about the process in general terms that will apply to all crawling search engines.
What Indexing Means in Practice
When a search engine’s indexer analyzes a document, it stores each word that occurs in the document as a hit in one of the indexes. The indexes may be sorted alphabetically, or they may be designed in a way that allows more commonly used words to be accessed more quickly.
The format of the index is very much like a table. Each row in the table records the word, the ID of the URL at which it appeared, its position within the document, and other information which will vary from one search engine to the next. This additional information may include such things as the structural element in which the word appeared (page title, heading, hyperlink etc.) and the formatting applied (bold, italic etc.).
Table 1.1 shows a hypothetical (and simplified) search engine index entry for an imaginary (and very boring) document. The page’s title is “Hello, World!” The document itself contains the same words in a large heading, followed by the words “Greetings, everyone!” as the first paragraph of text.
Each index contains hits for different groups of words. The hypothetical index entry for the document will therefore be spread across multiple indexes. The only place in which the entire document might remain intact is in the repository of a search engine that retains a full cached copy of each page, as Google does.
Table 1.1. A Search Engine Index Entry
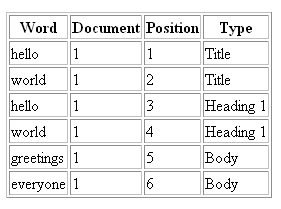
The first thing that you will notice is that punctuation is not stored in the index. That’s because search engines ignore punctuation – if any of them considered it at all, it would be news to me. When we talk about SEO copywriting later, you’ll see the importance of this fact.
For now, you need to understand that search engines don’t look at Web pages; they look at indexes that match words to documents. When we talk about the vector space model and the ranking/retrieval process later in this chapter, you may need to refer back to this table to refresh your memory.
I should note one thing before we move on. Although search engines do apply a different “weight” to words that appear in more prominent positions (such as headings), they do not necessarily attempt to store those values in the index records. When we talk about algorithm changes and term weights in just a moment, you’ll understand why.
Link (URL) Discovery and Indexing
URLs that are found within documents are fed back into the scheduler for crawling. Information about the source document may have an impact on the URL’s priority within the crawling queue. For example, the URLs contained in links found on an important page (such as the Yahoo! homepage) may take precedence over links that have been found on lesser pages.
When a hyperlink is found within the document that’s being indexed, the words in the hyperlink are recorded in the index as a hit, just like any other word, along with the fact that the words appeared in a hyperlink.
There are two ends to every link, though. The source document (the one being indexed) links to a target document, and some search engines also take this into account when indexing a page. The words contained within a hyperlink may also be indexed as hits for the target document.
In this manner, a URL that has never been crawled can still appear in search results, because the index still contains information about that URL. This definitely applies to Google, and may apply to other search engines as well. Only Google provides enough public information about its processes for us to be sure.
Even with Google, it’s unclear whether such hits are stored in the main indexes, or in a separate index of link-related hits. There are indications, for example, that the ordering and proximity of words in anchor text is a factor in determining how much the link text affects a page’s overall ranking for a given search query.
Results of the Indexing Phase
At the end of the indexing phase, the search engine is capable of returning the indexed URL in search results. If the search engine makes heavy use of link analysis in its ranking algorithm, the URL may not rank well for competitive search terms, but it is at least visible in the search results.
Note: We conclude our discussion of this phase with another example from Google. As mentioned in our examination of the crawling phase, Google’s site:domain search shows all known URLs for a domain, including those which are not yet crawled and indexed. In order to find all of the indexed pages from a domain, a different approach is required. Most sites will have some signature text which appears on all pages, such as the copyright notice etc.
By combining the site:domain search with this signature text, it’s possible to get a true measure of a site’s index saturation, or the number of pages from the site which have been indexed. For example, the query site:example.com copyright will return all of the indexed pages from example.com, assuming that the work ‘copyright’ appears on all pages.
Link Analysis
The content of documents is susceptible to manipulation or optimization, so there may be a large number of Web pages that appear, at first glance, to be relevant to given keywords. Indeed, there may be millions of pages that match the searcher’s query to some degree. Conversely, some highly relevant pages may not be optimized. As a result, search engines can’t simply rely on the content of documents as a means by which to assess them – to do so would prevent the engines from showing the best possible search results.
