

There’s a number of steps between applications and websites being conceived and being finally released — design, programming, QA, and deployment. Let’s close the gap between the development and operations cycle, and review some of the practices of the DevOps movement.
Key Takeaways
- DevOps is a culture, not a specific tool or technique, that fosters collaboration between development and operations teams. This approach can accelerate time-to-market, reduce costs, improve productivity, and enhance customer satisfaction.
- Technology such as Docker and Jenkins can support a DevOps culture by automating the creation of environments and continuous integration and delivery. This automation allows for more frequent and reliable releases, and gives developers, QA, and sysadmins the ability to work together effectively.
- Transitioning to a DevOps culture comes with challenges at the organizational, process, and technology levels. These include the need for a shift in mindset, the automation of testing processes, and the adoption or creation of technology that supports automation and feedback loops.
- Despite the challenges, implementing a DevOps culture can bring significant benefits. However, it’s crucial to remember that the success of DevOps depends on a strong culture of collaboration and trust, rather than the use of specific tools or technologies.
Conventional Software Development: Dev vs Ops
Traditionally, there are distinct teams and processes for the different states of a project, from the initial states of analysis and design (when a product or idea is conceived), to the actual development and testing (e.g. when code is being written or a product is being developed), to finally deployment and maintenance (e.g. when a website, application, or product goes live).
There’s good reason for this differentiation: they all demand a different set of skills. However, a strict (and at times even bureaucratic) separation of duties can add a lot of unnecessary delays, and experience proves that blurring some of these lines can be advantageous for all of the parties involved, and for the process as a whole.
This is true not only for software development, but for many industries. Think of Toyota, for example, the Japanese car manufacturer that’s had, for many years, a strong culture of reducing what they call “waste” from the production chain so that they could fasten the flow of changes from development into operations. Furthermore, Toyota’s practices have, in fact, heavily influenced the IT industry both in software development (see “lean software development“) and in DevOps (see “Kanban: from Toyota to DevOps?” and “Using the Toyota Production System to explain DevOps“).
DevOps: A Cultural Change for the Win
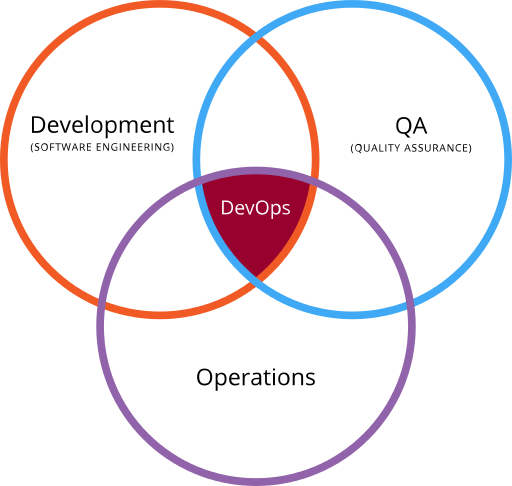
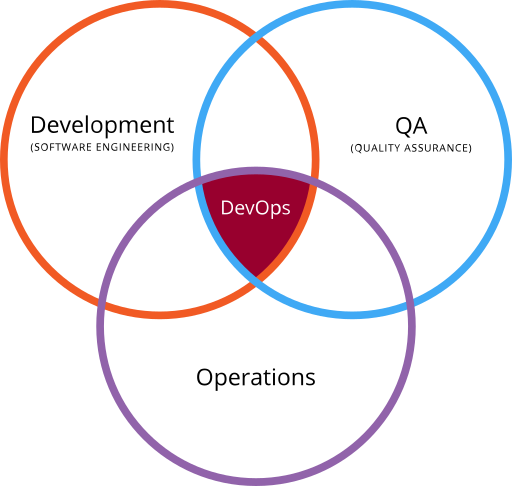
DevOps as the intersection of development, operations and quality assurance. Image from Wikimedia, via Gary Stevens of HostingCanada.org.
{kind=link}
Much like with agile development, DevOps isn’t a particular tool or technique that you can implement and you’re done. Rather, it’s a culture — even a mindset — that your team and organization can adopt and that will make processes smoother.
But what is it exactly? Think of developers being able to do some of the tasks that are normally assigned to system administrators, such as creating new servers, making updates to production sites, deploying apps. Also think of sysadmins sharing some duties with developers, and being able to manage multiple servers at once.
