

A photographer friend of mine implored me to find and download images of picture frames from the internet. I eventually landed on a web page that had a number of them available for free but there was a problem: a link to download all the images together wasn’t present.
I didn’t want to go through the stress of downloading the images individually, so I wrote this PHP class to find, download and zip all images found on the website.
Key Takeaways
- The PHP class utilizes Symfony’s DomCrawler component to scrape images from a webpage, download and save them into a folder, create a ZIP archive of the folder, and then delete the folder. This class is designed to automate the process of downloading multiple images from a website.
- The class includes five private properties and eight public methods. The properties store information such as the folder name, webpage URL, HTML document code, ZIP file name, and operation status. The methods include functions to set the folder and file name, instantiate the DomCrawler, download and save images, create a ZIP file, delete the folder, and get the operation status.
- To use the class, all required files must be included, either via autoload or explicitly. The setFolder and setFileName methods should be called with their respective arguments, and the process method is then called to put the class to work. The DomCrawler component and create_zip function must be included for the class to function.
How the Class works
It searches a URL for images, downloads and saves the images into a folder, creates a ZIP archive of the folder and finally deletes the folder.
The class uses Symfony’s DomCrawler component to search for all image links found on the webpage and a custom zip function that creates the zip file. Credit to David Walsh for the zip function.
Coding the Class
The class consists of five private properties and eight public methods including the __construct magic method.
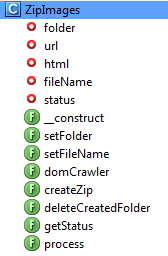
Below is the list of the class properties and their roles.
1. $folder: stores the name of the folder that contains the scraped images.
2. $url: stores the webpage URL.
3. $html: stores the HTML document code of the webpage to be scraped.
4. $fileName: stores the name of the ZIP file.
5. $status: saves the status of the operation. I.e if it was a success or failure.
Let’s get started building the class.
Create the class ZipImages containing the above five properties.
<?php
class ZipImages {
private $folder;
private $url;
private $html;
private $fileName;
private $status;Create a __construct magic method that accepts a URL as an argument.
The method is quite self-explanatory.
public function __construct($url) {
$this->url = $url;
$this->html = file_get_contents($this->url);
$this->setFolder();
}The created ZIP archive has a folder that contains the scraped images. The setFolder method below configures this.
By default, the folder name is set to images but the method provides an option to change the name of the folder by simply passing the folder name as its argument.
public function setFolder($folder="image") {
// if folder doesn't exist, attempt to create one and store the folder name in property $folder
if(!file_exists($folder)) {
mkdir($folder);
}
$this->folder = $folder;
}setFileName provides an option to change the name of the ZIP file with a default name set to zipImages:
public function setFileName($name = "zipImages") {
$this->fileName = $name;
}At this point, we instantiate the Symfony crawler component to search for images, then download and save all the images into the folder.
public function domCrawler() {
//instantiate the symfony DomCrawler Component
$crawler = new Crawler($this->html);
// create an array of all scrapped image links
$result = $crawler
->filterXpath('//img')
->extract(array('src'));
// download and save the image to the folder
foreach ($result as $image) {
$path = $this->folder."/".basename($image);
$file = file_get_contents($image);
$insert = file_put_contents($path, $file);
if (!$insert) {
throw new \Exception('Failed to write image');
}
}
}After the download is complete, we compress the image folder to a ZIP Archive using our custom create_zip function.
public function createZip() {
$folderFiles = scandir($this->folder);
if (!$folderFiles) {
throw new \Exception('Failed to scan folder');
}
$fileArray = array();
foreach($folderFiles as $file){
if (($file != ".") && ($file != "..")) {
$fileArray[] = $this->folder."/".$file;
}
}
if (create_zip($fileArray, $this->fileName.'.zip')) {
$this->status = <<<HTML
File successfully archived. <a href="$this->fileName.zip">Download it now</a>
HTML;
} else {
$this->status = "An error occurred";
}
}Lastly, we delete the created folder after the ZIP file has been created.
public function deleteCreatedFolder() {
$dp = opendir($this->folder) or die ('ERROR: Cannot open directory');
while ($file = readdir($dp)) {
if ($file != '.' && $file != '..') {
if (is_file("$this->folder/$file")) {
unlink("$this->folder/$file");
}
}
}
rmdir($this->folder) or die ('could not delete folder');
}Get the status of the operation. I.e if it was successful or an error occurred.
public function getStatus() {
echo $this->status;
}Process all the methods above.
public function process() {
$this->domCrawler();
$this->createZip();
$this->deleteCreatedFolder();
$this->getStatus();
}You can download the full class from Github.
