


Key Takeaways
- Utilize `try…catch` blocks strategically to manage exceptions effectively and enhance the debugging process by allowing errors to bubble up the call stack for clearer visibility.
- Implement global error handlers, such as the `window.onerror` event, to centralize and streamline error handling, making it easier to manage and maintain across different parts of your application.
- Leverage the browser’s ability to log detailed error information, including the call stack, to improve error diagnostics and provide clearer insights into the source and context of errors.
- Address asynchronous error handling challenges by using `setTimeout` within `try…catch` blocks or employing global error handlers that work across all executing contexts, ensuring that errors in asynchronous code are caught and managed effectively.
- Enhance error information by creating custom error types or enriching error messages, facilitating easier identification and resolution of specific issues, and improving the overall robustness of your JavaScript code.
Ah, the perils of error handling in JavaScript. If you believe Murphy’s law, anything that can go wrong, will go wrong. In this article, I would like to explore error handling in JavaScript. I will cover pitfalls, good practices, and finish with asynchronous code and Ajax.
This popular article was updated on 08.06.2017 to address reader feedback. Specifically, file names were added to snippets, unit tests were cleaned up, wrapper pattern was added to
uglyHandler, sections on CORS and 3rd party error handlers were added.
I feel JavaScript’s event-driven paradigm adds richness to the language. I like to imagine the browser as this event-driven machine, and errors are no different. When an error occurs, an event gets thrown at some point. In theory, one could argue errors are simple events in JavaScript.
If this sounds foreign to you, buckle up as you are in for quite a ride. For this article, I will focus only on client-side JavaScript.
This topic builds on concepts explained in Exceptional Exception Handling in JavaScript. I recommend reading up on the basics if you are not familiar. This article also assumes an intermediate level of JavaScript knowledge. If you’re looking to level up, why not sign up for SitePoint Premium and watch our course JavaScript: Next Steps. The first lesson is free.
In either case, my goal is to explore beyond the bare necessities for handling exceptions. Reading this article will make you think twice the next time you see a nice try...catch block.
The Demo
The demo we’ll be using for this article is available on GitHub, and presents a page like this:
All buttons detonate a “bomb” when clicked. This bomb simulates an exception that gets thrown as a TypeError. Below is the definition of such a module:
// scripts/error.js
function error() {
var foo = {};
return foo.bar();
}
To begin, this function declares an empty object named foo. Note that bar() does not get a definition anywhere. Let’s verify that this will detonate a bomb with a good unit test:
// tests/scripts/errorTest.js
it('throws a TypeError', function () {
should.throws(error, TypeError);
});
This unit test is in Mocha with test assertions in Should.js. Mocha is a test runner while Should.js is the assertion library. Feel free to explore the testing APIs if you are not already familiar. A test begins with it('description') and ends with a pass / fail in should. The unit tests run on Node and do not need a browser. I recommend paying attention to the tests as they prove out key concepts in plain JavaScript.
Once you have cloned the repo and installed the dependencies, you can run the tests using
npm t. Alternatively, you can run this individual test like so:./node_modules/mocha/bin/mocha tests/scripts/errorTest.js.
As shown, error() defines an empty object then it tries to access a method. Because bar() does not exist within the object, it throws an exception. Believe me, with a dynamic language like JavaScript this happens to everyone!
The Bad
On to some bad error handling. I have abstracted the handler on the button from the implementation. Here is what the handler looks like:
// scripts/badHandler.js
function badHandler(fn) {
try {
return fn();
} catch (e) { }
return null;
}
This handler receives a fn callback as a parameter. This callback then gets called inside the handler function. The unit tests show how it is useful:
// tests/scripts/badHandlerTest.js
it('returns a value without errors', function() {
var fn = function() {
return 1;
};
var result = badHandler(fn);
result.should.equal(1);
});
it('returns a null with errors', function() {
var fn = function() {
throw new Error('random error');
};
var result = badHandler(fn);
should(result).equal(null);
});
As you can see, this bad error handler returns null if something goes wrong. The callback fn() can point to a legit method or a bomb.
