This article was sponsored by VictorOps. Thank you for supporting the sponsors who make SitePoint possible.
What happens when you’re notified that your mission-critical application or website goes down or isn’t working correctly? Sure, most teams have an extensive array of services that tell them when something isn’t right, but what do you do when it comes time to implement a solution? You need a plan, and the ability to implement it quickly. The DevOps approach may appear to be simple, but in actuality it’s a complicated one. Fortunately there are services that make such a process easier.
Enter: VictorOps
One of these services is VictorOps. VictorOps is there to help make DevOps easier, in all aspects of the on-call process. They do this by providing an extensive array of features, each one aimed towards better managing the inner workings of a diverse DevOps team.
The VictorOps platform includes features like on-call management, incident notification, advanced timeline capabilities, team collaboration, and alert annotations / transformations. Each one of these features can be customized and can prove useful for any team, regardless of size or capability. When VictorOps is supporting your team, many of the challenges faced by DevOps engineers begin to fade away ( alert fatigue is real!), allowing your team to return to a productive and helpful state.
Lifecycles with VictorOps
Each incident has a lifecycle of it’s own, from when the alert comes in to holding a post-mortem when it’s over. With that in mind, let’s take a look at how VictorOps helps you work through the incident lifecycle to help you solve the problem faster.
Sending your alerts to VictorOps
Filtering through Alerts
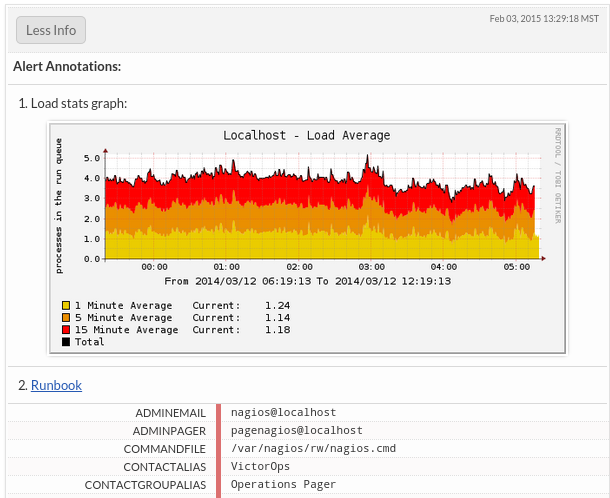
Alerts come through all the time, and while some do contain important information, many can be irrelevant and unhelpful. That being said, the first thing that VictorOps helps you achieve in the incident lifecycle is ensuring the right people are alerted for issues within their problem domain through advanced routing.
Advanced routing allows you to programmatically alert on-call team members to issues that need attention. Once VictorOps comes across an alert you’ve defined as critical, it begins the paging process in exactly the manner you’ve set up, itself open to plenty of customization and user specific settings. Users can be paged regarding incoming alerts via push notifications, SMS, email, and phone, all at specific and predetermined intervals.
The Transmogrifier is a recently launched VictorOps feature that works to greatly increase the value that an average alert can provide. This feature allows alerts to be escalated when certain conditions are met, annotated with documentation and/or developer specific notes, and much more. You can view a detailed overview of the Transmogrifier here.
The Timeline
After filtering through your alerts and notifying the developers on-call, the VictorOps timeline is there to help you see the full scope of the incident as it unfolds. This timeline is accessible from desktop and mobile devices, allowing you to help solve issues in and outside of the office. The timeline is also multi-threaded, which means that you can leverage the timeline to gain situational awareness of other alarms from your systems that may be contributing to the issue, rather than only surfacing limited information relevant to a single alert. Think of the timeline as the main point of focus in the VictorOps platform. The timeline shows all alerts coming off of your system, who’s being paged, and conversation occurring pertaining to problem identification and resolution.
Taking Advantage of the Incident Pane
Members of your DevOps team can see the Incident Pane, which is a distilled view of the critical alarms in their system. From there they can ack or re-route the issue to one or more teams, while also having the ability to filter the Incident Pane by items that are paging them, paging team’s they’re on, or all paging events.
