
Key Takeaways
- OrientDB is an open-source GraphDB that combines features from Document Databases and Object Orientation, offering a flexible schema from its Document DB roots and relationships as first-class citizens, like a graph database.
- OrientDB’s impressive performance claims include more than 150,000 inserts/second, and it already has a cloud service behind it in Nuvolabase.
- OrientDB is written in Java and can be run anywhere. It comes with a server, console, and Gremlin console, and supports three storage “engines”: memory, local, and plocal.
- OrientDB breaks the data into OO-like classes, which can be either a (V)ertex or an (E)dge subclass. Each class has one or more clusters, which are “a generic way to group records”. Records are instances of a class and are documents in the Document DB sense, as well as nodes in the Graph DB sense.
![]() In this post, I am going to give you a brief introduction to a OrientDB. In later posts in this series, I will take you through using OrientDB with Ruby.
In this post, I am going to give you a brief introduction to a OrientDB. In later posts in this series, I will take you through using OrientDB with Ruby.
You have probably heard of document databases, like MongoDB, and you may have heard of graph databases, like Neo4j. I am willing to bet you have not heard of very many, if any, Graph-Document databases.
That’s right. OrientDB touts itself as “The Graph-Document NoSQL.” From the website:
OrientDB is an Open Source GraphDB with a mix of features taken from Document Databases and Object Orientation.
Sound interesting? Or crazy? Or both?
We found OrientDB after going fairly far down the path with Neo4j[1], only to find out that Neo4j’s pricing for its “enterprise” features (namely, HA) was beyond our startup-limited reach. OrientDB’s has an Apache2 license which is more permissive than Neo4j’s.[2]
I love the GraphDB concepts, such as directed property relationships as well as the flexibility that comes with the graph approach. If you are unfamiliar with graph database concepts, check out these two posts (one and two) by Thiago Jackiw.
If you need a primer on document databases, check out this post from 10gen.
In essence, OrientDB holds the promise of a flexible schema from its Document DB roots, along with relationships as first-class citizens, like a graph database. A good example of both worlds is how OrientDB supports Embedded and Referenced Relationships. The former are contained inside the record and only accessible via that container. Referenced relationships are like edges from the Graph DB world, accessible as first-class objects with a start vertex, end vertex, and properties.
Orient has some impressive claims, such as more than 150,000 inserts/second and already has a cloud service behind it in Nuvolabase. In fact, Nuvolabase offers a demo of the “studio” app that comes with OrientDB, which you can see here.
Not Made in America
If you looked at the Nuvolabase pricing, you probably noticed that it’s not in good ol’ ‘Merican dollars. Currently, it seems the vast majority of OrientDB customers are in Europe. Also, the company behind OrientDB, Orient Technologies, is in London. I only mention it because 1) I am in the States, and 2) I’ve not heard much about OrientDB before I stumbled upon it. Other than that, I don’t really see it as an issue.
Installation
Enough background, let’s install OrientDB and play with it. OrientDB is written in Java, so you should be able to run it anywhere. It comes with a server, console, and Gremlin console. Don’t worry about Gremlin right now, I’ll talk about it later.
The available versions to download are here. Currently, I would recommend the 1.5.0 Stable release. Just click the big green button on that page to get a zip of the release.
Extract that file to a directory, which I’ll presume is named orientdb. The directory structure of OrientDB is fairly typical:
![]()
I’ll only touch on the config, bin and databases directories today.
Config
There are several files in the config directory. We just want to run the “standard” server, so open up the orientdb-server-config.xml file.
Remember XML? It is still XML and it still dominates Java configuration. Regardless, there are bunch of settings in here that you can research on your own (or I’ll post about later, perhaps). For now, scroll down until you see <users> section.
This section defines (you guessed it) the users that can access the server. By default, OrientDB provides a “root” and “guest” user. I like to add my own user with a much more reasonable password, so feel free to add:
<user resources="*" password="password" name="user"/>
The resources attribute controls what the user can do. A value of * makes that user all-powerful, so govern yourself accordingly. There is some documentation on the OrientDB wiki, but it doesn’t feel complete.
Save the config file and close it.
Databases
The databases directory holds (you guessed it again) the databases served by this server. Any databases in this directory are visible to the server without configuration. When you create a new database, a new folder will be created in this directory with the same name as your database. We’ll do that in a bit.
This directory is, however, simply the default directory for databases. You can add other storage sites via configuration.
OrientDB supports three storage “engines”: memory, local, and plocal. Memory is self-explanatory.
The local and plocal storage types use the filesystem. Local is the “old way,” it seems, and is the most feature rich right now. Plocal is the “new way,” but is missing some big-time features, such as transactions. You can read more here.
OrientDB ships with a demo database called tinkerpop, which you can play with when we fire up the server.
Bin: Fire it Up
The bin directory, as is so often the case, has the fun stuff. Namely, it contains scripts to launch the various types of servers and consoles. Today, we’ll just launch the vanilla standalone server, using server.sh (or server.bat if you are on Windows).