There are many ways in which search engines can derive information from the linking relationships between pages, and each search engine takes a different approach to doing so. In this brief summary, we’ll see how links can imply topical relationships and help search engines find the Web pages that are most important to their index. To start off, let’s look at a couple very small Web graphs to understand how a search engine might interpret the linking relationships between Web pages. A Web graph is simply a diagram of the linking relationships between a group of pages.
Figure 1.2. Simple Web graph: one page “votes” for two others.
In Figure 1.2, we see three pages (A, B, and C). A links to both B and C. This implies that the content of B and C may relate to the topic discussed on page A. It also implies that the author of page A considers B and C useful – in effect, the author of A is “voting” for B and C.
Figure 1.3. Simple Web graph: two pages “vote” for one page.

In Figure 1.3, both A and B link to page C. This implies that pages A and B cover the same topic as page C, and that the authors of A and B are voting for page C. The implied topical relationship between A and B is as strong, or stronger, than in the previous example, because two pages that are found to link to the same resource are likely related to the same topic.
Figure 1.4. Simple Web graph: two pages interlinked; a third links to both.
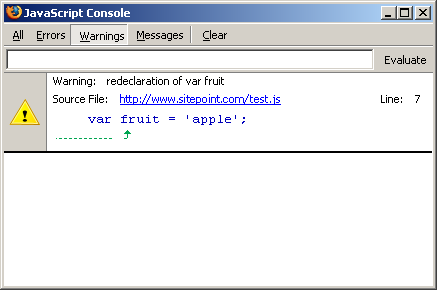
In Figure 1.4, we see a more complex relationship. Pages A and B link to each other, implying that they may address the same topic. The existence of links from C to both A and B validates this interlinking and provides a strong indication that pages A and B mention the same topic.
Hubs and Authorities
The first really interesting attempt to harness the linking relationships between pages was the HITS (Hypertext-Induced Topic Selection) algorithm developed by Jon Kleinberg at Cornell University. Kleinberg’s great revelation was that communities on the Web tend to cluster around specific hubs and authorities.
A hub is a page that contains links to many other pages on the same topic. A good example of a hub would be a page from Yahoo! or the Open Directory which contained a list of pages about a single topic. An authority is a page to which many other pages link. A page that’s listed within the appropriate category on many directories, or is otherwise well-linked within the community of related pages, is considered an authority.
Though the concept is simple, its practical implementation involves many nuances. Many attempts have been made to improve on the basic idea of HITS and, no doubt, some of these ideas are in use within search engines today. One such idea advocates that more focused hub pages are those that link to specific pages, rather than the homepage of every site, thereby implying that more editorial effort went into creating the hub page.
Google’s PageRank
Because of the dominant role Google plays in today’s search engine landscape, and because of the incredible amount of insight it allows into its inner workings, the PageRank algorithm that this search engine uses has taken on an almost mythical status among SEO practitioners.
Many very detailed explanations of PageRank are available on the Web. The original paper written by Google founders Larry P age (the “Page” in PageRank) and Sergey Brin is called The PageRank Citation: Bringing Order to the Web, and is available in multiple formats online.
In addition to the many papers published by Stanford and Google researchers, numerous competing (and occasionally conflicting) accounts have been prepared by SEO consultants. I list many authoritative papers and provide an explanation of PageRank in Appendix A, Resources; for now, let’s briefly discuss how PageRank works without getting bogged in mathematical detail.
The concept of PageRank is very similar to the “wandering drunk” algorithm employed in many areas of computer science, and to the proverbial thousands of monkeys that eventually type long enough to reproduce Shakespeare’s Hamlet.
To understand this concept, let’s consider a random Web surfer. We’ll make him male, and call him Bob. To get Bob started, we’ll sit him down with the browser open at a Web page that’s selected at random from our index. If there are a million pages in our index, there’s a one-in-a-million chance that Bob starts at any particular one of them.
Bob’s job is to pick a random link on every page he visits, and continue on to wherever that link sends him. On each page Bob visits, including the first, there’s a chance that he’ll get bored and ask for a different random Web page. So, when he gets bored, we select another page completely at random, and the process starts again. In Page and Brin’s paper, there is a 15% chance that Bob will get bored on any page.
