

Key Takeaways
- Importing large amounts of data into Redshift can be accomplished using the COPY command, which is designed to load data in parallel, making it faster and more efficient than the INSERT command.
- To use the COPY command, data source files must be uploaded to S3, and the CSV file format is recommended. The COPY command also supports various compression algorithms, which can reduce data transfer amounts and speed up the loading process.
- During the data import process, errors can be managed using the STL_LOAD_ERRORS system table for detailed information about load errors. The COPY command also includes the MAXERROR option, allowing the command to continue loading data despite encountering errors.
This article was originally published by TeamSQL. Thank you for supporting the partners who make SitePoint possible.
Importing a large amount of data into Redshift is easy using the COPY command. To demonstrate this, we’ll import the publicly available dataset “Twitter Data for Sentiment Analysis” (see Sentiment140 for additional information).
Note: You can connect to AWS Redshift with TeamSQL, a multi-platform DB client that works with Redshift, PostgreSQL, MySQL & Microsoft SQL Server and runs on Mac, Linux and Windows. You can download TeamSQL for free.
Download the ZIP file containing the training data here.
The Redshift Cluster
For the purposes of this example, the Redshift Cluster’s configuration specifications are as follows:
- Cluster Type: Single Node
- Node Type: dc1.large
- Zone: us-east-1a
Create a Database in Redshift
Run the following command to create a new database in your cluster:
CREATE DATABASE sentiment;
Create a Schema in the Sentiment Database
Run the following command to create a scheme within your newly-created database:
CREATE SCHEMA tweets;
The Schema (Structure) of the Training Data
The CSV file contains the Twitter data with all emoticons removed. There are six columns:
- The polarity of the tweet (key: 0 = negative, 2 = neutral, 4 = positive)
- The id of the tweet (ex. 2087)
- The date of the tweet (ex. Sat May 16 23:58:44 UTC 2009)
- The query (ex. lyx). If there is no query, then this value is NO_QUERY.
- The user that tweeted (ex. robotickilldozr)
- The text of the tweet (ex. Lyx is cool)
Create a Table for Training Data
Begin by creating a table in your database to hold the training data. You can use the following command:
CREATE TABLE tweets.training (
polarity int,
id BIGINT,
date_of_tweet varchar,
query varchar,
user_id varchar,
tweet varchar(max)
)
Uploading CSV File to S3
To use Redshift’s COPY command, you must upload your data source (if it’s a file) to S3.
To upload the CSV file to S3:
- Unzip the file you downloaded. You’ll see 2 CSV files: one is test data (used to show structure of original dataset), and the other (file name: training.1600000.processed.noemoticon) contains the original data. We will upload and use the latter file.
- Compress the file. If you’re using macOS or Linux, you can compress the file using GZIP by running the following command in Terminal:
gzip training.1600000.processed.noemoticon.csv - Upload your file using the AWS S3 Dashboard.
Alternatively, you can use Terminal/Command Line to upload your file. To do this, you must install AWS CLI and, after installation, configure it (run aws configure in your terminal to start the configuration wizard) with your access and secret key.
Connect TeamSQL to the Redshift Cluster and Create the Schema
Open TeamSQL (if you don’t have the TeamSQL Client, download it from teamsql.io) and add a new connection.
- Click Create a Connection to launch the Add Connection window.
