
Key Takeaways
- Aggregates in Domain-Driven Design (DDD) are clusters of associated objects treated as a single unit for data changes, with one of the objects chosen as the root. External references are restricted to the root, and all other members of the Aggregate are accessed through it. This makes enforcing invariants easier and reduces the number of bidirectional associations among objects.
- Establishing Aggregate boundaries and choosing roots relies on a few rules of thumb. Entities forming a parent-child relationship should form an Aggregate, with the parent class becoming the root. Entities that are semantically close to each other are also good candidates. If two Entities need to be modified inside a transaction, they should be part of the same Aggregate.
- Aggregates are not only about access restriction but also define the boundaries of invariants and transactions. While it’s common to make the root responsible for managing all transactions, there can be situations where it doesn’t make sense. Instead, a service can be used to ensure important invariants and wrap everything into a transaction.
My Previous Articles About DDD for Rails Developers
In Part 1, I talked about using the layered architecture for tackling domain complexity. I showed a few typical violations of the layered architecture and gave some advice on how to fix them.
In Part 2, I started talking about the building blocks of Domain Driven Design. I wrote about an important distinction between Entities and Value Objects. I also gave some advice on how to implement Value Objects in Rails.
Aggregates
This time I’d like to go into another building block of Domain Driven Design. I’d like to talk about Aggregates.
We’ve all experienced this situation before:
You start with nicely designed groups of objects. All the objects have clear responsibilities, and all interactions among them are explicit. Then, you have to consider additional requirements, such as transactions, integration with external systems, event generation. Satisfying all of them and not making all the objects interconnected is a nontrivial task. What usually happens is database hooks, conditional validations, and remote calls are added on an ad hoc basis. The result is more connections among objects. Hence, the boundaries of object groups become fuzzy and enforcing invariants becomes harder. Remember all the cases when you were thinking, “Maybe I need to reload this object?” It indicates that your objects are interconnected, and you cannot reason about your code with confidence. Instead, you just guess.
Defining Aggregates is a good remedy for the described situation.
- “An Aggregate is a cluster of associated objects that are treated as a unit for the purpose of data changes.” (see Resources)
- An Aggregate consists of a few Entities and Value Objects, one of which is chosen to be the root of the Aggregate.
- All external references are restricted to the root. Objects outside the Aggregate can hold references to the root only.
- Accessing other members of the Aggregate happens through the root. Therefore, nobody (outside the Aggregate) should hold references to those objects.
- As all external objects can hold reference only to the root, enforcing invariants becomes easier.
- Aggregates help to reduce the number of bidirectional associations among objects in the system because you are allowed to store references only to the root. That significantly simplifies the design and reduces the number of blindsided changes in the object graph.
Example
It may sound too abstract, so I’d like to show you an example. I’m going to model an online bookstore. The main responsibility of the model will be selling and shipping books. Hopefully the example will bring some clarity to the definition of Aggregates and will demonstrate how they can be implemented in Rails.
Sketch
This is a sketch illustrating all the classes that will form the model.
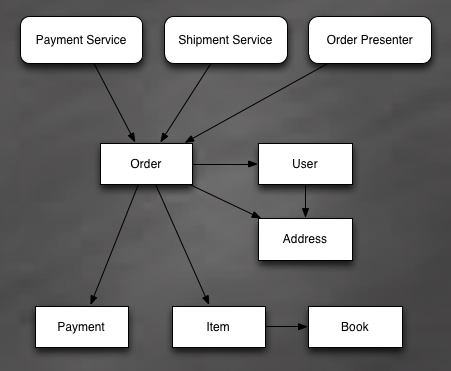
As you can see, I have:
- Entities: Order, Item, User, Book, Payment
- Value Objects: Address
- Services: ShipmentService, PaymentService
- View: OrderPresenter
Defining Aggregate Boundaries
Now, after I am done with sketching, I can establish Aggregate boundaries and choose roots.
