Python as Glue
Python is a versatile and powerful language that can be used for a wide variety of tasks. One of the most common use cases for Python is as a “glue” language: it helps us combine skills and programs we already know how to use by allowing us to easily convert data from one format to another. This means that we can take data in one format that we don’t have tools to manipulate and change it into data for tools that we’re comfortable with. Whether we need to process a CSV, web page, or JSON file, Python can help us get the data into a format we can use.
For example, we might use Python to pull data from a web page and put it into Excel, where we already know how to manipulate it. We might also read a CSV file downloaded from a website, calculate the totals from it, and then output the data in JSON format.
Who This Series is For
In this series of tutorials, we’re not looking at data science. That is, this isn’t about doing heavy statistical or numerical calculations on data we’ve received. Python is one of the industry-standard tools for doing calculations like these—using libraries such as NumPy and pandas —and there are plenty of resources available for learning data science (such as Become a Python Data Scientist).
In this series, we’ll looking at how to convert data from one form to another so that we can then go on to manipulate it.
We’re also going to assume a little knowledge of Python and programming already—such as what a variable is, what a dictionary is, and how to import a module. To start learning Python (or any other programming language) from scratch, check out SitePoint’s programming tutorials. The Python wiki also has a list of Python programming tutorials for programmers.
Getting Started
We’ll start this tutorial by looking at how to read data and then how to write it to a different format.
Reading Data
Let’s try an example. Let’s imagine we’re an author on a tour of local libraries, talking to people about our books. We’ve been given plymouth-libraries.json —a JSON file of all the public libraries in the town of Plymouth in the UK—and we want to explore this dataset a little and convert it into something we can read in Excel or Google Sheets, because we know about Excel.
First, let’s read the contents of the JSON file into a Python data structure:
Code snippet
import jsonwith open("plymouth-libraries.json") as fp: library_data = json.load(fp)Now let’s explore this data a little in Python code to see what it contains:
Code snippet
print(library_data.keys())This will print dict_keys(['type', 'name', 'crs', 'features']), which are the top-level keys from this file.
Similarly:
Code snippet
print(library_data["features"][0]["properties"]["LibraryName"])This will print Central Library, which is the LibraryName value in properties for the first entry in the features list in the JSON file.
This is the most basic, and most common, use of Python’s built-in json module: to load some existing JSON data into a Python data structure (usually a Python dictionary, or nested set of Python dictionaries).
Bear in mind that, to keep these examples simple, this code contains no error checking. (Check out A Guide to Python Exception Handling for more on that.) But handling errors is important. For example, what would happen if the plymouth-libraries.json file didn’t exist? What we do in that situation depends on how we should react for errors. If we’re running this script by hand, Python will display the exception that occurs—in this case, a FileNotFoundError exception. Simply seeing that exception may be enough; we may not want to “handle” this in code at all:
Code snippet
$ python load-json.pyTraceback (most recent call last): File "/home/aquarius/Scratch/fail.py", line 13, in <module> open("plymouth-libraries.json")FileNotFoundError: [Errno 2] No such file or directory: 'plymouth-libraries.json'If we’d like to do something more than have our program terminate with an error, we can use Python’s try and except keywords (as the exception handling article above describes) to do something else of our choosing. In this case, we display a more friendly error message and then exit (because the rest of the program won’t run without the list of libraries!):
Code snippet
try: with open("plymouth-libraries.json") as fp: library_data = json.load(fp)except FileNotFoundError: print("I couldn't find the plymouth-libraries.json file!") sys.exit(1)Writing
Now we want to write that data from its Python dictionary into a different format on disk, so we can open it in Excel. For now, let’s use CSV format, which is a very simple file format that Excel understands. (If you’re thinking, “Hey, why don’t we make it a full Excel file!” … then read on. CSV is simpler, so we’ll do that first.) This process of taking Python data structures and writing them out as some file format is called serialization. So we’re going to serialize the data we read as JSON into CSV format.
