
Key Takeaways
- Indexing in MongoDB can greatly enhance performance and throughput by reducing the number of full documents that need to be read, thus improving application performance.
- MongoDB supports several types of indexes, including Default _id Index, Secondary Index, Compound Index, Multikey Index, and Multikey Compound Index. Each type serves a specific purpose and is used for different types of queries.
- More than one index can be defined on a collection, but a query can only use one index during its execution. The best index is chosen at runtime by MongoDB’s query-optimizer.
- While indexing can dramatically improve read operations, it also incurs its own costs. Indexing operations occupy space and cause extra overhead on each insert, update, and delete operation on the collection. Therefore, indexing benefits read-heavy collections more than write-heavy collections.
Indexing is one of the more important concepts of working with MongoDB. A proper understanding is critical because indexing can dramatically increase performance and throughput by reducing the number of full documents to be read, thereby increasing the performance of our application. Because indexes can be bit difficult to understand, this two-part series will take a closer look at them.
In this article we’ll explore the following five types of indexes:
- Default _id Index
- Secondary Index
- Compound Index
- Multikey Index
- Multikey Compound Index
There are some other types too to discuss, but I’ve logically kept them for part 2 to provide a clear understanding and avoid any confusion.
Although more than one index can be defined on a collection, a query can only use one index during its execution. The decision of choosing the best index out of the available options is made at runtime by MongoDB’s query-optimizer.
This article assumes that you have a basic understanding of MongoDB concepts (like Collections, Documents, etc.) and performing basic queries using PHP (like find and insert). If not, I suggest you to read our beginner articles: Introduction to MongoDB and MongoDB Revisited.
For the series we’ll assume we have a collection named posts populated with 500 documents having the following structure:
{
"_id": ObjectId("5146bb52d852470060001f4"),
"comments": {
"0": "This is the first comment",
"1": "This is the second comment"
},
"post_likes": 40,
"post_tags": {
"0": "MongoDB",
"1": "Tutorial",
"2": "Indexing"
},
"post_text": "Hello Readers!! This is my post text",
"post_type": "private",
"user_name": "Mark Anthony"
}Now, let’s explore various types of indexing in detail.
Default _id Index
By default, MongoDB creates a default index on the _id field for each collection. Each document has a unique _id field as a primary key, a 12-byte ObjectID. When there are no other any indexes available, this is used by default for all kinds of queries.
To view the indexes for a collection, open the MongoDB shell and do the following:
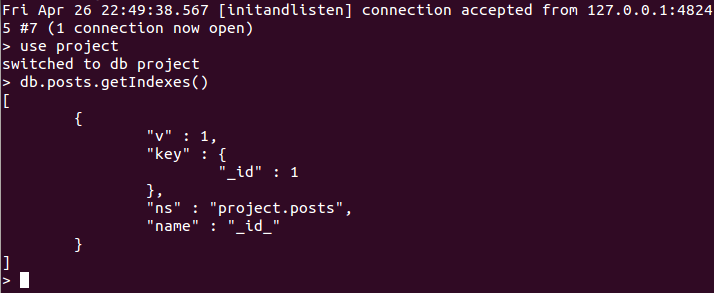
The getIndexes() method returns all of the indexes for our collection. As you can see, we have the default index with name _id_. The key field indicates that the index is on the _id field, and the value of 1 indicates an ascending order. We’ll learn about ordering in next section.
Secondary Index
For cases where we want to use indexing on fields other than _id field, we have to define custom indexes. Suppose we want to search for posts based on the user_name field. In this case, we’ll define a custom index on the user_name field of the collection. Such custom indexes, other than the default index, are called secondary indexes.
To demonstrate the effect of indexing on database, let’s briefly analyze query performance without indexing first. For this, we’ll execute a query to find all posts having a user_name with “Jim Alexandar”.
<?php
// query to find posts with user_name "Jim Alexandar"
$cursor = $collection->find(
array("user_name" => "Jim Alexandar")
);
// use explain() to get explanation of query indexes
var_dump($cursor->explain());An important method often used with indexing is explain() which returns information relevant to indexing. The output of the above explain() is as shown below:
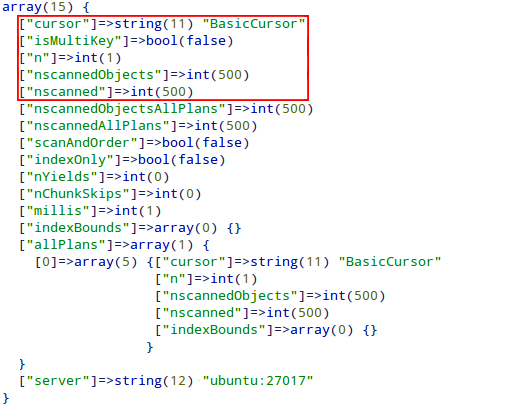
Some of the important keys worth looking at are:
cursor– indicates the index used in the query. BasicCursor indicates that the default _id index was used and MongoDB had to search the entire collection. Going ahead, we’ll see that when we apply indexing, BtreeCursor will be used instead of BasicCursor.n– indicates the number of documents the query returned (one document in this case).nscannedObjects– indicates the number of documents searched by the query (in this case, all 500 documents of the collection were searched). This can be an operation with large overhead if the number of documents in collection is very large.nscanned– indicates the number of documents scanned during the database operation.
Ideally, n should be equal to or near to nscanned, which means a minimum number of documents were searched.
Now, let’s execute the same query but using a secondary index. To create the index, execute the following in the MongoDB shell:

We created an index on the user_name field in the posts collection using the ensureIndex() method. I’m sure you’ve niced the value of the order argument to the method which indicates either an ascending (1) or descending (-1) order for the search. To better understand this, note that each document has a timestamp field. If we want the most recent posts first, we would use descending order. For the oldest posts first, we would choose ascending order.
After creating the index, the same find() and explain() methods are used to execute and analyze the query as before. The output of is:
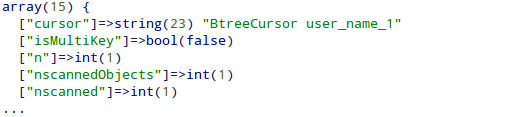
The output shows that the query used a BtreeCursor named user_name_1 (which we defined earlier) and scanned only one document as opposed to the 500 documents searched in the previous query without indexing.
For now, understand that all MongoDB indexes uses a BTree data structure in its algorithm, and BtreeCursor is the default cursor for it. A detailed discussion of BTreeCursor is out of scope for this article, but this doesn’t affect any further understanding.
The above comparison indicates how indexes can dramatically improve the the query performance.
Compound Index
There will be cases when a query uses more than one field. In such cases, we can use compound indexes. Consider the following query which uses both the post_type and post_likes fields:
<?php
// query to find posts with type public and 100 likes
$cursor = $collection->find(
array(
"post_type" => "public",
"post_likes" => 100
),
array()
);Analyzing this query with explain(), gives the following result, which shows that the query uses BasicCursor and all 500 documents are scanned to retrieve one document.

This is highly inefficient, so let’s apply some indexes. We can define a compound index on fields post_type and post_likes as follows:

Analyzing the query now gives the follow result:

A very important point of note here is that compound indexes defined on multiple fields can be used to query a subset of these fields. For example, suppose there is a compound index {field1,field2,field3}. This index can be used to query on:
field1field1, field2field1, field2, field3
So, if we’ve defined the index {field1,field2,field3}, we don’t need to define separate {field1} and {field1,field2} indexes. However, if we need this compound index while querying field2 and field2,field3, we can use hint() if the optimizer doesn’t select the desired index.
The hint() method can be used to force MongoDB to use an index we specify and override the default selection and query optimization process. You can specify the field names used in the index as a argument as shown below:
<?php
// query to find posts with type public and 100 likes
// use hint() to force MongoDB to use the index we created
$cursor = $collection
->find(
array(
"post_type" => "public",
"post_likes" => 100
)
)
->hint(
array(
"post_type" => 1,
"post_likes" => 1
)
);This ensures the query uses the compound index defined on the post_type and post_likes fields.
Multikey Index
When indexing is done on an array field, it is called a multikey index. Consider our post document again; we can apply a multikey index on post_tags. The multikey index would index each element of the array, so in this case separate indexes would be created for the post_tags values: MongoDB, Tutorial, Indexing, and so on.