There are a few rules of thumb to use:
- Entities forming the parent-child relationship, most likely, should form an Aggregate. In this case, the parent class becomes the root.
- Entities that are semantically close to each other are good candidates for forming an Aggregate as well. For instance, Book and Payment have no obvious connections with each other. Having them inside an Aggregate is awkward. On the other hand, Order and Item are closely related. Thus, we should consider putting them inside an Aggregate.
- If two Entities have to be modified inside a transaction, they should be parts of the same Aggregate.
Note:
These rules should just help you get started. After your first sketch you should look at all the invariants that need to be maintained and finalize your Aggregate boundaries based on them.
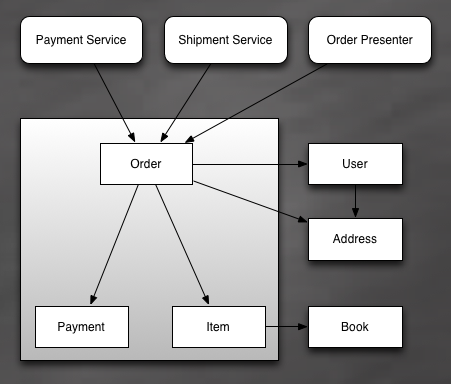
As you may have already guessed, Order and Item form an Aggregate. What other Entities should we include? Including Book does not make much sense because I can easily imagine clients using Book without Order (e.g. you may need to display the list of all available books in the store).
Including User into the same Aggregate with Order is not the best idea either. Just imagine if User becomes the root, you will have to access all the orders of a user through the user itself. Furthermore, updating two orders of the same user simultaneously will be tricky. Clearly neither Book nor User should be a part of the Aggregate.
The situation with the Payment class is different. Conceptually, Payment is an important part of Order. Also, you cannot simultaneously pay for an Order and modify it. It’s decided, Payment becomes a part of the Aggregate.
An updated sketch with the defined boundary:
Implementation
Let’s get started with the code. First, let’s define the Book and User classes:
[gist id=”2432865″]
There is nothing really interesting here. There are two Entities (Book and User) and one Value Object (Address). It gets interesting when we implement the Order and Item classes:
[gist id=”2432874″]
That is how the creation of an order may look like:
[gist id=”2432877″]
Reading the same order from the database may look like this:
[gist id=”2432879″]
There are a few important things I’d like to point out:
- All items and payments are created through an instance of Order.
- I don’t update attributes of an Order directly.
- I don’t use DataMapper methods directly. I wrote a few methods to decouple our model from DataMapper as much as possible.
- There are no bidirectional associations. Every order knows about its items, but the items don’t have any references to their orders. Why? Because they don’t need to. Order is the root; therefore, any client can get an item only through its order. This means that an item’s order will always be known. * Bidirectional associations are a bad practice established in the Rails community. If you can avoid it, please, do it. *
- A user does not know about its orders. Apart from the fact that it’s an unnecessary bidirectional association, it also makes testing much harder.
Don’t believe me? Take a look at this line of code:
[gist id=”2432887″]
It looks so simple. Some people might even say that it’s nicer than this one:
[gist id=”2432889″]
However, if you try to stub it in your test you may write something similar to this:
[gist id=”2432894″]
Now, compare it with the stubbing of Order.active_orders(user):
[gist id=”2432897″]
The second test is much easier to read and understand. In addition, in large applications such models as User tend to grow. In a few years, you may get the User class having many orders, promotions, friends, wish lists etc.
Accessing Our Model in View
Please, don’t be mistaken. The fact that Order is the root of the Aggregate does not mean I cannot access its payment or items. Of course, I can. The only rule is not to store references to those objects. For instance, I’d probably need a presenter. As presenters store references to the objects they present, creating ItemPresenter or PaymentPresenter is a violation of the Aggregate boundary. Instead, we can create OrderPresenter and pass an instance of Order to it. OrderPresenter can access the order’s items or payment through the order itself.