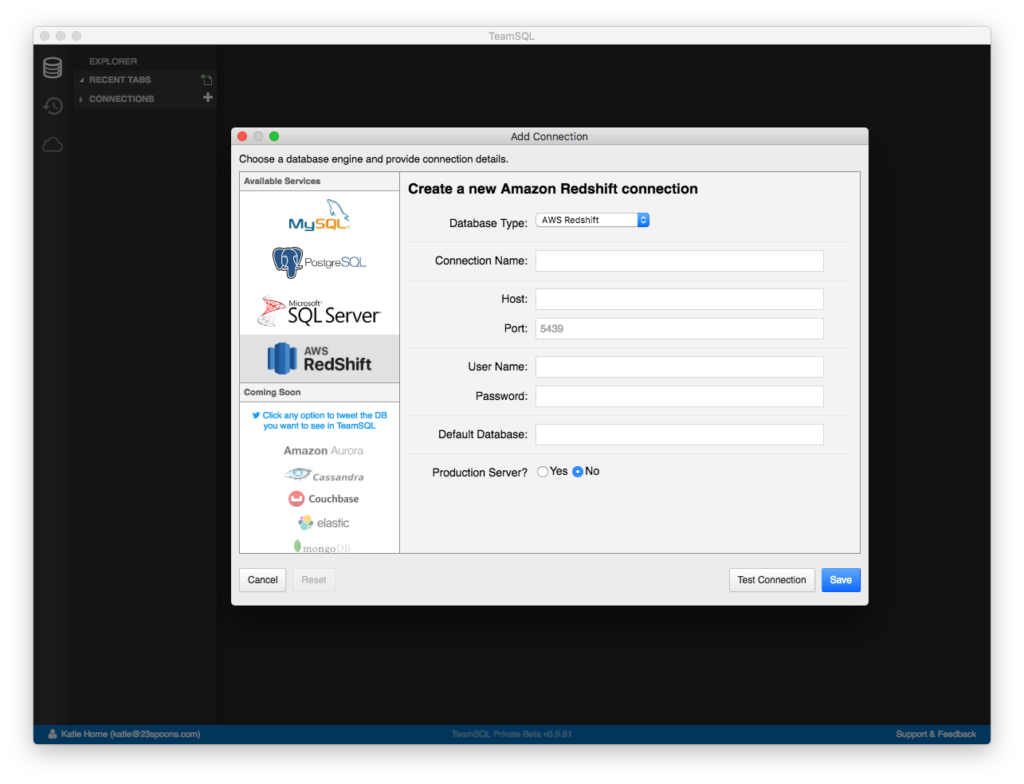
- Select Redshift and provide the requested details to set up your new connection.
- Do not forget to enter the Default Database Name!
- Test the connection, and save if the test is successful.
- By default, TeamSQL displays the connections you’ve added in the left-hand navigation panel. To enable the connection, click on the socket icon.
- Right click on default database to open a new tab.
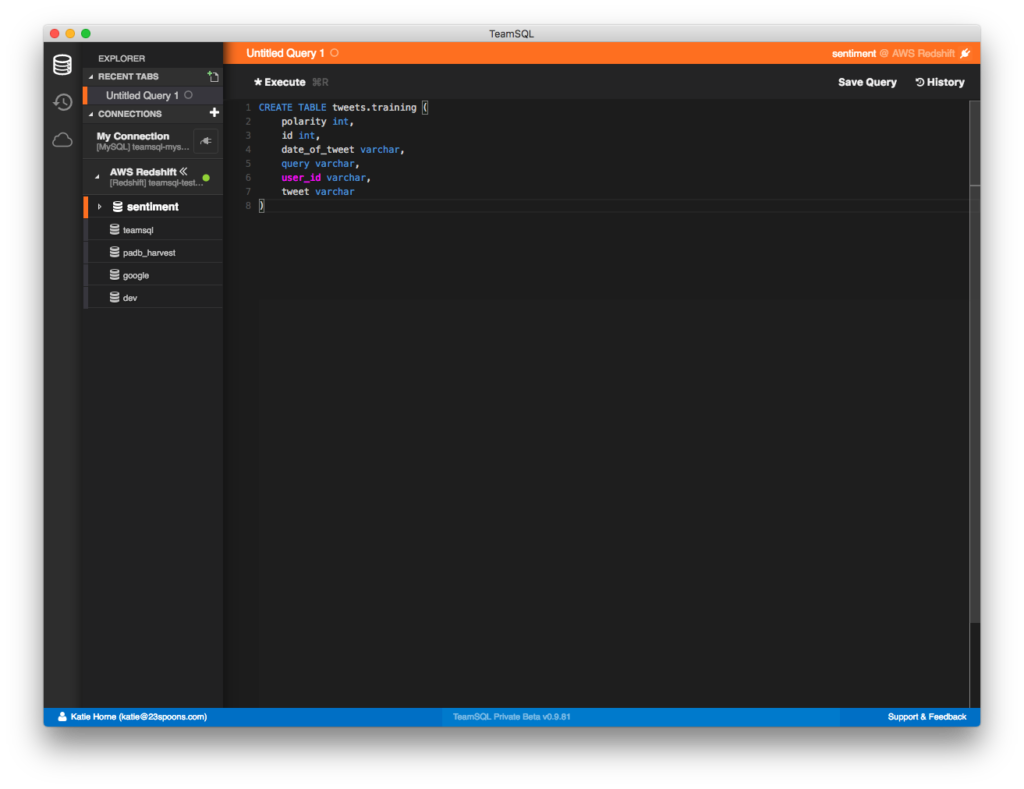
- Run this command to create a new schema in your database.
CREATE SCHEMA tweets;
- Refresh the database list in the left-hand navigation panel with right clicking on connection item.
- Create a new table for training data.