Indexes on array fields must be used very selectively, though, as they consume a lot of memory because of the indexing of each value.
Multikey Compound Index
We can create a multikey compound index, but with the limitation that at most one field in the index can be an array. So, if we have field1 as a string, and [field2, field3] as an array, we can’t define the index {field2,field3} since both fields are arrays.
In the example below, we create an index on the post_tags and user_name fields:

Indexing Limitations and Considerations
It is important to know that indexing can’t be used in queries which use regular expressions, negation operators (i.e. $ne, $not, etc.), arithmetic operators (i.e. $mod, etc.), JavaScript expressions in the $where clause, and in some other cases.
Indexing operations also come with their own cost. Each index occupies space as well as causes extra overhead on each insert, update, and delete operation on the collection. You need to consider the read:write ratio for each collection; indexing is beneficial to read-heavy collections, but may not be for write-heavy collections.
MongoDB keeps indexes in RAM. Make sure that the total index size does not exceed the RAM limit. If it does, some indexes will be removed from RAM and hence queries will slow down. Also, a collection can have a maximum of 64 indexes.
Summary
That’s all for this part. To summarize, indexes are highly beneficial for an application if a proper indexing approach is chosen. In the next part, we’ll look at using indexes on embedded documents, sub-documents, and ordering. Stay tuned!
Image via Fotolia
Frequently Asked Questions about MongoDB Indexing
What is the importance of MongoDB indexing in database management?
MongoDB indexing is a critical aspect of database management. It significantly improves the performance of database operations by providing a more efficient path to the data. Without indexes, MongoDB must perform a collection scan, i.e., scan every document in a collection, to select those documents that match the query statement. With indexes, MongoDB can limit its search to the relevant parts of the data, thereby reducing the amount of data it needs to scan. This results in faster query response times and lower CPU usage, which is particularly beneficial in large databases.
How does MongoDB indexing work?
MongoDB indexing works by creating a special data structure that holds a small portion of the collection’s data. This data structure includes the value of a specific field or set of fields, ordered by the value of the field as specified in the index. When a query is executed, MongoDB uses these indexes to limit the number of documents it must inspect. Indexes are particularly beneficial when the total size of the documents exceeds the available RAM.
What are the different types of indexes in MongoDB?
MongoDB supports several types of indexes that you can use to improve the performance of your queries. These include Single Field, Compound, Multikey, Text, 2d, and 2dsphere indexes. Each type of index serves a specific purpose and is used for different types of queries. For example, Single Field and Compound indexes are used for queries on single or multiple fields, respectively. Multikey indexes are used for arrays, and Text indexes are used for string content.
How do I create an index in MongoDB?
You can create an index in MongoDB using the createIndex() method. This method creates an index on a specified field if the index does not already exist. The method takes two parameters: the field or fields to index and an options document that allows you to specify additional options.
Can I create multiple indexes in MongoDB?
Yes, you can create multiple indexes in MongoDB. However, it’s important to note that while indexes improve query performance, they also consume system resources, particularly disk space and memory. Therefore, it’s crucial to create indexes judiciously and only on those fields that will be frequently queried.
How do I choose which fields to index in MongoDB?
The choice of which fields to index in MongoDB largely depends on your application’s query patterns. Fields that are frequently queried or used in sort operations are good candidates for indexing. Additionally, fields with a high degree of uniqueness are also good candidates for indexing as they can significantly reduce the number of documents MongoDB needs to scan when executing a query.
How can I check if an index exists in MongoDB?
You can check if an index exists in MongoDB using the getIndexes() method. This method returns a list of all indexes on a collection, including the _id index which is created by default.
Can I delete an index in MongoDB?
Yes, you can delete an index in MongoDB using the dropIndex() method. This method removes the specified index from a collection.
What is index intersection in MongoDB?
Index intersection is a feature in MongoDB that allows the database to use more than one index to fulfill a query. This can be particularly useful when no single index can satisfy a query, but the intersection of two or more indexes can.
What is the impact of indexing on write operations in MongoDB?
While indexing significantly improves the performance of read operations, it can have an impact on write operations. This is because each time a document is inserted or updated, all indexes on the collection must also be updated. Therefore, the more indexes a collection has, the slower the write operations will be. It’s important to find a balance between read performance and write performance when creating indexes.