

Voice commands are not only for assistants like Google or Alexa. They can also be added to your mobile and desktop apps, offering both extra functionality and even fun for your end users. And adding voice commands or voice search to your apps can be very easy. In this article, we’ll use the Web Speech API to build a voice controlled book search application.
The complete code for what we’ll build is available on GitHub. And for the impatient, there’s a working demo of what we’ll build at the end of the article.
Key Takeaways
- Utilize the Web Speech API to add voice search capabilities to React applications, enhancing user interaction by allowing voice commands.
- Begin by creating a basic React component using Create React App, then integrate the Web Speech API to enable speech recognition and handling.
- Implement continuous speech recognition within the React component lifecycle by adjusting the API’s settings and managing states with React hooks.
- Develop a custom React hook, `useVoice`, to abstract and reuse the voice recognition functionality across different components or applications.
- Expand the application’s functionality by integrating a book search feature using another custom hook, `useBookFetch`, which interacts with an external API to fetch data based on voice inputs.
Introduction to the Web Speech API
Before we get started, it’s important to note that the Web Speech API currently has limited browser support. To follow along with this article, you’ll need to use a supported browser.
Data on support for the mdn-api__SpeechRecognition feature across the major browsers
First, let’s see how easy it is to get the Web Speech API up and running. (You might also like to read SitePoint’s introduction to the Web Speech API and check out some other experiments with the Web Speech API.) To start using the Speech API, we just need to instantiate a new SpeechRecognition class to allow us to listen to the user’s voice:
const SpeechRecognition = webkitSpeechRecognition;
const speech = new SpeechRecognition();
speech.onresult = event => {
console.log(event);
};
speech.start();We start by creating a SpeechRecognition constant, which is equal to the global browser vendor prefix webkitSpeechRecognition. After this, we can then create a speech variable that will be the new instance of our SpeechRecognition class. This will allow us to start listening to the user’s speech. To be able to handle the results from a user’s voice, we need to create an event listener that will be triggered when the user stops speaking. Finally, we call the start function on our class instance.