CREATE TABLE tweets.training (
polarity int,
id int,
date_of_tweet varchar,
query varchar,
user_id varchar,
tweet varchar
)
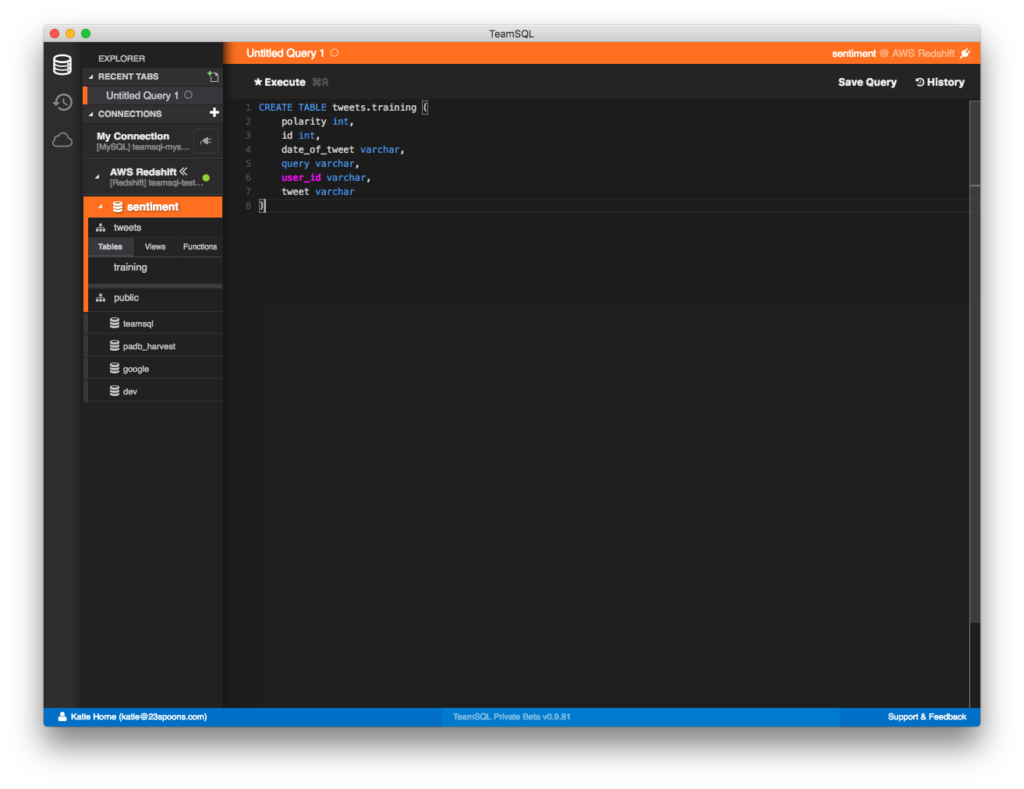
- Refresh the connection and your table should appear in the left-hand list.
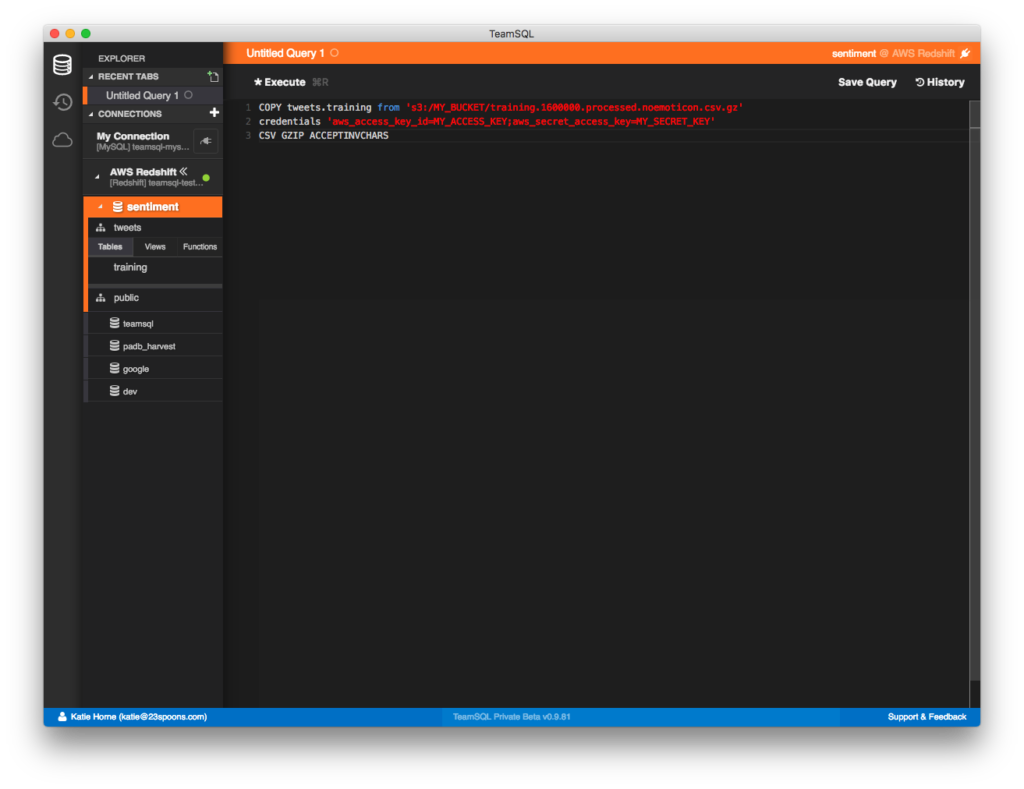
Using the COPY Command to Import Data
To copy your data from your source file to your data table, run the following command:
COPY tweets.training from 's3://MY_BUCKET/training.1600000.processed.noemoticon.csv.gz'
credentials 'aws_access_key_id=MY_ACCESS_KEY;aws_secret_access_key=MY_SECRET_KEY'
CSV GZIP ACCEPTINVCHARS
This command loads the CSV file and imports the data to our tweets.training table.
Command Parameter Definitions
CSV: Enables use of the CSV format in the input data.
DELIMITER: Specifies the single ASCII character that is used to separate fields in the input file, such as a pipe character ( | ), a comma ( , ), or a tab ( \t ).
GZIP: A value that specifies that the input file or files are in compressed gzip format (.gz files). The COPY operation reads each compressed file and uncompresses the data as it loads.
ACCEPTINVCHARS: Enables loading of data into VARCHAR columns even if the data contains invalid UTF-8 characters. When ACCEPTINVCHARS is specified, COPY replaces each invalid UTF-8 character with a string of equal length consisting of the character specified by replacement_char. For example, if the replacement character is ‘^’, an invalid three-byte character will be replaced with ‘^^^’.