The image below demonstrates the stages involved in serialization.

A CSV file is a text file of tabular data. Each row of the table is one line in the CSV file, with the entries in the row separated by commas. The first line of the file is a list of column headings.
Consider a set of data like this:
| Animal | Leg count | Furry? |
|---|---|---|
| Cat | 4 | Yes |
| Cow | 4 | No |
| Snake | 0 | No |
| Tarantula | 8 | Yes |
This data could look like this as a CSV file:
Code snippet
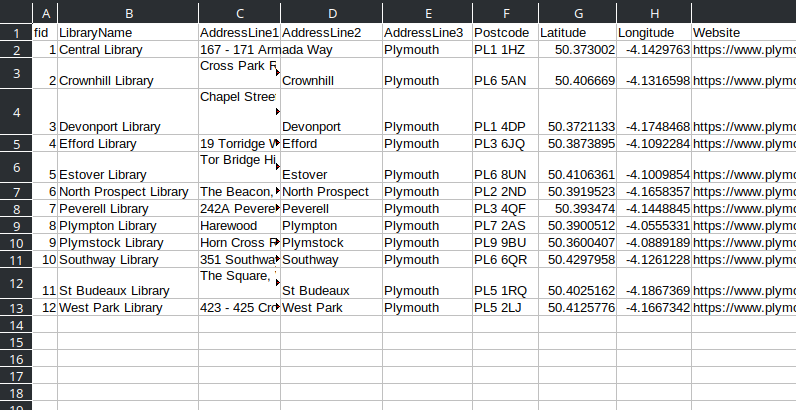
Animal,Leg count,"Furry?"Cat,4,YesCow,4,NoSnake,0,NoTarantula,8,YesTo write out a CSV file, we need a list of column header names. Fortunately, these will be the keys of the properties of the first entry in "features", since all libraries have the same keys:
Code snippet
header_names = library_data["features"][0]["properties"].keys()Given those names, we use the built-in csv module to write the header, and then write one row per library—to a file we open called plymouth-libraries.csv —like this:
Code snippet
with open("plymouth-libraries.csv", "w", newline="") as csvfile: writer = csv.DictWriter(csvfile, fieldnames=header_names) writer.writeheader() for library in library_data["features"]: writer.writerow(library["properties"])This is the core principle behind using Python as a file format converter to glue together two things:
- Read data in whatever format it’s currently in, which gives us that data as Python dictionaries.
- Then serialize those Python dictionaries into the file format we actually want.
That’s all there is to it. Now we have a CSV file that we can open and look through as we choose.
The script and input files referenced above can be downloaded from GitHub.
Reading Data with Code
A second example will further demonstrate this principle of format conversion. Let’s resume our fictional library tour. The following week, we’re planning to continue our tour by visiting libraries in north Somerset, and the list of those libraries is in a format called XML. Opening the XML file and looking at its contents suggests that an individual library is listed in this file as something like this:
Code snippet
<Row> <PublisherLabel>North Somerset Council</PublisherLabel> <PublisherURI>http://opendatacommunities.org/id/unitary-authority/north-somerset</PublisherURI> <LibraryName>Clevedon Library</LibraryName> <Address>37 Old Church Road</Address> <Locality>Clevedon</Locality> <Postcode>BS21 6NN</Postcode> <TelephoneNo>(01934) 426020</TelephoneNo> <Website>http://www.n-somerset.gov.uk/Leisure/libraries/your_local_library/Pages/Your-local-library.aspx</Website></Row>So we’re going to read that file with Python’s built-in XML module. Again, the goal here is to make a convenient Python dictionary and then serialize it. But this time, we’re also going to alter the data a little along the way: we only care about libraries where the postcode (the British version of a zip code) is BS40 or less. (So we want to keep BS21 6NN as a postcode, but ignore a postcode such as BS49 1AH.) This lets us use our knowledge of Python strings and numbers to discard some of the data.
