

Key Takeaways
- Sucker Punch is a single-process asynchronous processing library that allows you to move tasks to the background, keeping the UI responsive. It uses the celluloid framework and requires Ruby 1.9+, JRuby 1.6+ or Rubinius 2.0 to run.
- Creating a worker with Sucker Punch is simple and involves creating a plain Ruby class that includes the SuckerPunch::Worker module, and defining one or more instance methods. You can define as many queues as you want with as many workers as you want, but each queue can have only one worker class.
- Testing the worker is straightforward and can be done as any Ruby class. There are two options for testing: testing that it calls and enqueues the job, or running jobs inline. Be aware that running the job async will not raise any exception if it fails; it will just fail silently.
 Running background jobs in an app is a great way to keep the UI snappy. Being it sending an email, calling some API, or any long running task, there’s always something that can be moved to the background. Sometimes, it makes sense to set up a queue and worker processes, but other times it would be great just to have the method run in background with minimal code changes. Enter Sucker Punch, a single-process asynchronous processing library. Using the wonderful celluloid framework, it lets us do asynchronous work in very few steps.
Running background jobs in an app is a great way to keep the UI snappy. Being it sending an email, calling some API, or any long running task, there’s always something that can be moved to the background. Sometimes, it makes sense to set up a queue and worker processes, but other times it would be great just to have the method run in background with minimal code changes. Enter Sucker Punch, a single-process asynchronous processing library. Using the wonderful celluloid framework, it lets us do asynchronous work in very few steps.
Setup
First of all, your app needs to be running on Ruby 1.9+, JRuby 1.6+ or Rubinius 2.0 (with Ruby 1.9 mode on the last 2). Then, install the gem by running
gem install sucker_punch
or add it to you Gemfile via
gem 'sucker_punch'
And that’s it! Now lets see how to use it.
Creating a Worker
Creating a worker is pretty simple. It’s just a plain ruby class that includes the SuckerPunch::Worker module, and defines one or more instance methods. Sucker Punch suggests just one perform method, but any name and number of methods can be defined and used.
class SomeWorker
include SuckerPunch::Worker
def perform(some_data)
# Method code. Do some work.
end
end
Calling the Worker
Before calling the worker, we need to configure our queues:
SuckerPunch.config do
queue name: :some_queue, worker: SomeWorker, workers: 5
queue name: :welcome_queue, worker: WelcomeEmailWorker, workers: 2
end
We can define as many queues as we want with as many workers as we want (preferable 2+ per queue), but each can have only one worker class per queue.
More workers equals more parallel jobs that can be performed, but be aware of running out of connections if you’re using a connecting to an external service like a database or memcached.
Then you can access the workers on the queues via
SuckerPunch::Queue[:some_queue] # or
SuckerPunch::Queue.new(:some_queue)
This will give us a Celluloid::ActorProxy object wrapping our worker object.
We can call the perform method (or any other method we defined) on that object directly, or use async to return control instantly and make it run in background.
SuckerPunch::Queue[:welcome_queue].perform(1)
SuckerPunch::Queue[:welcome_queue].async.perform(1)
Just be aware that running the job async will not raise any exception if it fails. It will just fail silently.
Testing
Everything needs testing, of course!
Fortunately, testing the worker is pretty easy. You can test it as any Ruby class.
With some rspec flavor:
describe WelcomeEmailWorker
let(:user){ FactoryGirl.create :user }
let(:worker){ EmailWorker.new }
describe "#perform" do
it "delivers an email" do
expect{ worker.perform(user.id) }.to change{ UserMailer.deliveries.size }.by(1)
end
end
end
To test how it integrates with other methods, there are 2 options:
1) Test that it calls and enqueues the job. To do this you need to require 'sucker_punch/testing':
require 'sucker_punch/testing'
describe User do
describe "#send_welcome_email" do
it "delivers an email" do
let(:user){ FactoryGirl.create :user }
expect{
user.send_welcome_email
}.to change{ SuckerPunch::Queue.new(:email).jobs.size }.by(1)
end
end
end
2) Running jobs inline. This can be done by requiring 'sucker_punch/testing/inline', and jobs will always be run synchronously.
require 'sucker_punch/testing'
describe User do
let(:user){ FactoryGirl.create :user }
describe "#send_welcome_email" do
it "delivers an email" do
expect{
user.send_welcome_email
}.to change{ UserMailer.deliveries.size }.by(1)
end
end
end
Considerations
Tests Running Inside DB Transactions
There’s one thing to have in mind with tests. If you’re running each test inside a transaction, you’ll need to change that to a truncation strategy for Sucker Punch tests. Here’s an example of how to do it with DatabaseCleaner: https://gist.github.com/kitop/5248674. This happens because Sucker Punch workers always run the method in a separate thread, no matter if it is synchronous or asynchronous.
