

With the eCommerce boom, I have become a fan of price comparison apps in recent years. Each purchase I make online (or even offline) is the result of a thorough investigation across sites offering the product.
Some of the apps I use include RedLaser, ShopSavvy and BuyHatke, which have been doing great work in increasing transparency and saving the time of consumers.
Have you ever wondered how these apps get that important data? In most cases, the process employed by the apps is web scraping.
Key Takeaways
- Web scraping is a process of extracting data from the web, which can be automated using programming languages like Python and tools like Beautiful Soup. This can be useful for activities such as price comparisons, SEO tracking, news analysis, and sentiment analysis on social media.
- It’s crucial to be aware of the legal issues involved in web scraping. Many websites prohibit scraping in their terms of service, and scraping sites that do not allow it could result in being blacklisted or even legal action.
- Web scraping involves sending a request to a URL, receiving the response, and analyzing the response to find required data. Python’s Beautiful Soup module can be used to parse the HTML data and extract the needed information.
- To scrape data from parts of a website that require a login, or to emulate a browser to avoid being blocked, tools like mechanize and cookielib can be used. These allow you to manage sessions using cookies, emulate a browser, and even access restricted areas of a website after a login.
Web Scraping Defined

Web scraping is the process of extracting data on the web. With the right tools, anything that’s visible to you can be extracted. In this post, we’ll focus on writing programs that automate this process and help you gather huge amounts of data in a relatively short time. Apart from the example I’ve already given, scraping has a lot of uses like SEO tracking, job tracking, news analysis, and — my favorite — sentiment analysis on social media!
A note of caution
Before you go on a web scraping adventure, make sure you’re aware of the legal issues involved. Many websites specifically prohibit scraping in their terms of service. For example, to quote Medium, “Crawling the Services is allowed if done in accordance with the provisions of our robots.txt file, but scraping the Services is prohibited.” Scraping sites that do not allow scraping might actually get you blacklisted from them! Just like any other tool, web scraping can be used for for reasons like copying the content of other sites. Scraping has led to many lawsuits too.
Setting Up the Code
Now that you know that we must tread carefully, let’s get into scraping. Scraping can be done in any programming language, and we covered it for Node some time back. In this post, we’re going to use Python for the simplicity of the language and the availability of packages that make the process easy.
What’s the underlying process?
When you’re accessing a site on the Internet, you’re essentially downloading HTML code, which is analyzed and displayed by your web browser. This HTML code contains all the information that’s visible to you. Therefore, the required information (like the price) can be obtained by analyzing this HTML code. You can use regular expressions to search for your needle in the haystack, or use a library to parse the HTML and get the required data.
In Python, we’re going to use a module called Beautiful Soup to analyze this HTML data. You can install the module through an installer like pip by running the following command:
pip install beautifulsoup4
Alternately, you can build it from the source. The installation steps are listed on the module’s documentation page.
After getting that installed, we’ll broadly follow the following steps:
- send a request to URL
- receive the response
- analyze the response to find required data.
For demonstration purposes, we’ll use my blog http://dada.theblogbowl.in/.
The first two steps are fairly simple, and can be accomplished as follows:
from urllib import urlopen
#Sending the http request
webpage = urlopen('http://my_website.com/').read()
Next, we need to provide the response to
from bs4 import BeautifulSoup
#making the soup! yummy ;)
soup = BeautifulSoup(webpage, "html5lib")
Notice that we used html5lib as our parser. You may install a different parser for BeautifulSoup as mentioned in their documentation.
Parsing the HTML
Now that we’ve supplied the HTML to BeautifulSoup, let’s check out a few commands. To check that we have the correct HTML markup, let’s verify the title of the page (on the Python interpreter):
>>> soup.title
<title>Transcendental Tech Talk</title>
>>> soup.title.text
u'Transcendental Tech Talk'
>>>
Next, we move on to extracting specific elements from the page. Let’s say I want to extract the list of titles of posts on my blog. To do so, I would need to analyze the HTML structure, which I accomplish through the Chrome Inspector (Right click on an item and select “Inspect Element”). Similar tools are available in other browsers too.