Communication
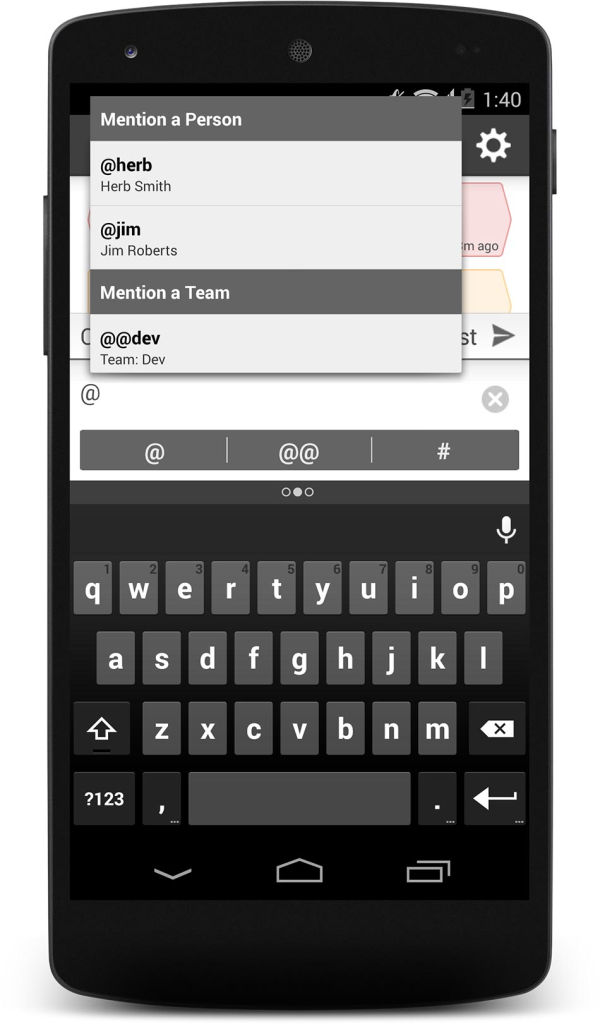
During the entire incident lifecycle, VictorOps provides extensive communication tools to ensure your team can work together. That includes Twitter conventions like @messaging and chat platform integration (although VictorOps has taken this concept further with @@messaging that allows you to ping an entire team in your chat). Speaking of chat, VictorOps offers robust integration with whatever chat client your company uses, including bidirectional integration with Slack and HipChat. Users can even chat into specific incidents to make their notes part of the log of incident resolution.
Post-Mortems and Reporting
Even though an alert may be solved, the incident lifecycle has not ended. It’s always important to collect information on how your team handles alerts, so that improvements can be made when necessary. That’s why VictorOps provides users with the Post-Mortem tool. This tool will allow you to pull a section of the timeline for use in retrospectives and reporting on SLAs for internal and external constituents.
VictorOps supports ‘continuous documentation’ via Incident Frequency and Post-Mortem reports which facilitate discussion around whether all alerts are actionable and if so, whether the Runbooks and Triage documentation were up to date.
[youtube v=9lPenLEbk-8]
Diving through a Hypothetical Alert
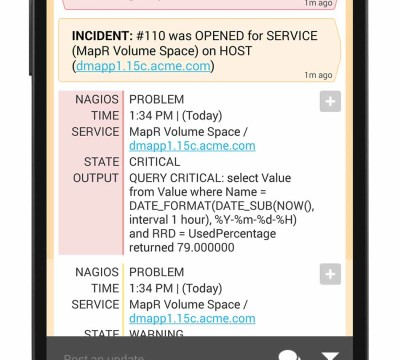
So let’s say you’re all set up on the VictorOps platform and your first alert comes through. What happens? Well, before the alert even gets to you, the Transmogrifier has been hard at work ensuring that the right alerts get to the right people, and that all of the information you need to solve the problem comes with it. You might even be able to stop there, simply because the Transmogrifier handles so much for you, and once difficult problems get solved in minutes. But let’s pretend that this alert is notifying you of a particularly challenging error. Using the custom filters that the Transmogrifier provides, a few other members are notified of the issue, ensuring that all of the correct people are on your team are in on the firefight. So what’s next?
The next and most helpful thing to do would be to visit the VictorOps Timeline. Here is where you can get a birds-eye view of the incident as it unfolds. Since this particular issue is a big one, you’ll probably be getting a few other alerts and warnings related to it. Not to worry though, because the incident pane will allow you to see this coming from a mile away, and instead of getting confused and potentially wasting resources, you can disregard these new alerts, knowing they’ll disappear once the larger issue is resolved.
It’s a good thing your lead developers have access to the incident pane, because some of your team members are realizing that they’ll need assistance from a few other developers. After hearing this they’re quickly able to page more team members, bringing more support into the firefight. But how are you all staying in touch with one another? VictorOps chat integration of course! In the past, a lot of these issues would be solved over email, leading to confusion and poor response time. But now, you have the power of VictorOps at your fingertips, and with it comes a host of great communication tools, ensuring that all of your team members are on the same page.
Eventually (quickly, hopefully!) the alert is finally solved, leading to minimal downtime and an overall positive experience for your team members. But we can’t stop just yet! At tomorrow’s morning scrum, you’ll want to go over the issue with your team, detailing what went wrong, how it was fixed, and what can be done better next time in order to prevent the issue. That’s where VictorOps’ Post-Mortem tool comes in. With the Post-Mortem tool, you’ve been able to pull the most relevant section of the Alert Timeline to show the most critical issues of the entire alert lifecycle. Using this information, you’re able to help your team form a plan to ensure that the issue you’ve solved today, doesn’t become an issue you’ll have to solve again tomorrow.
Conclusion
Using VictorOps allows for better communication, planning, and post-mortems before, during and after every incident. In the example I gave, a DevOps team with a basic plan and the tools to put it into effect managed to solve an issue in a much more organized, streamlined way than traditional approaches. The VictorOps platform not only enables faster response time, but also faster resolve time as well. Most importantly, VictorOps is there for your on-call team, providing a host of features to ensure their productivity, while limiting alert fatigue. If you’re interested in how VictorOps will work for your team, click here to try it out, free, for 14 days!
To see how VictorOps can help you through the entire incident lifecycle, check out their guide that breaks each phase down individually.
 Tim Evko
Tim EvkoTim Evko is a front end web developer from New York, with a passion for responsive web development, Sass, and JavaScript. He lives on coffee, CodePen demos and flannel shirts.