The click event handler below tells the rest of the story:
// scripts/badHandlerDom.js
(function (handler, bomb) {
var badButton = document.getElementById('bad');
if (badButton) {
badButton.addEventListener('click', function () {
handler(bomb);
console.log('Imagine, getting promoted for hiding mistakes');
});
}
}(badHandler, error));
What stinks is I only get a null. This leaves me blind when I try to figure out what went wrong. This fail-silent strategy can range from bad UX all the way down to data corruption. What is frustrating with this is I can spend hours debugging the symptom but miss the try-catch block. This wicked handler swallows mistakes in the code and pretends all is well. This may be okay with organizations that don’t sweat code quality. But, hiding mistakes will find you debugging for hours in the future. In a multi-layered solution with deep call stacks, it is impossible to figure out where it went wrong. As far as error handling, this is pretty bad.
A fail-silent strategy will leave you pining for better error handling. JavaScript offers a more elegant way of dealing with exceptions.
The Ugly
Time to investigate an ugly handler. I will skip the part that gets tight-coupled to the DOM. There is no difference here from the bad handler you saw.
// scripts/uglyHandler.js
function uglyHandler(fn) {
try {
return fn();
} catch (e) {
throw new Error('a new error');
}
}
What matters is the way it handles exceptions as shown below with this unit test:
// tests/scripts/uglyHandlerTest.js
it('returns a new error with errors', function () {
var fn = function () {
throw new TypeError('type error');
};
should.throws(function () {
uglyHandler(fn);
}, Error);
});
A definite improvement over the bad handler. Here the exception gets bubbled through the call stack. What I like is now errors will unwind the stack which is super helpful in debugging. With an exception, the interpreter travels up the stack looking for another handler. This opens many opportunities to deal with errors at the top of the call stack. Unfortunately, since it is an ugly handler I lose the original error. So I am forced to traverse back down the stack to figure out the original exception. With this at least I know something went wrong, which is why you throw an exception.
As an alternative, is is possible to end the ugly handler with a custom error. When you add more details to an error it is no longer ugly but helpful. The key is to append specific information about the error.
For example:
// scripts/specifiedError.js
// Create a custom error
var SpecifiedError = function SpecifiedError(message) {
this.name = 'SpecifiedError';
this.message = message || '';
this.stack = (new Error()).stack;
};
SpecifiedError.prototype = new Error();
SpecifiedError.prototype.constructor = SpecifiedError;
// scripts/uglyHandlerImproved.js
function uglyHandlerImproved(fn) {
try {
return fn();
} catch (e) {
throw new SpecifiedError(e.message);
}
}
// tests/scripts/uglyHandlerImprovedTest.js
it('returns a specified error with errors', function () {
var fn = function () {
throw new TypeError('type error');
};
should.throws(function () {
uglyHandlerImproved(fn);
}, SpecifiedError);
});
The specified error adds more details and keeps the original error message. With this improvement it is no longer an ugly handler but clean and useful.
With these handlers, I still get an unhandled exception. Let’s see if the browser has something up its sleeve to deal with this.
Unwind that Stack
So, one way to unwind exceptions is to place a try...catch at the top of the call stack.
Say for example:
function main(bomb) {
try {
bomb();
} catch (e) {
// Handle all the error things
}
}
But, remember I said the browser is event-driven? Yes, an exception in JavaScript is no more than an event. The interpreter halts execution in the executing context and unwinds. Turns out, there is an onerror global event handler we can use.
And it goes something like this:
// scripts/errorHandlerDom.js
window.addEventListener('error', function (e) {
var error = e.error;
console.log(error);
});
This event handler catches errors within any executing context. Error events get fired from various targets for any kind of error. What is so radical is this event handler centralizes error handling in the code. Like with any other event, you can daisy chain handlers to handle specific errors. This allows error handlers to have a single purpose if you follow SOLID principles. These handlers can get registered at any time. The interpreter will cycle through as many handlers as it needs to. The code base gets freed from try...catch blocks that get peppered all over which makes it easy to debug. The key is to treat error handling like event handling in JavaScript.
Now that there is a way to unwind the stack with global handlers, what can we do with this?
After all, may the call stack be with you.
Capture the Stack
The call stack is super helpful in troubleshooting issues. The good news is that the browser provides this information out of the box. The stack property is not part of the standard, but it is consistently available on the latest browsers.