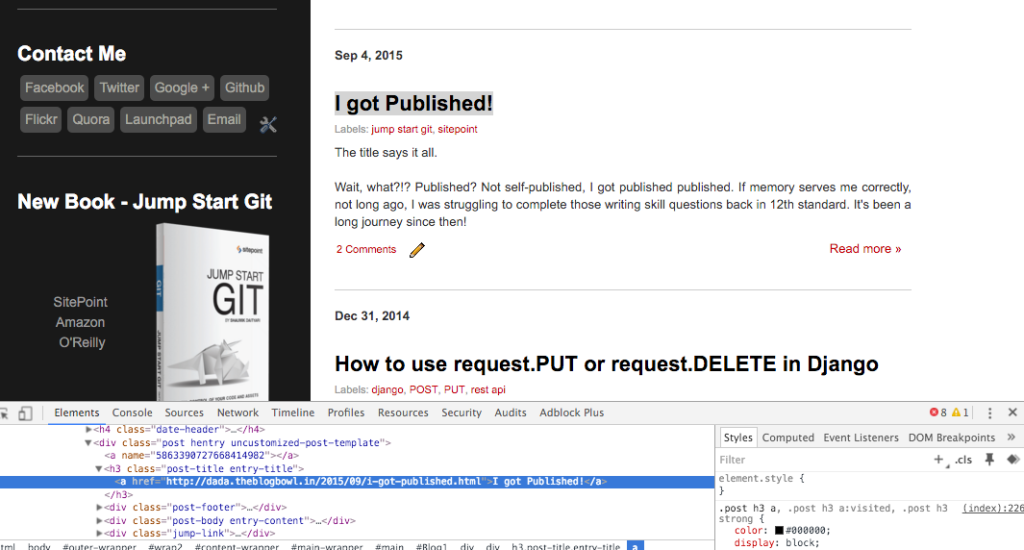
Using the Chrome Inspector to check the HTML structure of a page
As you can observe, all titles are housed under the h3 tags, with two classes — post-title and entry-title. Searching for all h3 elements with the class post-title should get me the list of titles on the page. We use the find_all function of BeautifulSoup and use the class_ argument to specify our class:
>>> titles = soup.find_all('h3', class_ = 'post-title') #Getting all titles
>>> titles[0].text
u'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n'
>>>
The same result could be achieved by searching for items with the class post-title:
>>> titles = soup.find_all(class_ = 'post-title') #Getting all items with class post-title
>>> titles[0].text
u'\nKolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips\n'
>>>
In case you’re interested in the links to further explore the items, you can run the following:
>>> for title in titles:
... # Each title is in the form of <h3 ...><a href=...>Post Title<a/></h3>
... print title.find("a").get("href")
...
http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html
http://dada.theblogbowl.in/2015/09/i-got-published.html
http://dada.theblogbowl.in/2014/12/how-to-use-requestput-or-requestdelete.html
http://dada.theblogbowl.in/2014/12/zico-isl-and-atk.html
...
>>>
There are many built-in methods in BeautifulSoup to navigate through the HTML, some of them illustrated below:
>>> titles[0].contents
[u'\n', <a href="http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html">Kolkata #BergerXP IndiBlogger meet, Marketing Insights, and some Blogging Tips</a>, u'\n']
>>>
Do note that you may also use the children attribute, but it acts as a generator:
>>> titles[0].parent
<div class="post hentry uncustomized-post-template">\n<a name="6501973351448547458"></a>\n<h3 class="post-title entry-title">\n<a href="http://dada.theblogbowl.in/2015/09/kolkata-bergerxp-indiblogger-meet.html">Kolkata #BergerXP IndiBlogger ...
>>>
You can use regular expressions to search for the CSS class too, as explained in the documentation.
Emulate Logins Using Mechanize
What we’ve done up to now is essentially download a page and analyze its contents. However, a web developer may have blocked requests through non-browsers, or a part of a website might only be accessible after a login. How should we go about the process then?
In the first case, we need to emulate a browser when we’re sending a request to a page. Every HTTP request has a number of associated headers that include information about things like the visitor’s browser, operating system and screen size. We can manipulate that and make it look like a browser is sending the request.
In the second case, we need to log in to the website and maintain the session using cookies in order to access restricted areas. Let’s see how to do this while also emulating a browser.