The replacement character can be any ASCII character except NULL. The default is a question mark ( ? ). For information about invalid UTF-8 characters, see Multibyte Character Load Errors.
COPY returns the number of rows that contained invalid UTF-8 characters, and it adds an entry to the STL_REPLACEMENTS system table for each affected row, up to a maximum of 100 rows for each node slice. Additional invalid UTF-8 characters are also replaced, but those replacement events are not recorded.
If ACCEPTINVCHARS is not specified, COPY returns an error whenever it encounters an invalid UTF-8 character.
ACCEPTINVCHARS is valid only for VARCHAR columns.
For additional information, please see Redshift Copy Parameters and Data Format.
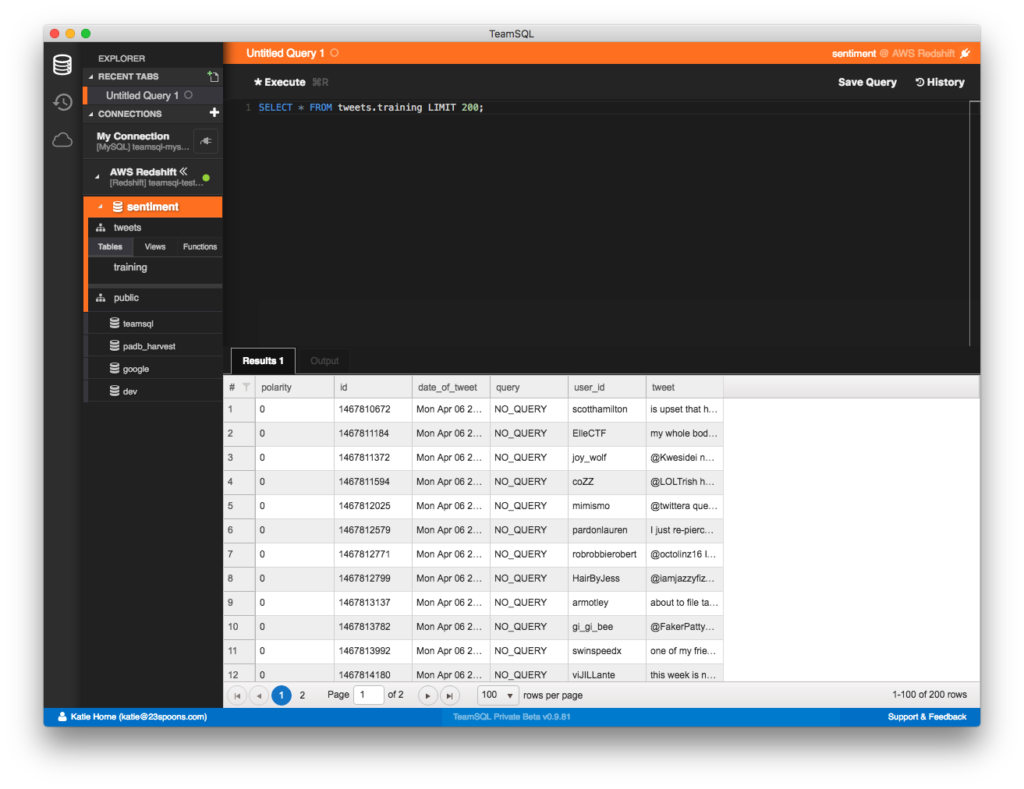
Accessing Imported Data
After your COPY process has finished, run a SELECT query to see if everything imported properly:
SELECT * FROM tweets.training LIMIT 200;
Troubleshooting
If you get an error while executing the COPY command, you can check the Redshift logs by running the following:
SELECT * FROM stl_load_errors;
You can download TeamSQL for free.
