8 Simple Steps to Complete a Technical SEO Audit


A technical SEO audit helps teams understand behind-the-scenes issues that affect search engine rankings like site speed, indexing, and backlinks. It’s important that SEO specialists have a full view of all of the elements that affect page rankings so that teams can take the best course of action to improve their positions.
Conducting daily technical SEO audits is crucial for building a great SEO strategy. But if you’re still starting out, beginning work with a new firm, or want to learn how to complete a technical SEO audit, it can be overwhelming.
In this article, we’ll go over eight steps to help you complete a technical SEO audit, increase web traffic to your web pages, and build your confidence as an SEO specialist.
Key Takeaways
What Is a Technical SEO Audit?
What most people think of as SEO is what specialists refer to as on-page SEO. This is where a professional optimizes the content that appears on a website so that it appears to the right audiences organically.
Technical SEO is not about the content that appears on a website but how users and search bots navigate through each page. A technical SEO audit is when specialists use a checklist of behind-the-scenes technical elements to review and improve to increase page rankings in search engines.
What’s involved in a technical SEO audit
When SEO specialists perform a technical SEO audit, they check a series of factors that impact a website’s speed, performance, and usability, and they take action towards optimizing web pages. Regular, sometimes daily technical SEO audits can help specialists learn about technical issues they might not know about.
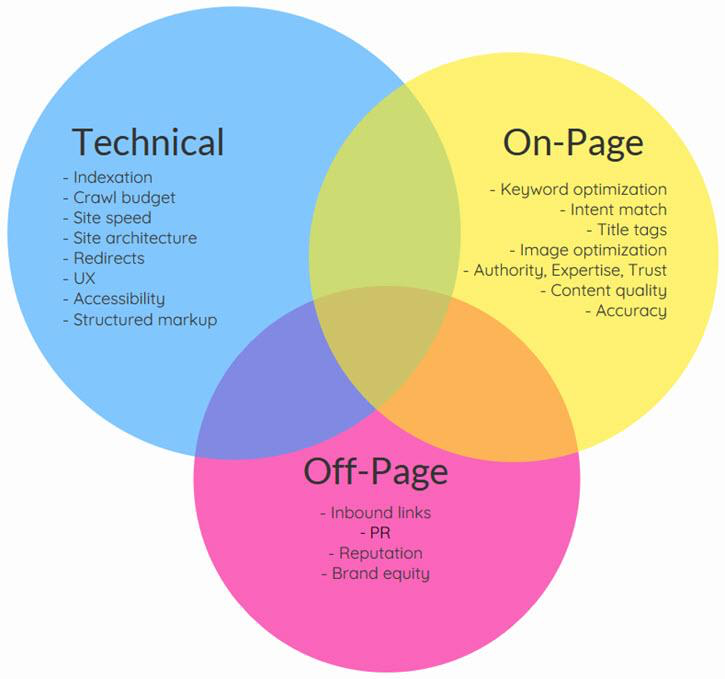
Image source: WordStream
SEO specialists and marketing teams use tools such as Google Search Console, Google PageSpeed Insights, web crawlers, mobile crawlers, and indexing tools, to optimize their web pages and improve search engine rankings through technical SEO audits.
When you should complete a technical SEO audit
It’s important to complete technical SEO audits regularly. Some businesses use technical SEO to help improve cash flow via web traffic and conversions, so daily audits are a must. But for blogs and personal websites, weekly or monthly SEO audits should suffice.
Besides regular maintenance, you should always complete a technical SEO audit when moving to a new site, start freelancing for a new client, or when you first get hired at a firm. And of course, technical SEO audits also come in handy during periods where your rankings are stagnant or in decline.
What you need to do before conducting a technical SEO audit
Before you conduct a technical SEO audit, there are a few things you need to do:
- Find out what your client’s goals are. Do they want to improve SEO, make web pages easier for users to navigate, or optimize their site’s performance?
- Get access to their tools and analytics. To perform a technical SEO audit, you’ll need to be able to access things like the site’s Google console, performance monitoring analytics, and anything else you need to meet your client’s expectations.
- Sign a written agreement. Whether you’re contracted for one job or ongoing work, it’s important to have a written agreement explaining what you’re going to do and how you’ll do it. You’ll also need liability disclaimers and a list of responsibilities so that you aren’t held accountable for things outside your control.
Having all of this information beforehand is important so you can prepare for the work. For example, if you were working for a SaaS company, you might be hired to perform a technical SEO audit on certain specialized landing pages based on their industry and business type so that they appear in front of the right people according to their previous searches and user behavior.
Image source: Search Engine Land
But if you were working for a retail company, your job might be to ensure that pages load fast, that there are no image issues, and that all of your 4xx links redirect to the correct locations.