If we let Bob surf the pages in our index in this way for a decade or so, he will eventually visit every page. Once Bob has viewed every page at least once, we can count the number of times he’s visited each page in the index. The pages that Bob has visited the most times will be allotted the highest PageRank. To put this another way, the PageRank score of a given Web page is an estimate of the probability that a random surfer would find that page if they followed the process that Bob followed.
Now, if Bob starts surfing from a page with a very high PageRank, we can assume that any page it links to will have a high probability of being found by Bob. As such, you might think that links from a page with a high PageRank would be the most valuable.
However, this is not the case. The more links there are on a page, the less likely it is that any particular link will be chosen by a random surfer. This leads us to PageRank Truth #1:
The value of any link from a Web page is decreased proportionally for every additional link on that page.
This is why links from a pure directory like the Open Directory may actually be more valuable than links from a Web portal that happens to include a directory. In a pure directory, nearly all the PageRank attributed to the homepage flows through to the category listings.
By comparison, of the vast number of links that appear on each page of the Yahoo! site, only a certain percentage link to directory pages. Over 200 links appear on the Yahoo! homepage, most of which lead away from the directory. Even the directory pages themselves display many listings and other links.
Likewise, links from a highly selective directory are likely to be worth more than a less selective directory of equal size, because there will be fewer links (or listings) on each of the category pages.
The same logic applies to all links. If you are interested in maximizing the PageRank of the pages on your site, simply looking for high PageRank pages may not be the best approach. Link placement (i.e. which page carries the link) matters much more than the average site owner realizes. We’ll have much more to say on PageRank and linking strategies later in this kit. But for now, let’s turn our attention to the final piece of the link analysis puzzle.
Topics and Communities
Search engines know that many hyperlinks exist solely for the purpose of boosting the perceived popularity of a site in order to improve its ranking in the search results. PageRank is susceptible to this sort of manipulation, as are older link analysis schemes based on link popularity (a simple count of the number of links to a particular page or site).
The cutting edge of link analysis, therefore, goes into a deeper exploration of the topical relationships between Web pages. The Teoma search engine, for example, sees the Web as a set of topical communities, and looks for the most relevant and authoritative pages within a topic. This was actually the basis of the HITS research, but HITS involved the manual selection of pages. Any sort of practical implementation of a topically-driven link analysis scheme requires some sort of automated method of performing “topic distillation” on a given Web page.
Appendix A, Resources contains many references that deal with topic distillation and link analysis, including a topic-sensitive variation on PageRank, and a scheme referred to as LocalRank. LocalRank involves the calculation of an internal PageRank score within the set of pages returned by a Web search, so that the results can be rearranged on the basis of topical authority.
Link analysis and topic distillation are fascinating topics. What they mean to SEO consultants will be explained in greater detail in the next chapter.
How Queries Are Processed
Today’s search engines handle many different types of search queries. Searches run the gamut from FedEx package tracking, phone numbers, and dictionary definition lookups, to the plain old text-based searches that started it all.
Before retrieving search results, the search engine needs to interpret the user’s query. Such an interpretation necessitates the extraction of any special syntax or search options that the user has invoked, such as a site-specific search, reverse phone directory lookup, or other options. Assuming that a text-based search is required (and it’s not something easier, like a FedEx number), the processes that take place will differ depending on the search engine being used.
All the major search engines make some attempt to interpret the searcher’s intent as indicated by the search terms he or she entered. Certain words, or types of words, may give clues that can help the search engine deliver the most satisfactory results. To give you a simple example, a person who searches for brake repair is probably looking for information. In this case, a mix of informational and how-to sites, along with a couple of nationwide chains, would be a good set of search results for most users. By comparison, someone who searches for brake repair Chicago obviously has one thing in mind: finding someone to fix their brakes. Once the searcher has made his or her intent clear like this, it’s much easier for the search engine to help them find what they’re looking for.
