


Key Takeaways
- JavaScript’s single-threaded nature means that asynchronous operations, like API calls, are essential for non-blocking UIs, and handling these operations efficiently is crucial in React Redux applications.
- Redux Thunk, Redux-Saga, and Redux-Observables are popular middleware options for managing async operations in Redux, each offering different advantages depending on the complexity and requirements of the application.
- Redux Thunk simplifies async action dispatch by allowing functions to be returned instead of actions, enabling sequential API calls and handling of dependent data within these functions.
- Redux-Saga utilizes ES6 generators to provide a more robust solution for complex scenarios, such as handling race conditions, pausing, and cancelling operations, making it suitable for large-scale applications.
- Redux-Observables, leveraging RxJS, offers a powerful approach to managing side effects through streams of actions, providing excellent scalability and control over async operations in sophisticated app architectures.
This post was originally posted at Codebrahma.
JavaScript is a single-threaded programming language. That is, when you have code something like this …

… the second line doesn’t get executed till the first one gets completed. Mostly this won’t be a problem, since millions of calculations are performed by the client or server in a second. We notice the effects only when we’re performing a costly calculation (a task that takes noticeable time to complete — a network request which takes some time to return back).
Why did I show only an API call (network request) here? What about other async operations? An API call is a very simple and useful example for describing how to deal with an asynchronous operation. There are other operations, like setTimeout(), performance-heavy calculations, image loading, and any event-driven operations.
While structuring our application, we need to consider how asynchronous execution impacts structuring. For example, consider fetch() as a function that performs an API call (network request) from the browser. (Forget if it is an AJAX request. Just think of the behavior as either asynchronous or synchronous in nature.) The time elapsed while the request is processed on the server doesn’t happen on the main thread. So your JS code will keep getting executed, and once the request returns a response it will update the thread.
Consider this code:
userId = fetch(userEndPoint); // Fetch userId from the userEndpoint
userDetails = fetch(userEndpoint, userId) // Fetch for this particular userId.
In this case, since fetch() is asynchronous, we won’t be having userId when we try to fetch userDetails. So we need to structure it in a way that ensures the second line executes only when the first returns a response.
Most modern implementations of network requests are asynchronous. But this doesn’t always help, since we depend on the previous API response data for the subsequent API calls. Let’s look at how particularly we can structure this in ReactJS/Redux applications.
React is a front-end library used for making user interfaces. Redux is a state container that can manage the whole state of the application. With React in combination with Redux, we can make efficient applications that scale well. There are several ways to structure async operations in such a React application. For each method, let’s discuss the pros and cons in relation to these factors:
- code clarity
- scalability
- ease of error handling.
For each method, we’ll perform these two API calls:
1. Fetching city from userDetails (First API response)
Let’s assume the endpoint is /details. It will have the city in the response. The response will be an object:
userDetails : {
…
city: 'city',
…
};
2. Based on the user city we will fetch all restaurants in the city
Let’s say the endpoint is /restuarants/:city. The response will be an array:
['restaurant1', 'restaurant2', …]
Remember that we can do the second request only when we finish doing the first (since it’s dependent on the first request). Let’s look at various ways to do this:
- directly using promise or async await with setState
- using Redux Thunk
- using Redux-Saga
- using Redux Observables.
Particularly I have chosen the above methods because they’re the most popularly used for a large-scale project. There are still other methods that can be more specific to particular tasks and that don’t have all the features required for a complex app (redux-async, redux-promise, redux-async-queue to name a few).
Promises
A promise is an object that may produce a single value some time in the future: either a resolved value, or a reason that it’s not resolved (e.g., a network error occurred). — Eric Elliot
In our case, we’ll use the axios library to fetch data, which returns a promise when we make a network request. That promise may resolve and return the response or throw an error. So, once the React Component mounts, we can straight away fetch like this:
componentDidMount() {
axios.get('/details') // Get user details
.then(response => {
const userCity = response.city;
axios.get(`/restaurants/${userCity}`)
.then(restaurantResponse => {
this.setState({
listOfRestaurants: restaurantResponse, // Sets the state
})
})
})
}
This way, when the state changes (due to fetching), Component will automatically re-render and load the list of restaurants.
Async/await is a new implementation with which we can make async operations. For example, the same thing can be achieved by this:
async componentDidMount() {
const restaurantResponse = await axios.get('/details') // Get user details
.then(response => {
const userCity = response.city;
axios.get(`/restaurants/${userCity}`)
.then(restaurantResponse => restaurantResponse
});
this.setState({
restaurantResponse,
});
}
Both of these are the simplest of all methods. Since the entire logic is inside the component, we can easily fetch all the data once the component loads.