A Step-by-step Guide to Completing a Technical SEO Audit
Let’s go through each of the eight steps that will help you complete a technical SEO audit successfully.
1. Crawl your website
Use a tool that scans your website to check how many URLs there are, how many are indexable, and how many have issues, including any problems hindering your site’s performance.
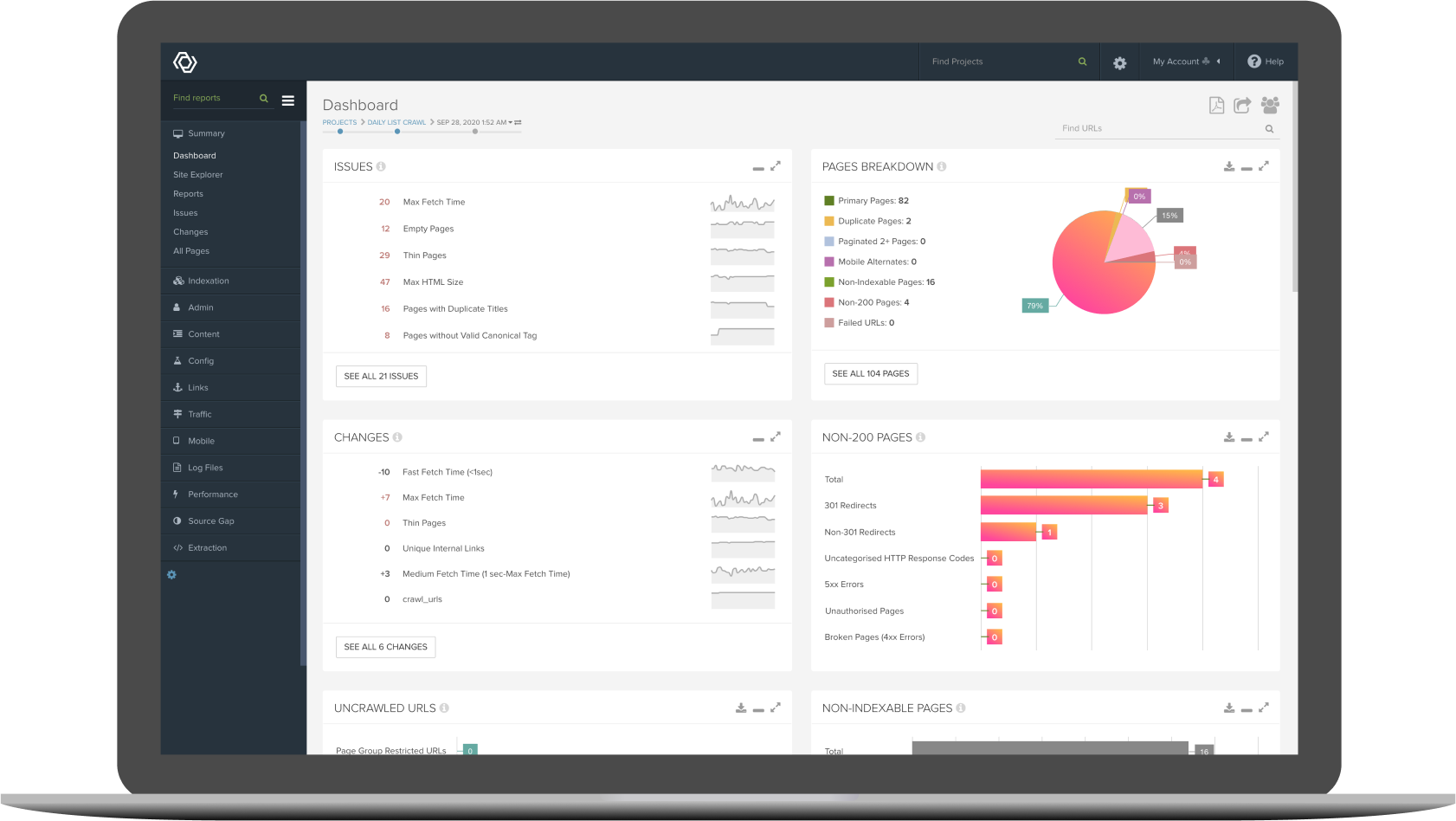
Image source: Deepcrawl
For Wix users, Deepcrawl is the top tool that professionals trust, but most people start out using Google Search Console:
- Decide which sitemap format you want to use: XML, RSS, mRSS, Atom 1.0, or Text.
- Create the sitemap either manually or automatically with a sitemap generator.
- Add your sitemap to your robots.txt file, or submit it to Google through the Search Console.