When running this code for the first time, the user will be prompted to allow access to the mic. This a security check that the browser puts in place to prevent unwanted snooping. Once the user has accepted, they can start speaking, and they won’t be asked for permission again on that domain. After the user has stopped speaking, the onresult event handler function will be triggered.
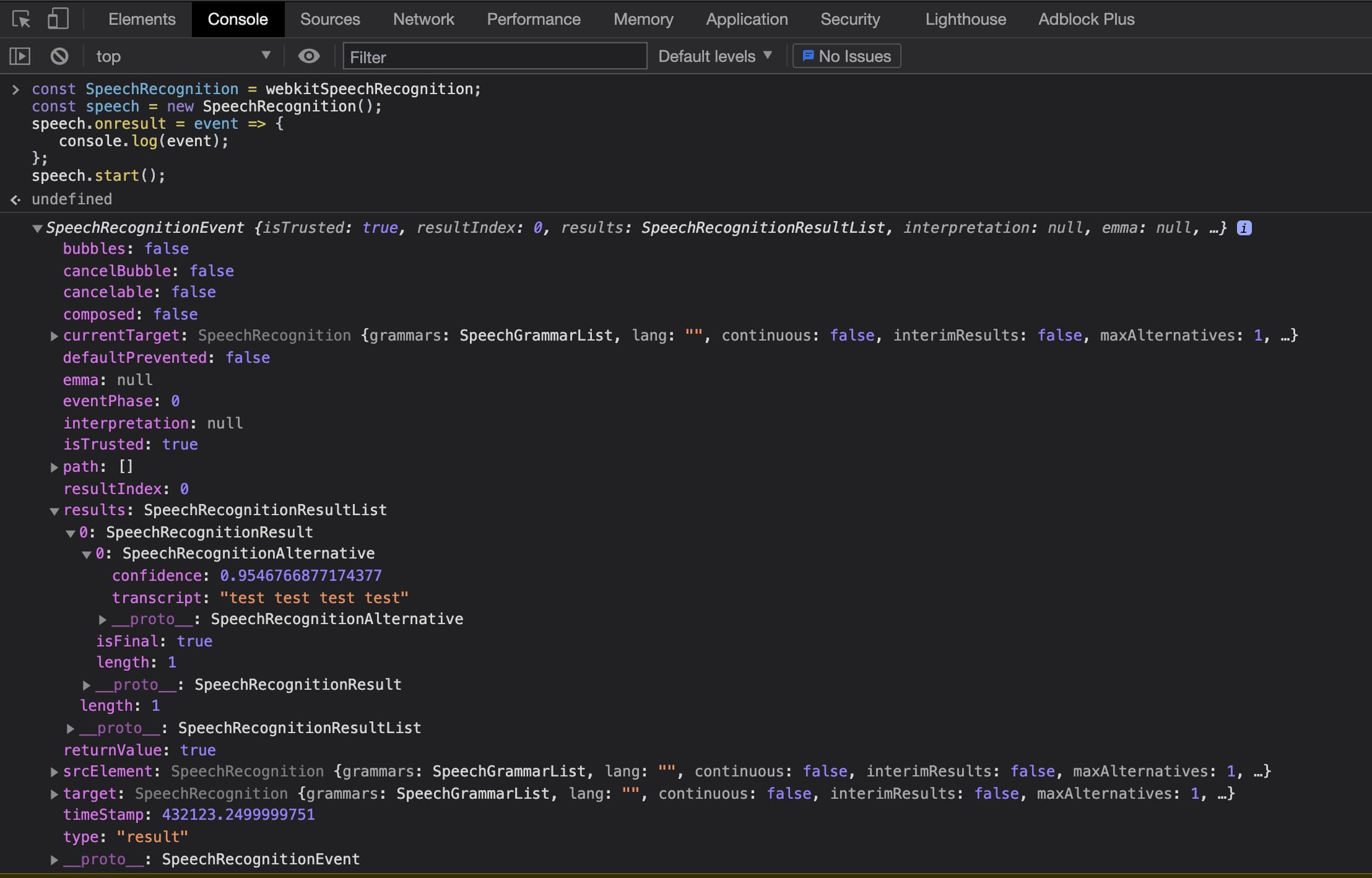
The onresult event is passed a SpeechRecognitionEvent object, which is made up of a SpeechRecognitionResultList results array. The SpeechRecognitionResultList object contains SpeechRecognitionResult objects. The first item in the array returns a SpeechRecognitionResult object, which contains a further array. The first item in this array contains the transcript of what the user had spoken.
The above code can be run from the Chrome DevTools or a normal JavaScript file. Now that we have the basics understood, let’s look at building this into a React application. We can see the results below when running via the Chrome DevTools console.
Using Web Speech in React
Using what we’ve already learned, it’s a simple process to add the Web Speech API to a React application. The only issue we have to deal with is the React component lifecycle. First, let’s create a new project with Create React App, following its getting start guide. This assumes that Node is installed on your machine:
npx create-react-app book-voice-search
cd book-voice-search
npm startNext, we replace the App file with the code below to define a basic React component. Then we can add some speech logic to it:
// App.js
import React from 'react';
const App = () => {
return (
<div>
Example component
</div>
);
};
export default App;This simple component renders a div with some text inside it. Now we can start adding our speech logic to the component. We want to build a component that creates the speech instance, then uses this inside the React lifecycle. When the React component renders for the first time, we want to create the speech instance, start listening to results, and provide the user a way to start the speech recognition. We first need to import some React hooks (you can learn more about the core React hooks here), some CSS styles, and a mic image for our user to click:
{kind=link}
// App.js
import { useState, useEffect } from "react";
import "./index.css";
import Mic from "./microphone-black-shape.svg";After this, we’ll create our speech instance. We can use what we learned earlier when looking at the basics of the Web Speech API. We have to make a few changes to the original code we pasted into the browser developer tools. Firstly, we make the code more robust by adding browser support detection. We can do this by checking if the webkitSpeechRecognition class exists on the window object. This will tell us if the browser knows of the API we want to use.