First, let’s read in the XML file. The ElementTree module is traditionally imported with the name ET, for brevity, and can read a file with .parse(). We’ll also need the json module later to write out a JSON version of this data:
Code snippet
import xml.etree.ElementTree as ETimport jsontree = ET.parse('somerset-libraries.xml')ElementTree reads in an XML file and forms a tree structure out of it. At the top of the tree is the root, which is the first element in the XML. An ET element has properties relating to its content. An XML element like <MyElement>content here</MyElement> would have a tag property of "MyElement", the tag name, and a text property of "content here", containing the text in the element. The element also presents as a list that can be iterated over with a Python for loop, which will yield all the element’s direct child elements.
We obtain a reference to the root element of the tree:
Code snippet
root = tree.getroot()In this XML file in particular, this element is actually <Root>, but the name is a coincidence; it could be called anything. We can then iterate over all child elements of the root. These child elements are the <Row> elements in the XML, each of which defines one library. Our plan here is to turn the above XML for a <Row> into a Python dictionary, with one entry per child of the <Row>. That is, the above XML should become this Python dictionary:
Code snippet
{ "PublisherLabel": "North Somerset Council", "PublisherURI": "http://opendatacommunities.org/id/unitary-authority/north-somerset", "LibraryName": "Clevedon Library", "Address": "37 Old Church Road", "Locality": "Clevedon", "Postcode": "BS21 6NN", "TelephoneNo": "(01934) 426020", "Website": "http://www.n-somerset.gov.uk/Leisure/libraries/your_local_library/Pages/Your-local-library.aspx"}To do this, we’ll iterate over each of the <Row> elements in the root, and then, for each <Row>, iterate over each of its child elements and add them to a dictionary for that row. This will give us one dictionary per library, which we’ll store in a list called libraries:
Code snippet
libraries = []
for row in root: this_library = {} for element in row: name = element.tag value = element.text this_library[name] = value libraries.append(this_library)At this point, we’ve successfully parsed the input XML data into a list of Python dictionaries, meaning that we can discard the XML and work simply with the Python data structures. The first goal is to remove all the libraries with postcode BS40 or greater, which can be done by removing items from the list that don’t match:
Code snippet
for library in libraries: # get the third and fourth characters of the postcode, as a number # note that real postcode parsing is more complex than this! postcode = library["Postcode"] postcode_number = int(postcode[2:4]) if postcode_number >= 40: libraries.remove(library)The final step is to serialize the Python data into the destination format we want, which in this case is JSON. This is done with the json module’s dump function:
Code snippet
with open("somerset-libraries.json", mode="w") as fp: json.dump(libraries, fp, indent=2) # the indent makes the JSON be formattedThe outputted JSON data will look something like this:
Code snippet
[ { "PublisherLabel": "North Somerset Council", "PublisherURI": "http://opendatacommunities.org/id/unitary-authority/north-somerset", "LibraryName": "Clevedon Library", "Address": "37 Old Church Road", "Locality": "Clevedon", "Postcode": "BS21 6NN", "TelephoneNo": "(01934) 426020", "Website": "http://www.n-somerset.gov.uk/Leisure/libraries/your_local_library/Pages/Your-local-library.aspx" },... more libraries here ...]The script and input files can be downloaded from GitHub.
General Principles
The goal here is to take three steps:
- Load the data we want into a set of Python data structures.
- Manipulate the data however we want—which is convenient, because it’s now a set of Python data structures.
- Serialize the data into whatever output format we want.
Sometimes, the steps might require a little programming, as above. JSON data, as we saw in the first example, has a built-in Python library to load it (or “de-serialize” it) directly into a Python dictionary, ready for us to manipulate. XML data doesn’t have such a library, so a little delving into the Python docs is required if we’re to understand exactly how to read it. Many more esoteric formats also have Python libraries available to read or to write them, which can be installed from PyPI, Python’s suite of third-party libraries.
Parsing Complicated Formats
A useful guide to parsing some more complicated formats using the Python pandas module is available in Using Python to Parse Spreadsheet Data.