So, for example, you can now log errors on the server:
// scripts/errorAjaxHandlerDom.js
window.addEventListener('error', function (e) {
var stack = e.error.stack;
var message = e.error.toString();
if (stack) {
message += '\n' + stack;
}
var xhr = new XMLHttpRequest();
xhr.open('POST', '/log', true);
// Fire an Ajax request with error details
xhr.send(message);
});
It may not be obvious from this example, but this will fire alongside the previous example. Every error handler can have a single purpose which keeps the code DRY.
In the browser, event handlers get appended to the DOM. This means if you are building a third party library, your events will coexist with client code. The window.addEventListener() takes care of this for you, it does not blot out existing events.
Here is a screenshot of what this log looks like on the server:
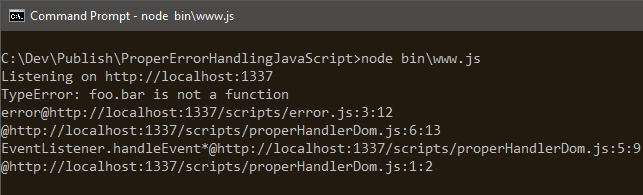
This log lives inside a command prompt, yes, it is unapologetically running on Windows.
This message comes from Firefox Developer Edition 54. With a proper error handler, note that it is crystal clear what the issue is. No need to hide mistakes, by glancing at this, I can see what threw the exception and where. This level of transparency is good for debugging front-end code. You can analyze logs, giving insight on what conditions trigger which errors.
The call stack is helpful for debugging, never underestimate the power of the call stack.
One gotcha is if you have a script from a different domain and enable CORS you won’t see any of the error details. This occurs when you put scripts on a CDN, for example, to exploit the limitation of six requests per domain. The e.message will only say “Script error” which is bad. In JavaScript, error information is only available for a single domain.
One solution is to re-throw errors while keeping the error message:
try {
return fn();
} catch (e) {
throw new Error(e.message);
}
Once you rethrow the error back up, your global error handlers will do the rest of the work. Only make sure your error handlers are on the same domain. You can even wrap it around a custom error with specific error information. This keeps the original message, stack, and custom error object.
Async Handling
Ah, the perils of asynchrony. JavaScript rips asynchronous code out of the executing context. This means exception handlers such as the one below have a problem:
// scripts/asyncHandler.js
function asyncHandler(fn) {
try {
// This rips the potential bomb from the current context
setTimeout(function () {
fn();
}, 1);
} catch (e) { }
}
The unit test tells the rest of the story:
// tests/scripts/asyncHandlerTest.js
it('does not catch exceptions with errors', function () {
// The bomb
var fn = function () {
throw new TypeError('type error');
};
// Check that the exception is not caught
should.doesNotThrow(function () {
asyncHandler(fn);
});
});
The exception does not get caught and I can verify this with this unit test. Note that an unhandled exception occurs, although I have the code wrapped around a nice try...catch. Yes, try...catch statements only work within a single executing context. By the time an exception gets thrown, the interpreter has moved away from the try...catch. This same behavior occurs with Ajax calls too.
So, one alternative is to catch exceptions inside the asynchronous callback:
setTimeout(function () {
try {
fn();
} catch (e) {
// Handle this async error
}
}, 1);
This approach will work, but it leaves much room for improvement. First of all, try...catch blocks get tangled up all over the place. In fact, 1970s bad programming called and they want their code back. Plus, the V8 engine discourages the use of try…catch blocks inside functions. V8 is the JavaScript engine used in the Chrome browser and Node. One idea is to move blocks to the top of the call stack but this does not work for asynchronous code.
So, where does this lead us? There is a reason I said global error handlers operate within any executing context. If you add an error handler to the window object, that’s it, done! It is nice that the decision to stay DRY and SOLID is paying off. A global error handler will keep your async code nice and clean.
Below is what this exception handler reports on the server. Note that if you’re following along, the output you see will be different depending on which browser you use.
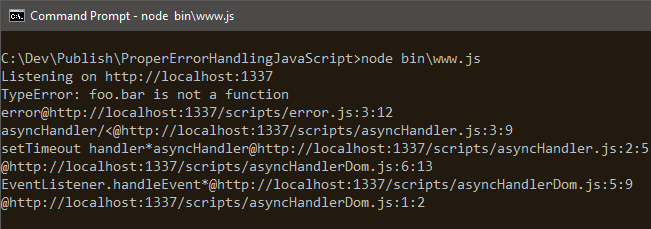
This handler even tells me that the error is coming from asynchronous code. It says it is coming from a setTimeout() function. Too cool!