Then we change the continuous setting to true. This configures the speech recognition API to keep listening. In our very first example, this was defaulted to false and meant that when the user stopped speaking, the onresult event handler would trigger. But as we’re allowing the user to control when they want the site to stop listening, we use continuous to allow the user to talk for as long as they want:
// App.js
let speech;
if (window.webkitSpeechRecognition) {
// eslint-disable-next-line
const SpeechRecognition = webkitSpeechRecognition;
speech = new SpeechRecognition();
speech.continuous = true;
} else {
speech = null;
}
const App = () => { ... };Now that we’ve set up the speech recognition code, we can start to use this inside the React component. As we saw before, we imported two React hooks — the useState and useEffect hooks. These will allow us to add the onresult event listener and store the user transcript to state so we can display it on the UI:
// App.js
const App = () => {
const [isListening, setIsListening] = useState(false);
const
= useState("");
const listen = () => {
setIsListening(!isListening);
if (isListening) {
speech.stop();
} else {
speech.start();
}
};
useEffect(() => {
//handle if the browser does not support the Speech API
if (!speech) {
return;
}
speech.onresult = event => {
setText(event.results[event.results.length - 1][0].transcript);
};
}, []);
return (
<>
<div className="app">
<h2>Book Voice Search</h2>
<h3>Click the Mic and say an author's name</h3>
<div>
<img
className={`microphone ${isListening && "isListening"}`}
src={Mic}
alt="microphone"
onClick={listen}
/>
</div>
<p>{text}</p>
</div>
</>
);
}
export default App;In our component, we firstly declare two state variables — one to hold the transcript text from the user’s speech, and one to determine if our application is listening to the user. We call the React useState hook, passing the default value of false for isListening and an empty string for text. These values will be updated later in the component based on the user’s interactions.
After we set up our state, we create a function that will be triggered when the user clicks the mic image. This checks if the application is currently listening. If it is, we stop the speech recognition; otherwise, we start it. This function is later added to the onclick for the mic image.
We then need to add our event listener to capture results from the user. We only need to create this event listener once, and we only need it when the UI has rendered. So we can use a useEffect hook to capture when the component has mounted and create our onresult event. We also pass an empty array to the useEffect function so that it will only run once.
Finally, we can render out the UI elements needed to allow the user to start talking and see the text results.
Custom reusable React voice hook
We now have a working React application that can listen to a user’s voice and display that text on the screen. However, we can take this a step further by creating our own custom React hook that we can reuse across applications to listen to users’ voice inputs.
First, let’s create a new JavaScript file called useVoice.js. For any custom React hook, it’s best to follow the file name pattern useHookName.js. This makes them stand out when looking at the project files. Then we can start by importing all the needed built-in React hooks that we used before in our example component:
// useVoice.js
import { useState, useEffect } from 'react';
let speech;
if (window.webkitSpeechRecognition) {
// eslint-disable-next-line
const SpeechRecognition = SpeechRecognition || webkitSpeechRecognition;
speech = new SpeechRecognition();
speech.continuous = true;
} else {
speech = null;
}This is the same code that we used in our React component earlier. After this, we declare a new function called useVoice. We match the name of the file, which is also common practice in custom React hooks:
// useVoice.js
const useVoice = () => {
const
= useState('');
const [isListening, setIsListening] = useState(false);
const listen = () => {
setIsListening(!isListening);
if (isListening) {
speech.stop();
} else {
speech.start();
}
};
useEffect(() => {
if (!speech) {
return;
}
speech.onresult = event => {
setText(event.results[event.results.length - 1][0].transcript);
setIsListening(false);
speech.stop();
};
}, [])
return {
text,
isListening,
listen,
voiceSupported: speech !== null
};
}
export {
useVoice,
};Inside the useVoice function, we’re doing multiple tasks. Similar to our component example, we create two items of state — the isListening flag, and the text state. We then create the listen function again with the same logic from before, using an effect hook to set up the onresult event listener.
Finally, we return an object from the function. This object allows our custom hook to provide any component using the user’s voice as text. We also return a variable that can tell the consuming component if the browser supports the Web Speech API, which we’ll use later in out application. At the end of the file, we export the function so it can be used.