What should be clear to you, though, is that different search terms are interpreted in different ways by different search engines. Though semantic analysis (the art of trying to determine the meaning of the words used in a search) is just coming into its own, already it plays a significant role in the search process. It’s likely that at least some elements of the algorithms used by many search engines to determine search results and rankings are already modified to address the type of search query that’s performed.
Search engines also have a set of so-called stop words – extremely common words like a, and, and the. Although these words are supposed to be ignored by the search engine, they do have an influence on search results. A search for watching and waiting on almost any search engine will return different results than a search for watching waiting, even though the search engines claim to ignore the word and. It’s likely that search engines replace the stop word with a wildcard, so that any word positioned between watching and waiting could pass for a matching phrase.
We will discuss how people search, how different types of searches indicate different buying modes, and what it all means to your strategy, in the next chapter.
Information Retrieval (IR) Theory
The godfather of text-based information retrieval was Gerald Salton (1927–1995), a professor at Cornell University. Salton’s group at Cornell developed the SMART information retrieval system. This system pioneered the vector space model that’s now used in some form or other by all crawling search engines.
The vector space model is conceptually simple: take the contents of a set of documents, create an index of every word occurrence in every document, and combine this information to create a mathematical representation of each document within a multi-dimensional vector space. Once you’ve done that, all you need to do is create a vector that represents your search query, and present the documents that are closest to it in the vector space.
Okay… maybe it’s not so simple after all!
If you think the vector space model sounds complicated, you’re not alone. And I didn’t even explain how it takes the dot product of the magnitudes of the query and document vectors, calculates the cosine of the angle between them, and compares the cosines of the dot products of the query vector and the different document vectors, in order to find the most relevant documents for the query!
The good news is that an elaborate mathematical explanation of this concept is not necessarily important to search engine marketing. That said, there are a few things you need to understand about the field of information retrieval theory and the vector space model:
- Words that appear more frequently within the collection of documents being searched are seen as less important in the retrieval of documents. Conversely, words that appear less frequently within the collection of documents are deemed more important in the retrieval of documents. So, if you search for defenestration policy guidelines, the less common word defenestration will have a greater influence on the retrieval process.
- The proximity and ordering of words within a document is significant. If you searched for red monkey shoes, a document containing that exact phrase would be considered more relevant than a document that contained the words in a different sequence or in close proximity, either of which would, in turn, be seen as more relevant than a document that merely contained all three words.
- Search engines make use of the structural and presentational elements of hypertext. Words that appear within key structural elements (page title, headings, hyperlinks etc.), to which significant formatting has been applied (bold, italic, large type), or which appear near the top of the document, are given more relevance than words that appear elsewhere within that document. In other words, occurrences of a given word can be weighted differently depending on where and how they appear in a document.
The Vector Space Model in Action
Just in case you’re interested in digging deeper into the vector space, I thought I’d take a moment to explore it in more detail here.
As we’ve already seen, the search engine is not looking at documents; it’s using an inverted index that maps words to their specific appearances within indexed documents. This is important, so do whatever you have to do to lock this concept into your brain.
When you perform a search, the ranking/retrieval component of the search engine constructs a set of vectors for matching documents within the index, and a separate vector for the search query itself. Don’t get hung up on the term vector – a vector is just a collection of variables that relate to a specific item.
Each occurrence of a word within a document is weighted differently depending on a number of factors, including where the word occurs (e.g. is it a heading or bold text?). If these considerations are factored into the indexing process, the search engine may save some time during the search, but it will also forfeit the flexibility to change elements’ weights depending on the specific search query.
The weighted occurrences of terms within a document are combined with the overall frequency with which the word occurs in the total collection of documents, and within the document itself, to produce a set of “term weights” for the document. The collection of term weights for all the words in the query represents that document’s vector.
The query vector is an idealized set of term weights for the words in the query. To find the most relevant documents in its index, the search engine applies a little math that identifies the closest document matches in vector space. I won’t even attempt to explain the math this involves – see Dr Garcia’s Website for a detailed explanation.
Ranking and Retrieval Strategies
At some point, the search engine has to return results to the searcher. All the work that’s lead up to this point has given the search engine a certain understanding of the user’s query, and a great deal of information about the contents of each page.
