

Key Takeaways
- Utilize Hapi and TypeScript to build a REST API for the Jamstack, enabling independent evolution of client and server sides with high cohesion and low coupling.
- Implement MVC architecture with versioning in folder structure to manage future API changes without breaking existing functionality.
- Leverage Joi for robust validation of REST endpoints, ensuring adherence to HTTP standards and facilitating client-server decoupling.
- Apply behavior-driven development using Hapi’s lab tool for testing, focusing on red/green testing phases to validate API functionality.
- Integrate MongoDB with Mongoose for data persistence, configuring schemas and models to support flexible data handling and versioning.
- Explore practical API testing and interaction using tools like Hoppscotch and cURL, demonstrating real-time request handling and responses.
The Jamstack has a nice way of separating the front end from the back end to where the entire solution doesn’t have to ship in a single monolith — and all at the exact same time. When the Jamstack is paired with a REST API, the client and the API can evolve independently. This means both front and back ends are not tightly coupled, and changing one doesn’t necessarily mean changing the other.
In this article, I’ll take a look at a REST API from the perspective of the Jamstack. I’ll show how to evolve the API without breaking existing clients and adhere to REST standards. I’ll pick Hapi as the tool of choice to build the API, and Joi for endpoint validations. The database persistence layer will go in MongoDB via Mongoose to access the data. Test-driven development will help me iterate through changes and provide a quick way to get feedback with less cognitive load. At the end, the goal is for you to see how REST, and the Jamstack, can provide a solution with high cohesion and low coupling between software modules. This type of architecture is best for distributed systems with lots of microservices each on their own separate domains. I’ll assume a working knowledge of NPM, ES6+, and a basic familiarity with API endpoints.
The API will work with author data, with a name, email, and an optional 1:N (one-to-few via document embedding) relationship on favorite topics. I’ll write a GET, PUT (with an upsert), and DELETE endpoints. To test the API, any client that supports fetch() will do, so I’ll pick Hoppscotch and CURL.
I’ll keep the reading flow of this piece like a tutorial where you can follow along from top to bottom. For those who’d rather skip to the code, it is available on GitHub for your viewing pleasure. This tutorial assumes a working version of Node (preferably the latest LTS) and MongoDB already installed.
Initial Setup
To start the project up from scratch, create a folder and cd into it:
mkdir hapi-authors-rest-api
cd hapi-authors-rest-api
Once inside the project folder, fire up npm init and follow the prompt. This creates a package.json at the root of the folder.
Every Node project has dependencies. I’ll need Hapi, Joi, and Mongoose to get started:
npm i @hapi/hapi joi mongoose --save-exact
- @hapi/hapi: HTTP REST server framework
- Joi: powerful object schema validator
- Mongoose: MongoDB object document modeling
Inspect the package.json to make sure all dependencies and project settings are in place. Then, add an entry point to this project:
"scripts": {
"start": "node index.js"
},
MVC Folder Structure with Versioning
For this REST API, I’ll use a typical MVC folder structure with controllers, routes, and a database model. The controller will have a version like AuthorV1Controller to allow the API to evolve when there are breaking changes to the model. Hapi will have a server.js and index.js to make this project testable via test-driven development. The test folder will contain the unit tests.
Below is the overall folder structure:
┳
┣━┓ config
┃ ┣━━ dev.json
┃ ┗━━ index.js
┣━┓ controllers
┃ ┗━━ AuthorV1Controller.js
┣━┓ model
┃ ┣━━ Author.js
┃ ┗━━ index.js
┣━┓ routes
┃ ┣━━ authors.js
┃ ┗━━ index.js
┣━┓ test
┃ ┗━━ Author.js
┣━━ index.js
┣━━ package.json
┗━━ server.js
For now, go ahead and create the folders and respective files inside each folder.
mkdir config controllers model routes test
touch config/dev.json config/index.js controllers/AuthorV1Controller.js model/Author.js model/index.js routes/authors.js routes/index.js test/Authors.js index.js server.js
This is what each folder is intended for:
config: configuration info to plug into the Mongoose connection and the Hapi server.controllers: these are Hapi handlers that deal with the Request/Response objects. Versioning allows multiple endpoints per version number — that is,/v1/authors,/v2/authors, etc.model: connects to the MongoDB database and defines the Mongoose schema.routes: defines the endpoints with Joi validation for REST purists.test: unit tests via Hapi’s lab tool. (More on this later.)
