

Key Takeaways
- Kimono is a tool that aims to simplify web scraping by creating APIs for websites that don’t have one. However, it may not be as intuitive or efficient as expected, especially for developers who are familiar with writing scrapers.
- While Kimono can handle simple single-page applications well, it struggles with multi-page scraping and complex web pages with a lot of logic. Its pagination feature only works if the website has a “next” button, limiting its capabilities.
- Kimono’s legality is based on the website’s robots.txt file and Terms of Service. Users should proceed with caution as scraping data from certain websites may pose legal issues.
Being a frequent reader of Hacker News, I noticed an item on the front page earlier this year which read, “Kimono – Never write a web scraper again.” Although it got a great number of upvotes, the tech junta was quick to note issues, especially if you are a developer who knows how to write scrapers. The biggest concern was a non-intuitive UX, followed by the inability of the first beta version to extract data items from websites as smoothly as the demo video suggested.
I decided to give it a few months before I tested it out, and I finally got the chance to do so recently.
Kimono is a Y-Combinator backed startup trying to do something in a field where others have failed. Kimono is focused on creating APIs for websites which don’t have one, another term would be web scraping. Imagine you have a website which shows some data you would like to dynamically process in your website or application. If the website doesn’t have an API, you can create one using Kimono by extracting the data items from the website.
Is it Legal?
Kimono provides an FAQ section, which says that web scraping from public websites “is 100% legal” as long as you check the robots.txt file to see which URL patterns they have disallowed. However, I would advise you to proceed with caution because some websites can pose a problem.
A robots.txt is a file that gives directions to crawlers (usually of search engines) visiting the website. If a webmaster wants a page to be available on search engines like Google, he would not disallow robots in the robots.txt file. If they’d prefer no one scrapes their content, they’d specifically mention it in their Terms of Service. You should always look at the terms before creating an API through Kimono.
An example of this is Medium. Their robots.txt file doesn’t mention anything about their public posts, but the following quote from their TOS page shows you shouldn’t scrape them (since it involves extracting data from their HTML/CSS).
For the remainder of the site, you may not duplicate, copy, or reuse any portion of the HTML/CSS, JavaScipt, logos, or visual design elements without express written permission from Medium unless otherwise permitted by law.
If you check the #BuiltWithKimono section of their website, you’d notice a few straightforward applications. For instance, there is a price comparison API, which is built by extracting the prices from product pages on different websites.
Let us move on and see how we can use this service.
What are we about to do?
Let’s try to accomplish a task, while exploring Kimono. The Blog Bowl is a blog directory where you can share and discover blogs. The posts that have been shared by users are available on the feeds page. Let us try to get a list of blog posts from the page.
The simple thought process when scraping the data is parsing the HTML (or searching through it, in simpler terms) and extracting the information we require. In this case, let’s try to get the title of the post, its link, and the blogger’s name and profile page.
Getting Started
The first step is, of course, to register. Once you’ve signed up, choose either of two options to run Kimono: through a Chrome extension or a bookmarklet.
Stage items to be scraped
We’ll start by using the bookmarklet, where we start with our base URL (http://theblogbowl.in/feeds/). The next step is to select items we would like to store. In our case, we just store the titles of posts and the names of bloggers. The respective links (or any other HTML attributes) associated with these texts are automatically picked up by Kimono. Once you have selected the data you want, you can check the advanced view or the sample data output by changing the views.
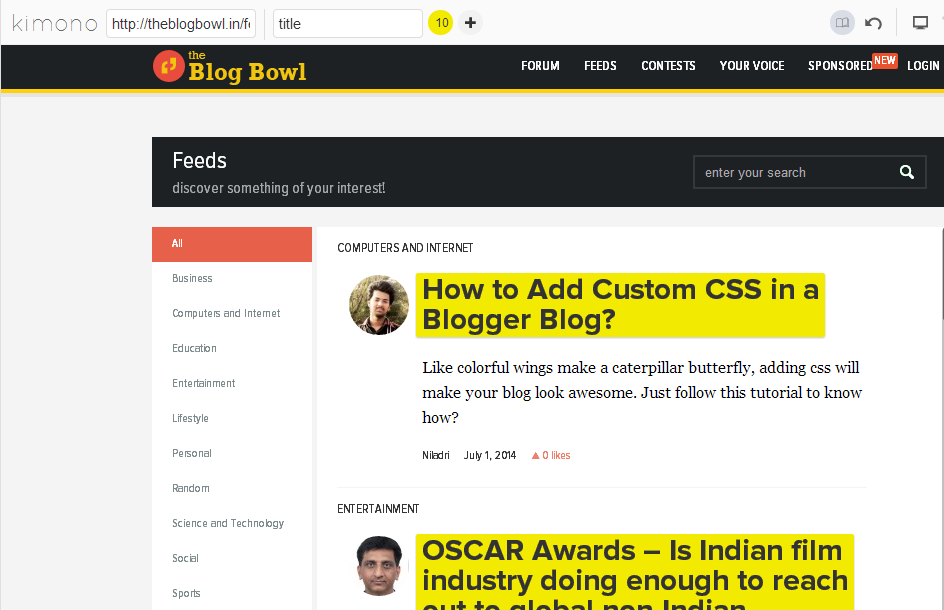
This is where you’ll start to notice some hiccups in the process. It’s not very intuitive at making selections, but you should be able to figure out the correct process eventually. Once you click on an item, all other similar items on the page are highlighted, and you need to point out whether the selections were correct, by selecting one of the pair of small icons (a tick and a cross) that appear next to the selections. If you need to add more items to your list, click the on the “+” icon at the top and repeat the process.