Understanding All the Formats
One example of such a format is KML, which was originally developed for Google Earth to allow a number of points on the globe to be specified and then loaded onto a map. It might be useful to plot our list of Plymouth libraries on a map so we can see where they all are in relation to one another and plan the best route for our tour. Let’s write a script that reads in that data and outputs it as KML so we can do that!
A little searching reveals that Python doesn’t have a built-in module for reading KML, but there are quite a few available for download. The simplest seems to be simplekml (truth in advertising!), and this is available from PyPI. Installing modules from PyPI involves a little setup, which is documented in Virtual Environments in Python Made Easy and also in the Python Packaging Guide, but once that’s done (and it only needs to be done once and will work for ever more), we should be able to pip install simplekml to get the simplekml module.
Embracing All the Formats
At this point, the script we need to write follows our standard three steps: load the data from the format it’s in (in this case, we’ll use the CSV file we created earlier), manipulate it if we wish (we don’t need to this time), and then serialize it to a file in the new format (which the simplekml documentation shows us how to do for KML).
First, let’s read in our input data. The Python csv module knows how to read the CSV file of libraries that we created previously:
Code snippet
import simplekmlimport csv
libraries = []with open('plymouth-libraries.csv') as csvfile: reader = csv.DictReader(csvfile) for row in reader: libraries.append(row)Now we have a Python list of dictionaries. One of those dictionaries looks like this:
Code snippet
{ "fid": "1", "LibraryName": "Central Library", "AddressLine1": "167 - 171 Armada Way", "AddressLine2": "", "AddressLine3": "Plymouth", "Postcode": "PL1 1HZ", "Latitude": "50.373002", "Longitude": "-4.1429763", "Website": "https://www.plymouth.gov.uk/libraries/findlibraryandopeninghours/centrallibrary",}To create a KML file, we can follow the simplekml module’s documentation. Make a Kml() object, then call its newpoint() function with name, latitude, and longitude values for each library:
Code snippet
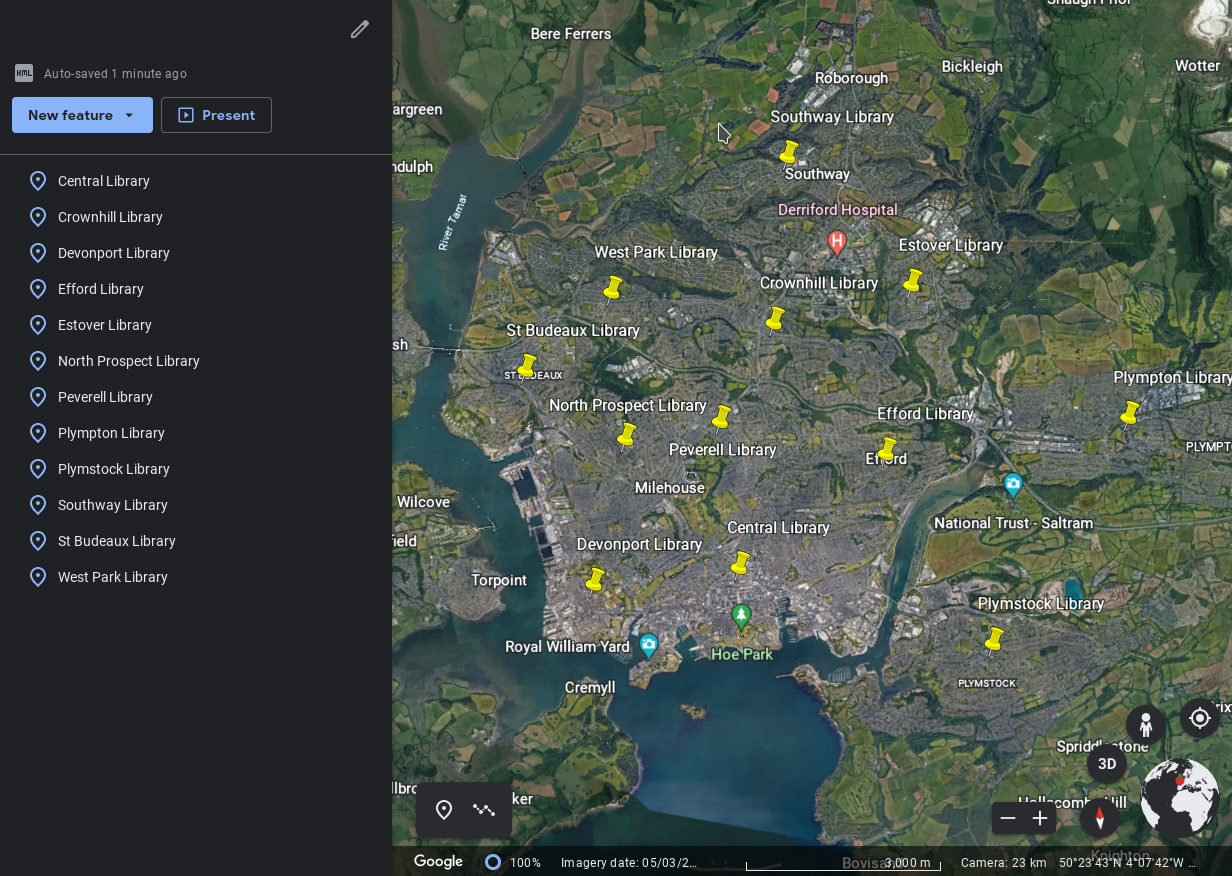
kml = simplekml.Kml()for library in libraries: # the coordinates need to be numeric, so convert # them to floating-point numbers lat = float(library["Latitude"]) lon = float(library["Longitude"]) # and add a new "point" to the KML file for this library kml.newpoint(name=library["LibraryName"], coords=[(lon, lat)])Finally, save the file as KML:
