This article was sponsored by VictorOps. Thank you for supporting the sponsors who make SitePoint possible.
It sounds like something you might remember from the Calvin & Hobbes comic strip. But instead of helping with mind reading and shape-shifting, the VictorOps Transmogrifier tool is designed to help engineers resolve application alerts and minimize downtime.
By bringing automation to key stages of an alert lifecycle, the Transmogrifier is unrivaled in both range of use and user satisfaction. Engineers no longer have to sift through irrelevant alerts, while hunting for documentation related to the ones that are of actual importance. That’s because the Transmogrifier can handle those tasks on its own, leaving the important part, resolving the issue, to the engineer on-call.
Why you need a Transmogrifier
If you’ve managed to successfully integrate an alert monitoring system into your workflow, you may have started to notice two things. The first being that, at the slightest hint of an error (valid or not), an alert is sent. This can add up to a lot of alerts in a short time period, especially when you begin to consider all of the different pieces of an application that might require monitoring.
The second issue you may notice is that, as a result of these alerts, your devops team may begin to start feeling a little overwhelmed. It’s called alert fatigue, and it’s an issue that plagues on-call teams whose responsibility it is to respond to all of these alerts getting sent to them.
These two issues can lead to an environment of constant business and disorganization, as teams struggle to filter through alerts and gather the relevant information needed to actually solve them.
Using the VictorOps Transmogrifier is like adding another member to your devops team. It removes the problem of alert fatigue by adding a number of key features to your alert notification process. With the Transmogrifier you can filter through irrelevant alerts, delivering only the important ones to your team.
To cut down on development time, you can make sure relevant documentation is attached to to every alert, so that your developers don’t have to hunt down a solution to a commonly occurring problem. You can even change the status of alerts on the fly, so that specific alert patterns go on to notify the right members of your team.
The Transmogrifier helps to transform your current alert monitoring strategy so you’re not left in the dark to fight every random alert that comes your way.
So how does it work?
VictorOps Transmogrifier from VictorOps on Vimeo.
By way of a simple drag-and-drop interface, the Transmogrifier gives you a number of features that you can add onto your alerts, transforming them into miniature programs that can do a lot of important work for you and your team. Let’s go over those features and explain how you can customize them to help your team.
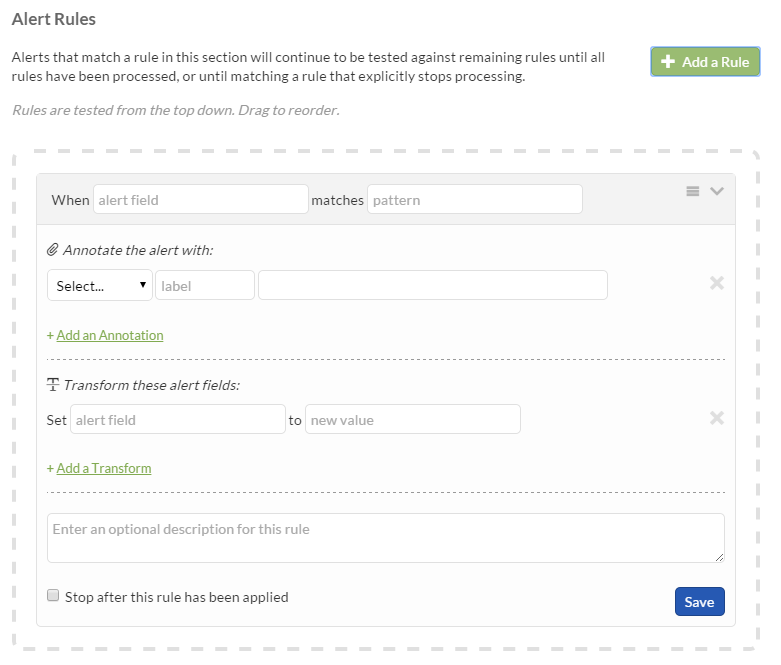
Alert Rules
Setting up an alert rule using the Transmogrifier resembles an IFTT (If This, Then That) pattern. Designating a match between an alert field and specified value will enable the user to attach specific notes, links, and documentation to the alert.
