


Key Takeaways
- Python’s standard library provides enough functionality to fetch data from an HTTP API, but using third-party modules like ‘requests’ can make the process more streamlined and efficient.
- The ‘requests’ module allows a user to make an HTTP request to an API and read the response in a user-friendly manner. It simplifies the process of constructing an HTTP URL, requesting it, and reading the response in JSON format.
- It’s beneficial to avoid making the same request to an HTTP API more than once. Using ‘requests-cache’ with the ‘requests’ module can help save time and bandwidth by recording HTTP calls and saving the results for future use.
- Python can be used to create a simple HTML page to display the images fetched from an API. This can be achieved by constructing an HTML page from a list of images using a list comprehension and joining the results into one string.
In this quick tip, excerpted from Useful Python, Stuart shows you how easy it is to use an HTTP API from Python using a couple of third-party modules.
Most of the time when working with third-party data we’ll be accessing an HTTP API. That is, we’ll be making an HTTP call to a web page designed to be read by machines rather than by people. API data is normally in a machine-readable format—usually either JSON or XML. (If we come across data in another format, we can use the techniques described elsewhere in this book to convert it to JSON, of course!) Let’s look at how to use an HTTP API from Python.
The general principles of using an HTTP API are simple:
- Make an HTTP call to the URLs for the API, possibly including some authentication information (such as an API key) to show that we’re authorized.
- Get back the data.
- Do something useful with it.
Python provides enough functionality in its standard library to do all this without any additional modules, but it will make our life a lot easier if we pick up a couple of third-party modules to smooth over the process. The first is the requests module. This is an HTTP library for Python that makes fetching HTTP data more pleasant than Python’s built-in urllib.request, and it can be installed with python -m pip install requests.
To show how easy it is to use, we’ll use Pixabay’s API (documented here). Pixabay is a stock photo site where the images are all available for reuse, which makes it a very handy destination. What we’ll focus on here is fruit. We’ll use the fruit pictures we gather later on, when manipulating files, but for now we just want to find pictures of fruit, because it’s tasty and good for us.
To start, we’ll take a quick look at what pictures are available from Pixabay. We’ll grab a hundred images, quickly look through them, and choose the ones we want. For this, we’ll need a Pixabay API key, so we need to create an account and then grab the key shown in the API documentation under “Search Images”.
The requests Module
The basic version of making an HTTP request to an API with the requests module involves constructing an HTTP URL, requesting it, and then reading the response. Here, that response is in JSON format. The requests module makes each of these steps easy. The API parameters are a Python dictionary, a get() function makes the call, and if the API returns JSON, requests makes that available as .json on the response. So a simple call will look like this:
import requests
PIXABAY_API_KEY = "11111111-7777777777777777777777777"
base_url = "https://pixabay.com/api/"
base_params = {
"key": PIXABAY_API_KEY,
"q": "fruit",
"image_type": "photo",
"category": "food",
"safesearch": "true"
}
response = requests.get(base_url, params=base_params)
results = response.json()
This will return a Python object, as the API documentation suggests, and we can look at its parts:
>>> print(len(results["hits"]))
20
>>> print(results["hits"][0])
{'id': 2277, 'pageURL': 'https://pixabay.com/photos/berries-fruits-food-blackberries-2277/', 'type': 'photo', 'tags': 'berries, fruits, food', 'previewURL': 'https://cdn.pixabay.com/photo/2010/12/13/10/05/berries-2277_150.jpg', 'previewWidth': 150, 'previewHeight': 99, 'webformatURL': 'https://pixabay.com/get/gc9525ea83e582978168fc0a7d4f83cebb500c652bd3bbe1607f98ffa6b2a15c70b6b116b234182ba7d81d95a39897605_640.jpg', 'webformatWidth': 640, 'webformatHeight': 426, 'largeImageURL': 'https://pixabay.com/get/g26eb27097e94a701c0569f1f77ef3975cf49af8f47e862d3e048ff2ba0e5e1c2e30fadd7a01cf2de605ab8e82f5e68ad_1280.jpg', 'imageWidth': 4752, 'imageHeight': 3168, 'imageSize': 2113812, 'views': 866775, 'downloads': 445664, 'collections': 1688, 'likes': 1795, 'comments': 366, 'user_id': 14, 'user': 'PublicDomainPictures', 'userImageURL': 'https://cdn.pixabay.com/user/2012/03/08/00-13-48-597_250x250.jpg'}
The API returns 20 hits per page, and we’d like a hundred results. To do this, we add a page parameter to our list of params. However, we don’t want to alter our base_params every time, so the way to approach this is to create a loop and then make a copy of the base_params for each request. The built-in copy module does exactly this, so we can call the API five times in a loop:
for page in range(1, 6):
this_params = copy.copy(base_params)
this_params["page"] = page
response = requests.get(base_url, params=params)
This will make five separate requests to the API, one with page=1, the next with page=2, and so on, getting different sets of image results with each call. This is a convenient way to walk through a large set of API results. Most APIs implement pagination, where a single call to the API only returns a limited set of results. We then ask for more pages of results—much like looking through query results from a search engine.