Code snippet
kml.save("plymouth-libraries.kml")Now we can import that KML file to Google Earth and … this is what we see.
The script and input files can be downloaded from GitHub.
Reading HTML
While we’re in Plymouth, we notice that the skyline is dominated by Beckley Point, the tallest building in the southwest of England, and that gets us wondering about tall buildings generally. Wikipedia, as usual, provides a page about the tallest buildings in the world, and we decide we’d like to explore that list a little more in Excel. Of course, we already know that we can copy a table from a web page and paste it into Excel and it does a reasonable job, but that’s not very exciting. We’re all Python all the time now! What if we wanted to look at, say, all the tall buildings without an E in their name? Or to get that list every day by running one command? So let’s break out the text editor again, with the intention of getting the data from that Wikipedia page and then putting it into Excel with a script.
Extracting data from an HTML page is the task of screen scraping, and much has been written about it. One useful guide is Web Scraping for Beginners. There are dedicated screen scraping tools to do the work, but Python can do it too, and then we have all the power of code at our disposal.
First, let’s look at how to fetch and read an HTML page with Python to extract data from it.
Requesting data from the Web can be done with the built-in urllib.request module, but the requests module is easier to use, so it’s worth installing that. We’ll also need Beautiful Soup (BS) for parsing HTML. (Again, this can be done with built-in modules, but BS is more pleasant.) So pip install requests beautifulsoup4 should get those modules ready for use. After that, the content of a web page can be fetched with requests.get() and the response’s content property:
Code snippet
import requestsfrom bs4 import BeautifulSoup
# Use the Python requests module to fetch the web pageresponse = requests.get("https://en.wikipedia.org/wiki/List_of_tallest_buildings")# and extract its HTMLhtml = response.contentAt this point, html is a long string variable of HTML. Beautiful Soup knows how to parse that into a useful data structure that we can explore:
Code snippet
soup = BeautifulSoup(html, "html.parser")Extracting data from HTML is one of the tasks that requires some programming—as well as some knowledge of the structure of the HTML in question—to make best use of the data. Beautiful Soup is the most-used Python module for this, and it has a deep well of functionality to help with advanced screen scraping.