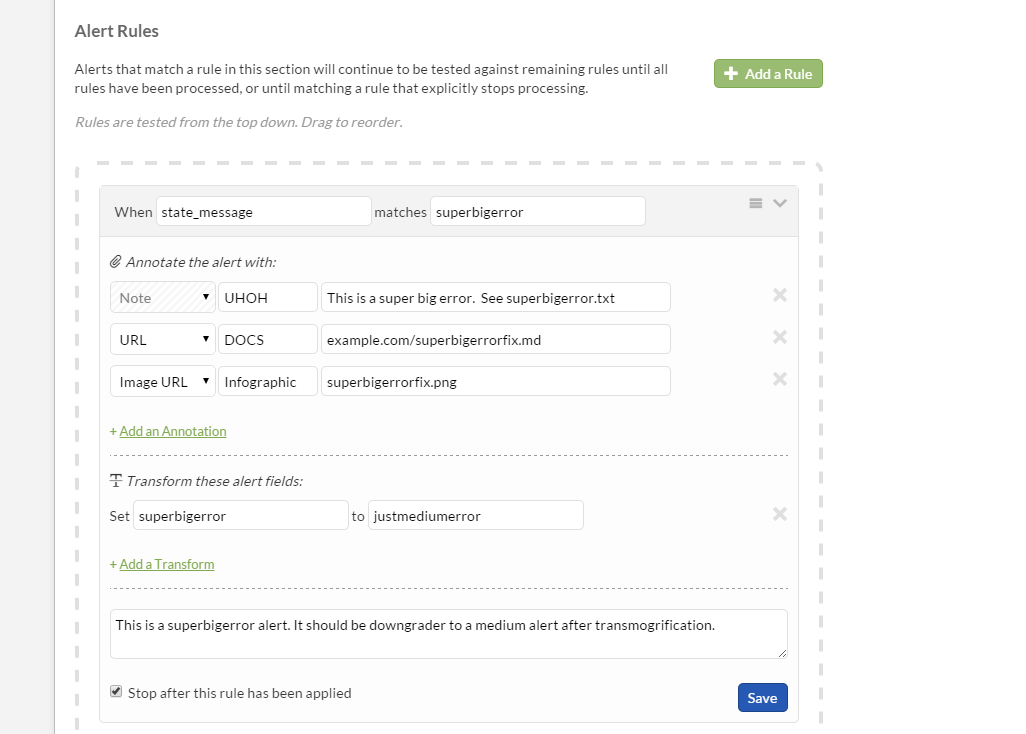
You can set as many alert rules as you’d like, with each rule being tested on every alert that comes through the pipeline. If you’d like the Transmogrification to stop after a specific rule is matched, you can specify that with the cunningly-named “Stop after this rule has been applied” option.
These rules can be very flexible, especially when wildcard characters are used in the alert value field.
When host\_name matches db\*.victorops.com
Note the use of the ‘’ in the value field. You can use the ‘’ and ‘?’ characters for simple wildcards, representing any string of characters or any single character, respectively.
Custom Annotations
Another useful feature provided by the Transmogrifier is the ability to add custom annotations to your alerts. Using these annotations, you can add things like data visualizations, graphs and charts, as well as extra documentation to your alert. This feature is partly aided by the ability to use variables inside of your alert rules, shown in the following image.

Automation
You can even configure alerts to run certain processes for you via annotations, by writing commands directly into note fields.
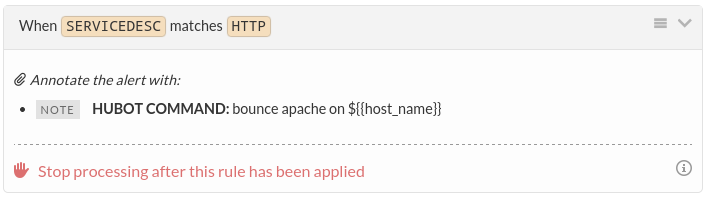
There are plenty of interesting things you can do with the features provided by the Transmogrifier, so be sure to check out their documentation once you’re ready to dive in!
Using the Transmogrifier
Now that we know all about the Transmogrifier and what it can do, let’s use it to set up some alert filters!
After navigating to settings > Transmogrifier, we’re presented with a dashboard where we can start setting up filters for every alert that comes our way.
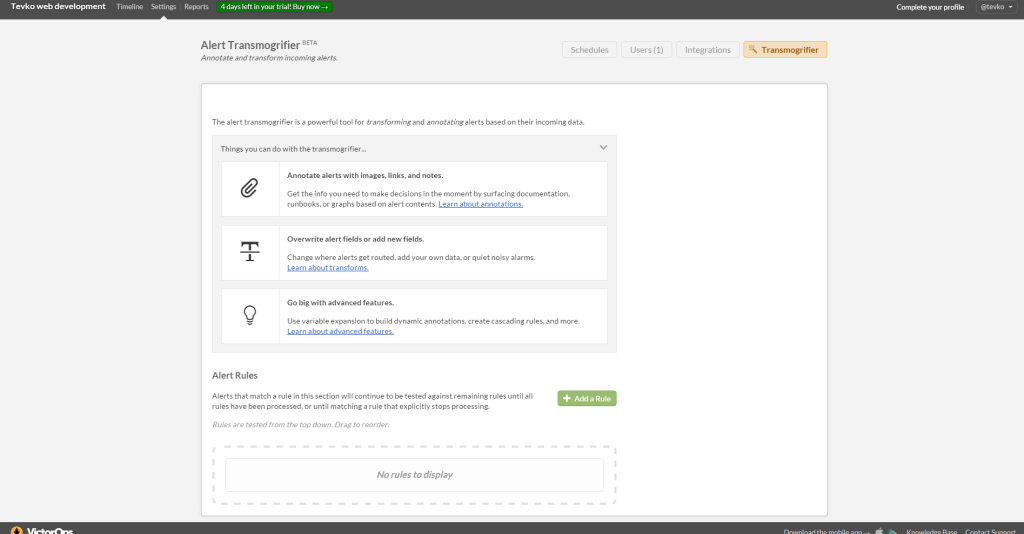
Clicking the “Add a Rule” button presents us with a fresh new menu to start plugging in our options.