Class Dependency
For the class to work, the Domcrawler component and create_zip function need to be included. You can download the code for this function here.
Download and install the DomCrawler component via Composer simply by adding the following require statement to your composer.json file:
"symfony/dom-crawler": "2.3.*@dev"Run $ php composer.phar install to download the library and generate the vendor/autoload.php autoloader file.
Using the Class
- Make sure all required files are included, via autoload or explicitly.
- Call the
setFolder, andsetFileNamemethod and pass in their respective arguments. Only call thesetFoldermethod when you need to change the folder name. - Call the
processmethod to put the class to work.
<?php
require_once 'zipfunction.php';
require_once 'vendor/autoload.php';
use Symfony\Component\DomCrawler\Crawler;
require_once 'vendor/autoload.php';
//instantiate the ZipImages class
$object = new ArchiveFile('https://www.sitepoint.com');
// set the zip file name
$object->setFolder('pictureFrames');
// set the zip file name
$object->setFileName('myframes');
// initialize the class process
$object->process();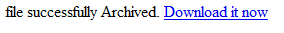
Summary
In this article, we learned how to create a simple PHP image scraper that automatically compresses downloaded images into a Zip archive. If you have alternative solutions or suggestions for improvement, please leave them in the comments below, all feedback is welcome!
Frequently Asked Questions (FAQs) about Image Scraping with Symfony’s DomCrawler
What is Symfony’s DomCrawler Component?
Symfony’s DomCrawler Component is a powerful tool that allows developers to traverse and manipulate HTML and XML documents. It provides an API that is easy to use and understand, making it a popular choice for web scraping tasks. The DomCrawler Component can be used to select specific elements on a page, extract data from them, and even modify their content.
How do I install Symfony’s DomCrawler Component?
Installing Symfony’s DomCrawler Component is straightforward. You can use Composer, a dependency management tool for PHP. Run the following command in your project directory: composer require symfony/dom-crawler. This will download and install the DomCrawler Component along with its dependencies.
How do I use Symfony’s DomCrawler Component to scrape images?
To scrape images using Symfony’s DomCrawler Component, you first need to create a new instance of the Crawler class and load the HTML content into it. Then, you can use the filter method to select the image elements and extract their src attributes. Here’s a basic example:$crawler = new Crawler($html);$crawler->filter('img')->each(function (Crawler $node) {
echo $node->attr('src');});
Can I use Symfony’s DomCrawler Component with Laravel?
Yes, you can use Symfony’s DomCrawler Component with Laravel. Laravel’s HTTP testing functionality actually uses the DomCrawler Component under the hood. This means you can use the same methods and techniques to traverse and manipulate HTML content in your Laravel tests.
How do I select elements using Symfony’s DomCrawler Component?
Symfony’s DomCrawler Component provides several methods to select elements, including filter, filterXPath, and selectLink. These methods allow you to select elements based on their tag name, XPath expression, or link text, respectively.
Can I modify the content of elements using Symfony’s DomCrawler Component?
Yes, you can modify the content of elements using Symfony’s DomCrawler Component. The each method allows you to iterate over each selected element and perform operations on it. For example, you can change the src attribute of an image element like this:$crawler->filter('img')->each(function (Crawler $node) {
$node->attr('src', 'new-image.jpg');});
How do I handle errors and exceptions when using Symfony’s DomCrawler Component?
When using Symfony’s DomCrawler Component, errors and exceptions can be handled using try-catch blocks. For example, if the filter method doesn’t find any matching elements, it will throw an InvalidArgumentException. You can catch this exception and handle it appropriately.
Can I use Symfony’s DomCrawler Component to scrape websites that require authentication?
Yes, you can use Symfony’s DomCrawler Component to scrape websites that require authentication. However, this requires additional steps, such as sending a POST request with the login credentials and storing the session cookie.
How do I extract attribute values using Symfony’s DomCrawler Component?
You can extract attribute values using the attr method provided by Symfony’s DomCrawler Component. For example, to extract the src attribute of an image element, you can do the following:$crawler->filter('img')->each(function (Crawler $node) {
echo $node->attr('src');});
Can I use Symfony’s DomCrawler Component to scrape AJAX-loaded content?
Unfortunately, Symfony’s DomCrawler Component cannot directly scrape AJAX-loaded content because it doesn’t execute JavaScript. However, you can use tools like Guzzle and Goutte in combination with the DomCrawler Component to send HTTP requests and handle AJAX-loaded content.