For most examples, though, it will suffice to load the HTML into a “soup” of parsed data, and then use the .select() function to extract HTML elements by CSS selector, iterate through them, and read the .text within them. This is somewhat similar to using JavaScript methods to identify HTML elements in the DOM in a web page, which may be familiar to web programmers. The BS4 documentation explains some of Beautiful Soup’s more advanced features in detail, but much of the work can be done with select(), which takes a CSS selector as a parameter and returns a list of elements matching that selector, similarly to JavaScript’s querySelectorAll().
The HTML table that we want—of the tallest buildings in the world by height to pinnacle—is the fifth <table> element on the page. If the Wikipedia HTML had an ID attribute on that table, we could use that to find it directly, but it doesn’t. So we’ll use the knowledge that it’s the fifth table to find it with the .select() function:
Code snippet
tallest_table = soup.select("table")[4]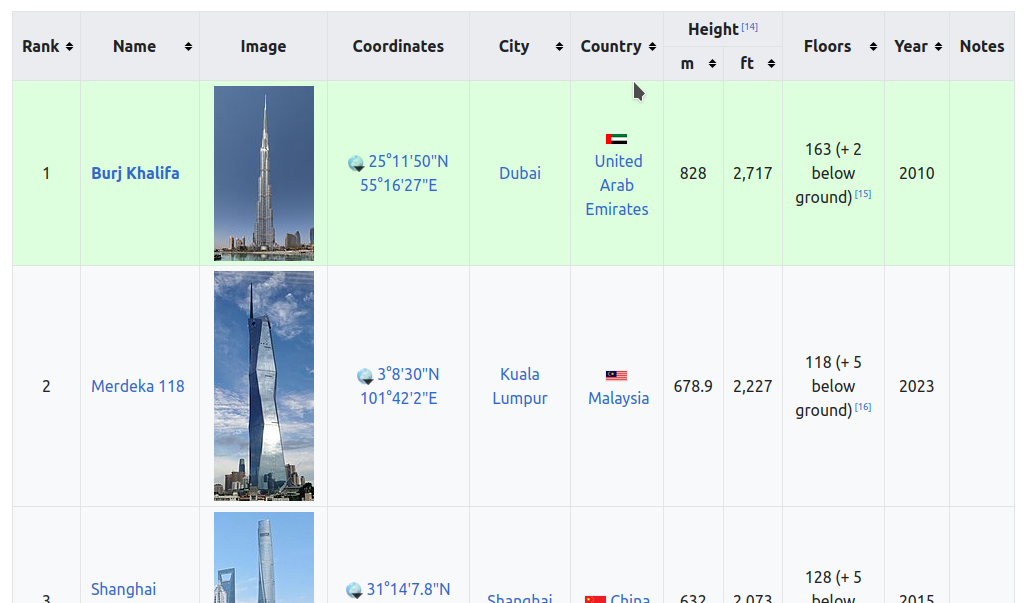
As can be seen from the table, we can get the title of each column by reading the first row. The table actually has two header rows, because there are separate columns for both height in meters and height in feet, and so we handle this a little differently by adding two columns to the list of column titles:
Code snippet
# Get the title for each column, by reading the text of# each <th> in the first row of this table.# Note that the "Height" column is two columns, m and ft,# so we handle this differently.column_titles = []first_row = tallest_table.select("tr")[0]for th in first_row.select("th"): column_title = th.text.strip() # .strip() removes carriage returns if column_title == "Height": # add two columns column_titles.append(column_title + " (m)") column_titles.append(column_title + " (ft)") else: # add this column title to the list column_titles.append(column_title)Once the column titles have been extracted—so that they can be used to make a dictionary for each building—it’s time to actually extract the building data. Each row in the table contains the values for a building. This means that, for each row, we need to combine the column titles and the column data to make a dictionary. Fortunately, Python provides the zip() function, which makes this easy.
zip() takes two lists— [a, b, c, d] and [w, x, y, z] —and returns one list: [(a,w), (b,x), (c,y), (d,z)]. We can then iterate through this combined list.