My goal is to modify alerts that are notifying me when any of my Github pages sites are having trouble related to performance monitoring, so I’m going to configure my filter to start Transmogrifying as soon as the host_name field matchestevko.github.io/*. This is going to be my top-level filter, meaning that all other filters will be applied after this filter passes.
Next, I’m going to annotate the alert with a note that clarifies the issue. In the “Annotate the alert with:” field, I’m placing a note that tells me the error is coming from a Github pages url. Here’s where I’ll be using the double curly bracket variable syntax, so I’ll be notified of the exact location that the error is coming from. Pretty cool!
Let’s set up one more rule to ensure that the alert can be handled quickly. I’m going to add another rule that checks where exactly the alert is coming from, and updates the status of the alert if it’s coming from a specific location. In order to do that, I’ve configured the filter to check for a monitoring_tool that matches pingdom. If that checks out, then I’m going to annotate the alert with the url for pingdom’s performance monitoring tool. I’ll then transform the alert’s status to urgent, and add a note that the alert requires immediate attention.
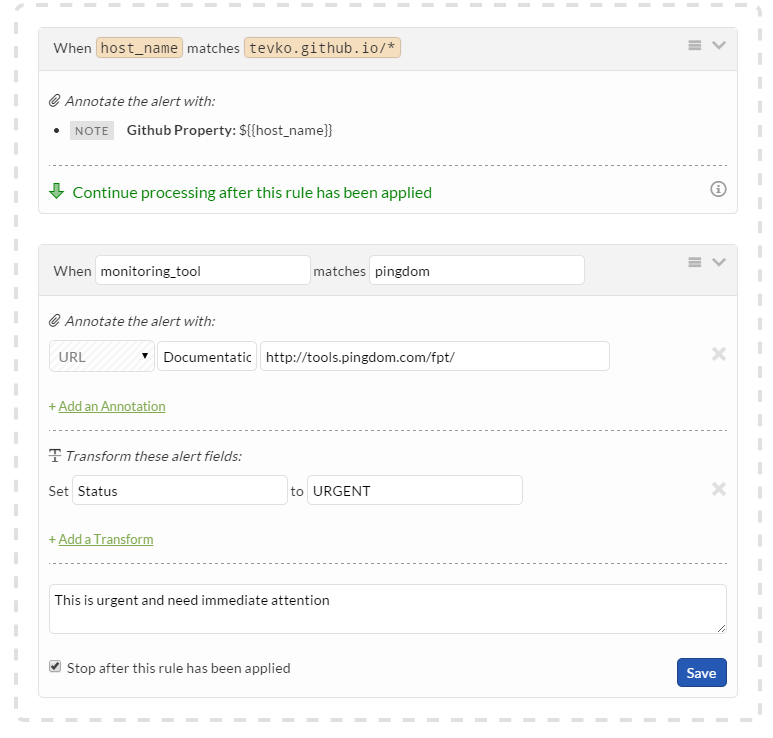
Now we have a well-defined set of rules that filters through all of my alerts and informs me if one of them is a performance-related alert coming from a Github pages URL. It’s pretty incredible how specific we can get with only two rules!
Overall thoughts
After having a chance to preview the Transmogrifier and set up a few alerts of my own, I’m very impressed with how VictorOps has once again improved the on-call process. Alert fatigue is the most dreaded part of being on-call, and having the ability to sort through and clarify alerts makes the process run much more efficiently. Instead of having to filter through irrelevant and unimportant error messages, your alerts can come with helpful documentation and data visualizations, and some alerts can even solve or downgrade themselves!
My favorite part of the Transmogrifier is its ability to attach documentation to alerts on the fly. Imagine the next alert you receive including a specific and detailed path to solving the problem at hand. With the Transmogrifier, this feature is only a few clicks away.
While the Transmogrifier is a great solution to alert fatigue and other on-call difficulties, it’s also incredibly easy to use. The Transmogrifier dashboard is simple yet powerful, combining a minimalistic drag-and-drop interface with a feature-rich set of user controls.
Conclusion
No website or application will have 100% uptime. But with the Transmogrifier it’s a lot easier to prevent downtime while solving the issues that lead to it. If your engineers are tired of being on-call, suffering from alert fatigue, or just unhappy with their current monitoring solutions, then VictorOps’ solution with the transmogrifier feature might just be the perfect tool for you.
How do you manage alerts and avoid alert fatigue? Have you given VictorOps a go?
 Tim Evko
Tim EvkoTim Evko is a front end web developer from New York, with a passion for responsive web development, Sass, and JavaScript. He lives on coffee, CodePen demos and flannel shirts.