Frequently Asked Questions (FAQs) about Importing Data into Redshift Using the COPY Command
What are the Best Practices for Loading Data into Redshift?
When loading data into Redshift, it’s crucial to follow best practices to ensure optimal performance and efficiency. Firstly, always use the COPY command instead of INSERT. COPY is designed to load large amounts of data in parallel, making it faster and more efficient. Secondly, split your data into multiple files. Redshift can load multiple files concurrently, which significantly speeds up the process. Lastly, compress your data files before loading. Redshift supports various compression algorithms, which can reduce the amount of data transferred and speed up the loading process.
How Can I Optimize the COPY Command for Faster Data Loading?
There are several ways to optimize the COPY command for faster data loading. One method is to use the MAXERROR option, which allows the COPY command to continue loading data even if it encounters errors. Another method is to use the COMPUPDATE and STATUPDATE options, which control whether the COPY command updates the table statistics and compression encodings. Disabling these options can speed up the COPY command, especially for large tables.
How Can I Handle Errors During Data Loading?
Redshift provides several tools to handle errors during data loading. The COPY command returns an error message if it encounters any issues. You can also use the STL_LOAD_ERRORS system table to view detailed information about load errors. Additionally, the COPY command supports the MAXERROR option, which allows the command to continue loading data even if it encounters a certain number of errors.
How Can I Load Data from Different File Formats?
Redshift supports loading data from various file formats, including CSV, JSON, and Avro. The COPY command includes options to specify the file format, such as CSV, JSON, or AVRO. You can also use the FORMAT AS clause to specify the file format. For example, to load data from a CSV file, you would use the COPY command with the CSV option.
How Can I Load Data from Amazon S3?
To load data from Amazon S3, you need to use the COPY command with the ‘FROM’ clause followed by the S3 bucket URL. You also need to provide your AWS access key ID and secret access key for authentication. Additionally, you can specify options to control the data loading process, such as the file format, compression encoding, and error handling.
How Can I Load Compressed Data Files?
Redshift supports loading data from compressed files to save bandwidth and speed up the loading process. The COPY command automatically detects and decompresses the data files. It supports various compression algorithms, including GZIP, LZOP, and BZIP2. You just need to compress your data files using one of these algorithms before loading.
How Can I Load Data in Parallel?
Redshift can load data in parallel to speed up the process. To do this, you need to split your data into multiple files and load them concurrently. The COPY command automatically manages the parallel loading process. It distributes the data files across the compute nodes and loads them simultaneously.
How Can I Update Table Statistics After Loading Data?
After loading data, you can update the table statistics using the ANALYZE command. This command updates the statistics used by the query planner to optimize query execution. It’s a good practice to run the ANALYZE command after loading large amounts of data or making significant changes to the table.
How Can I Load Data from a Remote Host?
To load data from a remote host, you need to use the SSH protocol. Redshift doesn’t support SSH directly, but you can use an intermediary service like Amazon S3. First, transfer your data to an S3 bucket using SSH, then load the data from the S3 bucket into Redshift using the COPY command.
How Can I Monitor the Data Loading Process?
Redshift provides several system tables and views to monitor the data loading process. The STL_LOAD_COMMITS table shows the progress of each load operation. The STL_LOADERROR_DETAIL view provides detailed information about load errors. You can query these tables and views to monitor the data loading process and troubleshoot any issues.