Since we want a hundred results, we could simply decide that this is five calls of 20 results each, but it would be more robust to keep requesting pages until we have the hundred results we need and then stop. This protects the calls in case Pixabay changes the default number of results to 15 or similar. It also lets us handle the situation where there aren’t a hundred images for our search terms. So we have a while loop and increment the page number every time, and then, if we’ve reached 100 images, or if there are no images to retrieve, we break out of the loop:
images = []
page = 1
while len(images) < 100:
this_params = copy.copy(base_params)
this_params["page"] = page
response = requests.get(base_url, params=this_params)
if not response.json()["hits"]: break
for result in response.json()["hits"]:
images.append({
"pageURL": result["pageURL"],
"thumbnail": result["previewURL"],
"tags": result["tags"],
})
page += 1
This way, when we finish, we’ll have 100 images, or we’ll have all the images if there are fewer than 100, stored in the images array. We can then go on to do something useful with them. But before we do that, let’s talk about caching.
Caching HTTP Requests
It’s a good idea to avoid making the same request to an HTTP API more than once. Many APIs have usage limits in order to avoid them being overtaxed by requesters, and a request takes time and effort on their part and on ours. We should try to not make wasteful requests that we’ve done before. Fortunately, there’s a useful way to do this when using Python’s requests module: install requests-cache with python -m pip install requests-cache. This will seamlessly record any HTTP calls we make and save the results. Then, later, if we make the same call again, we’ll get back the locally saved result without going to the API for it at all. This saves both time and bandwidth. To use requests_cache, import it and create a CachedSession, and then instead of requests.get use session.get to fetch URLs, and we’ll get the benefit of caching with no extra effort:
import requests_cache
session = requests_cache.CachedSession('fruit_cache')
...
response = session.get(base_url, params=this_params)
Making Some Output
To see the results of our query, we need to display the images somewhere. A convenient way to do this is to create a simple HTML page that shows each of the images. Pixabay provides a small thumbnail of each image, which it calls previewURL in the API response, so we could put together an HTML page that shows all of these thumbnails and links them to the main Pixabay page—from which we could choose to download the images we want and credit the photographer. So each image in the page might look like this:
<li>
<a href="https://pixabay.com/photos/berries-fruits-food-blackberries-2277/">
<img src="https://cdn.pixabay.com/photo/2010/12/13/10/05/berries-2277_150.jpg" alt="berries, fruits, food">
</a>
</li>
We can construct that from our images list using a list comprehension, and then join together all the results into one big string with "\n".join():
html_image_list = [
f"""<li>
<a href="{image["pageURL"]}">
<img src="{image['thumbnail']}" alt="{image["tags"]}">
</a>
</li>
"""
for image in images
]
html_image_list = "\n".join(html_image_list)
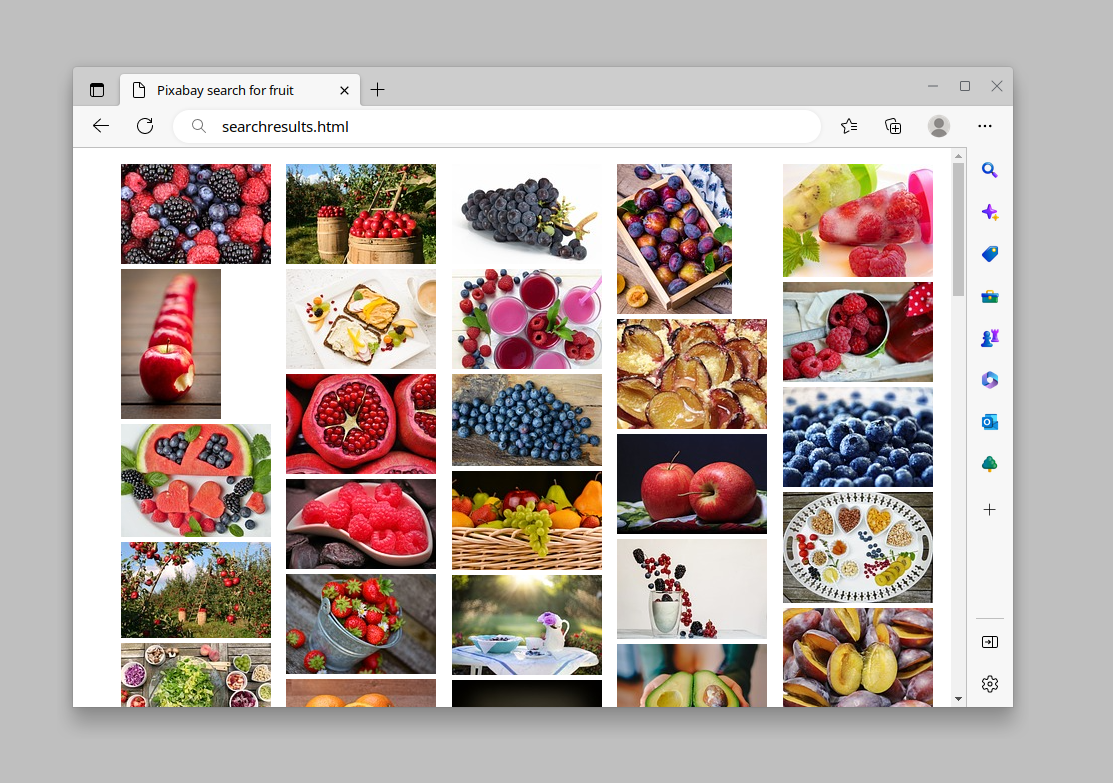
At that point, if we write out a very plain HTML page containing that list, it’s easy to open that in a web browser for a quick overview of all the search results we got from the API, and click any one of them to jump to the full Pixabay page for downloads:
html = f"""<!doctype html>
<html><head><meta charset="utf-8">
<title>Pixabay search for {base_params['q']}</title>
<style>
ul {{
list-style: none;
line-height: 0;
column-count: 5;
column-gap: 5px;
}}
li {{
margin-bottom: 5px;
}}
</style>
</head>
<body>
<ul>
{html_image_list}
</ul>
</body></html>
"""
output_file = f"searchresults-{base_params['q']}.html"