Benefits
Companies embracing a DevOps culture report significant improvements, and different surveys conducted among some of them seem to confirm these claims (see “Continuous Delivery: Huge Benefits, but Challenges Too“).
Some of the these improvements include:
- Accelerated time-to-market: shorten the time it takes from when an idea is conceived until it’s available for sale or in production.
- Building the right product: developers get faster feedback from users with more frequent releases and live testing of ideas (more on this later on the “A/B Testing” section).
- Cost reduction: reports average a 20% reduction.
- Improved productivity: with continuous delivery, developers and testers save time setting up and fixing their working environments. Also, deployments are significantly faster (more on this later in the “Continuous Integration with Jenkins” section).
- Reliable releases: with smaller and more frequent releases, the changes in code — and therefore the bugs introduced and their impact — are also smaller.
- Improved product quality: companies report a very significant reduction in open bugs and other issues (in some cases, by more than 90%).
- Improved customer satisfaction: this is, not surprisingly, a byproduct of all of the previous improvements.
Examples
Same Production and Development Environments with Docker
![]()
The conventional wisdom goes that one shouldn’t mix production with development environments — that these two should be carefully separated in order to avoid disasters. And while it’s true that making changes to a live platform without testing and rollback mechanisms is, in fact, a formula for disaster, having multiple environments comes at a high operational cost.
Automating the creation of environments is key in DevOps, and one technology that enables this is Docker. We won’t get into the full details here, but the principle is that, with Docker, you can create a well-tested and functional environment (called an image) that developers and engineers in the operations side will be able to launch as software containers. Whenever an update or patch is required, the QA team will just patch the image, and the changes will be replicated in every new container that’s launched.
This gives independence to programmers and designers to launch environments that are constantly updated and known to work (and as many of them as they need), and even deploy changes to live platforms, because the QA people are maintaining these environments and have already set the appropriate tests. It also provides a communication channel with the server administrators, because they’re all basically working together in having a working environment that’s good for both production and development.
Notice that this is also valid if development and deployment are carried out by the same people — as in a single freelance developer — because these concerns for testing and implementing a live application in different environments are still valid regardless of who’s in charge of doing it.
For more info about what you can do with Docker, see Understanding Docker, Containers and Safer Software Delivery.
A/B Testing
Wikipedia describes A/B testing as follows:
In marketing and business intelligence, A/B testing is a term for a randomized experiment with two variants, A and B, which are the control and variation in the controlled experiment.
The principle is that you can test variants of an idea on live environments to make improvements in usability and other areas, based on popularity or users feedback. The reckless part is that you perform these tests with your actual audience — who are the ones best qualified for feedback anyway — which is something that Facebook, for example, does on a big scale to conduct social experiments. In the web dev field, think of experiments for testing landing pages with Google Analytics.
How is all of this related to DevOps? Well, with automated deployment processes you give the parties involved — be they designers, developers, or even scientists with no background whatsoever in programming or engineering — the autonomy they need to conduct the experiments — again, with the safeguard mechanisms in place to test, pull or rollback changes.
Continuous Integration with Jenkins
Jenkins logo (wikimedia)
{kind=link}
Jenkins is a continuous integration (CI) and continuous delivery (CD) software — an orchestration system with hundreds of plugins to automate everything from building an application and testing it, to the final deployment. These plugins can integrate building software from source code platforms such as Git or Mercurial, to cloud services such as Amazon Web Services (AWS) or the Google Cloud Platform (GCP), passing through all of the scheduled tests. It is, essentially, a pipeline from source to delivery that’s becoming the engine of DevOps.
Again, we see how everyone involved (developers, QA and sysadmins) work together on an effective and automated workflow:
- Do developers need a new working environment? Jenkins will fire up Docker to launch it.
- Do sysadmins require a new QA test to pass before an update can go live? They just add it to the Jenkins pipeline.
- Do developers want to pull changes to a production site and launch new servers with it? No problem: sysadmins have already instructed Jenkins what tests to run, and if everything goes fine, how to launch the servers.
As you can see, there’s a lot of automation in the process, and a fair amount of trust between the parties — all of which requires a lot of work to set up, but which, once in place, also gives everyone a lot of room to operate on their own.
Challenges and Fails
Switching to a DevOps culture may bring a number of benefits, but it also comes with certain challenges to overcome.
The first one is at an organization level. As development and deployment constraints are removed and programmers and sysadmins have more independence, the people involved will need to adopt a different mindset, and the appropriate mechanisms for a feedback loop from ops to dev will need to be set in place — such as issue trackers, boards of discussions (think of Slack), and the like.
