
Keep up to date on current trends and technologies
Ruby - Getting Started
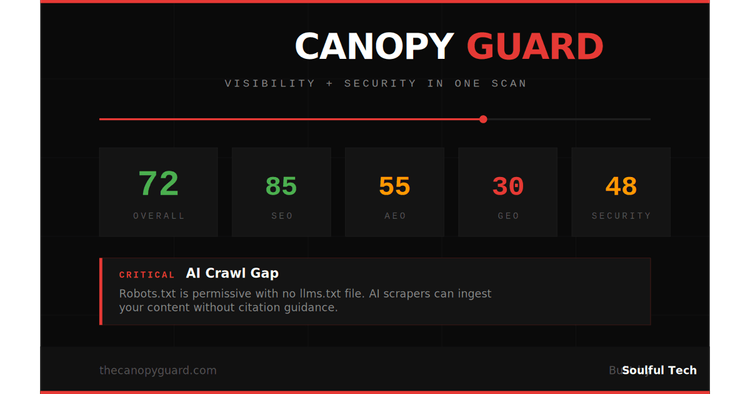
How I Built a 47-Signal Website Audit Tool That Runs in 15 Seconds
Adam McClarin
Exorcise Your Newbie Demons by Contributing to Exercism
Katrina Owen
Learn Concurrency by Implementing Futures in Ruby
Benjamin Tan Wei Hao
Octopress 3 Arrives to Make Blog Generation Crazy Simple
Kingsley Silas
Shelly Cloud: Deploy a Rails App in Less Than 5 Minutes
Jesse Herrick
The Ruby Community: An Introduction
Nihal Sahu
ORM in Ruby: An Introduction
Manu Ajith

Code Kata
João M. D. Moura
8 Simple Steps for Contributing to Open Source
Glenn Goodrich
Network Architecture Based on Gaming
João M. D. Moura
Boosting Your Rails Development Workflow
Ahmed Refaat Tawfik
An Introduction to Sass in Rails
Manjunath M
Deploying Your Rails App to the Cloud with Unicorn, Nginx, and Capistrano
Benjamin Iandavid Rodriguez
Code Safari: Getting Started in HAML
Xavier Shay
Making Ruby Quack—Why We Love Duck Typing
Dan Cheail
Building Your First Rails Application: Views and Controllers
Darcy Laycock
Building Your First Rails Application: Models
Darcy Laycock
Showing 17 of 17