2. Spot indexing issues
If the website has pages that Google can’t crawl, it may not be indexed properly. Here are some common indexing issues to look for:
- indexation errors
- robots.txt errors
- sitemap issues
The easiest way to check your site indexation is to use the Coverage Report in Google Search Console. It will tell you which pages are indexed and why others are excluded so you can fix them. You may need to optimize your crawl budget to ensure that your pages are indexed regularly.
3. Check technical on-page elements
Although on-page elements are often left out of a technical SEO audit, attending to them is considered basic housekeeping that needs to be addressed. Here’s a list of on-page elements to review during a technical SEO audit:
- page titles and title tags
- meta descriptions
- canonical tags
hreflangtags- schema markup
4. Identify image problems
Image optimization is another often-overlooked aspect that’s crucial to technical SEO audits. Ensuring images have no errors can help a site’s ranking in many ways, including improved loading speeds, increasing traffic from Google Images, and improved accessibility.
Be sure to identify technical image problems such as:
- broken images
- image file size too large
- HTTPS page links to HTTP image
- missing
alttext
5. Analyze internal links
Next, it’s important to analyze internal links. Identify 4xx status codes that need to be redirected. If there are any orphan pages with no internal links leading to them, identify and address them.
6. Check external links
Next, move on to the external links. External links are important because they make a website more credible to users and search engines. Ensure all backlinks are active and don’t lead to broken pages, and check to see that all pages have outgoing links.
7. Measure site speed and performance
Google Search gives better ranking positions to websites with good performance and fast loading times.
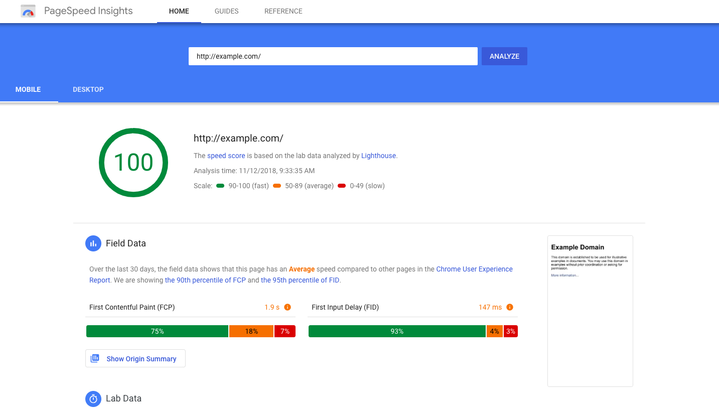
Image source: PageSpeed
Here’s how to use Google PageSpeed Insights to check on a site’s performance:
- Go to the Google PageSpeed Insights page.
- Input your web page URL into the box.
- Click analyze and view your results.
This tool will provide you with an overall score, field data, suggestions, and other diagnostic information that can help improve your page speed.
8. Ensure your site is mobile-friendly
Finally, ensure that the site you’re auditing is mobile-friendly, responsive, and compatible with different browsers. Google favors responsive web pages that load easily and are easy to view regardless of the user’s device.
Here’s an example of how CryptoWallet.com uses mobile and web-friendly design:
Web view

Mobile scrolling view
It’s easy to check the responsiveness of a website with a tool like Responsive Web Design Checker or with these steps in Google Chrome:
- Open the web page in Google Chrome.
- Right-click to open the menu and select Inspect.
- Click on the Toggle device toolbar to see how the website looks on screen and mobile.
Wrapping Up
Technical SEO audits help optimize websites so that they’re easier for users and for indexing bots to understand. Conducting a technical SEO audit involves a lot of elements, but this eight-step process can help streamline your workflow so that you don’t miss a thing.
FAQs about Technical SEO Audits
A technical SEO audit is a comprehensive evaluation of a website’s technical aspects to identify and address issues that may impact search engine visibility. It aims to improve website performance, crawlability, and indexability.
A technical SEO audit helps uncover and resolve issues that may hinder a website’s performance in search engines. It ensures that the site is structured in a way that search engines can easily crawl, index, and understand its content.
Components include crawl analysis, indexing issues, site structure, URL structure, mobile optimization, page speed, duplicate content, canonicalization, sitemaps, robots.txt, and more.
You can perform a technical SEO audit manually by reviewing each aspect of your site or use tools like Google Search Console, Screaming Frog, and other SEO audit tools to automate the process.
Common issues include broken links, duplicate content, missing meta tags, slow page speed, improper redirects, mobile-friendliness problems, and issues with site architecture.
Yes, addressing technical issues identified in an audit can positively impact search engine rankings. Improving site performance, fixing crawl errors, and optimizing technical aspects contribute to a better user experience and search engine visibility.
Magnus Eriksen is a copywriter and an eCommerce SEO specialist with a degree in Marketing and Brand Management. Before embarking on his copywriting career, he was a content writer for digital marketing agencies such as Synlighet AS and Omega Media, where he mastered on-page and technical SEO.