There’s one misconception about search result delivery that I should clear up now. A typical SERP will include some message like, “Results 1-10 of 843,000.” What that means is that there were a total of approximately 843,000 pages that might have been relevant to the query. Search engines don’t really examine all 843,000 in order to deliver search results.
In reality, none of the major search engines delivers more than 1,000 total matches, presumably because users would get tired before they actually clicked through to the hundredth page of search results. And, because search engines don’t have to deliver more than 1,000 matches, they can use a pre-selection process to winnow the 843,000 candidates down to a smaller number of returned results. A page that isn’t among the top 1,000 results for any specific factor in the selection process has no chance whatsoever of appearing in the search results.
The factors involved in that selection process are very dependent on the search query itself, and this is one of the instances in which less common words (such as defenestration) are likely to have a greater influence than commonly used words (like free or cheap).
Once the pre-selection is made, the search engine applies its ranking algorithm to the pages that made the cut, and presents a selection to the user as search results.
Query-Dependent Ranking Strategies
The type of search query that’s entered can affect the way in which the search engine approaches the problem of delivering results. Every search engine has its own unique algorithm, but the results will always come from some combination of on-page factors, including content, formatting and structure, and off-page factors, such as link analysis and topic distillation.
For shorter, more generic queries, the initial result set will be very large, and there’s a very good chance that the vector space model based on page content will fail to deliver satisfactory results. With such queries, ranking factors based on link analysis must play a significant role in the pre-selection process, and in determining the final results.
For longer, more specific queries, the initial result set will be smaller, so content-based strategies such as the vector space model may be more appropriate. This doesn’t mean that all search engines will treat these queries differently, but it’s a definite possibility.
Does the Topic Come into Play?
Although topical factors are definitely put to use by some search engines (notably Teoma), the extent of their impact is unknown. One of the difficulties search engines face in applying topic distillation and topical link analysis is that these algorithms need an idea of the query’s topic in order to work.
For very long search queries, this is probably fairly easy to determine, but the vector space model already performs very well with long queries. In this case, a topical algorithm may be overkill, and may even lead to results that are less relevant to the specific query than they are to a related topic.
For very short queries, with which the vector space model needs help, it can be very difficult to determine an appropriate topic. My favorite example of this type of query is barber shop. This might be a place to get a haircut, but it’s also the title of a popular comedy film series, and a form of a capella music performed by four men wearing striped shirts.
Because the importance of topical algorithms is uncertain, much of our discussion of topical factors may be less than completely relevant today. However, search engine optimization is very much a long-term game, and the trend towards topic distillation and topical link analysis is too strong to ignore.
Call it future-proofing if you like, but throughout this kit I will encourage you to adopt topical strategies in your content, copywriting, and link strategies.
Other Considerations
In addition to the basic processes we’ve just described, which are responsible for creating search results and rankings, search engines have a number of parallel activities that are worth a quick look.
Nearly all search engines undertake some form of automated monitoring of search quality. Google and Yahoo! both use a tracking link that allows them to know which of the search listings has been clicked. If a highly popular search phrase does not generate an acceptable number of clicks for the top-ranked pages, the search engine may consider adjusting its algorithm to deliver more satisfactory search results. Note, though, that this is not the same as Direct Hit technology, in which user clicks directly influence search results.
The search quality team, in addition to seeking out areas for improvement in search results, is responsible for the review and removal of sites that attempt to “spam” or deceive the search engine. For the most part, search engines can’t act on individual spam reports, but must instead identify the techniques being used by spammers. When a new technique is identified, the software engineers attempt to find an automated means of detecting and filtering that form of spam from the search results.
Judging from the countless panic-stricken site owners who post every day to online discussion forums, many folks assume that a “spam penalty” is the most common reason for a site or page to drop out of the search results. In fact, such penalties are extremely uncommon and, in most cases, the explanation is far more mundane.
Any Website operator whose pages suddenly disappear from a search engine will be upset, but the problem almost always lies on their side of the equation. As mentioned above, not all Websites are ready to answer when the spider calls, and this can cause the search engines to stop crawling for a time. Server and DNS errors are the most common reasons for pages to be removed from a search engine’s index.