with open(output_file, mode="w", encoding="utf-8") as fp:
fp.write(html)
print(f"Search results summary written as {output_file}")
This article is excerpted from Useful Python, available on SitePoint Premium and from ebook retailers.
Frequently Asked Questions (FAQs) about Fetching Data with HTTP API in Python
What is the difference between HTTP and HTTPS?
HTTP stands for Hypertext Transfer Protocol, while HTTPS stands for Hypertext Transfer Protocol Secure. The main difference between the two is that HTTPS uses an SSL (Secure Sockets Layer) certificate to establish a secure encrypted connection between the server and the client, which is not the case with HTTP. This makes HTTPS safer for transferring sensitive data, such as credit card information or login credentials.
How does HTTP work in Python?
In Python, HTTP requests can be made using several libraries, but the most common one is ‘requests’. This library allows you to send HTTP requests and handle responses, including handling cookies, form data, multipart files, and more. It’s a powerful tool for interacting with web services and can be used in a wide range of applications.
What are the common HTTP methods and how are they used in Python?
The most common HTTP methods are GET, POST, PUT, DELETE, HEAD, OPTIONS, and PATCH. In Python, these methods can be used with the ‘requests’ library. For example, to send a GET request, you would use ‘requests.get(url)’, and to send a POST request, you would use ‘requests.post(url, data)’.
How can I handle HTTP responses in Python?
When you send an HTTP request in Python using the ‘requests’ library, you get a Response object. This object contains the server’s response to your request. You can access the content of the response using ‘response.text’ or ‘response.json()’ if the response is in JSON format. You can also check the status code of the response using ‘response.status_code’.
How can I use HTTP headers in Python?
HTTP headers can be used in Python by passing them as a dictionary to the ‘headers’ parameter of the ‘requests’ function. For example, ‘requests.get(url, headers={‘User-Agent’: ‘my-app’})’. Headers can be used to provide additional information about the request or the client, such as the user-agent, content-type, authorization, and more.
How can I handle cookies in Python?
Cookies can be handled in Python using the ‘cookies’ attribute of the Response object. You can access the cookies sent by the server using ‘response.cookies’, and you can send cookies to the server by passing them as a dictionary to the ‘cookies’ parameter of the ‘requests’ function.
How can I send form data with a POST request in Python?
Form data can be sent with a POST request in Python by passing it as a dictionary to the ‘data’ parameter of the ‘requests.post’ function. For example, ‘requests.post(url, data={‘key’: ‘value’})’. The ‘requests’ library will automatically encode the data in the correct format.
How can I send a file with a POST request in Python?
Files can be sent with a POST request in Python by passing them as a dictionary to the ‘files’ parameter of the ‘requests.post’ function. The dictionary should contain the name of the file field as the key and a tuple with the filename and the file object as the value.
How can I handle errors and exceptions with the ‘requests’ library in Python?
The ‘requests’ library in Python raises exceptions for certain types of errors, such as a network error or a timeout. You can catch these exceptions using a try/except block and handle them appropriately. You can also check the status code of the response to handle HTTP errors.
How can I make asynchronous HTTP requests in Python?
Asynchronous HTTP requests can be made in Python using the ‘aiohttp’ library. This library allows you to send HTTP requests and handle responses asynchronously, which can significantly improve the performance of your application when dealing with a large number of requests.