In a real project, you may find it useful to abstract common business logic into a separate folder, say utils. I recommend creating a AuthorUtil.js module with purely functional code to make this reusable across endpoints and easy to unit test. Because this solution doesn’t have any complex business logic, I’ll choose to skip this folder.
One gotcha to adding more folders is having more layers of abstraction and more cognitive load while making changes. With exceptionally large code bases, it’s easy to get lost in the chaos of layers of misdirection. Sometimes it’s better to keep the folder structure as simple and as flat as possible.
TypeScript
To improve the developer experience, I’ll now add TypeScript type declarations. Because Mongoose and Joi define the model at runtime, there’s little value in adding a type checker at compile time. In TypeScript, it’s possible to add type definitions to a vanilla JavaScript project and still reap the benefits of a type checker in the code editor. Tools like WebStorm or VS Code will pick up type definitions and allow the programmer to “dot” into the code. This technique is often called IntelliSense, and it’s enabled when the IDE has the types available. What you get with this is a nice way to define the programming interface so developers can dot into objects without looking at the documentation. The editor too will sometimes show warnings when developers dot into the wrong object.
This is what IntelliSense looks like in VS Code:
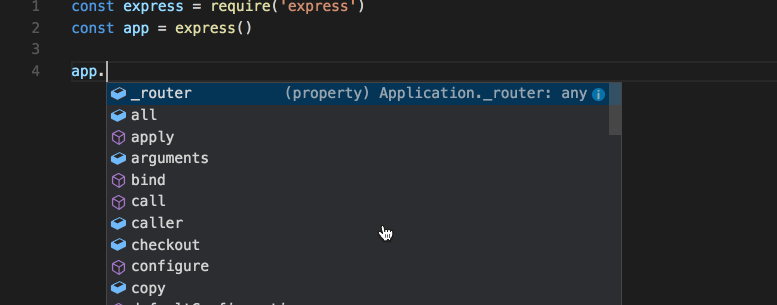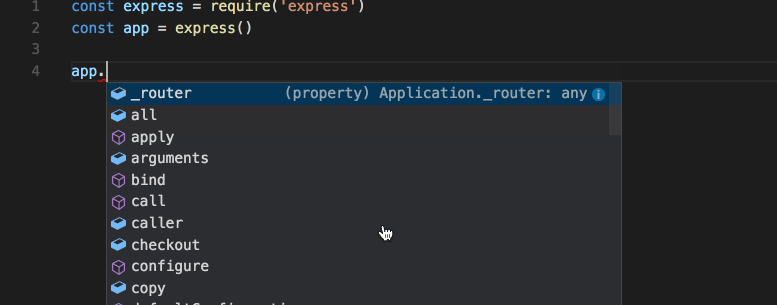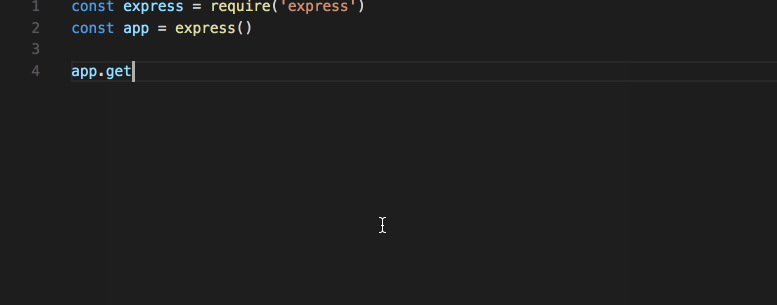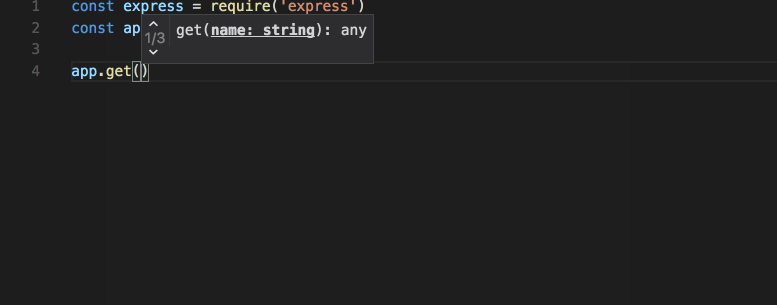
In WebStorm, this is called code completion, but it’s essentially the same thing. Feel free to pick whichever IDE you prefer to write the code. I use Vim and WebStorm, but you may choose differently.