Let’s now move back to our App.js file and start using our custom hook. We can start by removing the following:
SpeechRecognitionclass instances- import for
useState - the state variables for
isListeningandtext - the
listenfunction - the
useEffectfor adding theonresultevent listener
Then we can import our custom useVoice React hook:
// App.js
import { useVoice } from './useVoice';We start using it like we would a built-in React hook. We call the useVoice function and deconstruct the resulting object:
// App.js
const {
text,
isListening,
listen,
voiceSupported,
} = useVoice();After importing this custom hook, we don’t need to make any changes to the component as we reused all the state variable names and function calls. The resulting App.js should look like below:
// App.js
import React from 'react';
import { useVoice } from './useVoice';
import Mic from './microphone-black-shape.svg';
const App = () => {
const {
text,
isListening,
listen,
voiceSupported,
} = useVoice();
if (!voiceSupported) {
return (
<div className="app">
<h1>
Voice recognition is not supported by your browser, please retry with a supported browser e.g. Chrome
</h1>
</div>
);
}
return (
<>
<div className="app">
<h2>Book Voice Search</h2>
<h3>Click the Mic and say an author's name</h3>
<div>
<img
className={`microphone ${isListening && "isListening"}`}
src={Mic}
alt="microphone"
onClick={listen}
/>
</div>
<p>{text}</p>
</div>
</>
);
}
export default App;We have now built our application in a way that allows us to share the Web Speech API logic across components or applications. We’re also able to detect if the browser supports the Web Speech API and return a message instead of a broken application.
This also removes logic from our component, keeping it clean and more maintainable. But let’s not stop here. Let’s add more functionality to our application, as we’re currently just listening to the user’s voice and displaying it.
Book Voice Search
Using what we’ve learned and built so far, let’s build a book search application that allows the user to say their favorite author’s name and get a list of books.
To start, we need to create a second custom hook that will allow us to search a library API. Let’s start by creating a new file called useBookFetch.js. In this file, we’ll follow the same pattern from the useVoice hook. We’ll import our React hooks for state and effect. Then we can start to build our custom hook:
// useBookFetch.js
import { useEffect, useState } from 'react';
const useBookFetch = () => {
const [authorBooks, setAuthorBooks] = useState([]);
const [isFetchingBooks, setIsFetchingBooks] = useState(false);
const fetchBooksByAuthor = author => {
setIsFetchingBooks(true);
fetch(`https://openlibrary.org/search.json?author=${author}`)
.then(res => res.json())
.then(res => {
setAuthorBooks(res.docs.map(book => {
return {
title: book.title
}
}))
setIsFetchingBooks(false);
});
}
return {
authorBooks,
fetchBooksByAuthor,
isFetchingBooks,
};
};
export {
useBookFetch,
}Let’s break down what we’re doing in this new custom hook. We first create two state items. authorBooks is defaulted to an empty array and will eventually hold the list of books for the chosen author. isFetchingBooks is a flag that will tell our consuming component if the network call to get the author’s books is in progress.
Then we declare a function that we can call with an author name, and it will make a fetch call to the open library to get all the books for the provided author. (If you’re new to it, check out SitePoint’s introduction to the Fetch API.) In the final then of the fetch, we map through each result and get the title of the book. We then finally return an object with the authorBooks state, the flag to indicate that we’re fetching the books, and the fetchBooksByAuthor function.
Let’s jump back to our App.js file and import the useBookFetch hook in the same way we imported the useVoice hook. We can call this hook and deconstruct out the values and start using them in our component:
// App.js
const {
authorBooks,
isFetchingBooks,
fetchBooksByAuthor
} = useBookFetch();
useEffect(() => {
if (text !== "") {
fetchBooksByAuthor(text);
}
},
);We can make use of the useEffect hook to watch the text variable for changes. This will automatically fetch the author’s books when the user’s voice text changes. If the text is empty, we don’t attempt the fetch action. This prevents an unnecessary fetch when we first render the component. The last change to the App.js component is to add in logic to render out the author books or show a fetching message:
// App.js
{
isFetchingBooks ?