Kimono gives you the ability to create collections, and group similar data items into one. Although it doesn’t make a difference from the point of view of the scraper, it helps in simplifying the data conceptually, which might help others understand what you did.
Pagination
For any web scraper, managing pagination is a very important issue. As a developer, you’ll either check the URL pattern of the pages (http://theblogbowl.in/feeds/?p=[page_no] in our case) and iterate through the pages, or you save the pagination links and open them one by one. Naturally, the former way is better. Kimono allows pagination and you need to click the icon on the top right to activate the feature.
Click on the button or link that takes you to the next page. In this page, the “>” link does this work, so we select the item after activating the pagination feature.
Click the tick icon as shown in the screenshot below once you are done selecting the next page link.
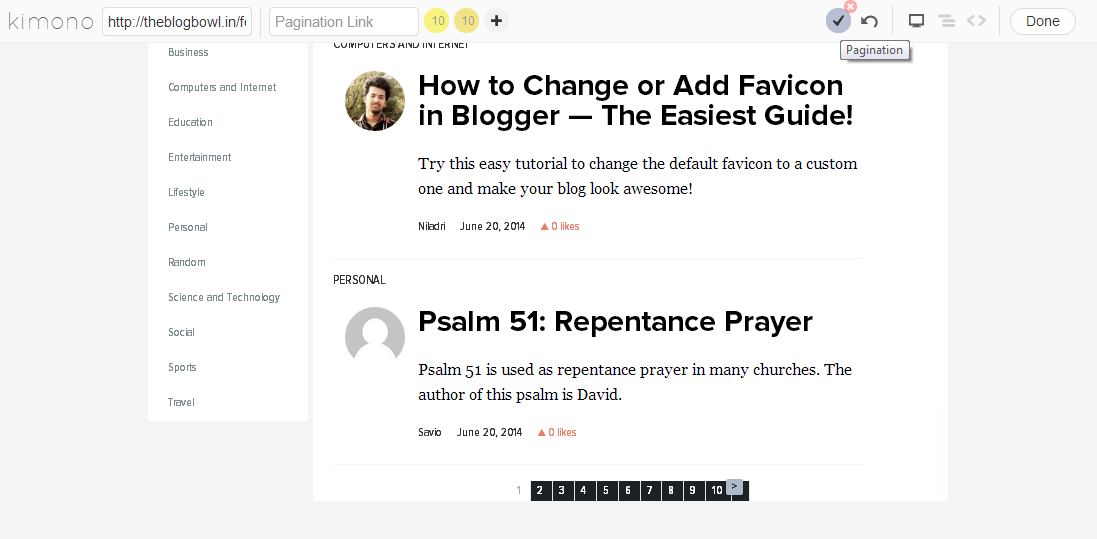
When you are all done, click the “Done” button to proceed.
Although it looked like Kimono understood what to look for, I’ll explain a loophole in their pagination feature later in the post.
Running the scraper
Once we save the scraper, we can either set it to run at regular intervals, or run it on demand. In our case, we chose the latter. Although there were 92 pages, I set the limit to 500 to see how it goes.