Note: I had to chmod +x *.sh inside that directory, as all my shell scripts were not executable.
Once you fire up the server, you’ll see something like:

Ahhh…don’t you love ASCII art? I do. As long as you don’t see any errors, everthing is ready to go. OrientDB comes with a handy web application where you can browse the database, create classes, records, indices, etc. By default, it lives at http://localhost:2480. When you visit that page, it will ask you to login. Be sure to use the username and password we defined in the configuration above. You should only have the tinkerpop database in the database drop-down right now.
Once logged in, you should see:
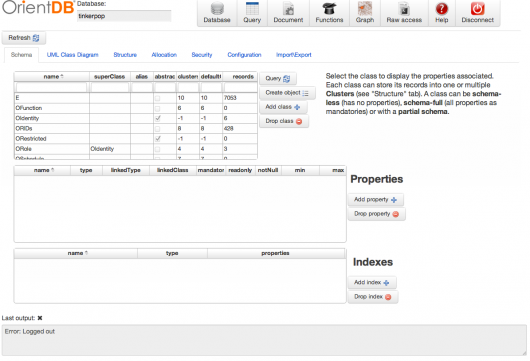
The Studio app starts you off on the “Schema” tab in the “Database” section. This shows the classes available along with some other metadata. The important ones to notice are V and E, which stand for Vertex and Edge, respectively. These are the base classes of your graph database, and when you create a new class (also knows as a “vertex type” or “edge type”) it will inherit from one of these classes.
The tinkerpop database does not have any vertex subclasses, but it does have three edge subclasses: followed_by,, sung_by, and written_by. The indication that they are an edge subclass is the ‘E’ value in the superclass column. Vertex subclasses, as you probably guessed, have a ‘V’ in that column. Oh, and you can create subclasses of subclasses.
You can think of classes much like classes in the Object-Oriented world. They define a “type of record.” As a brief demo, select the “V” class in the table and click the “Query” button. You’ll be taken to the Query page, which looks like:
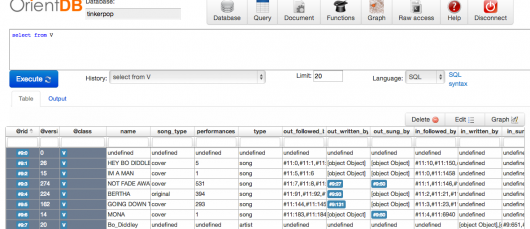
Here you can see the records and properties of the V class. Any attribute that starts with a ‘@’ (so, @rid, @version, and @class) is a OrientDB system property, meaning all classes have them. The rest are either user defined or defined as a part of a relationship. The relationship properties start with in_ or out_, each holding the ids of the edge records coming into or out of each vertex for each relationship type.
Your first look at the OrientDB can be, well, disorienting. The relationship properties and odd ids (like, “#11:0”) can take you right out of your comfort zone. A quick chat about how the data is structured in OrientDB may help.
Structure
As previously mentioned, OrientDB breaks the data into OO-like classes. These classes have inheritence and, in the graph world, can be either a (V)ertex or an (E)dge subclass. Each class has one or more clusters, which are “a generic way to group records”. You can group a class into clusters based on attribution.
For example, if you had an Invoice class, you could group the 2012 invoices into a Invoice2012 cluster and the 2013 invoices into a Invoice2013 cluster. You specify which cluster to use for a given record when you create that record. Every class has at least one default physical cluster that is used if none is specified on record creation.
The point of clusters is to group data that you will want to query together. We haven’t done much with them yet, but plan to use them extensively as we grow with OrientDB.
Records are what you would expect: an instance of a class. They are documents in the Document DB sense, as well as nodes in the Graph DB sense. Records live in a cluster and have the schema defined by the class. Classes, Clusters, and Records are the lion’s share of OrientDB’s data structure.
Relationships, as I’ve alluded to, are the “edges” of the property graph and are first-class citizens. They have direction (meaning, an “in” vertex and an “out” vertex) and can have properties. Much of a graph database’s speed comes from the ease of traversing the graph from vertex to edge to vertex, etc. which is why graphs are the choice of most social networking sites. These kinds of relationships are meant to avoid the “join pain” of the traditional RDBMS, where the weight of millions of joins cause massive performance issues.
Playing with Data
The bin directory also has a console script (either .sh or .bat, depending on your OS). Open a new terminal and fire up the console.
OrientDB has an extensive console command list. Today, we’ll create a database, add a vertex type, create some data, then query for that data.
Create a Database
create database plocal:databases/sitepoint-test user pass plocal graph
(Note: I started my console.sh from the root of the OrientDB installation, so the relative path to my databases folder is reflected above. If you started the console from the bin dir, you’ll need to put in a relative or absolute path to get the database to be created in the right place.)

Notice that the console has made this new database “current.” This means commands and queries will be run against this database.