To enable TypeScript type declarations in this project, fire up NPM and save these developer dependencies:
npm i @types/hapi @types/mongoose --save-dev
I recommend keeping developer dependencies separate from app dependencies. This way, it’s clear to other devs in the organization what the packages are meant for. When a build server pulls down the repo, it also has the option to skip packages the project doesn’t need at runtime.
With all the developer niceties in place, it’s now time to start writing code. Open the Hapi server.js file and put in place the main server:
const config = require('./config')
const routes = require('./routes')
const db = require('./model')
const Hapi = require('@hapi/hapi')
const server = Hapi.server({
port: config.APP_PORT,
host: config.APP_HOST,
routes: {
cors: true
}
})
server.route(routes)
exports.init = async () => {
await server.initialize()
await db.connect()
return server
}
exports.start = async () => {
await server.start()
await db.connect()
console.log(`Server running at: ${server.info.uri}`)
return server
}
process.on('unhandledRejection', (err) => {
console.error(err)
process.exit(1)
})
I’ve enabled CORS by setting cors to true so this REST API can work with Hoppscotch.
To keep it simple, I’ll forgo semicolons in this project. It’s somewhat freeing to skip a TypeScript build in this project and typing that extra character. This follows the Hapi mantra, because it’s all about the developer happiness anyway.
Under config/index.js, be sure to export the dev.json info:
module.exports = require('./dev')
To flesh out configuring the server, put this in dev.json:
{
"APP_PORT": 3000,
"APP_HOST": "127.0.0.1"
}
REST Validation
To keep the REST endpoints following the HTTP standards, I’ll add Joi validations. These validations help to decouple the API from the client, because they enforce resource integrity. For the Jamstack, this means the client no longer cares about implementation details behind each resource. It’s free to treat each endpoint independently, because the validation will ensure a valid request to the resource. Adhering to a strict HTTP standard makes the client evolve based on a target resource that sits behind an HTTP boundary, which enforces the decoupling. Really, the goal is to use versioning and validations to keep a clean boundary in the Jamstack.
With REST, the main goal is to maintain idempotency with the GET, PUT, and DELETE methods. These are safe request methods because subsequent requests to same resource don’t have any side effects. The same intended effect gets repeated even if the client fails to establish a connection.
I’ll choose to skip POST and PATCH, since these aren’t safe methods. This is for the sake of brevity and idempotency, but not because these methods tight couple the client in any way. The same strict HTTP standards can apply to these methods, except that they don’t guarantee idempotency.
In routes/authors.js, add the following Joi validations:
const Joi = require('joi')
const authorV1Params = Joi.object({
id: Joi.string().required()
})
const authorV1Schema = Joi.object({
name: Joi.string().required(),
email: Joi.string().email().required(),
topics: Joi.array().items(Joi.string()), // optional
createdAt: Joi.date().required()
})
Note that any changes to the versioned model will likely need a new version, like a v2. This guarantees backwards compatibility for existing clients and allows the API to evolve independently. Required fields will fail the request with a 400 (Bad Request) response when there are fields missing.
With the params and schema validations in place, add the actual routes to this resource:
// routes/authors.js
const v1Endpoint = require('../controllers/AuthorV1Controller')
module.exports = [{
method: 'GET',
path: '/v1/authors/{id}',
handler: v1Endpoint.details,
options: {
validate: {
params: authorV1Params
},
response: {
schema: authorV1Schema
}
}
}, {
method: 'PUT',
path: '/v1/authors/{id}',
handler: v1Endpoint.upsert,
options: {
validate: {
params: authorV1Params,
payload: authorV1Schema
},
response: {
schema: authorV1Schema
}
}
}, {
method: 'DELETE',
path: '/v1/authors/{id}',
handler: v1Endpoint.delete,
options: {
validate: {
params: authorV1Params
}
}
}]
To make these routes available to the server.js, add this in routes/index.js:
module.exports = [
...require('./authors')
]
The Joi validations go in the options field of the routes array. Each request path takes in a string ID param that matches the ObjectId in MongoDB. This id is part of the versioned route because it’s the target resource the client needs to work with. For a PUT, there’s a payload validation that matches the response from the GET. This is to adhere to REST standards where the PUT response must match a subsequent GET.