We’ll use the module cookielib for managing our session using cookies. Further, we’ll use mechanize, which can be installed through an installer like pip.
We’ll login through this page on The Blog Bowl, and then access our notifications page. The code is explained inline through the comments:
import mechanize
import cookielib
from urllib import urlopen
from bs4 import BeautifulSoup
# Cookie Jar
cj = cookielib.LWPCookieJar()
browser = mechanize.Browser()
browser.set_cookiejar(cj)
browser.set_handle_robots(False)
browser.set_handle_redirect(True)
# Solving issue #1 by emulating a browser by adding HTTP headers
browser.addheaders = [('User-agent', 'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.1) Gecko/2008071615 Fedora/3.0.1-1.fc9 Firefox/3.0.1')]
# Open Login Page
browser.open("http://theblogbowl.in/login/")
# Select Login form (1st form of the page)
browser.select_form(nr = 0)
# Alternate syntax - browser.select_form(name = "form_name")
# The first <input> tag of the form is a CSRF token
# Setting the 2nd and 3rd tags to email and password
browser.form.set_value("email@example.com", nr=1)
browser.form.set_value("password", nr=2)
# Logging in
response = browser.submit()
# Opening new page after login
soup = BeautifulSoup(browser.open('http://theblogbowl.in/notifications/').read(), "html5lib")
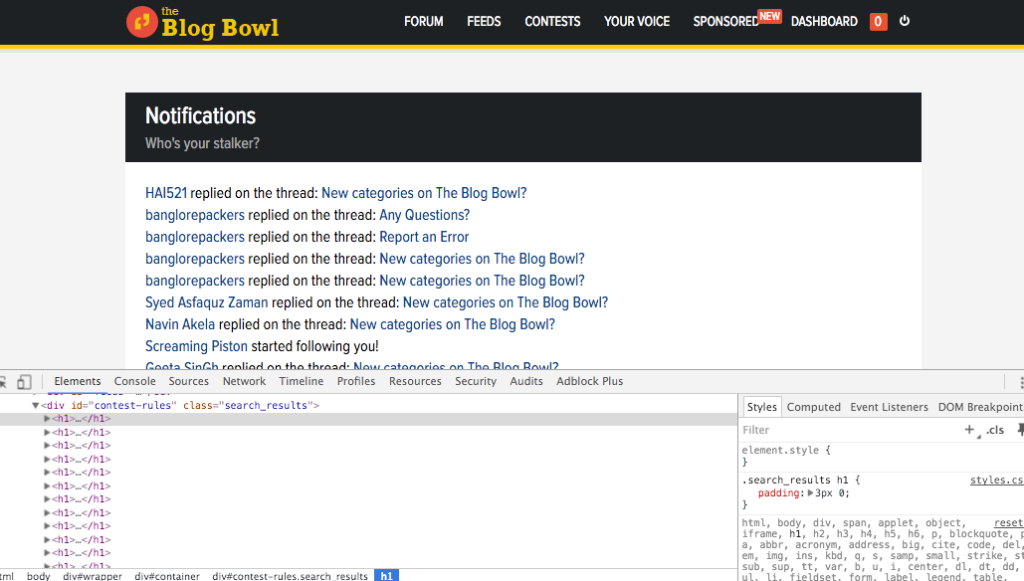
Structure of the notifications page
# Print notifications
print soup.find(class_ = "search_results").text
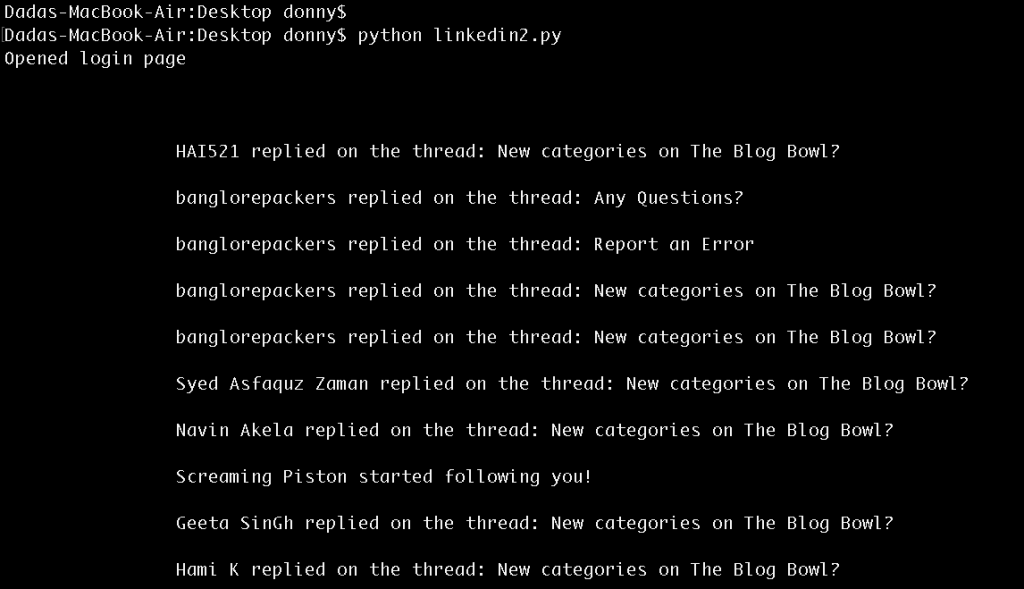
Results of logging in to the notification page
Final Words
As many developers will tell you that anything you can view online can be scraped. With this post, you know that something behind a login can also easily be extracted. In cases where your IP gets blocked, you may mask your IP address (or use a different one). To make it look like a human is accessing the data, you may maintain a time lag between your requests too.
With the increasing need for data, web scraping (for both good and bad reasons) is only going to increase in the future. It is thus advisable that you understand the process either to use it effectively or save yourself from it!
Frequently Asked Questions (FAQs) on Web Scraping for Beginners
What is the difference between web scraping and web crawling?
Web scraping and web crawling are two terms often used interchangeably, but they are different. Web crawling is a process used by search engines to visit and index web pages. It involves following all the links on a webpage. On the other hand, web scraping is the process of extracting specific data from a webpage. Unlike web crawling, it doesn’t involve moving around the web.