This means that, for each table row (or <tr>), we can retrieve the cells (<td>) in that row with tr.select("td"), and then zip the column titles together with them. Each cell returned from the <td> is a soup object, so we must then use the .text property of each <td> to retrieve the text in it:
Code snippet
tallest_buildings = []
for tr in tallest_table.select("tr")[1:]: building = {} tds = tr.select("td") # combine the header list and the data list from this row with zip() named_data = zip(column_titles, tds) for title, td in named_data: building[title] = td.text.strip() # and store this building in the list tallest_buildings.append(building)More Data Fiddling
Now that we have the data in a convenient Python data structure and no longer have to worry about HTML (or however else we obtained it), the next step is to manipulate the data. Here, it will be useful to convert the numeric heights of the buildings to be actual numbers. Since HTML data is all textual, this means that all the “height” values in our data are strings of digits rather than actual numbers. We can see this with a quick test, using Python’s built-in pprint module to “pretty-print” the first building in the list:
Code snippet
import pprintpprint.pprint(tallest_buildings[0])Code snippet
{'Building': 'Burj Khalifa†', 'Built': '2010', 'City': 'Dubai', 'Country': 'United Arab Emirates', 'Floors': '163', 'Height (ft)': '2,722\xa0ft', 'Height (m)': '829.8 m', 'Rank': '1'}Let’s convert the “Height (ft)”, “Height (m)” and “Floors” values from strings to numbers. These data may contain characters that aren’t numbers, so a simple call to float() may not work and we’ll need to be a little more clever.
The most basic way to convert string data like this to a floating point number or integer is to walk through each character in the string and only keep it if it’s a digit or a decimal point, and then to call float() on the kept characters only. This removes any commas, carriage returns, spaces, or other extraneous data in a string like "2,345.6 m", and would look like this, for converting the “Height (m)” data for each building:
Code snippet
height_m_digits = ""for character in building["Height (m)"]: if character.isdigit() or character == ".": height_m_digits += characterbuilding["Height (m)"] = float(height_m_digits)A second but slightly more advanced way is to use a list comprehension to extract these digits, which will convert "2,345.6 m" into ["2", "3", "4", "5", ".", "6"] —which can then be combined back into a string with .join() and then to a number with float():
Code snippet
height_ft_digits = [ character for character in building["Height (ft)"] if character.isdigit() or character == "."]height_ft_digits = "".join(height_ft_digits)building["Height (ft)"] = float(height_ft_digits)And a third way that’s shorter still is to use regular expressions, which are more powerful but also a more complex subject:
Code snippet
floors_digits = re.findall(r"[\d.]", building["Floors"])building["Floors"] = int("".join(floors_digits)) # note floor count is an int, not a floatLearning Regular Expressions
If you’d like to learn more about using regular expressions, check out the article Understanding Python Regex Functions, with Examples.
Once the data is converted to numbers for each building, if we pretty-print the first building, the data is more properly numeric:
Code snippet
import pprintpprint.pprint(tallest_buildings[0])Code snippet
{'Building': 'Burj Khalifa†', 'Built': '2010', 'City': 'Dubai', 'Country': 'United Arab Emirates', 'Floors': 163, 'Height (ft)': 2722.0, 'Height (m)': 829.8, 'Rank': 1}Writing for Excel for Real
The final step is to convert this data to our preferred destination format.
It’s sometimes useful to be able to create nicer Excel output than CSV can provide. In particular, a CSV file looks very plain when loaded into a spreadsheet, and has no formatting at all. If we’re producing a sheet for our own data exploration, then it may not matter how pretty it is. But a little effort put into making data look more readable can help a lot, especially if it’s destined for someone else. For this, we’ll use Python’s XlsxWriter, which can be installed with pip install Xlsxwriter. We can then pay some attention to the examples given in XlsxWriter’s tutorial.