This is what it says in the standard:
A successful PUT of a given representation would suggest that a subsequent GET on that same target resource will result in an equivalent representation being sent in a 200 (OK) response.
This makes it inappropriate for a PUT to support partial updates since a subsequent GET would not match the PUT. For the Jamstack, it’s important to adhere to HTTP standards to ensure predictability for clients and decoupling.
The AuthorV1Controller handles the request via a method handler in v1Endpoint. It’s a good idea to have one controller for each version, because this is what sends the response back to the client. This makes it easier to evolve the API via a new versioned controller without breaking existing clients.
The Author’s Database Collection
The Mongoose object modeling for Node first needs a MongoDB database installed. I recommend setting one up on your local dev box to play with MongoDB. A minimum installation only needs two executables, and you can get the server up and running in about 50 MB. This is the real power of MongoDB, because a full database can run in dirt cheap hardware like a Raspberry PI, and this scales horizontally to as many boxes as needed. The database also supports a hybrid model where the servers can run both on the cloud and on-prem. So, no excuses!
Inside the model folder, open up index.js to set up the database connection:
const config = require('../config')
const mongoose = require('mongoose')
module.exports = {
connect: async function() {
await mongoose.connect(
config.DB_HOST + '/' + config.DB_NAME,
config.DB_OPTS)
},
connection: mongoose.connection,
Author: require('./Author')
}
Note the Author collection gets defined in Author.js in this same folder:
const mongoose = require('mongoose')
const authorSchema = new mongoose.Schema({
name: String,
email: String,
topics: [String],
createdAt: Date
})
if (!authorSchema.options.toObject) authorSchema.options.toObject = {}
authorSchema.options.toObject.transform = function(doc, ret) {
delete ret._id
delete ret.__v
if (ret.topics && ret.topics.length === 0) delete ret.topics
return ret
}
module.exports = mongoose.model('Author', authorSchema)
Keep in mind the Mongoose schema doesn’t reflect the same requirements as the Joi validations. This adds flexibility to the data, to support multiple versions, in case somebody needs backwards compatibility across multiple endpoints.
The toObject transform sanitizes the JSON output, so the Joi validator doesn’t throw an exception. If there are any extra fields, like _id, which are in the Mongoose document, the server sends a 500 (Internal Server Error) response. The optional field topics gets nuked when it’s an empty array, because the GET must match a PUT response.
Lastly, set the database configuration in config/dev.json:
{
"APP_PORT": 3000,
"APP_HOST": "127.0.0.1",
"DB_HOST": "mongodb://127.0.0.1:27017",
"DB_NAME": "hapiAuthor",
"DB_OPTS": {
"useNewUrlParser": true,
"useUnifiedTopology": true,
"poolSize": 1
}
}
Behavior-driven Development
Before fleshing out the endpoints for each method in the controller, I like to begin by writing unit tests. This helps me conceptualize the problem at hand to get optimum code. I’ll do red/green but skip the refactor and leave this as an exercise to you so as not to belabor the point.
I’ll pick Hapi’s lab utility and their BDD assertion library to test the code as I write it:
npm i @hapi/lab @hapi/code --save-dev
In test/Author.js add this basic scaffold to the test code. I’ll pick the behavior-driven development (BDD) style to make this more fluent:
const Lab = require('@hapi/lab')
const { expect } = require('@hapi/code')
const { after, before, describe, it } = exports.lab = Lab.script()
const { init } = require('../server')
const { connection } = require('../model')
const id = '5ff8ea833609e90fc87fee52'
const payload = {
name: 'C R',
email: 'xyz@abc.net',
createdAt: '2021-01-08T06:00:00.000Z'
}
describe('/v1/authors', () => {
let server
before(async () => {
server = await init()
})
after(async () => {
await server.stop()
await connection.close()
})
})
As you build more models and endpoints, I recommend repeating this same scaffold code per test file. Unit tests are not DRY (“don’t repeat yourself”), and it’s perfectly fine to start/stop the server and database connection. The MongoDB connection and the Hapi server can handle this while keeping tests snappy.