'fetching books....' :
<ul>
{
authorBooks.map((book, index) => {
return (
<li key={index}>
<span>
{book.title}
</span>
</li>
);
})
}
</ul>
}The final App.js file should look like this:
// App.js
import React, { useEffect } from "react";
import "./index.css";
import Mic from "./microphone-black-shape.svg";
import { useVoice } from "./useVoice";
import { useBookFetch } from "./useBookFetch";
const App = () => {
const { text, isListening, listen, voiceSupported } = useVoice();
const { authorBooks, isFetchingBooks, fetchBooksByAuthor } = useBookFetch();
useEffect(() => {
if (text !== "") {
fetchBooksByAuthor(text);
}
},
);
if (!voiceSupported) {
return (
<div className="app">
<h1>
Voice recognition is not supported by your browser, please retry with
a supported browser e.g. Chrome
</h1>
</div>
);
}
return (
<>
<div className="app">
<h2>Book Voice Search</h2>
<h3>Click the Mic and say an autors name</h3>
<div>
<img
className={`microphone ${isListening && "isListening"}`}
src={Mic}
alt="microphone"
onClick={listen}
/>
</div>
<p>{text}</p>
{isFetchingBooks ? (
"fetching books...."
) : (
<ul>
{authorBooks.map((book, index) => {
return (
<li key={index}>
<span>{book.title}</span>
</li>
);
})}
</ul>
)}
</div>
<div className="icon-reg">
Icons made by{" "}
<a
href="https://www.flaticon.com/authors/dave-gandy"
title="Dave Gandy"
>
Dave Gandy
</a>{" "}
from{" "}
<a href="https://www.flaticon.com/" title="Flaticon">
www.flaticon.com
</a>
</div>
</>
);
};
export default App;Demo
Here’s a working demo of what we’ve built. Try searching for your favorite author.
Conclusion
This was just a simple example of how to use the Web Speech API to add additional functionality to an application, but the possibilities are endless. The API has more options that we didn’t cover here, such as providing grammar lists so we can restrict what voice input the user can provide. This API is still experimental, but hopefully will become available in more browsers to allow for easy-to-implement voice interactions. You can find the full running example on CodeSandbox or on GitHub.
If you’ve built an application with voice search and found it cool, let me know on Twitter.
Frequently Asked Questions (FAQs) about Voice Search in React
How can I implement voice search in my React application?
Implementing voice search in a React application involves using the Web Speech API, which allows you to incorporate speech recognition and synthesis into your application. You can use libraries such as react-speech-recognition to simplify the process. This library provides a custom hook that you can use to access the browser’s SpeechRecognition API. You can then use the transcript provided by the hook to implement voice search functionality.
What are the limitations of using voice search in React?
While voice search can greatly enhance the user experience, it does have some limitations. The main one is browser compatibility. The Web Speech API is not supported by all browsers, so you may need to provide a fallback for users who are using unsupported browsers. Additionally, the accuracy of speech recognition can vary depending on the user’s accent and background noise.
Can I customize the behavior of the react-speech-recognition hook?
Yes, the react-speech-recognition hook provides several options for customization. You can set the language, interim results, and continuous mode. You can also handle events such as start, stop, and error.
How can I handle errors when using the react-speech-recognition hook?
The react-speech-recognition hook provides an error state that you can use to handle errors. This state will contain an error message if an error occurs during speech recognition. You can display this message to the user or use it for debugging purposes.
Can I use voice search in a production React application?
Yes, you can use voice search in a production React application. However, you should be aware of the limitations and potential issues, such as browser compatibility and speech recognition accuracy. It’s also important to test the functionality thoroughly before deploying it to production.
How can I improve the accuracy of speech recognition in my React application?
The accuracy of speech recognition can be improved by setting the appropriate language and providing a quiet environment for the user. You can also use machine learning algorithms to train the speech recognition engine to better understand different accents and speech patterns.
Can I use voice search with other React libraries?
Yes, you can use voice search with other React libraries. For example, you can use it with a state management library like Redux to manage the transcript state. You can also use it with a routing library like React Router to navigate based on voice commands.
How can I test the voice search functionality in my React application?
You can test the voice search functionality by simulating speech input and checking the resulting transcript. You can also use end-to-end testing tools like Cypress to automate the testing process.
Can I use voice search in a React Native application?
The Web Speech API is not supported in React Native. However, there are other libraries available that provide speech recognition functionality for React Native, such as react-native-voice.
How can I convert speech to text in my React application?
You can convert speech to text using the react-speech-recognition hook. This hook provides a transcript state that contains the recognized speech as text. You can display this text to the user or use it for other purposes, such as search or command execution.