First, create a new Excel spreadsheet file, and add a worksheet to it:
Code snippet
import xlsxwriter
workbook = xlsxwriter.Workbook('tallest_buildings.xlsx')worksheet = workbook.add_worksheet()To add formatting to Excel cells using XlsxWriter, it’s easiest to define a particular format style, which can then be applied later. Let’s do that for some of the cell data up front:
Code snippet
# Add a bold red format to use to highlight cellsbold = workbook.add_format({ 'bold': True, 'font_color': 'red'})
# Add a number format for cells with heights.heights = workbook.add_format({'num_format': '#,##0.00'})The first row of the spreadsheet will be the column titles. We can fetch these by using the dictionary keys from the first building in the list:
Code snippet
column_titles = tallest_buildings[0].keys()row_number = 0 # we write the column titles in row 0We now need to walk through this list of titles and write each into its corresponding column in row 0. To do this, we use worksheet.write with a row number (always 0), column number (starting at 0 and increasing by one for each column title), cell content (the column title string itself), and a cell format (bold, as defined above). Python provides the useful enumerate() function to iterate the list while getting the index position for each item. enumerate([a, b, c, ...]) will return a list ([(0, a), (1, b), (2, c), ...]) which can be iterated over to write out our column titles at the top of each column:
Code snippet
for column_number, title in enumerate(column_titles): worksheet.write(row_number, column_number, title, bold)Then, to write out all the data, we do exactly the same thing: iterate through the column titles list once for each building, and write out the value of that field in the building’s dictionary into the appropriate row and column number:
Code snippet
# Start from the first cell below the headers.row_number = 1
# Iterate over the buildings and write them out row by row,for building in tallest_buildings: for column_number, title in enumerate(column_titles): worksheet.write(row_number, column_number, building[title], heights) row_number += 1Finally, a call to worksheet.autofit() adjusts all the cell widths in the spreadsheet so they fit the data contained with them, similar to double-clicking on a column border in Excel itself. Then, closing the worksheet ensures it’s saved:
Code snippet
worksheet.autofit()workbook.close()The script and input files can be downloaded from GitHub.
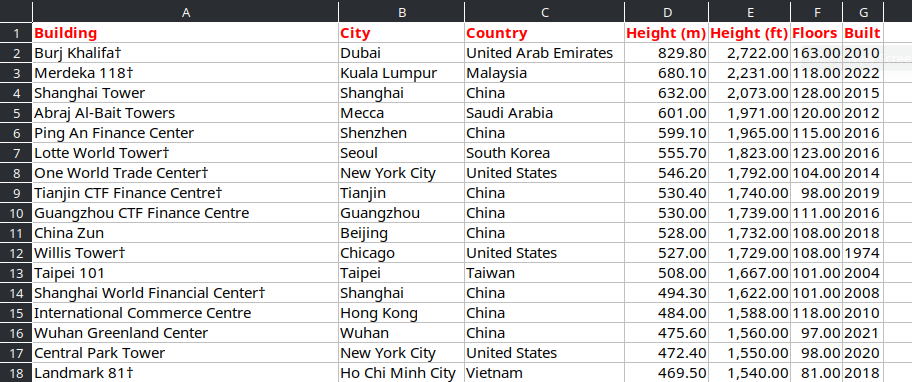
And then we have some more nicely formatted Excel data to look at, as pictured below.
Summary
And that’s all we need! Whether we’re using code libraries to find real libraries, or trying to extract sense from a mess of reports or published data, Python’s there for us.
For each file or set of data we want to work with, we can take these three steps:
- Load the data we want into a set of Python data structures, using Python’s built-in modules or others that we find from PyPI which can read that format.
- Manipulate the data however we want—which is convenient, because it’s now a set of Python data structures.
- Serialize the data into whatever output format we want, again using built-in or third-party modules.