Tests are almost ready to run except for a minor wrinkle in AuthorV1Controller1, because it’s empty. Crack open controllers/AuthorV1Controller.js and add this:
exports.details = () => {}
exports.upsert = () => {}
exports.delete = () => {}
The tests run via npm t in the terminal. Be sure to set this in package.json:
"scripts": {
"test": "lab"
},
Go ahead and fire up unit tests. There should be nothing failing yet. To fail unit tests, add this inside describe():
it('PUT responds with 201', async () => {
const { statusCode } = await server.inject({
method: 'PUT',
url: `/v1/authors/${id}`,
payload: {...payload}
})
expect(statusCode).to.equal(201)
})
it('PUT responds with 200', async () => {
const { statusCode } = await server.inject({
method: 'PUT',
url: `/v1/authors/${id}`,
payload: {
...payload,
topics: ['JavaScript', 'MongoDB']}
})
expect(statusCode).to.equal(200)
})
it('GET responds with 200', async () => {
const { statusCode } = await server.inject({
method: 'GET',
url: `/v1/authors/${id}`
})
expect(statusCode).to.equal(200)
})
it('DELETE responds with 204', async () => {
const { statusCode } = await server.inject({
method: 'DELETE',
url: `/v1/authors/${id}`
})
expect(statusCode).to.equal(204)
})
To start passing unit tests, put this inside controllers/AuthorV1Controller.js:
const db = require('../model')
exports.details = async (request, h) => {
const author = await db.Author.findById(request.params.id).exec()
request.log(['implementation'], `GET 200 /v1/authors ${author}`)
return h.response(author.toObject())
}
exports.upsert = async (request, h) => {
const author = await db.Author.findById(request.params.id).exec()
if (!author) {
const newAuthor = new db.Author(request.payload)
newAuthor._id = request.params.id
await newAuthor.save()
request.log(['implementation'], `PUT 201 /v1/authors ${newAuthor}`)
return h
.response(newAuthor.toObject())
.created(`/v1/authors/${request.params.id}`)
}
author.name = request.payload.name
author.email = request.payload.email
author.topics = request.payload.topics
request.log(['implementation'], `PUT 200 /v1/authors ${author}`)
await author.save()
return h.response(author.toObject())
}
exports.delete = async (request, h) => {
await db.Author.findByIdAndDelete(request.params.id)
request.log(
['implementation'],
`DELETE 204 /v1/authors ${request.params.id}`)
return h.response().code(204)
}
A couple of things to note here. The exec() method is what materializes the query and returns a Mongoose document. Because this document has extra fields the Hapi server doesn’t care for, apply a toObject before calling response(). The API’s default status code is 200, but this can be altered via code() or created().
With red/green/refactor test-driven development, I only wrote the minimum amount of code to get passing tests. I’ll leave writing more unit tests and more use cases to you. For example, the GET and DELETE should return a 404 (Not Found) when there’s no author for the target resource.
Hapi supports other niceties, like a logger that’s inside the request object. As a default, the implementation tag sends debug logs to the console when the server is running, and this also works with unit tests. This is a nice clean way to see what’s happening to the request as it makes its way through the request pipeline.
Testing
Finally, before we can fire up the main server, put this in index.js:
const { start } = require('./server')
start()
An npm start should get you a running and working REST API in Hapi. I’ll now use Hoppscotch to fire requests to all endpoints. All you have to do is click on the links below to test your API. Be sure to click on the links from top to bottom:
Or, the same can be done in cURL:
curl -i -X PUT -H "Content-Type:application/json" -d "{\"name\":\"C R\",\"email\":\"xyz@abc.net\",\"createdAt\":\"2021-01-08T06:00:00.000Z\"}" http://localhost:3000/v1/authors/5ff8ea833609e90fc87fee52
201 Created {"name":"C R","email":"xyz@abc.net","createdAt":"2021-01-08T06:00:00.000Z"}
curl -i -X PUT -H "Content-Type:application/json" -d "{\"name\":\"C R\",\"email\":\"xyz@abc.net\",\"createdAt\":\"2021-01-08T06:00:00.000Z\",\"topics\":[\"JavaScript\",\"MongoDB\"]}" http://localhost:3000/v1/authors/5ff8ea833609e90fc87fee52
200 OK {"topics":["JavaScript","MongoDB"],"name":"C R","email":"xyz@abc.net","createdAt":"2021-01-08T06:00:00.000Z"}
curl -i -H "Content-Type:application/json" http://localhost:3000/v1/authors/5ff8ea833609e90fc87fee52
200 OK {"topics":["JavaScript","MongoDB"],"name":"C R","email":"xyz@abc.net","createdAt":"2021-01-08T06:00:00.000Z"}
curl -i -X DELETE -H "Content-Type:application/json" http://localhost:3000/v1/authors/5ff8ea833609e90fc87fee52
204 No Content
In Jamstack, a JavaScript client can make these calls via a fetch(). The nice thing about a REST API is that it doesn’t have to be a browser at all, because any client that supports HTTP will do. This is perfect for a distributed system where multiple clients can call the API via HTTP. The API can remain stand-alone with its own deployment schedule and be allowed to evolve freely.