Drawbacks in the method
The problem will be when doing complex interactions based on the data. For example, consider the following cases:

- We don’t want the thread in which JS is being executed to be blocked for network request.
- All the above cases will make the code very complex and difficult to maintain and test.
- Also, scalability will be a big issue, since if we plan to change the flow of the app, we need to remove all the fetches from the component.
- Imagine doing the same if the component is at the top of the parent child tree. Then we need to change all the data dependent presentational components.
- Also to note, the entire business logic is inside the component.
How we can improve from here?
1. State Management
In these cases, using a global store will actually solve half of our problems. We’ll be using Redux as our global store.
2. Moving business logic to correct place
If we think of moving our business logic outside of the component, then where exactly can we do that? In actions? In reducers? Via middleware? The architecture of Redux is such that it’s synchronous in nature. The moment you dispatch an action (JS objects) and it reaches the store, the reducer acts upon it.
3. Ensuring there’s a separate thread where async code is executed and any change to global state can be retrieved through subscription
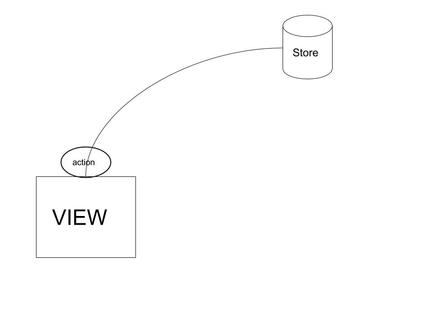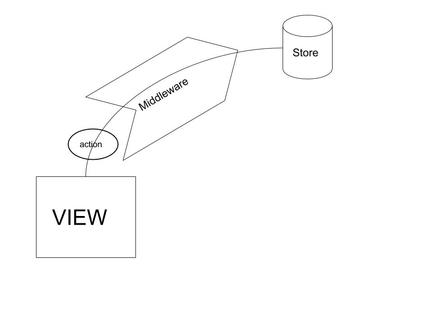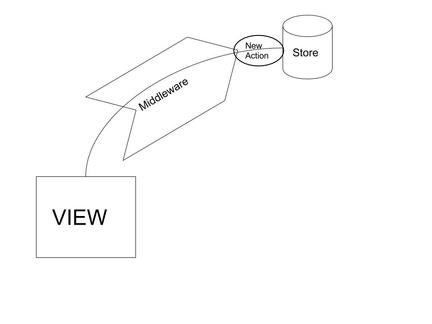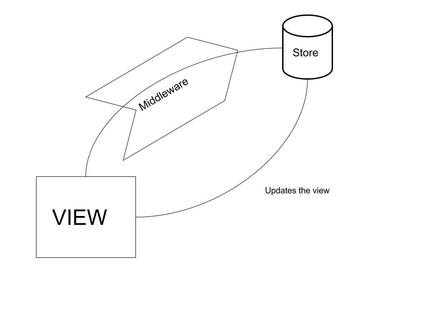
From this, we can get an idea that if we’re moving all the fetching logic before reducer — that is either action or middleware — then it’s possible to dispatch the correct action at the correct time.
For example, once the fetch starts, we can dispatch({ type: 'FETCH_STARTED' }), and when it completes, we can dispatch({ type: 'FETCH_SUCCESS' }).
Want to develop a React JS application?
Using Redux Thunk
Redux Thunk is middleware for Redux. It basically allows us to return function instead of objects as an action. This helps by providing dispatch and getState as arguments for the function. We use the dispatch effectively by dispatching the necessary actions at the right time. The benefits are:
- allowing multiple dispatches inside the function
- relating of business logic to the fetch will be outside of React components and moved to actions.
In our case, we can rewrite the action like this:
export const getRestaurants = () => {
return (dispatch) => {
dispatch(fetchStarted()); // fetchStarted() returns an action
fetch('/details')
.then((response) => {
dispatch(fetchUserDetailsSuccess()); // fetchUserDetailsSuccess returns an action
return response;
})
.then(details => details.city)
.then(city => fetch('/restaurants/city'))
.then((response) => {
dispatch(fetchRestaurantsSuccess(response)) // fetchRestaurantsSuccess(response) returns an action with the data
})
.catch(() => dispatch(fetchError())); // fetchError() returns an action with error object
};
}
As you can see, we now have a good control of when to dispatch what type of action. Each function call like fetchStarted(), fetchUserDetailsSuccess(), fetchRestaurantsSuccess() and fetchError() dispatches a plain JavaScript object of a type and additional details if required. So now it’s the job of the reducers to handle each action and update the view. I haven’t discussed the reducer, since it’s straightforward from here and the implementation might be varying.