In addition to the automated processes that may remove pages, search engines must comply with copyright laws such as the Digital Millennium Copyright Act (DMCA), which applies in the US. DMCA notifications represent a significant burden for search engines and other online service providers.
Unlike Web hosting companies, search engines usually do not have the means to contact the site owner quickly in order to allow for an appeal, and pages may be removed on the grounds of copyright infringement without the site owner ever becoming aware of the action. When Google deletes a page from its index for this reason, a link may be displayed on some search results to indicate that the page has been removed.
All of the major search engines must deal with a high volume of search requests from users, as well as peak hour demands that can easily be five times higher than their quiet times. In order to deliver search results in a hurry, no matter what the traffic levels, today’s search engines use load balancing techniques across multiple data centers located strategically around the world.
It’s not easy to run a search engine, and that fact goes a long way toward explaining why there are so few of them in the market today.
What Search Engines Want
One of the keys to developing a long term search engine strategy for any Website is an understanding of what search engines want. Repeat visitors drive revenue, so the major goal of any search engine is to keep its users happy. A few lessons from the past can help shed a little light on the future.
Freshness is critical. The once mighty AltaVista search engine (now a Yahoo! property) lost users to Google and the Inktomi-driven search portals for one major reason: it stopped crawling the Web aggressively, and failed to update the index on a regular basis. The lack of freshness in the AltaVista search results meant that many SERPs contained mostly broken links. Don’t expect any search engine operating today to make the same mistake.
Snapshot of the Search Market
Search engine usage varies substantially from country to country. Here’s a snapshot of the top ten search engines in various countries for a given week in December, 2004. The data was provided by Hitwise and should prove valuable to an SEM practitioner who wishes to target campaigns to any of these areas.
The most popular search engines visited by US Internet users for the week ending 12/18/04 are shown in Table 1.2.
Table 1.2. Popular Search Engines: USA
The most popular search engines visited by UK Internet users during the week ending 12/18/04 are displayed in Table 1.3.
Table 1.3. Popular Search Engines: UK
The most popular search engines visited by Australian Internet users in the week ending 12/18/04 are presented in Table 1.4.
Table 1.4. Popular Search Engines: Australia
The most popular search engines visited by New Zealand Internet users in that same week are shown in Table 1.5.
Table 1.5. Popular Search Engines: New Zealand
The most popular search engines visited by Hong Kong Internet users for the week ending 12/18/04 are as show in Table 1.6.
Table 1.6. Popular Search Engines: Hong Kong

The most popular search engines visited by Internet users in Singapore in the week ending 12/18/04 were as shown in Table 1.7 below.
Table 1.7. Popular Search Engines: Singapore
The Future of Search
While search engines today have, without a doubt, reached the point at which they’re exceptionally useful, there’s still a lot of work to be done before users can trust them for every type of search. Additionally, in terms of search success, a great deal still depends on user knowledge of individual systems.
Anticipated improvements in search technology lie in three major areas: localization, context, and the so-called Semantic Web. The first two deal primarily with gaining a better understanding of users’ needs; the third offers opportunities to improve the efficiency of indexing and the quality of search results.
Localization
Many search engines offer local search options, whether they’re explicit, such as Google’s Local Search, currently in beta, or implicit. For instance, the addition of a zip/postal code to any search on Google or Yahoo! brings local search elements into action. Unfortunately, users aren’t used to inputting a zip code when they search.
One of the most famous cities in the world is Springfield, the setting for the popular Simpsons cartoon series. It’s sort of a running joke in the series that nobody knows which Springfield they’re talking about – there are numerous towns of that name in the United States – although, in reality, the Simpsons live in a purely fictional city. This reflects a major challenge that’s inherent in implicit local searches: many cities have the same name.
If an implicit local search isn’t possible (as would be the case for a search on real estate Springfield), search engines can prompt users to clarify which city they’re looking for – provided it can be identified as a city. But, what if someone searches for marketing wisdom? Do you know whether they want marketing advice, or marketing firms in Wisdom, Montana?
Part of the solution lies in the emerging geo-targeting technologies that attempt to identify users’ locations on the basis of their IP addresses. This technology is already used by Google AdWords and Overture to let PPC advertisers target specific locations and exclude others.