Conclusion
In the world of error handling, there are at least two approaches. One is the fail-silent approach where you ignore errors in the code. The other is the fail-fast and unwind approach where errors stop the world and rewind. I think it is clear which of the two I am in favor of and why. My take: don’t hide problems. No one will shame you for accidents that may occur in the program. It is acceptable to stop, rewind and give users another try.
In a world that is far from perfect, it is important to allow for a second chance. Errors are inevitable, it’s what you do about them that counts.
This article was peer reviewed by Tim Severien and Moritz Kröger. Thanks to all of SitePoint’s peer reviewers for making SitePoint content the best it can be!
Frequently Asked Questions (FAQs) about Proper Error Handling in JavaScript
What is the importance of proper error handling in JavaScript?
Error handling in JavaScript is crucial for maintaining the integrity and reliability of your code. It allows developers to anticipate potential problems and address them before they cause significant issues. Without proper error handling, a single error can cause a script to stop running, leading to a poor user experience. By implementing error handling, you can provide useful feedback to users and prevent the entire application from crashing due to minor issues.
How does the ‘throw’ statement work in JavaScript?
The ‘throw’ statement in JavaScript allows developers to create custom error messages. When an error is thrown, the JavaScript runtime will stop and look for any catch statement in the call stack. If it finds one, the control is passed to that catch block, otherwise the error message is displayed to the user. This allows for more precise error handling and debugging.
What is the difference between ‘throw’ and ‘try…catch’ in JavaScript?
Throw’ and ‘try…catch’ are both used for error handling in JavaScript, but they serve different purposes. The ‘throw’ statement is used to generate errors. When an error is thrown, the JavaScript runtime will stop and look for a catch statement. On the other hand, ‘try…catch’ is used to handle errors. The ‘try’ block contains the code that might throw an error, and the ‘catch’ block contains the code to handle the error.
How can I handle multiple errors in JavaScript?
To handle multiple errors in JavaScript, you can use multiple ‘catch’ blocks. Each ‘catch’ block can handle a specific type of error. If an error is thrown in the ‘try’ block, JavaScript will attempt to match the error with the appropriate ‘catch’ block. If no match is found, the error will be passed to the next ‘catch’ block, and so on, until it is either handled or it reaches the end of the catch chain.
What is the role of ‘finally’ in JavaScript error handling?
The ‘finally’ block in JavaScript error handling is used to execute code regardless of whether an error was thrown or caught. This is useful for cleaning up after your code, such as closing files or clearing resources, regardless of the outcome of the ‘try’ and ‘catch’ blocks.
How can I create custom error types in JavaScript?
JavaScript allows developers to define custom error types by extending the Error object. This can be done by creating a new object constructor that inherits from the Error object. This allows for more precise error handling and debugging, as you can throw and catch specific custom errors.
What is the difference between a runtime error and a logic error in JavaScript?
A runtime error in JavaScript is an error that occurs during the execution of a program, such as a type error or a syntax error. These errors are usually caused by illegal operations performed by the code. A logic error, on the other hand, is an error that occurs when a program does not perform as intended, even though the syntax is correct. These errors are usually harder to detect and require careful debugging.
How can I handle asynchronous errors in JavaScript?
Asynchronous errors in JavaScript can be handled using promises or async/await. Promises are objects that represent the eventual completion or failure of an asynchronous operation. They can be used to handle asynchronous errors by chaining a ‘catch’ method to the promise. The async/await syntax provides a more readable and concise way to handle asynchronous errors using try/catch blocks.
What is the best practice for error handling in JavaScript?
The best practice for error handling in JavaScript is to anticipate potential errors and handle them proactively. This includes validating user input, using try/catch blocks to handle errors, and throwing custom errors when necessary. It’s also important to provide useful feedback to the user when an error occurs, and to clean up resources in a ‘finally’ block regardless of whether an error was thrown or caught.
How can I debug errors in JavaScript?
Debugging errors in JavaScript can be done using various tools and techniques. The console.log() method can be used to print out values and track the flow of the code. The debugger statement can be used to pause the execution of the code and inspect the current state of the program. Browser developer tools also provide powerful debugging features, such as breakpoints, step-through execution, and real-time editing.