For this to work, we need to connect the React component with Redux and bind the action with the component using the Redux library. Once this is done, we can simply call this.props.getRestaurants(), which in turn will handle all the above tasks and update the view based on the reducer.
In terms of its scalability, Redux Thunk can be used in apps which don’t involve complex controls over async actions. Also, it works seamlessly with other libraries, as discussed in the topics of the next section.
But still, it’s a little difficult to do certain tasks using Redux Thunk. For example, we need to pause the fetch in between, or when there are multiple such calls, and allow only the latest, or if some other API fetches this data and we need to cancel.
We can still implement those, but it will be little complicated to do exactly. Code clarity for complex tasks will be little poor when compared with other libraries, and maintaining it will be difficult.
Using Redux-Saga
Using the Redux-Saga middleware, we can get additional benefits that solve most of the above-mentioned functionalities. Redux-Saga was developed based on ES6 generators.
Redux-Saga provides an API that helps to achieve the following:
- blocking events that block the thread in the same line till something is achieved
- non-blocking events that make the code async
- handling race between multiple async requests
- pausing/throttling/debouncing any action.
How do sagas work?
Sagas use a combination of ES6 generators and async await APIs to simplify async operations. It basically does its work on a separate thread where we can do multiple API calls. We can use their API to make each call synchronous or asynchronous depending on the use case. The API provides functionalities by which we can make the thread to wait in the same line till the request returns a response. Apart from this, there are lot of other APIs provided by this library, which makes API requests very easy to handle.
Consider our previous example: if we initialize a saga and configure it with Redux as mentioned in their documentation, we can do something like this:
import { takeEvery, call } from 'redux-saga/effects';
import request from 'axios';
function* fetchRestaurantSaga() {
// Dispatches this action once started
yield put({ type: 'FETCH_RESTAURANTS_INITIATED '});
try {
// config for fetching details API
const detailsApiConfig = {
method: 'get',
url: '/details'
};
// Blocks the code at this line till it is executed
const userDetails = yield call(request, config);
// config for fetching details API
const restaurantsApiConfig = (city) {
method: 'get',
url: `/restaurants/${city}`,
};
// Fetches all restuarants
const restaurants = yield call(request, restaurantsApiConfig(userDetails.city));
// On success dispatch the restaurants
yield put({
type: 'FETCH_RESTAURANTS_SUCCESS',
payload: {
restaurants
},
});
} catch (e) {
// On error dispatch the error message
yield put({
type: 'FETCH_RESTAURANTS_ERROR',
payload: {
errorMessage: e,
}
});
}
}
export default function* fetchRestaurantSagaMonitor() {
yield takeEvery('FETCH_RESTAURANTS', fetchInitial); // Takes every such request
}
So if we dispatch a simple action with type FETCH_RESTAURANTS, the Saga middleware will listen and respond. Actually, none of the Actions get consumed by the middleware. It just listens and does some additional tasks and dispatches a new action if required. By using this architecture, we can dispatch multiple requests each describing
- when the first request started
- when the first request finished
- when the second request started
… and so on.
Also, you can see the beauty of fetchRestaurantsSaga(). We have currently used a call API for implementing blocking calls. Sagas provide other APIs, like fork(), which implements non-blocking calls. We can combine both blocking and nonblocking calls to maintain a structure that fits our application.
In terms of scalability, using sagas is beneficial:
- We can structure and group sagas based on any particular tasks. We can trigger one saga from another by simply dispatching an action.
- Since it’s middleware, actions that we write will be plain JS objects, unlike thunks.
- Since we move the business logic inside sagas (which is a middleware), if we know what will be the functionality of a saga, then understanding the React part of it will be much easier.
- Errors can easily be monitored and dispatched to the store through a try/catch pattern.
Using Redux-Observables
As mentioned in their documentation under “An epic is the core primitive of redux-observable”:
-
An Epic is a function that takes a stream of actions and returns a stream of actions. That is, an Epic runs alongside a normal Redux dispatch channel, after the reducers have already received them.
-
Actions always run through your reducers before epics even receive them. An Epic just receives and outputs another stream of actions. This is similar to Redux-Saga, in that none of the Actions get consumed by the middleware. It just listens and does some additional tasks.