The second key challenge is regarding processes. You no longer want developers and server administrators themselves using their time to individually test after changes. What you’ll want is to automate the testing processes, so that you can allow different teams to make changes and quickly check that things are still in place, and reverse those changes should problems arise.
Finally, there’s a technology challenge. As mentioned, once your organization has carefully reviewed the processes from end to end, you may need either to adopt or create a technology that addresses the kind of automation and feedback loop that better suits your processes and organization.
It isn’t trivial: you can’t simply copy/paste the processes and technologies others are using. These issues need to be addressed individually, and there has to be a fair level of trust between the parties involved.
As Dave Roberts comments in “Why ‘Enterprise DevOps’ Doesn’t Make Sense”:
The key is to understand that simply deploying a tool or even a broad solution without thinking through your unique situation and the current state of your value stream and its current constraints is foolish.
Recap
It’s not about the Apps. You can use tools such as Docker, Jenkins, Kanban and yet never be doing any actual DevOps if you can’t rely on the people at the other side of your chain.
In contrast, you can go without these tools and instead implement your own solutions and set a chain of QA that suits you or your organization. And if you’re having a fluent communication with the colleagues from different teams, and even temporarily do some of their tasks yourself when you need to — trusting that they can to do same because you already have in place everything necessary to reverse changes — then you’re making a cultural shift that very much sounds like DevOps.
The benefits ahead may very well be worth the effort.
Frequently Asked Questions (FAQs) about DevOps
What are the key benefits of implementing a DevOps culture in an organization?
Implementing a DevOps culture in an organization can bring about numerous benefits. Firstly, it promotes a collaborative environment where developers and operations teams work together, leading to faster and more efficient software development. Secondly, it encourages continuous integration and delivery, which means that software updates can be released more frequently and with fewer errors. Thirdly, it can lead to improved problem-solving and decision-making as teams share knowledge and learn from each other. Lastly, it can increase customer satisfaction as products are delivered faster and with higher quality.
How does automation play a role in DevOps?
Automation is a key component of DevOps. It allows for the continuous integration and delivery of software, which means that updates can be released more frequently and with fewer errors. Automation can also reduce the amount of manual work involved in software development, freeing up developers to focus on more complex tasks. This can lead to increased productivity and efficiency.
What are some examples of DevOps tools?
There are many tools available that can support a DevOps culture. These include source code management tools like Git, continuous integration tools like Jenkins, configuration management tools like Puppet, and monitoring tools like Nagios. These tools can help to automate various aspects of the software development process, making it more efficient and reliable.
What are the potential challenges of implementing a DevOps culture?
While implementing a DevOps culture can bring many benefits, it can also present some challenges. These can include resistance to change, difficulties in breaking down silos between teams, and the need for new skills and knowledge. However, with careful planning and management, these challenges can be overcome.
How can an organization transition to a DevOps culture?
Transitioning to a DevOps culture requires a shift in mindset and practices. This can involve promoting collaboration between developers and operations teams, implementing continuous integration and delivery, and adopting automation tools. It may also require training and education to ensure that all team members have the necessary skills and knowledge.
What is the role of a DevOps engineer?
A DevOps engineer is responsible for overseeing the continuous integration and delivery of software. This can involve managing the automation of the software development process, troubleshooting any issues that arise, and working closely with developers and operations teams to ensure that software is delivered efficiently and effectively.
How does DevOps relate to Agile methodologies?
DevOps and Agile methodologies share a common goal of delivering software more efficiently and effectively. Both approaches promote collaboration, continuous improvement, and customer satisfaction. However, while Agile focuses on the development process, DevOps extends this focus to include operations as well.
What is the relationship between DevOps and cloud computing?
DevOps and cloud computing are closely related. Cloud computing provides the infrastructure and services that support the continuous integration and delivery of software, while DevOps provides the practices and tools that make this process more efficient and reliable.
How does DevOps contribute to business value?
By promoting collaboration, continuous improvement, and customer satisfaction, DevOps can contribute to increased business value. This can result in faster time to market, higher quality products, and improved customer satisfaction.
What is the future of DevOps?
The future of DevOps is likely to involve further integration with other approaches such as Agile and Lean, as well as increased use of automation and cloud computing. As organizations continue to recognize the benefits of a DevOps culture, it is likely to become an increasingly important part of software development.