Conclusion
The JamStack has a nice way of decoupling software modules via versioned endpoints and model validation. The Hapi server has support for this and other niceties, like type declarations, to make your job more enjoyable.
Frequently Asked Questions (FAQs) about JAMstack, REST API, and Hapi
What is the main advantage of using JAMstack with Hapi?
The main advantage of using JAMstack with Hapi is the ability to create fast, secure, and scalable applications. JAMstack stands for JavaScript, APIs, and Markup. It is a modern web development architecture based on client-side JavaScript, reusable APIs, and prebuilt Markup. When combined with Hapi, a rich framework for building applications and services, developers can create robust, efficient, and highly scalable applications. Hapi provides a detailed API reference and powerful plugin system, making it easier to build and maintain complex business logic.
How can I use TypeScript with Hapi?
TypeScript can be used with Hapi to provide static typing and other advanced JavaScript features. To use TypeScript with Hapi, you need to install the TypeScript definitions for Hapi. You can do this by running the command npm install @types/hapi__hapi. After installing, you can import Hapi in your TypeScript file using import * as Hapi from '@hapi/hapi';. TypeScript provides static typing, which can help catch errors early during the development process, and it also provides autocompletion and documentation in code editors, which can improve developer productivity.
What resources are available for learning Hapi?
There are several resources available for learning Hapi. The official Hapi website provides a detailed API reference, tutorials, and a plugin directory. There are also several online tutorials and blog posts available that provide step-by-step guides on how to use Hapi. Additionally, there are several books and online courses available that provide a more in-depth look at Hapi and its features.
How can I use Hapi with REST APIs?
Hapi can be used to build REST APIs by defining routes and handlers for different HTTP methods. A route in Hapi is an endpoint (a specific URL) that your application will respond to. A handler is a function that gets executed when a specific route is hit. You can define a route in Hapi using the server.route() method, and you can specify the HTTP method, the URL, and the handler for the route.
What are some best practices for using Hapi with TypeScript?
When using Hapi with TypeScript, it’s important to follow some best practices to ensure your code is clean, efficient, and easy to maintain. First, always use TypeScript’s static typing features to catch errors early. Second, organize your code into modules to make it easier to manage. Third, use Hapi’s plugin system to encapsulate and isolate your application’s business logic. Finally, always write tests for your code to ensure it works as expected.
How can I handle errors in Hapi?
Hapi provides several ways to handle errors. You can use the Boom module to create HTTP-friendly error objects. You can also use the request.log() method to log errors, or the request.generateResponse() method to generate custom error responses.
How can I test my Hapi application?
Hapi provides several tools for testing your application. You can use the server.inject() method to simulate HTTP requests and responses. You can also use the Lab module, which is a test utility for Hapi, to write and run tests.
How can I secure my Hapi application?
Hapi provides several features to help secure your application. You can use the hapi-auth-basic plugin to implement basic authentication, or the hapi-auth-jwt2 plugin to implement JWT authentication. You can also use the hapi/nes plugin to secure WebSocket connections.
How can I optimize the performance of my Hapi application?
There are several ways to optimize the performance of your Hapi application. You can use the hapi-swagger plugin to document your API and reduce development time. You can also use the hapi-pal toolkit to structure your application in a way that promotes code reuse and reduces duplication.
How can I deploy my Hapi application?
There are several ways to deploy your Hapi application. You can use traditional hosting services, or you can use modern cloud platforms like AWS, Google Cloud, or Heroku. You can also use containerization technologies like Docker to package your application and its dependencies into a single, runnable unit.