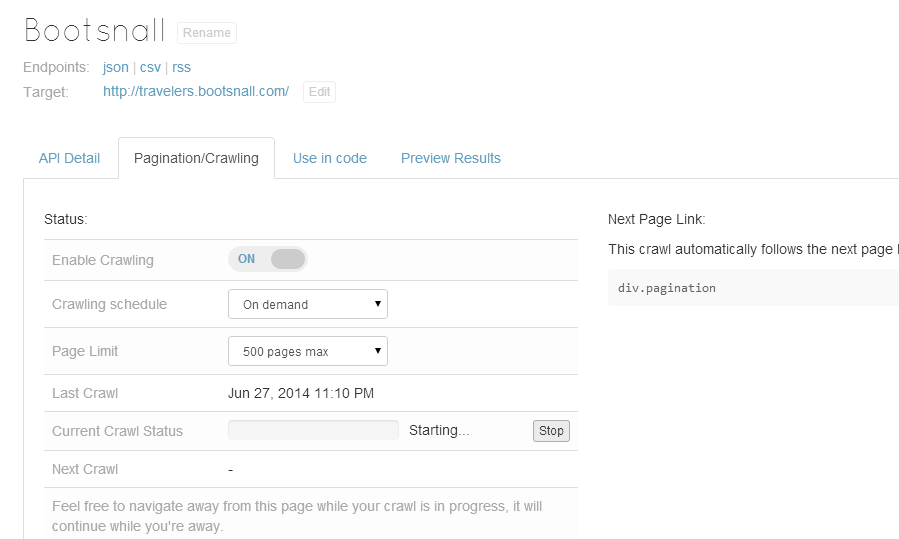
Results
Once the scraping task is complete, let us look at the results.
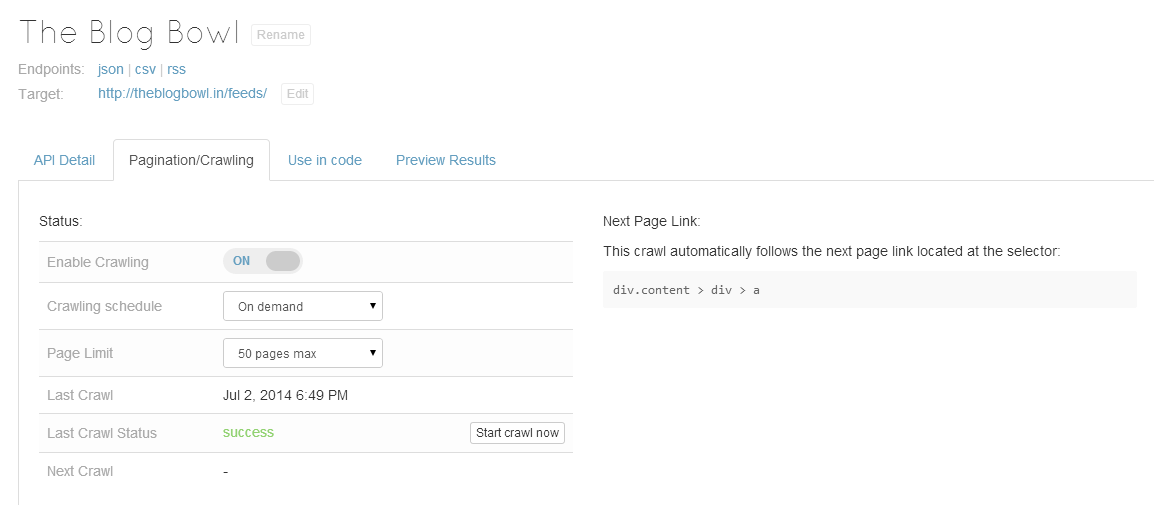
Although I put a limit of 50 pages, I stopped it at approximately 18 pages to see the results. Here they are.
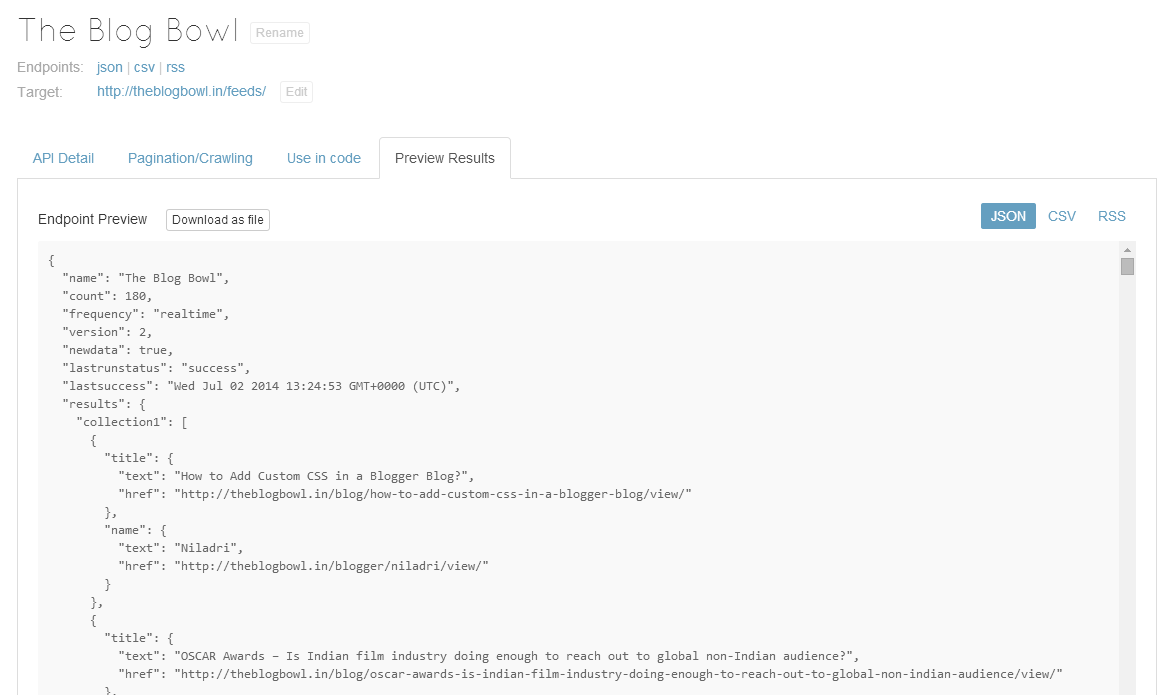
We were successfully able to extract the data that we required. But is it a perfect service?