Geo-targeting may be part of the overall localization solution, but the current methods suffer two problems that are not so easy to overcome. The first is the use of proxy servers by some Web users, especially those on corporate networks. The firewall through which these users access the Web may be housed a long way from their physical location. This becomes a significant issue with geo-targeting in PPC advertising campaigns, particularly in major business to business markets.
The second problem is that not all local searches are intended for the user’s current location. If I’m sitting at my desk in Frisco, Texas, and I search for Cleveland hotels, a geo-targeting system might think that I’m looking for hotels in Cleveland, Texas instead of Cleveland, Ohio.
Given the popularity of the browser toolbar additions distributed by all the major search engines, it’s possible that some user profile information may eventually be incorporated into the delivery of search results. That will take care of where the user is coming from. An even bigger problem is figuring out the geographic scope of a Website. The world headquarters of Exxon-Mobil, for example, are in Dallas, Texas, but someone searching for Exxon in Chicago just might be looking for a gas station closer to home.
To determine which country a Website belongs to can be tricky, too. For search engines like Google that offer country-specific search options, this is a very real problem. It’s easy to include all sites that use the appropriate country’s top level domain (such as .au for Australia), but many sites around the world use .com, .net, .biz, .info and other global TLDs. SitePoint.com, for example, is based in Australia, but serves a global audience. Google’s solution is to use IP-based lookups to determine where the DNS servers for the domain are located, but this has caused more than a few problems, and it’s basically a “better than nothing” solution.
Despite all these challenges, we can expect search engines to move forward with efforts to localize their search offerings. Localization holds the promise of more relevant results (which helps keep users loyal), and offers substantial profit gains for those using PPC advertising programs.
Context and Personalization
If there’s one thing that’s destined to shatter the old illusions about search engine optimization, it’s the coming rise of context and personalization. Google and Microsoft have already shown personalized search offerings, and the results are simply too compelling to ignore.
Google’s Personalized Search system invites the user to select one or more topics from a list, then returns search results that are slightly skewed toward those topics. Depending on the mix of topics selected, it’s possible to produce very different results. This system shows how far Google has progressed in its implementation of topic distillation.
Microsoft’s system isn’t a product yet – it’s still a research project – but it provides some very useful insights into the ways that the company’s offerings may differ from those of other major players. Called “Stuff I’ve Seen,” it’s designed to confine a user’s search to Websites or documents that they’ve already seen.
When you put these two ideas together – as someone certainly will – you get a search that’s different for each user, depending on their browsing and searching history. The search toolbars that the major search engines offer as browser plug-ins are already very popular; all they need in order to extend these services is users’ permission to gather and use their browse and search data.
Not everyone will climb aboard the personalized search bandwagon (privacy concerns will need to be allayed), but you can expect the search engines to make an effort to promote this kind of service in coming years. My bet is that the majority of users will be happy to share a little semi-anonymous information if it helps them find what they’re looking for.
Search results for many queries already differ from one location to the next on some search engines. Given the compelling opportunities created by personalized search, will search engine rankings as we know them today even exist in 2006?
Structure and the Semantic Web
Tim Berners-Lee, inventor of the World Wide Web, has a plan for the future of the Web, or at least, the next version of it. The Semantic Web is built on top of the existing Internet structure, in a sense, in that it doesn’t really involve eradicating the old Web. The Semantic Web is all about creating structure by providing a great deal more data about the different resources available online.
As I mentioned earlier in this chapter, some search engines already accept XML-based trusted feeds from some Websites, and/or read RDF Site Summary (RSS) files when they’re available. Yahoo! has been particularly active in this area.
RSS, and Google-endorsed alternative Atom, are designed to let site owners provide more detailed and structured data about the resources available on their sites. In current practice, this is used mainly to provide news feeds for blogs, news sites, and similar content portals. Other sites can process these news feeds and make headlines and other information available to their visitors.
The Semantic Web is just beginning to take hold, but as more sites offer summaries and structured data, it is inevitable that search engines will find ways to make use of this new information source. It’s not going to change the world tomorrow, but it’s definitely the shape of things to come.
Summary
The main goal in this chapter was to provide a detailed picture of how search engines work, and where search results come from. To keep you from falling asleep, I’ve mixed in a few little tidbits and insights that you can use right away.