Is web scraping legal?
The legality of web scraping depends on the specific circumstances. Some websites allow web scraping while others do not. It’s important to read and understand a website’s robots.txt file before scraping it. Also, scraping personal data can lead to legal issues, so it’s crucial to respect privacy laws.
How can I avoid getting blocked while web scraping?
There are several strategies to avoid getting blocked while web scraping. These include rotating your IP addresses, using a delay between requests, and using a headless browser. It’s also important to mimic human behavior as closely as possible to avoid detection.
Can I scrape data from any website?
While technically it’s possible to scrape data from any website, not all websites allow it. Some websites have measures in place to prevent web scraping, such as CAPTCHAs and rate limiting. Always check a website’s robots.txt file and terms of service before scraping it.
What are the best libraries for web scraping in Python?
Some of the best libraries for web scraping in Python include Beautiful Soup, Scrapy, and Selenium. Beautiful Soup is great for parsing HTML and XML documents, while Scrapy is a powerful and flexible web scraping framework. Selenium is useful for scraping websites that rely heavily on JavaScript.
How can I scrape websites that load content with JavaScript?
To scrape websites that load content with JavaScript, you can use libraries like Selenium or Puppeteer. These libraries allow you to control a web browser, which can load and execute JavaScript just like a normal browser.
What is the difference between static and dynamic web scraping?
Static web scraping involves extracting data from the source code of a webpage, while dynamic web scraping involves interacting with a webpage just like a human user would. Dynamic web scraping is necessary for websites that load content with JavaScript.
How can I clean and process the data I’ve scraped?
After scraping data, you can use libraries like Pandas to clean and process it. This might involve removing unnecessary characters, converting data types, and handling missing values.
Can I use web scraping for sentiment analysis?
Yes, web scraping can be used for sentiment analysis. By scraping reviews or comments from a website, you can analyze the sentiment of the text to understand public opinion about a product or topic.
How can I store the data I’ve scraped?
The data you’ve scraped can be stored in various formats, such as CSV, JSON, or a database. The best format depends on the nature of the data and how you plan to use it. Libraries like Pandas make it easy to save data in different formats.