Persistence
Keep in mind that Sucker Punch runs your jobs on a separate thread, and not polling from an outside queue. That means that, if your app goes down while processing a job, it will not notify nor store that error anywhere by default, and it won’t retry it either. If you need more control over this, you can write your own wrapper. Maybe you could get some inspiration from girl_friday, or use some other solution like resque, sidekiq, or delayed_job.
Rails
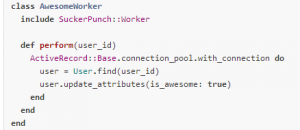
If you’re working with Rails, workers usually go in the app/workers directory. You should be careful with ActiveRecord objects and connections. Workers should receive a record id and not the full object. Preferably, workers should wrap database access related code in a ActiveRecord::Base.connection_pool.with_connection block so it does not exhaust connections in the pool.
class WelcomeEmailWorker
include SuckerPunch::Worker
def perform(user_id)
ActiveRecord::Base.connection_pool.with_connection do
user = User.find(user_id)
UserMailer.welcome(user).deliver
end
end
end
Connections
You have to be careful not just with ActiveRecord connections, but also with any redis, memcache, or any other service that may limit connections. It’s important to also limit the number of workers based on those limits. You don’t want to have 20 workers, when there are 10 connections max!
Unicorn/Passenger
If you’re using Unicorn or Passenger as your web server, there’s one more step to ensure everything is set up well. That is to define the queues on blocks that run after the server. For unicorn (only needed if preload_app true is set):
# config/unicorn.rb
after_fork do |server, worker|
SuckerPunch.config do
queue name: :log_queue, worker: LogWorker, workers: 10
end
end
For Passenger:
# config/initializers/sucker_punch.rb
if defined?(PhusionPassenger)
PhusionPassenger.on_event(:starting_worker_process) do |forked|
SuckerPunch.config do
queue name: :log_queue, worker: LogWorker, workers: 10
end
end
end
Further Reading:
- Concurrency and Database Connections, Heroku Dev Center
- Celluloid’s Frequently Asked Questions
- Celluluid’s Thread safety notes
Frequently Asked Questions (FAQs) about Simple Background Jobs with Sucker Punch
What is Sucker Punch and how does it work in Ruby?
Sucker Punch is a Ruby gem that allows for the creation of asynchronous background jobs in a Ruby application. It works by creating a new thread for each job, allowing them to run concurrently with the main application. This means that long-running tasks can be offloaded to a background job, preventing them from blocking the main application and improving overall performance. Sucker Punch is particularly useful in Rails applications, where it can be used to handle tasks such as sending emails, processing images, or handling API calls.
How do I install and set up Sucker Punch in my Ruby application?
To install Sucker Punch, you need to add the gem to your Gemfile with the line gem 'sucker_punch', and then run bundle install. Once the gem is installed, you can create a new job by creating a new Ruby class and including the SuckerPunch::Job module. The job class should define a perform method, which contains the code that will be run in the background.
How do I enqueue a job with Sucker Punch?
To enqueue a job with Sucker Punch, you simply need to call the perform_async method on your job class, passing in any arguments that the job needs. This will create a new instance of the job and add it to Sucker Punch’s job queue, where it will be run as soon as a thread becomes available.
How can I handle errors in Sucker Punch jobs?
Sucker Punch provides a rescue method that you can override in your job class to handle any exceptions that are raised during the execution of the job. By default, this method will re-raise the exception, causing the job to fail. However, you can override this method to provide custom error handling, such as logging the error or retrying the job.
Can I schedule jobs to run at a specific time with Sucker Punch?
Sucker Punch does not natively support scheduled jobs. However, you can use the after method to delay the execution of a job by a certain amount of time. If you need to schedule jobs to run at specific times, you may want to consider using a more advanced background job library, such as Sidekiq or Delayed Job.
How does Sucker Punch compare to other background job libraries?
Sucker Punch is a lightweight and easy-to-use solution for background jobs in Ruby. It doesn’t require any external dependencies, making it a good choice for small applications or for getting started with background jobs. However, it lacks some of the advanced features of other libraries, such as job persistence, retries, and scheduling.
Can I use Sucker Punch with Rails?
Yes, Sucker Punch is fully compatible with Rails and can be used to handle background tasks in a Rails application. To use Sucker Punch with Rails, you simply need to add the gem to your Gemfile and bundle install, just like any other gem.
How can I test Sucker Punch jobs?
Sucker Punch provides a test_mode that you can enable in your tests to make job execution synchronous. This means that jobs will be run immediately when they are enqueued, allowing you to easily test their behavior. You can enable test mode with the line SuckerPunch::Queue.test_mode = :inline.
What are some common use cases for Sucker Punch?
Sucker Punch is commonly used for tasks that are time-consuming and can be run in the background, such as sending emails, processing images, or making API calls. By offloading these tasks to a background job, you can improve the responsiveness of your application and provide a better user experience.
How can I monitor the performance of Sucker Punch jobs?
Sucker Punch does not provide built-in monitoring tools, but you can use external services such as New Relic or Skylight to monitor the performance of your jobs. These services can provide insights into job execution time, memory usage, and other important metrics.