For our task, we can simply write this:
const fetchUserDetails = action$ => (
action$.ofType('FETCH_RESTAURANTS')
.switchMap(() =>
ajax.getJSON('/details')
.map(response => response.userDetails.city)
.switchMap(() =>
ajax.getJSON(`/restaurants/city/`)
.map(response => ({ type: 'FETCH_RESTAURANTS_SUCCESS', payload: response.restaurants })) // Dispatching after success
)
.catch(error => Observable.of({ type: 'FETCH_USER_DETAILS_FAILURE', error }))
)
)
)
At first, this might look little confusing. But the more you understand RxJS, the easier it is to create an Epic.
As in the case of sagas, we can dispatch multiple actions each one describing at what part of the API request chain the thread currently is in.
In terms of scalability, we can split Epics or compose Epics based on particular tasks. So this library can help in building scalable applications. Code clarity is good if we understand the Observable pattern of writing code.
My Preferences
How do you determine which library to use?
It depends on how complex our API requests are.
How do you choose between Redux-Saga and Redux-Observable?
It comes down to the learning generators or RxJS. Both are different concepts but equally good enough. I would suggest trying both to see which one suits you best.
Where do you keep your business logic dealing with APIs?
Preferably before the reducer, but not in the component. The best way would be in middleware (using sagas or observables).
You can read more React Development posts at Codebrahma.
Frequently Asked Questions on Async Operations in React-Redux Applications
What is the role of middleware in handling async operations in Redux?
Middleware in Redux plays a crucial role in handling asynchronous operations. It provides a third-party extension point between dispatching an action and the moment it reaches the reducer. Middleware can be used to log, modify, and even cancel actions, as well as dispatch other actions. In the context of async operations, middleware like Redux Thunk or Redux Saga allows you to write action creators that return a function instead of an action. This function can then be used to delay the dispatch of an action or to dispatch only if certain conditions are met.
How does Redux Thunk help in managing async operations?
Redux Thunk is a middleware that allows you to write action creators that return a function instead of an action. The thunk can be used to delay the dispatch of an action or to dispatch only if certain conditions are met. This functionality makes it a great tool for handling async operations in Redux. For instance, you can dispatch an action to indicate the start of an API call, then dispatch another action when the call returns with the data or an error message.
What is the difference between Redux Thunk and Redux Saga?
Both Redux Thunk and Redux Saga are middleware used for managing side effects, including async operations, in Redux. The main difference between the two lies in their approach. Redux Thunk uses callback functions to handle async operations, while Redux Saga uses generator functions and a more declarative approach. This makes Redux Saga more powerful and flexible, but also more complex. If your application has simple async operations, Redux Thunk might be sufficient. However, for more complex scenarios involving race conditions, cancellation, and if-else logic, Redux Saga might be a better choice.
How can I handle errors in async operations in Redux?
Error handling in async operations in Redux can be done by dispatching an action when an error occurs during the async operation. This action can carry the error message as its payload. In your reducer, you can then handle this action to update the state with the error message. This way, the error message can be displayed to the user or logged for debugging purposes.
How can I test async actions in Redux?
Testing async actions in Redux can be done by mocking the Redux store and the API calls. For the Redux store, you can use libraries like redux-mock-store. For the API calls, you can use libraries like fetch-mock or nock. In your test, you dispatch the async action, then assert that the expected actions were dispatched with the correct payloads.
How can I cancel an async operation in Redux?
Cancelling an async operation in Redux can be done using middleware like Redux Saga. Redux Saga uses generator functions, which can be cancelled using the cancel effect. When the cancel effect is yielded, the saga is cancelled from the point it was started to the current effect.
How can I handle race conditions in async operations in Redux?
Race conditions in async operations in Redux can be handled using middleware like Redux Saga. Redux Saga provides effects like takeLatest and takeEvery, which can be used to handle concurrent actions. For instance, takeLatest cancels any previous saga task started if it’s still running when a new action is dispatched.
How can I use async/await with Redux Thunk?
Redux Thunk supports async/await out of the box. In your action creator, you can return an async function instead of a regular function. Inside this async function, you can use async/await to handle async operations. The dispatch function can be called with an action object when the async operation completes.
How can I handle loading states in async operations in Redux?
Loading states in async operations in Redux can be handled by dispatching an action before and after the async operation. The action dispatched before the operation can set a loading state to true, and the action dispatched after the operation can set it back to false. In your reducer, you can handle these actions to update the loading state in your store.
How can I handle side effects in Redux?
Side effects in Redux can be handled using middleware like Redux Thunk or Redux Saga. These middleware allow you to write action creators that return a function instead of an action. This function can be used to perform side effects, such as async operations, logging, and conditional dispatching of actions.