When can it go wrong?
In our task, we conveniently selected the next button for the pagination. The official documentation mentions that we must feed the Next link to the API for Kimono to understand the pagination.
This means that Kimono’s pagination works only in presence of a “next” button. This means that websites which do not have a “next” button can’t be scraped by Kimono.
For instance, this website contains a lot of information and the list of pages is displayed below. However, a “Next” or “Previous” button is absent.
What’s the future for Kimono?
Kimono is great to build APIs for single page applications. If you require it to scrape multiple pages, with different structures, Kimono might not be able to accomplish it.
If you need to scrape complex web pages with a lot of logic in between, Kimono is not advanced enough to accomplish your needs. Kimono is constantly evolving (after all, it’s backed by YC!) and there might be a day when “you don’t have to write a web scraper again.”
Until then, you just have to depend on your regex skills and an HTML parser if you want to undertake these complex tasks!
Have you had any experience with Kimono? What do you think of the service?
Frequently Asked Questions (FAQs) about Kimono Web Scraper
What is Kimono Web Scraper and how does it work?
Kimono Web Scraper is a tool that allows users to extract data from websites without needing to write any code. It works by allowing users to select the data they want from a website, and then it automatically creates an API that can be used to access that data. This makes it a powerful tool for anyone who needs to gather data from the web, whether for research, business, or personal use.
How can I use Kimono Web Scraper to extract data from a website?
To use Kimono Web Scraper, you first need to install it on your browser. Once installed, navigate to the website you want to extract data from and click on the Kimono icon in your browser. You can then select the data you want to extract by clicking on it. Once you’ve selected all the data you want, click on the ‘Done’ button and Kimono will create an API for you to access that data.
What are some alternatives to Kimono Web Scraper?
While Kimono Web Scraper is a powerful tool, there are other alternatives available. These include ParseHub, Import.io, and Octoparse. Each of these tools has its own strengths and weaknesses, so it’s important to choose the one that best fits your needs.
Can I use Kimono Web Scraper for commercial purposes?
Yes, you can use Kimono Web Scraper for commercial purposes. However, it’s important to note that you should always respect the terms of service of the websites you’re scraping data from. Some websites may prohibit scraping, so it’s important to check before you start.
How can I access the data I’ve extracted with Kimono Web Scraper?
Once you’ve created an API with Kimono Web Scraper, you can access the data you’ve extracted by making a request to that API. This can be done using a variety of programming languages, including Python, JavaScript, and Ruby.
Can I use Kimono Web Scraper to extract data from dynamic websites?
Yes, Kimono Web Scraper can be used to extract data from dynamic websites. However, it’s important to note that this can be more complex than extracting data from static websites, and may require some additional steps.
What kind of data can I extract with Kimono Web Scraper?
You can use Kimono Web Scraper to extract a wide variety of data, including text, images, and links. However, the exact data you can extract will depend on the structure of the website you’re scraping.
Can I schedule data extraction with Kimono Web Scraper?
Yes, Kimono Web Scraper allows you to schedule data extraction. This can be useful if you need to extract data from a website on a regular basis.
Do I need any programming knowledge to use Kimono Web Scraper?
No, you don’t need any programming knowledge to use Kimono Web Scraper. However, having some basic understanding of how websites are structured can be helpful.
Is Kimono Web Scraper free to use?
Yes, Kimono Web Scraper is free to use. However, there may be some limitations on the amount of data you can extract with the free version.