[gist id=”2432899″]
Invariants
Remember that Aggregates are not only about access restriction. They also define the boundaries of invariants and transactions. There is a common opinion that those invariants must be enforced by the root. It’s also common to make the root responsible for managing all transactions. Although sometimes it may make perfect sense, there are lots of situations when it does not. Just to give you an example, let’s take a look at the PaymentService class:
[gist id=”2432901″]
PaymentService has several responsibilities. First, it masks the credit card. Next, it updates the database to mark the order as paid. After that, it makes a remote call to some external service that processes credit card transactions. Also, it wraps everything into a transaction. PaymentService ensures an important invariant that updating the status of the order and making the remote call must be done together. An alternative would be to make Order responsible for calling external services. The result would be a violation of Single Responsibility Principle and a few nasty dependencies of Order on external payment systems.
Wrapping Up
Sometimes invariants need to be applied not to discrete objects, but to clusters of objects. Defining Aggregates and restricting access to Aggregate members is an arrangement that makes enforcing all the invariants possible.
Resources
* Aggregate | Domain-Driven Design Community
Frequently Asked Questions (FAQs) about Domain-Driven Design (DDD) for Rails Developers
What is the role of Aggregates in Domain-Driven Design (DDD)?
Aggregates are a crucial part of Domain-Driven Design. They are clusters of domain objects that can be treated as a single unit. An aggregate will have one of its component objects be the aggregate root. Any references from outside the aggregate should only go to the aggregate root. The root can thus ensure the integrity of the aggregate as a whole.
How do Aggregates ensure consistency in DDD?
Aggregates ensure consistency by enforcing business rules. They encapsulate business logic and data, ensuring that the system remains in a consistent state. The aggregate root is responsible for maintaining this consistency. It ensures that all operations on the aggregate are valid according to the business rules.
How do Aggregates differ from Entities in DDD?
While both aggregates and entities are important concepts in DDD, they serve different purposes. An entity is an object that has a distinct identity and continuity over time. An aggregate, on the other hand, is a cluster of associated objects that we treat as a unit for the purpose of data changes. Each aggregate has an aggregate root, which is an entity.
What is the significance of the Aggregate Root in DDD?
The aggregate root is the entity within the aggregate that holds the direct references to all the entities within the aggregate. It is responsible for maintaining the consistency and integrity of changes within the aggregate. All external requests to change the state of any entity within the aggregate must go through the aggregate root.
How does DDD handle complex business logic?
DDD handles complex business logic by breaking it down into smaller, more manageable parts. These parts are then modeled as aggregates. Each aggregate encapsulates a specific business rule or set of rules, ensuring that the system remains consistent and that the business rules are enforced.
How does DDD improve communication between developers and domain experts?
DDD improves communication by using a ubiquitous language. This is a common language that is used by both developers and domain experts. It is based on the domain model and is used in all discussions and in the code. This ensures that everyone has a common understanding of the domain and the business rules.
How does DDD help in dealing with large codebases?
DDD helps in dealing with large codebases by promoting a clean, modular design. The code is organized around the domain model, with each aggregate representing a specific business rule or set of rules. This makes the code easier to understand and maintain.
How does DDD relate to microservices?
DDD and microservices are complementary. DDD provides a way to design and structure the system, while microservices provide a way to deploy and scale it. Each microservice can be designed as an aggregate, ensuring that it encapsulates a specific business rule and that it can be developed, deployed, and scaled independently.
How does DDD handle data persistence?
In DDD, data persistence is handled by repositories. A repository provides a way to retrieve and store aggregates. It provides an abstraction over the underlying data storage mechanism, allowing the rest of the system to focus on the domain logic.
How does DDD handle concurrency issues?
DDD handles concurrency issues by ensuring that only one transaction can modify an aggregate at a time. This is achieved by using the aggregate root to coordinate changes to the aggregate. If two transactions try to modify the same aggregate at the same time, one of them will have to wait until the other one has completed.