Create a Vertex Type and Vertex
Let’s create a “Person” vertex type and make two people.
create class Person extends V
=> Class created successfully. Total classes in database now: 11
Remember, a vertex type is just a subclass of Vertex.
Now, we can add a property .
create property Person.name string
=> Property created successfully with id=1
And now, create our lovers.
create vertex Person set name='Joanie'
=> Created vertex 'Person#11:0{name:Joanie} v0' in 0.076000 sec(s).
create vertex Person set name='Joanie'
=> Created vertex 'Person#11:1{name:Chachie} v0' in 0.001000 sec(s).
Create an Edge Type and Edge
Creating our edge/relationship is very similar to creating our vertex type and vertices. However, you don’t have to create an edge type if your relationship is not going to have any properties. We’ll keep it simple today and just mimic what we did with vertices.
create class loves extends E
=> Class created successfully. Total classes in database now: 12
create edge loves from #11:1 to #11:0
=> Created edge '[loves{in:#11:0,out:#11:1}]' in 0.003000 sec(s).
Querying
select from Person
----+-----+-------
# |@RID |name
----+-----+-------
0 |#11:0|Joanie
1 |#11:1|Chachie
----+-----+-------
select name as subject, out_loves.name as loves from person
----+-----+-------+------
# |@RID |subject|loves
----+-----+-------+------
0 |#-2:1|Joanie |null
1 |#-2:2|Chachie|Joanie
----+-----+-------+------
You’ll notice that OrientDB has a very SQL-ish syntax, which is nice when you’re trying to digest all the new concepts
There is tons more you can do, obviously. This example serves to whet your whistle.
Conclusion
That’s as far as I want to go with OrientDB today. In the next post, I’ll talk about the orientdb-jruby gem as well as a new gem (codename: “oriented”) we are writing as a part of our work. Until then, explore the OrientDB console and studio application and check out the Google Group (linked below).
Resources
1: Which is really, really great. Really, if it weren’t for budget issues, I probably would not have looked beyond Neo4j.
2: To be fair, Neo4j licenses their commercial and enterprise offerings. In my opinion, you couldn’t really deploy a production app without their enterprise features. OrientDB also charges for their “enterprise” offering, as shown here, but it doesn’t remove any of the features that allow scaling. This is not a post about Neo4j vs OrientDB, so that’s all I have to say about that.
Frequently Asked Questions about OrientDB
How do I get started with OrientDB in Java?
OrientDB is a versatile NoSQL database system which supports multiple models. To get started with OrientDB in Java, you need to first install OrientDB and Java Development Kit (JDK) on your system. After installation, you can connect to the OrientDB server using the OrientDB API. You can create a new database, define classes, and create records using the API. Remember to close the database and OrientDB server after you’re done to free up resources.
How can I use OrientDB with Python?
OrientDB can be used with Python through PyOrient, which is OrientDB’s native Python driver. PyOrient allows you to connect to an OrientDB server, manage databases, execute commands, and handle records. You need to install PyOrient first, and then you can import it in your Python script to use its functionalities.
What are the key features of OrientDB?
OrientDB is a multi-model NoSQL database system with support for graph, document, key-value, and object models. It provides ACID transaction support, SQL support, and can handle relationships without using joins. It also supports schema-less, schema-full, and schema-mixed modes, and has a strong security profiling system based on user roles.
How can I learn OrientDB?
There are several resources available to learn OrientDB. The official OrientDB website provides comprehensive documentation, tutorials, and guides. There are also several online platforms like TutorialsPoint that provide OrientDB tutorials. You can also refer to various books, online courses, and video tutorials available on the internet.
How do I interface OrientDB with Python?
You can interface OrientDB with Python using PyOrient, which is OrientDB’s native Python driver. PyOrient allows you to connect to an OrientDB server, manage databases, execute commands, and handle records. You need to install PyOrient first, and then you can import it in your Python script to use its functionalities.
What is the difference between OrientDB and other NoSQL databases?
Unlike other NoSQL databases, OrientDB supports multiple data models including graph, document, key-value, and object models. It also provides ACID transaction support, SQL support, and can handle relationships without using joins. It also supports schema-less, schema-full, and schema-mixed modes, and has a strong security profiling system based on user roles.
How do I install OrientDB?
OrientDB can be installed on various operating systems including Windows, Linux, and MacOS. You can download the latest version of OrientDB from the official website and follow the installation instructions provided in the documentation.
How do I create a database in OrientDB?
You can create a database in OrientDB using the CREATE DATABASE command. You need to specify the database name, the storage type (plocal or memory), and the database type (document or graph). You can also specify the username and password for the database.
How do I query data in OrientDB?
You can query data in OrientDB using SQL commands. OrientDB supports a subset of SQL along with some additional commands and features. You can use SELECT, INSERT, UPDATE, DELETE, and other SQL commands to query data in OrientDB.
How do I handle relationships in OrientDB?
OrientDB is a graph database and can handle relationships without using joins. You can create relationships between records using links. You can also use the graph API to manage relationships in a more intuitive way.