Note: Note to search engine marketing consultants: as you begin to think of yourself as a professional SEO or SEM consultant (and maybe you already do), I’m sure you can see how this kind of knowledge will help you position yourself in the eyes of clients. People trust experts, and you will certainly be seen as one if you can answer questions in detail, and clear up your client’s own misconceptions about search engines.
The next chapter will dig more deeply into the process of search engine optimization, and introduce you to many of the practical aspects of what you’ve just learned.
That’s it for this sample of The Search Engine Marketing Kit. What’s next?
Download this chapter in PDF format, and you’ll have a copy you can refer to at any time.
Review the kit’s table of contents to find out exactly what’s included.
Buy your own copy of the kit now, right here at SitePoint.com.
We hope you enjoy The Search Engine Marketing Kit.
Frequently Asked Questions (FAQs) about Search Engine Marketing
What is the importance of Search Engine Marketing (SEM) in today’s digital world?
In today’s digital era, SEM plays a crucial role in enhancing the visibility of your website on search engine result pages (SERPs). It is a powerful tool that helps businesses reach their target audience who are actively searching for products or services similar to theirs. SEM can significantly increase your website’s traffic, improve brand awareness, and generate leads, thereby contributing to business growth.
How does SEM differ from SEO?
While both SEM and SEO aim to increase website visibility and traffic, they do so in different ways. SEO focuses on organic search results and involves optimizing your website to rank higher on SERPs. On the other hand, SEM involves paid advertising strategies like pay-per-click (PPC) ads, where you pay for your ads to appear on SERPs.
What are the key components of a successful SEM strategy?
A successful SEM strategy comprises several components, including keyword research, competitive analysis, paid advertising, landing page optimization, and performance tracking. It’s essential to choose the right keywords, understand your competition, create compelling ads, optimize your landing pages for conversions, and regularly monitor and adjust your strategy based on performance metrics.
How can I optimize my SEM campaigns for better results?
Optimizing your SEM campaigns involves several steps. Firstly, conduct thorough keyword research to identify high-performing keywords. Secondly, create compelling ad copies that resonate with your target audience. Thirdly, optimize your landing pages to improve user experience and conversion rates. Lastly, monitor your campaign performance regularly and make necessary adjustments for continuous improvement.
What are the benefits of using Google Ads for SEM?
Google Ads is a popular platform for SEM due to its extensive reach and advanced targeting options. It allows businesses to reach potential customers who are actively searching for their products or services. With Google Ads, you can target your ads based on keywords, location, demographics, and more. Plus, you only pay when someone clicks on your ad, making it a cost-effective advertising solution.
How can I measure the success of my SEM campaigns?
The success of SEM campaigns can be measured using various metrics such as click-through rate (CTR), conversion rate, cost per click (CPC), and return on investment (ROI). These metrics provide insights into how well your ads are performing and whether they are driving the desired actions.
Can SEM help improve my website’s SEO?
While SEM and SEO are separate strategies, they can complement each other. The increased visibility and traffic from SEM can indirectly benefit your SEO efforts by potentially increasing your website’s authority. Moreover, the keyword insights gained from SEM can also be used to optimize your SEO strategy.
What are some common mistakes to avoid in SEM?
Common mistakes in SEM include not conducting thorough keyword research, targeting the wrong audience, creating unappealing ad copies, neglecting landing page optimization, and not tracking performance metrics. Avoiding these mistakes can significantly improve the effectiveness of your SEM campaigns.
How can I get started with SEM?
To get started with SEM, first, define your marketing goals. Then, conduct keyword research to identify relevant keywords for your business. Next, set up your SEM account (e.g., Google Ads), create your ads, and set your budget. Finally, launch your campaign and monitor its performance regularly to make necessary adjustments.
Can I manage my SEM campaigns on my own, or should I hire a professional?
While it’s possible to manage your SEM campaigns on your own, it can be time-consuming and require a steep learning curve. Hiring a professional can save you time and ensure your campaigns are optimized for the best results. However, if you’re on a tight budget or want to learn more about SEM, there are plenty of resources available online to help you get started.